







Java的HashMap底层原理解析
java集合中有比较重要的两个概念
一个是Collection(存放单个数据)实现了list和set两个接口

一个是Map(存放键值对)
今天就主要来讨论一下Map中的HashMap的底层原理
1.HashMap存储结构
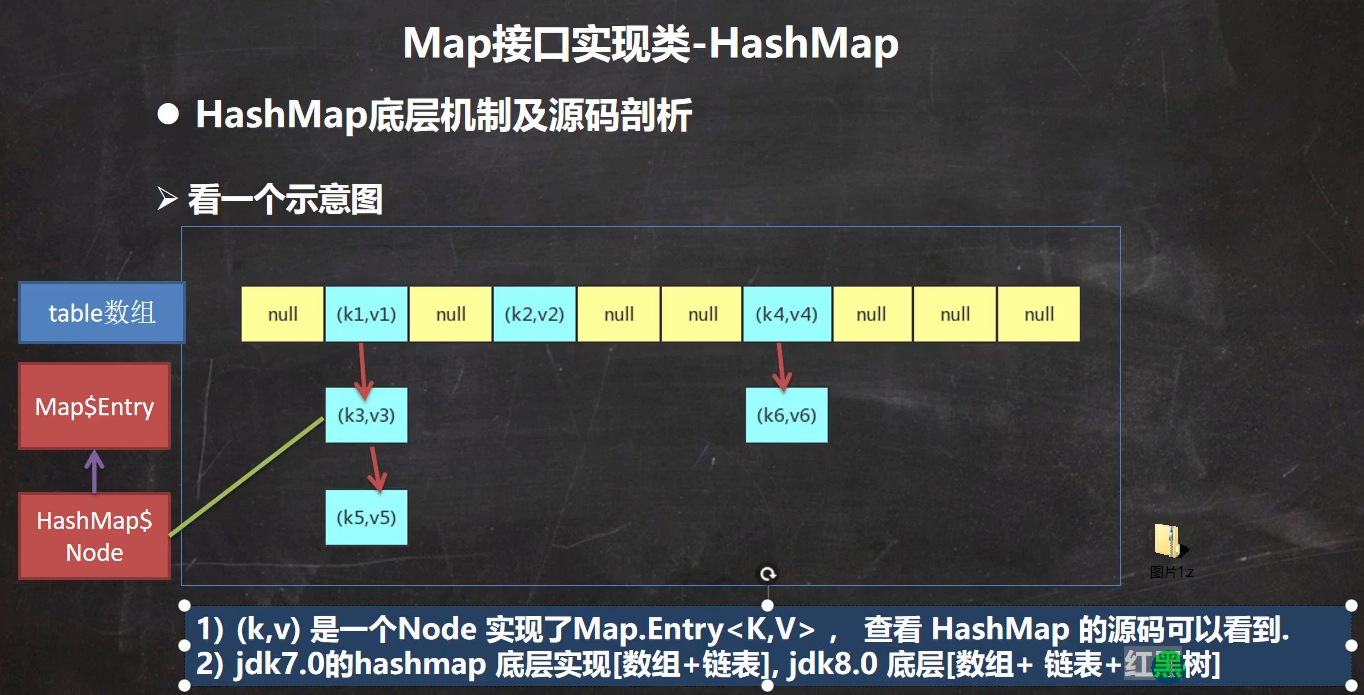
HashMap的存储结构为数据结构中散列表(哈希表)中的链式存储结构,其构成为数组+连表的存储结构 如下图

即存储的数据先经过hash算法计算存储位置,相同位置的数据存储在对应数组后,并依次形成链表形式。
2.HashMap存储的数据类型(比较复杂)
(1)HashMap底层维护了Node类(可以存储键值对的数据类型,并且是实现了Map.Entry<K,V>接口)形成的数组table,默认为null。

(2)为了方便遍历,还会创建EntrySet集合,集合内放入的元素类型为Entry 该类型就有K,V 即EntrySet<Entry<key,value>>
例如下图,每一个横行是一个Entry ,4个Entry 组成一个EntrySet

Entry 中的每一个 key 值存储在Set中,而KeySet中的每个值都指向Node类中的Key值
Entry 中的每一个 value 值存储在Collection中,而Collection中的每个值都指向Node类中的Value值
(这里使用了向上造型的思想,EntrySet<>中其实放入的是实现Map.Entry<K,V>的Node类)重点
这些事情只是为了。Entry 中的**getKey()和getValue()**方法,可以直接获取键与值。。。
3.HashMap的动态生成
因为HashMap是动态生成的集合,下面是它的扩容原理
(1)首次添加,则需要扩容table容量为16,K-V的个数临界值(threshold)为12(16*0.75)
(2)以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推
(3)在Java8中,如果一条链表的元素个数超过8个,如果table的大小 < 64,进行扩容
table的大小 >= 64,就会进行树化,变为红黑树(方便进行查询操作)
下图为总体结构图
4.HashMap的添加机制
添加key-val时,通过计算key的哈希值得到在table的索引。然后判断该索引处是否有元素,
如果没有元素直接添加。
如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,
如果相等,则直接替换val;
如果不相等需要判断是树结构还是链表结构,做出相应添加处理。
如果添加时发现容量不够,则需要扩容。
以上就是HashMap基本的设计理念分析,参考源码进行书写总结,放心查阅.















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









