







(1)词频统计(2学时)
词频统计的大致功能是:统计单个或者多个文本文件中每个单词出现的次数,并将每个单词及其出现频率按照“about 3”形式的列表输出。
由图可知:
输入文本(可以不只一个),按行提取文本文档的单词,形成行<k1,v1>键值对(具体形式很多,例如<行数,字符偏移>);
通过Spliting将<k1,v1>细化为单词键值对<k2,v2>,Map分发到各个节点,同时将<k2,v2>归结为list(<k2,v2>);
在进行计算统计前,先用Shuffing将相同主键k2归结在一起形成<k2, list(v2)>;
Reduce阶段直接对<k2, list(v2)> 进行合计得到list(<k3,v3>)并将结果返回主节点。
编写wordcount程序对输入文件进行词频统计
有文本文档data.txt,内容为:
| a good beginning is half the battle where there is a will there is a way |
预期输出result.txt文档中的内容为:
| a 3 battle 1 beginning 1 good 1 half 1 is 3 the 1 there 2 way 1 where 1 will 1 |
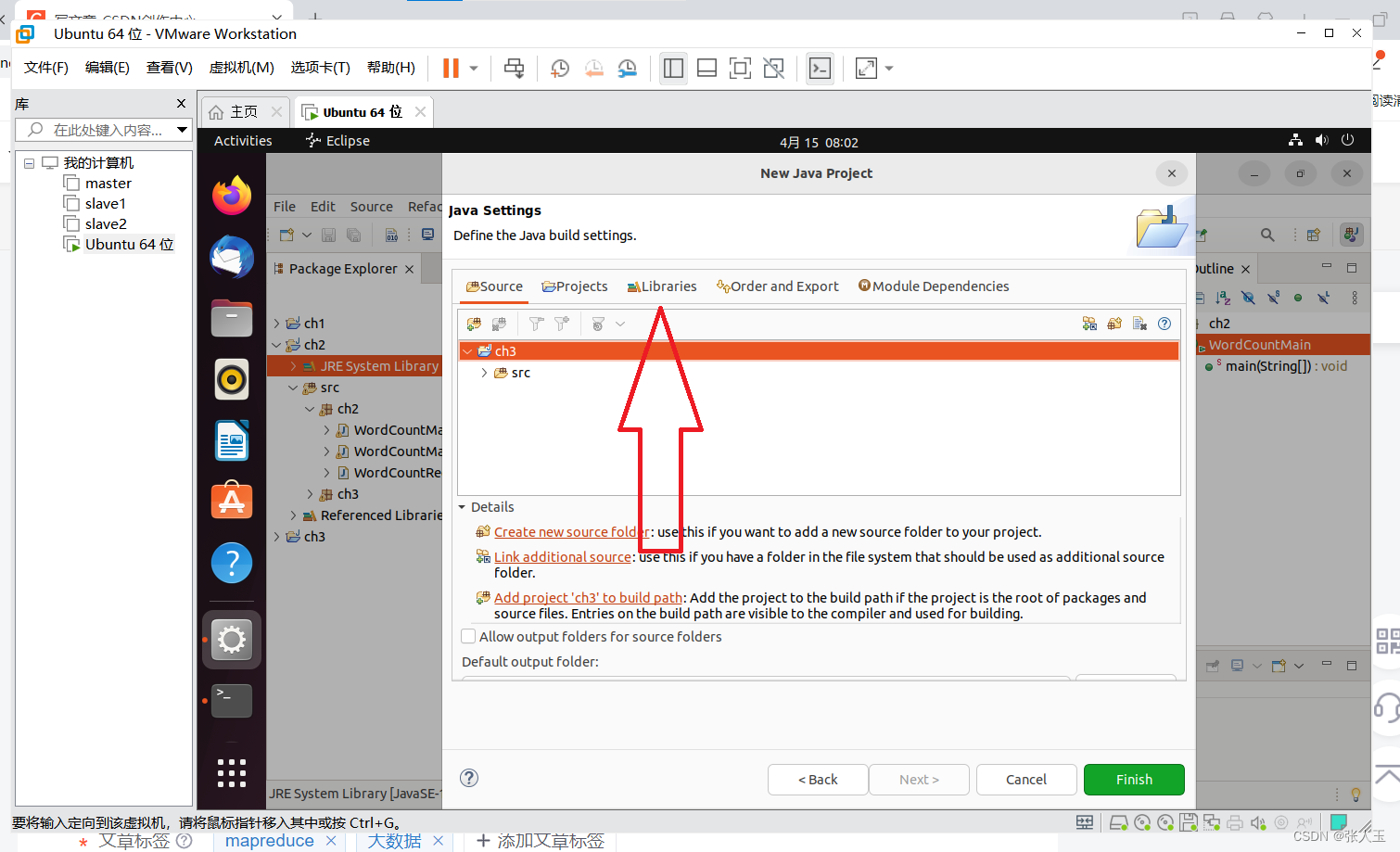
在编写eclipse代码之前我们要进行导包

点击next
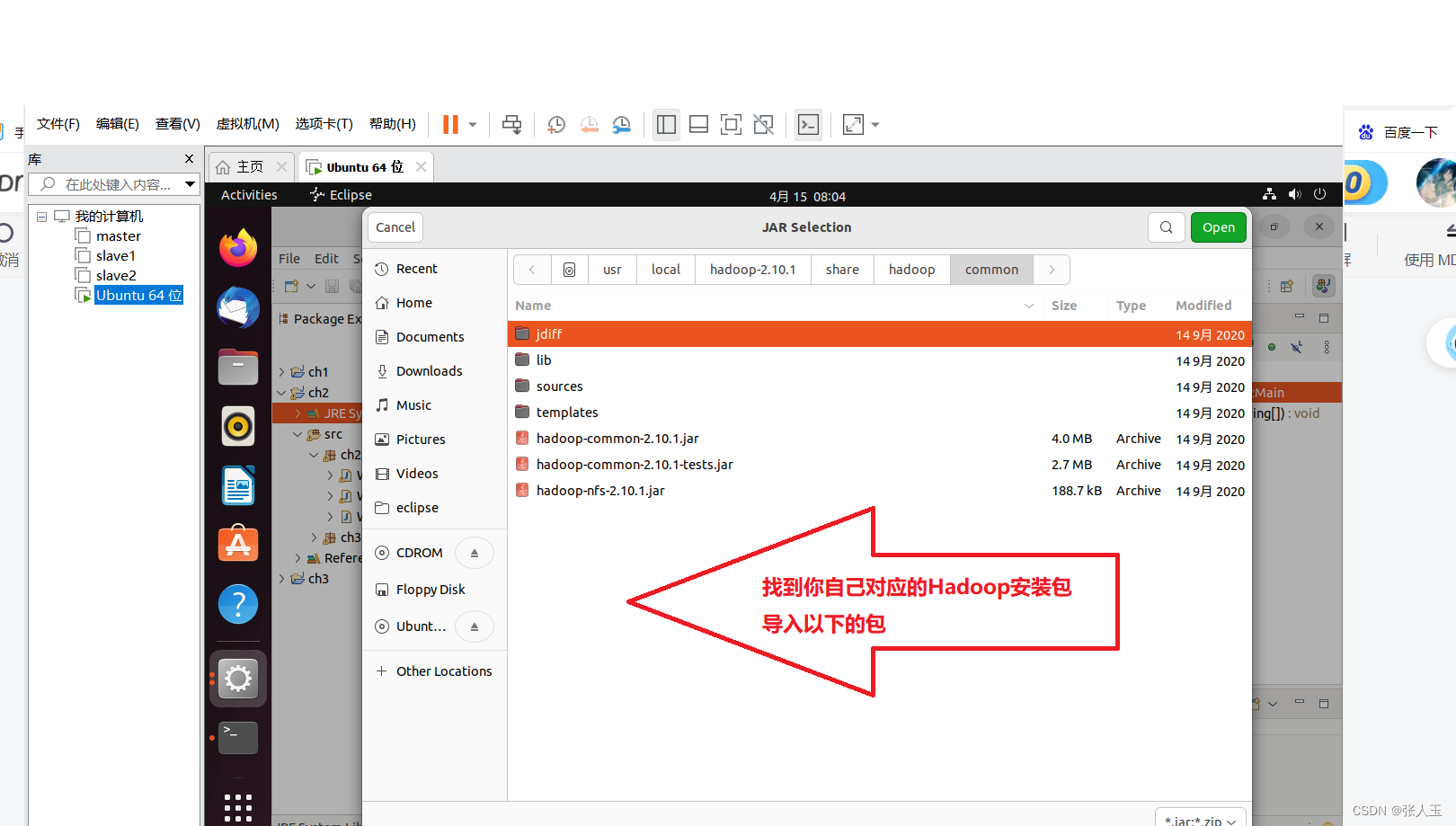
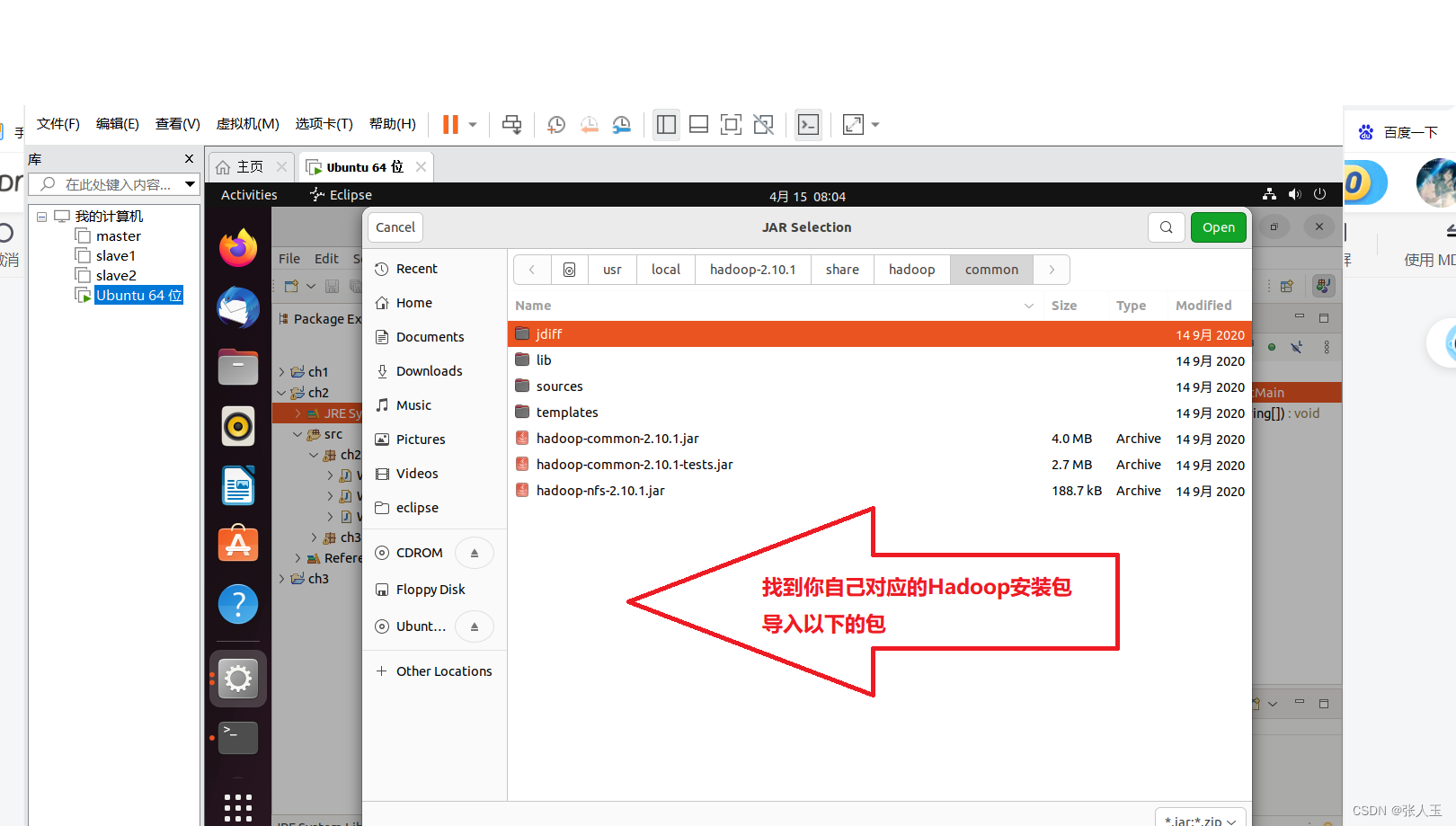
目录 Jar 包
/usr/local/Hadoop-2.10.1/share/hadoop/common hadoop-common-2.7.1.jar /haoop-nfs-2.7.1.jar
/usr/local/ hadoop-2.10.1/share/hadoop/common/lib 所有 Jar 包
/usr/local/hadoop-2.10.1/share/hadoop/hdfs haoop-hdfs-2.7.1.jar /haoop-hdfs-nfs-2.7.1.jar
/usr/local/hadoop-2.10.1/share/hadoop/hdfs/lib 所有 Jar 包
/usr/local/hadoop-2.10.1/share/hadoop/ mapreduce hadoop-mapreduce-client-core-2.10.1.jar
我们首先在eclipse上创建三个类
分别为 WordCountMapper 、WordCountReducer 、WordCountMain
代码如下
package ch2;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
String data = value1.toString();
String[] words = data.split(" ");
for(String w:words)
{
context.write(new Text(w),new LongWritable(1));
}
}
}
package ch2;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable,Text, LongWritable> {
@Override
protected void reduce(Text k3, Iterable<LongWritable> v3,Context context) throws IOException,InterruptedException {
long total = 0;
for(LongWritable v:v3)
{
total+=v.get();
}
context.write(k3, new LongWritable(total));
}
}
package ch2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain{
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
在eclipse内完成编写后,进行打包

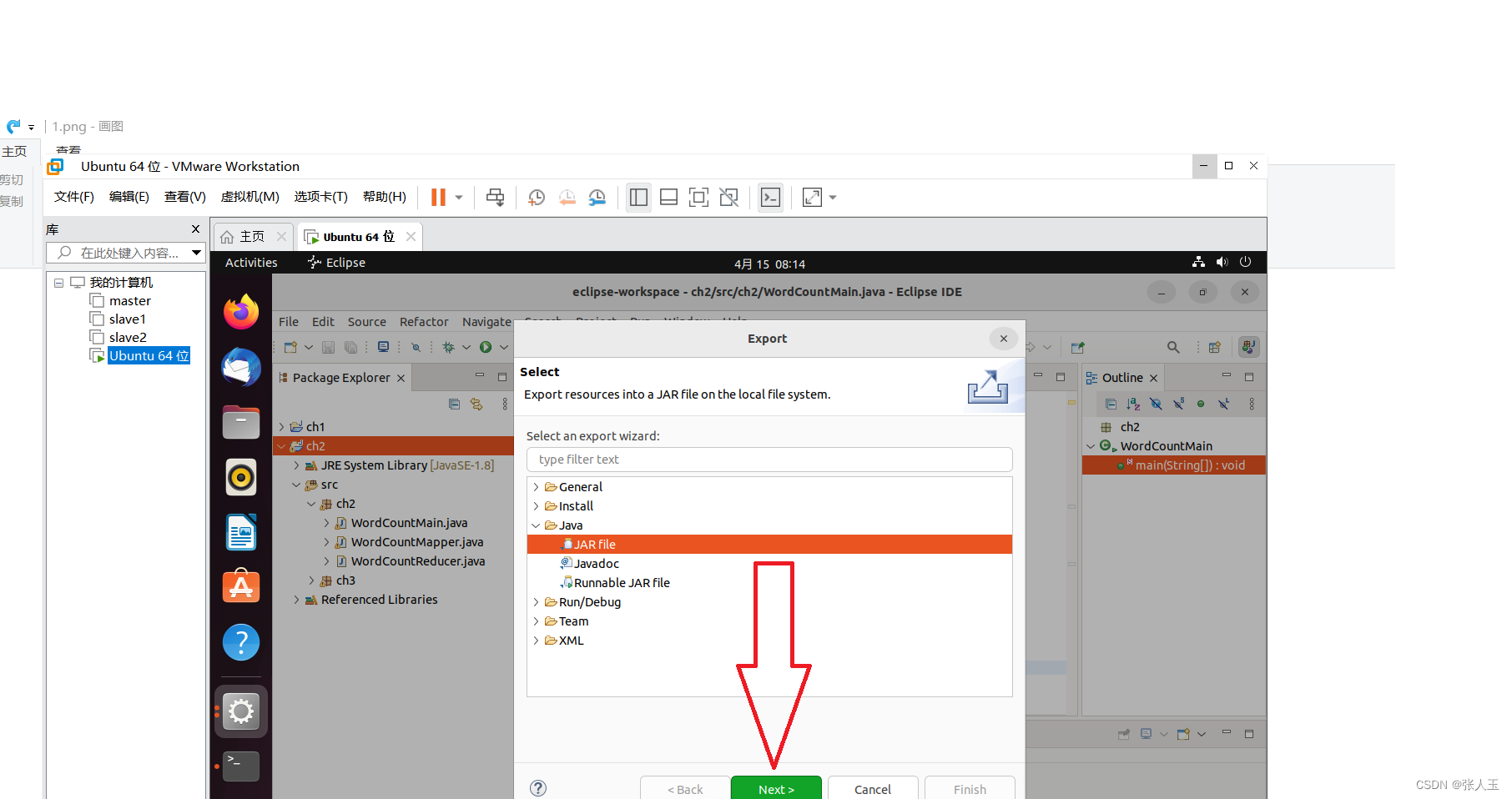
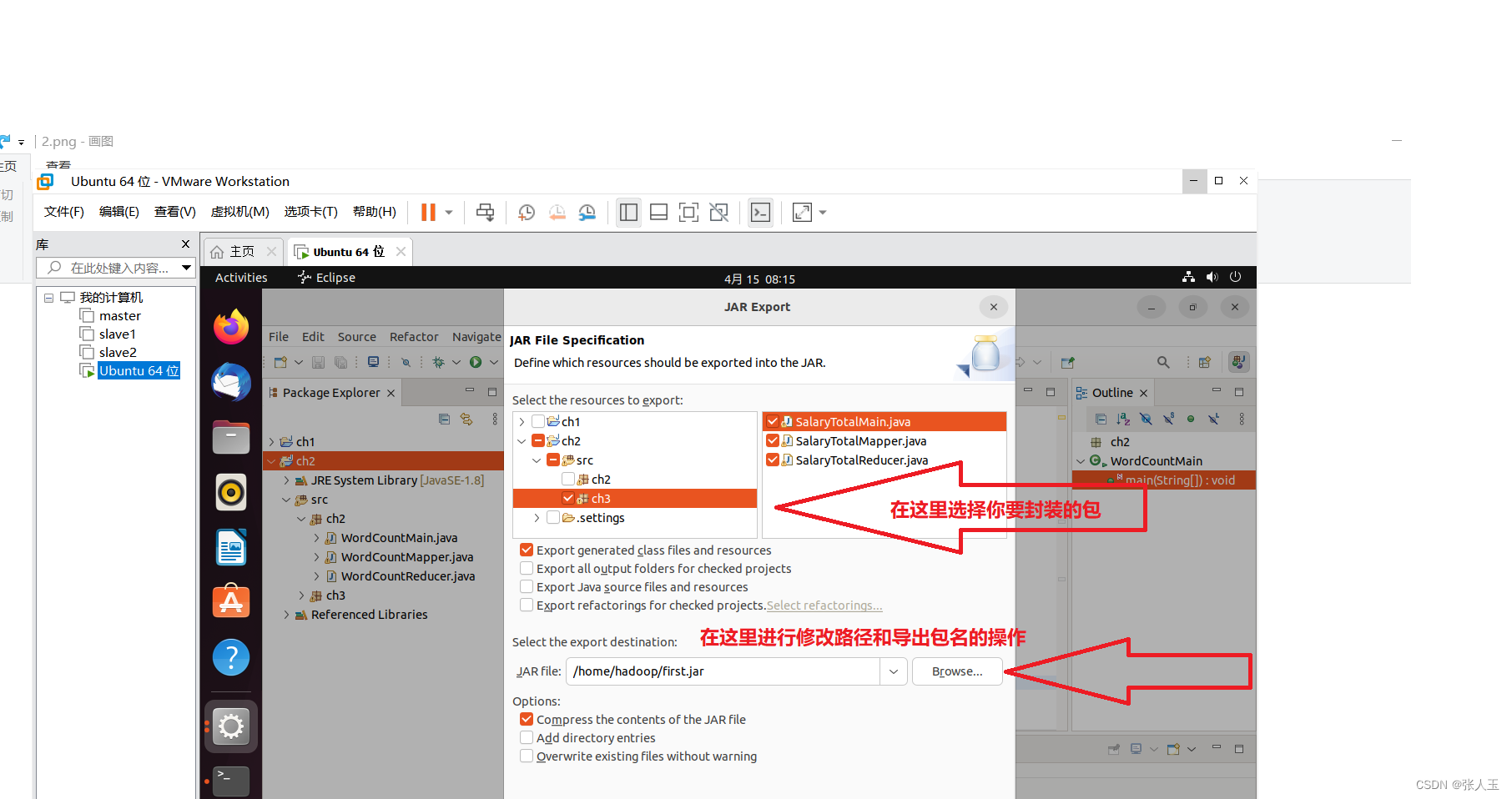
剩下的进行默认配置就可以了
完成之后,进入导出包的文件夹下查看,确定导出

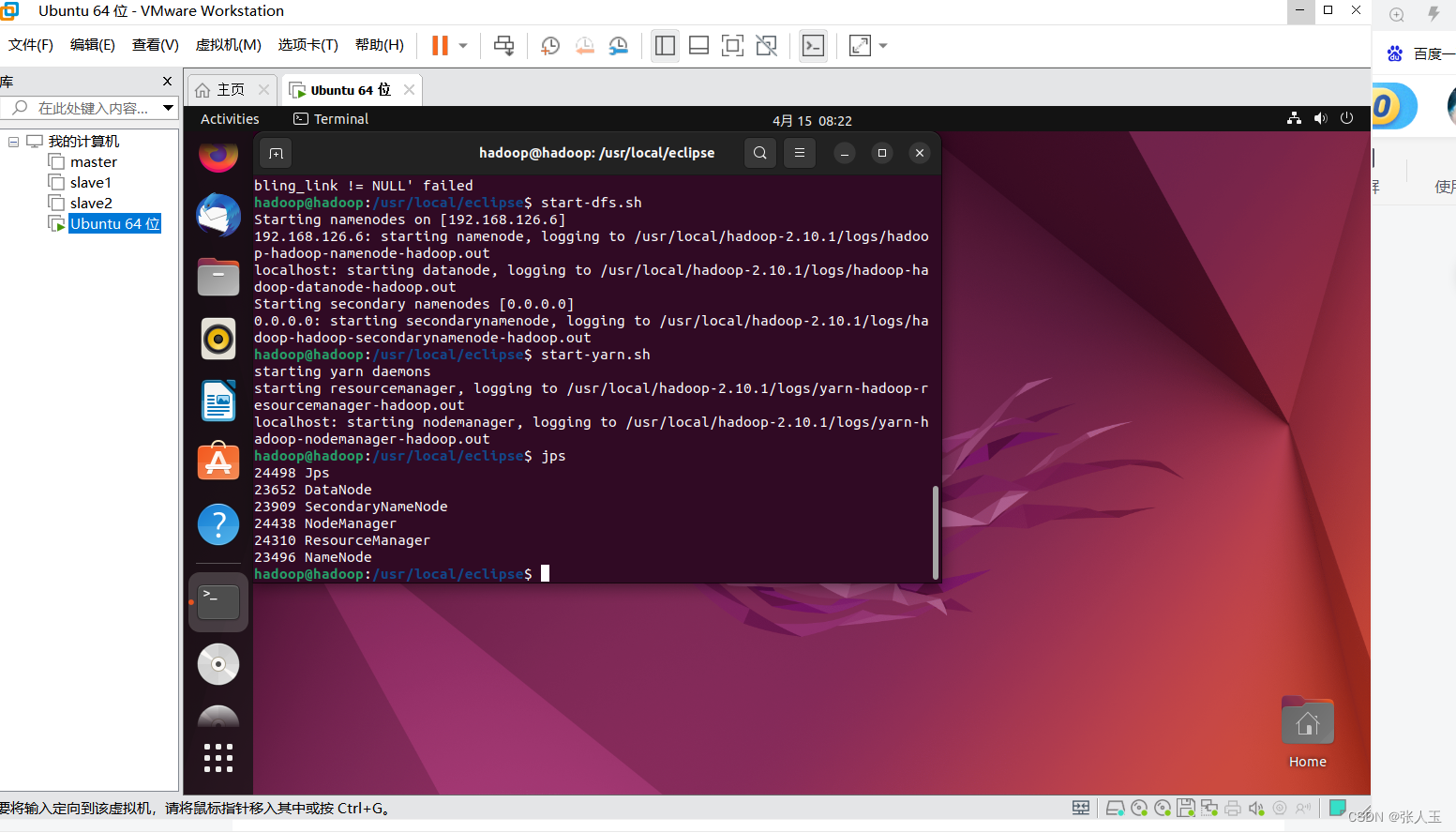
下面我们对要进行词频统计的文档进行上传
先启动dhfs和yarn
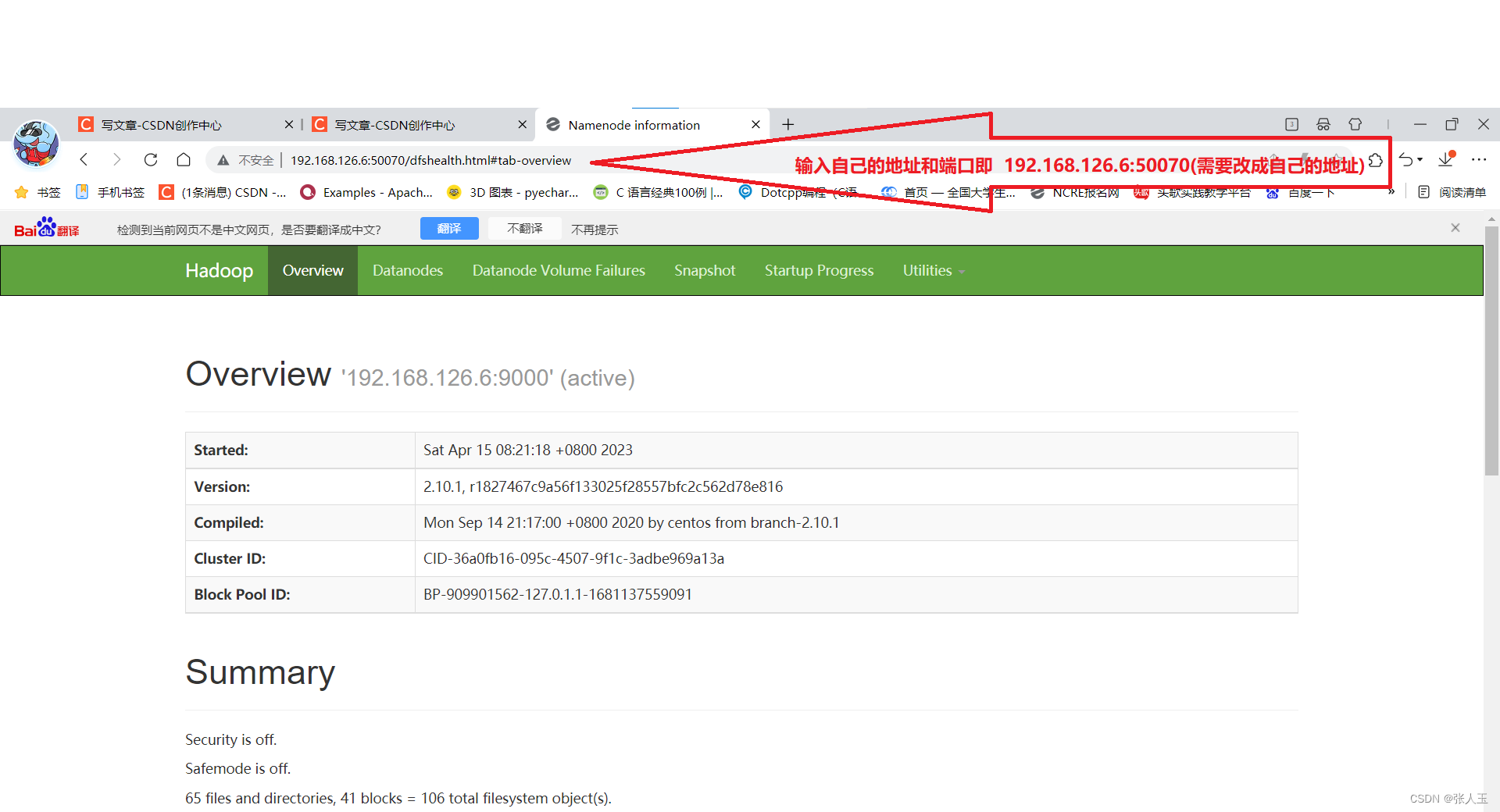
进入浏览器
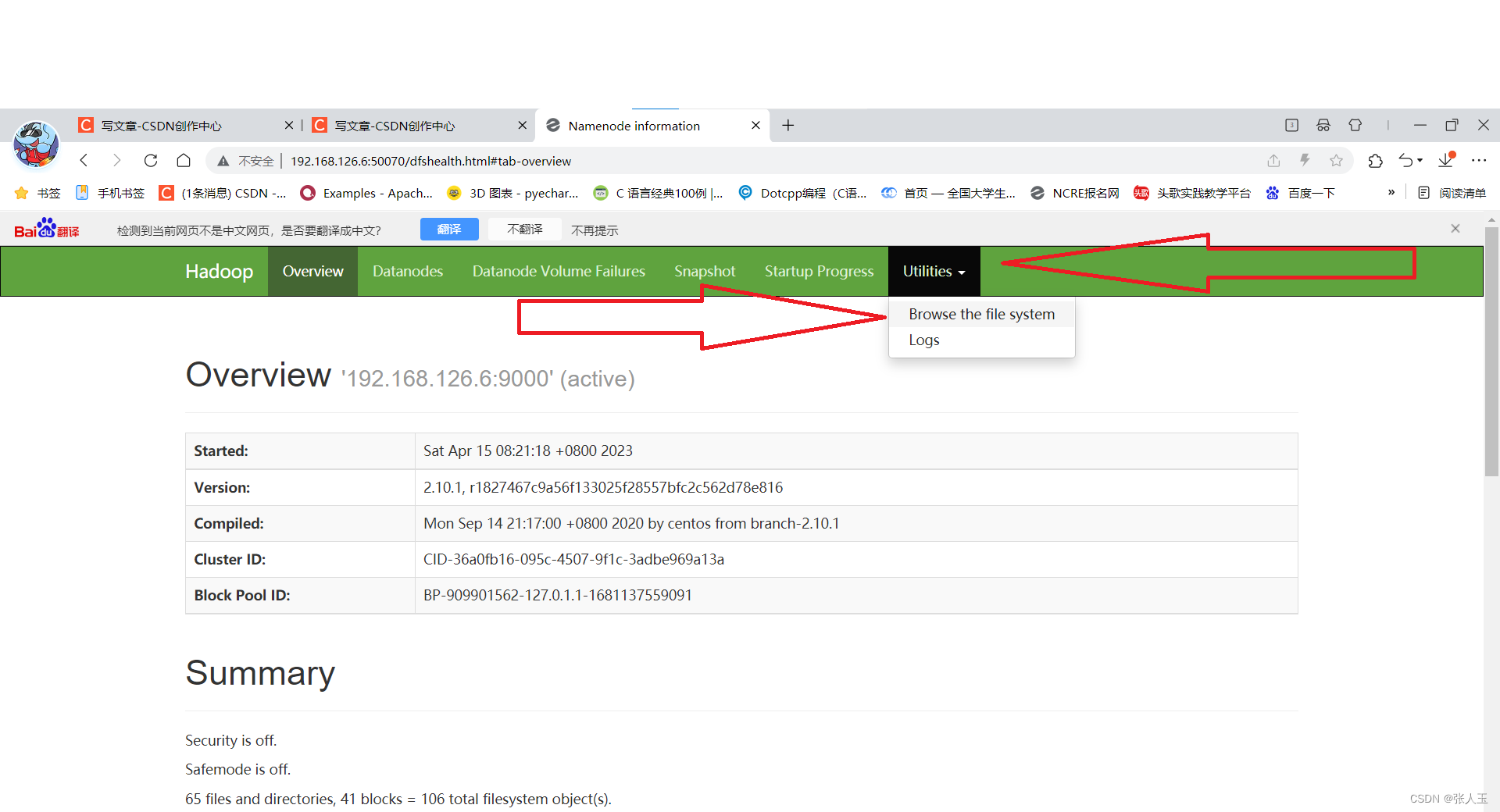
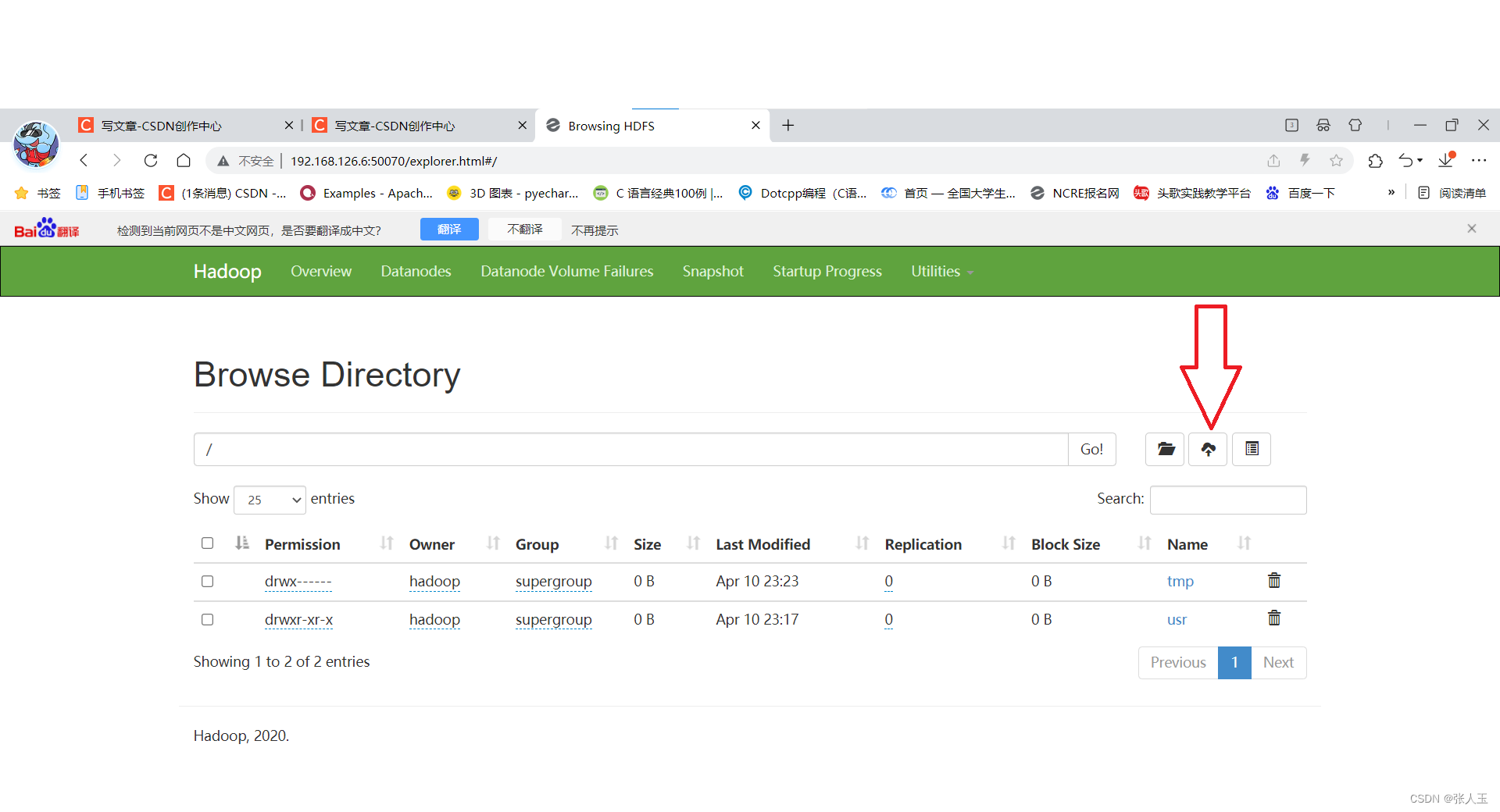

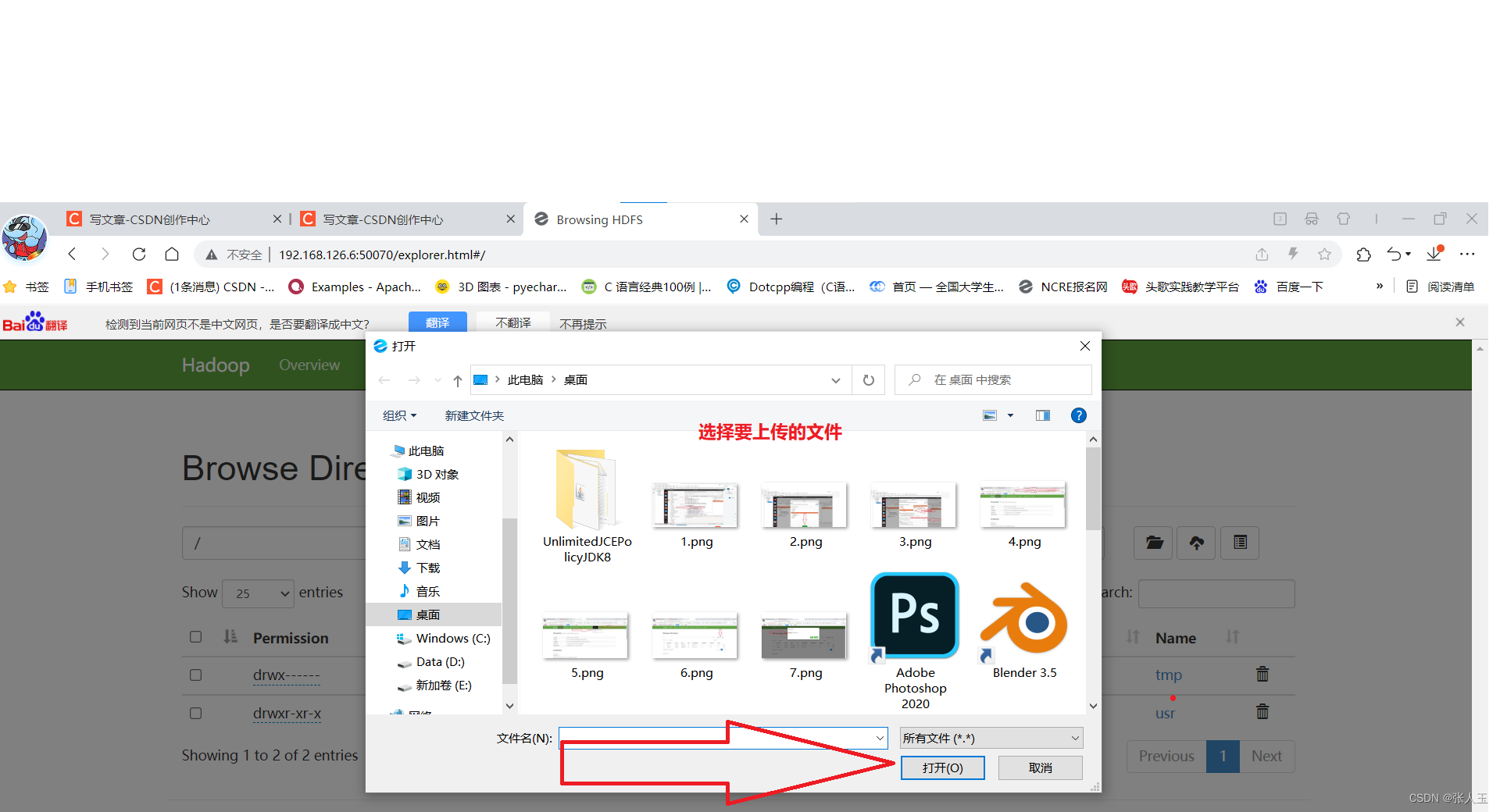
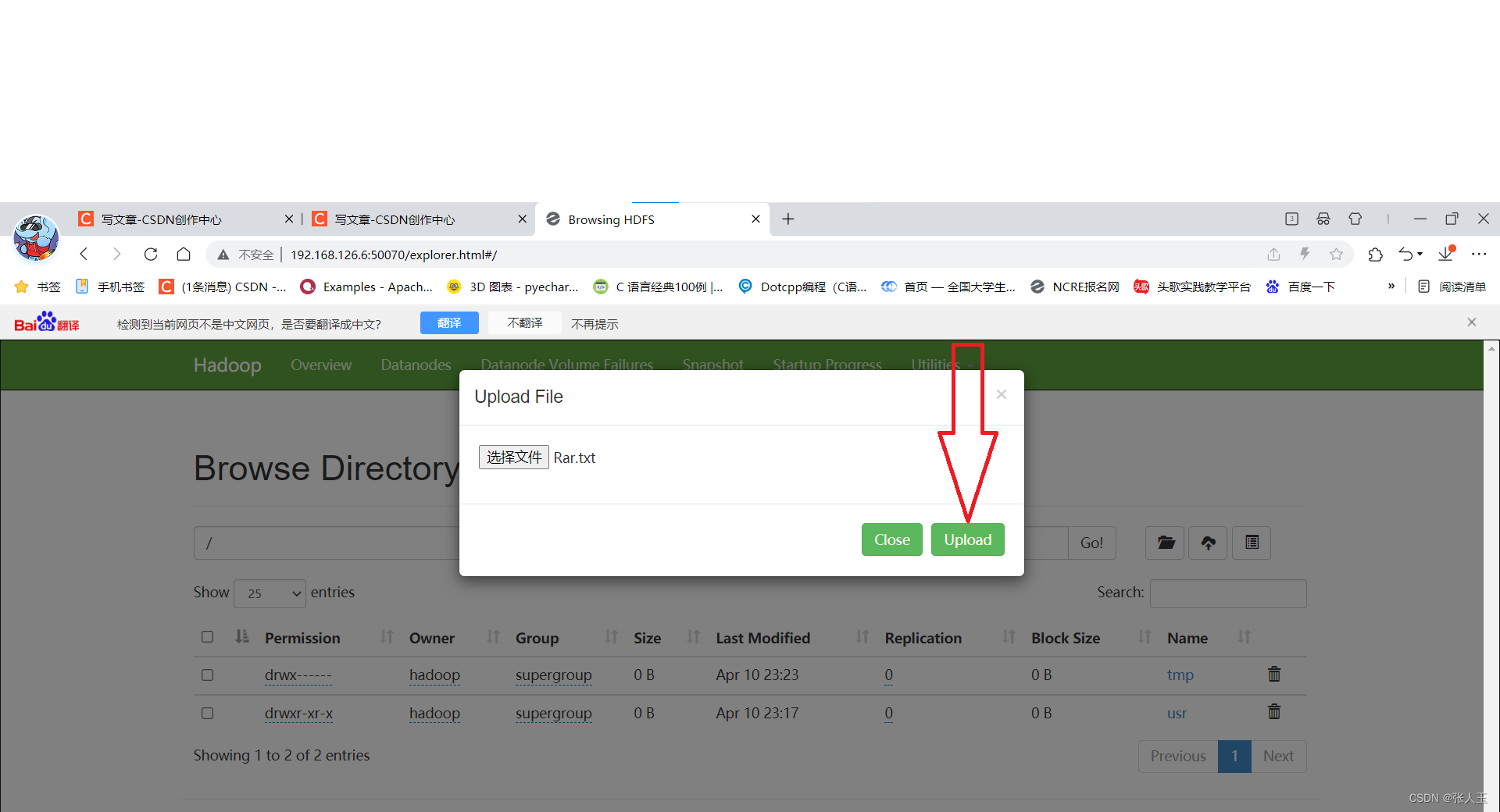
上传文件成功之后
在Ubuntu中进行命令
hadoop jar first.jar ch2.WordCountMain /usr/data/input/data.txt /usr/data/output/
hadoop jar 使用包的路径 包的主类 分析的文档的位置 文档导出的位置

在进入浏览器进行查询

出现part-r-00000即导出成功
可以下载到桌面上
进行查看
用记事本进行打开
 到这里词频统计就完成了
到这里词频统计就完成了

















 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











