







文章目录
注意:在写本文前,已经完成了三台机的Hadoop集群,desktop机已经配好了网络、yum源、关闭了防火墙等操作,详细请看本专栏第一、二篇
部署eclipse
1、创建hadoop用户
root@ddai-desktop:~# groupadd -g 285 hadoop
root@ddai-desktop:~# useradd -u 285 -g 285 -m -s /bin/bash hadoop
root@ddai-desktop:~# passwd hadoop
New password:
Retype new password:
passwd: password updated successfully
root@ddai-desktop:~# gpasswd -a hadoop sudo
Adding user hadoop to group sudo
2、配置文件
root@ddai-desktop:~# vim /home/hadoop/.profile
#添加,因暂时不会用到其他的,这里不加,后文会慢慢增加
export JAVA_HOME=/opt/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

3、上传eclipse压缩包到/root目录
用rz命令上传时可能会出现Waiting for cache lock: Could not get lock /var/lib/dpkg/lock-frontend. It is he
下面会出现process的进程,把它kill就行了


4、解压eclipse压缩包到/opt目录
root@ddai-desktop:~# cd /opt/
root@ddai-desktop:/opt# tar xzvf /root/eclipse-java-2020-06-R-linux-gtk-x86_64.tar.gz
5、上传hadoop-eclipse jar包
传到eclipse下面的plugins目录下(可以直接上传到plugins,也可以后期移过去)
root@ddai-desktop:~# cp hadoop-eclipse-plugin-2.7.2.jar /opt/eclipse/plugins/

6、安装JAVA
(办法1:自己安装;办法2:从Master节点复制JDK过来)
这里采取从master复制
需要对desktop做一次免密处理
hadoop@ddai-master:~$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub ddai-desktop

7、从ddai-master节点复制hadoop和jdk到ddai-desktop
root@ddai-desktop:~# scp -r hadoop@ddai-master:/opt/* /opt/

修改文件属性
root@ddai-desktop:~# chown -R hadoop:hadoop /opt/
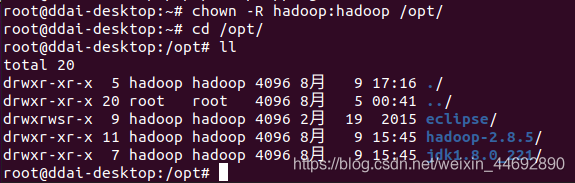
root@ddai-desktop:~# source /home/hadoop/.profile #让环境生效
8、运行eclipse
解决bug ignoring option PermSize=512m; support was removed in 8.0
其实我的问题主要是当时没有转换用户,我刚开始是以ddai-desktop用户登录的,然后su命令进行切换,此时的Hadoop是我用su命令切换来的,所有这样是没有权限的,要重新登录,以Hadoop用户登进去就行了,不存在它提示的那么复杂

reboot重启进入hadoop用户


把目录修改成workspace
9、检查mapreduce平台是否成功搭建

出现了这个选项表明插件安装成功

在file点击new project,出现了此选项也表明安装成功

词频统计实例
要先开启hadoop集群
1、建立两个有内容的文档
hadoop@ddai-desktop:~$ vim a1.txt
hadoop@ddai-desktop:~$ vim a2.txt
hadoop@ddai-desktop:~$ more a1.txt
Happiness is a way station between too much and too little.
hadoop@ddai-desktop:~$ more a2.txt
You may be out of my sight, but never out of my mind.
2、创建目录并上传数据
hadoop@ddai-desktop:~$ hdfs dfs -mkdir /test
hadoop@ddai-desktop:~$ hdfs dfs -put a*.txt /test

3、运行词频统计
注意:运行后的输出目录out1今后不能再使用,一个输出目录对应一个结果,除非把它删除,一个input只能存在最高需要运行的项目的文件,不能留其他东西,不然运行不出结果
adoop@ddai-desktop:~$ cd /opt/hadoop-2.8.5/share/hadoop/mapreduce/
hadoop@ddai-desktop:/opt/hadoop-2.8.5/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-2.8.5.jar wordcount /test /out1
#输出结果
21/08/10 10:58:49 INFO client.RMProxy: Connecting to ResourceManager at ddai-master/172.25.0.10:8032
21/08/10 10:58:50 INFO input.FileInputFormat: Total input files to process : 2
21/08/10 10:58:50 INFO mapreduce.JobSubmitter: number of splits:2
21/08/10 10:58:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1628563656760_0001
21/08/10 10:58:51 INFO impl.YarnClientImpl: Submitted application application_1628563656760_0001
21/08/10 10:58:51 INFO mapreduce.Job: The url to track the job: http://ddai-master:8088/proxy/application_1628563656760_0001/
21/08/10 10:58:51 INFO mapreduce.Job: Running job: job_1628563656760_0001
21/08/10 10:59:03 INFO mapreduce.Job: Job job_1628563656760_0001 running in uber mode : false
21/08/10 10:59:03 INFO mapreduce.Job: map 0% reduce 0%
21/08/10 10:59:16 INFO mapreduce.Job: map 100% reduce 0%
21/08/10 10:59:22 INFO mapreduce.Job: map 100% reduce 100%
21/08/10 10:59:23 INFO mapreduce.Job: Job job_1628563656760_0001 completed successfully
21/08/10 10:59:23 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=474853
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=314
HDFS: Number of bytes written=140
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=22182
Total time spent by all reduces in occupied slots (ms)=2871
Total time spent by all map tasks (ms)=22182
Total time spent by all reduce tasks (ms)=2871
Total vcore-milliseconds taken by all map tasks=22182
Total vcore-milliseconds taken by all reduce tasks=2871
Total megabyte-milliseconds taken by all map tasks=22714368
Total megabyte-milliseconds taken by all reduce tasks=2939904
Map-Reduce Framework
Map input records=2
Map output records=24
Map output bytes=210
Map output materialized bytes=232
Input split bytes=200
Combine input records=24
Combine output records=20
Reduce input groups=20
Reduce shuffle bytes=232
Reduce input records=20
Reduce output records=20
Spilled Records=40
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=878
CPU time spent (ms)=7150
Physical memory (bytes) snapshot=707117056
Virtual memory (bytes) snapshot=5784072192
Total committed heap usage (bytes)=473432064
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=114
File Output Format Counters
Bytes Written=140
4、查看统计结果
hadoop@ddai-desktop:~$ hdfs dfs -text /out1/part-r-00000

编写词频统计程序
创建项目
运行eclipse,选择菜单栏的“File”→“New”→“Other…”菜单项,选择“Map/Reduce Project”

输入项目名“WordCount”,选择“Configure Hadoop install directory…”

选择Hadoop安装目录,直接输入“/opt/hadoop-2.7.3”或者单击“Browse…”进行选择

点击finish,进入项目




创建WordCount.class,输入代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


hadoop@ddai-desktop:~$ hdfs dfs -mkdir /input
hadoop@ddai-desktop:~$ hdfs dfs -put a*.txt /input
运行

气象报告分析
下载气象数据文件到hadoop用户下
编写脚本,查找这两年的最高温度
hadoop@ddai-desktop:~$ vim max_temp.sh
#脚本
for year in 19*
do
echo -n $year "\t"
cat $year | \
awk '{temp=substr($0,88,5)+0;
q=substr($0,93,1);
if(temp!=9999 && q ~ /[01459]/ && temp > max) max=temp}
END {print max}'
done

编写代码实现
建立一个MaxTemp项目,并选择hadoop的路径

创建一个类

编写代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MaxTemp {
public static class TempMapper
extends Mapper<Object, Text, Text, IntWritable>{
private static int MISSING = 9999;
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15,19);//日期在15-19位
int airTemperature;
if (line.charAt(87) == '+') { // 判断正负号
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93); //质量代码
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
public static class TempReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: MaxTemp <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Max Temperature");
job.setJarByClass(MaxTemp.class);
job.setMapperClass(TempMapper.class);
job.setCombinerClass(TempReducer.class);
job.setReducerClass(TempReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hadoop@ddai-desktop:~$ hdfs dfs -put 19* /input
hadoop@ddai-desktop:~$ hdfs dfs -ls /input
需要把无关的文件删掉,不然无法统计


查看结果

















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











