






基于flask的气象数据可视化(含登录页面,数据连接到数据库,可实时更新,内涵python爬虫)
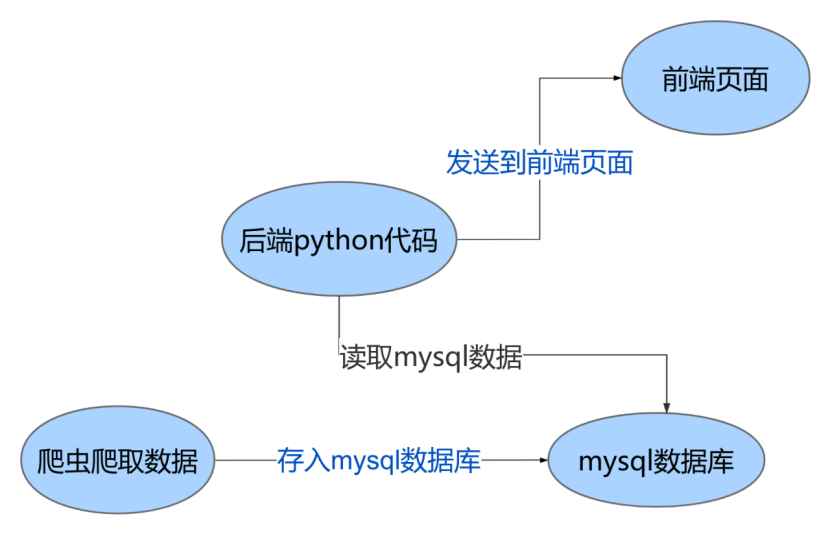
以下是基于 Flask 的气象数据可视化系统的综述,涵盖系统架构、核心功能模块及技术实现要点:
代码结构:
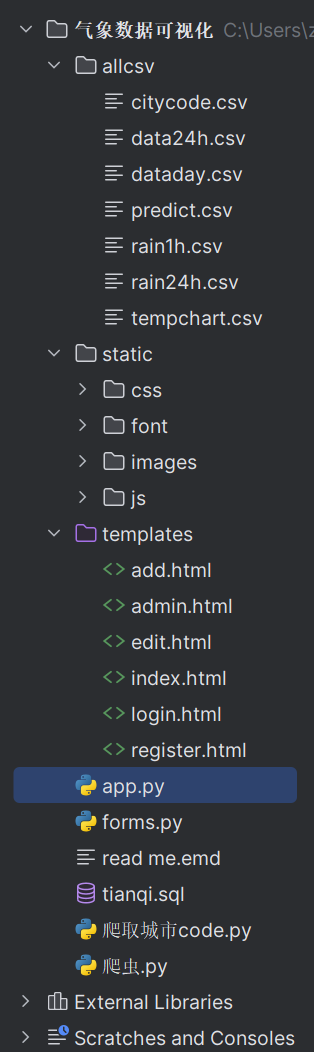
完整代码:
app.py
# app.py
from flask import Flask, render_template, redirect, url_for, flash
from config import Config
from models.models import db, User
from forms.forms import LoginForm, RegisterForm
from views.views import views_bp
import json
import pandas as pd
from flask import Flask, jsonify, render_template, redirect, url_for, session, flash,request
import pymysql
from pyspark.sql.types import StringType
from sqlalchemy import create_engine,text
import cpca
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField,PasswordField,ValidationError
from wtforms.validators import DataRequired,Length,Email,EqualTo,Regexp
def create_app():
app = Flask(__name__)
app.config.from_object(Config)
db.init_app(app)
with app.app_context():
db.create_all()
# 创建默认用户(如果不存在)
if not User.query.filter_by(username='admin').first():
user = User(username='admin', password='password') # TODO: Implement password hashing
db.session.add(user)
db.session.commit()
# 注册蓝图
app.register_blueprint(views_bp)
# 定义根路径路由,重定向到登录页面
@app.route('/')
def index():
return redirect(url_for('views.login'))
# 其他路由保持不变
@app.route('/quota')
def quota():
return render_template('quota.html')
@app.route('/trend')
def trend():
return render_template('trend.html')
@app.route('/chronic')
def chronic():
return render_template('chronic.html')
@app.route('/go_to_quota')
def go_to_quota():
return redirect(url_for('views.quota'))
@app.route('/go_to_trend')
def go_to_trend():
return redirect(url_for('views.trend'))
@app.route('/go_to_chronic')
def go_to_chronic():
return redirect(url_for('views.chronic'))
return app
app = create_app()
@app.route("/echart1")
def echart1():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
connection = engine.connect()
# 从数据库中读取数据
df = pd.read_sql(sql=text('SELECT 城市,风向,风速,时间 FROM 24h where 城市="北京"'), con=connection)
# 定义一个函数来将风向转换为文本
def get_wind_direction(x):
if (x > 337.5) or (x <= 22.5):
return "N"
elif (x > 22.5) and (x <= 67.5):
return "NE"
elif (x > 67.5) and (x <= 112.5):
return "E"
elif (x > 112.5) and (x <= 157.5):
return "SE"
elif (x > 157.5) and (x <= 202.5):
return "S"
elif (x > 202.5) and (x <= 247.5):
return "SW"
elif (x > 247.5) and (x <= 292.5):
return "W"
elif (x > 292.5) and (x <= 337.5):
return "NW"
else:
return None
df['风向'] = df['风向'].apply(get_wind_direction)
df['时间'] = df['时间']
print(df)
# 将 '时间' 列转换为时间戳
df['时间'] = pd.to_datetime(df['时间'])
df['时间'] = df['时间'].apply(lambda x: x.timestamp())
# 将三列数据组成一个数组
array = df[['时间', '风速', '风向']].to_numpy()
print(array)
# 渲染模板并传入图表对象
return jsonify(array.tolist())
@app.route("/echart2")
def echart2():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
query = "SELECT 温度,相对湿度 FROM 24h WHERE 城市='北京'"
df = pd.read_sql(sql=text(query), con=engine.connect())
array = df.values.tolist()
print(array)
return jsonify(array)
@app.route("/echart3")
def echart3():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
# 查询SQL语句
query = "SELECT 城市,日期,最高温度,最低温度 FROM tempchart where 城市='北京'"
# 使用pandas读取数据
df = pd.read_sql(sql=text(query), con=engine.connect())
# 转换日期格式
df['日期'] = pd.to_datetime(df['日期'], format='%Y-%m-%d')
# 筛选日期
df = df[df['日期'] < '2023-04-20']
# 提取数据
date = df['日期'].apply(lambda x: x.strftime('%Y-%m-%d')).tolist()
array1 = df['最高温度'].tolist()
array2 = df['最低温度'].tolist()
return jsonify({'date':date,'array1':array1,'array2':array2})
@app.route("/echart4")
def echart4():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
# 查询SQL语句
query = "SELECT 城市,日期,白天温度,夜晚温度 FROM predict where 城市='北京'"
# 使用pandas读取数据
df = pd.read_sql(sql=text(query), con=engine.connect())
df['日期'] = pd.to_datetime(df['日期'], format='%Y-%m-%d')
date = df['日期'].tolist()
array1 = df['白天温度'].tolist()
array2 = df['夜晚温度'].tolist()
return jsonify({'date': date, 'array1': array1, 'array2': array2})
@app.route("/echart5")
def echart5():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
# 从MySQL数据库中获取数据
query = "SELECT 城市,降雨量 FROM rain24h"
df = pd.read_sql(sql=text(query), con=engine.connect())
# 选取并显示前十个降雨量最高的城市
top_10_rainfall = df.sort_values('降雨量', ascending=False).head(10)
print(top_10_rainfall)
# 将城市和降雨量分别存储在列表中
city = top_10_rainfall['城市'].tolist()
array = top_10_rainfall['降雨量'].tolist()
return jsonify({'array':array,'city':city})
@app.route("/echart6")
def echart6():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
# 从MySQL数据库中获取数据
query = "SELECT 城市,降雨量 FROM rain1h"
df = pd.read_sql(sql=text(query), con=engine.connect())
# 选取并显示前十个降雨量最高的城市
top_10_rainfall = df.sort_values('降雨量', ascending=False).head(10)
print(top_10_rainfall)
# 将城市和降雨量分别存储在列表中
city = top_10_rainfall['城市'].tolist()
array = top_10_rainfall['降雨量'].tolist()
return jsonify({'array':array,'city':city})
# 编写将城市名称转换为省份名称的函数
def get_province(city):
location = cpca.transform([city])
return location.iloc[0]["省"]
@app.route("/echart7")
def echart7():
# 连接到MySQL数据库
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
# 从MySQL数据库中获取数据
query = "SELECT 城市,温度 FROM day"
df = pd.read_sql(sql=text(query), con=engine.connect())
print(df)
# 将 get_province() 函数应用于城市列,并添加省份列
df['province'] = df['城市'].apply(get_province)
# 根据省份列进行分组,并计算每个省份的平均温度
df = df.groupby('province')['温度'].mean().reset_index()
df.columns = ['province', 'avg(温度)']
# 将结果转换为键值对列表
array = df.to_dict('records')
array = [{'name': i['province'], 'value': round(i['avg(温度)'], 2)} for i in array]
print(array)
return jsonify(array)
if __name__ == '__main__':
app.run(debug=True)一、应用初始化与配置(create_app函数)
python
运行
def create_app():
app = Flask(__name__)
app.config.from_object(Config)
db.init_app(app)
with app.app_context():
db.create_all()
# 创建默认用户(如果不存在)
if not User.query.filter_by(username='admin').first():
user = User(username='admin', password='password') # TODO: Implement password hashing
db.session.add(user)
db.session.commit()
app.register_blueprint(views_bp)
@app.route('/')
def index():
return redirect(url_for('views.login'))
# 其他路由(/quota等)...
return app
分析:
-
应用工厂模式:
- 优点:通过
create_app封装应用创建逻辑,支持配置隔离(如开发 / 生产环境)。 - 问题:默认用户密码硬编码为
password,且未使用密码哈希(如bcrypt),存在严重安全隐患。 - 优化:
python
运行
from werkzeug.security import generate_password_hash user = User(username='admin', password=generate_password_hash('strong_password'))
- 优点:通过
-
蓝图注册:
- 优点:使用
views_bp蓝图组织路由,避免主文件臃肿。 - 问题:部分路由(如
/quota、/trend)直接定义在create_app中,未纳入蓝图,导致结构混乱。 - 优化:将所有页面路由移至蓝图文件(如
views.py),保持主文件简洁。
- 优点:使用
-
根路由重定向:
- 逻辑正确:访问根路径时重定向到登录页面,符合认证流程。
二、认证相关路由(未在代码中完全展示)
代码中通过 views_bp 蓝图处理登录 / 注册,但主文件未展示具体逻辑。需注意:
-
会话管理:
- 应使用
Flask-Login扩展管理用户会话,确保未登录用户无法访问受限页面(如/quota)。 - 缺失代码示例:
python
运行
from flask_login import login_required, current_user @views_bp.route('/quota') @login_required def quota(): return render_template('quota.html', user=current_user)
- 应使用
-
表单验证:
- 依赖
forms.forms中的LoginForm和RegisterForm,需确保表单字段包含数据验证(如邮箱格式、密码强度)。
- 依赖
三、数据可视化 API 路由(/echart1 至 /echart7)
共性问题:
-
数据库连接重复创建:
- 每个 API 路由均重新创建
engine = create_engine(...),浪费资源。 - 优化:在应用初始化时创建全局数据库连接,或使用 Flask-SQLAlchemy 的
db.session直接查询。
- 每个 API 路由均重新创建
-
SQL 查询硬编码:
- 查询条件如
WHERE 城市='北京'直接拼接字符串,存在 SQL 注入风险。 - 优化:使用 SQLAlchemy 的参数化查询或 Pandas 的
params参数:python
运行
# 错误示例(硬编码) df = pd.read_sql(sql=text("SELECT * FROM table WHERE 城市='北京'"), con=connection) # 正确示例(参数化) df = pd.read_sql(sql=text("SELECT * FROM table WHERE 城市=:city"), con=connection, params={'city': '北京'})
- 查询条件如
-
数据处理逻辑冗余:
- 多个路由中重复处理日期格式(如
pd.to_datetime)、分组聚合(如groupby),可封装为工具函数。
- 多个路由中重复处理日期格式(如
分路由分析:
1. /echart1(风速风向数据)
python
运行
@app.route("/echart1")
def echart1():
engine = create_engine('mysql+pymysql://root:mysql@127.0.0.1/tianqi')
connection = engine.connect()
df = pd.read_sql(sql=text('SELECT 城市,风向,风速,时间 FROM 24h where 城市="北京"'), con=connection)
def get_wind_direction(x): # 函数定义在路由内,可提取为全局工具函数
# ... 风向转换逻辑 ...
df['风向'] = df['风向'].apply(get_wind_direction)
df['时间'] = df['时间'].apply(lambda x: x.timestamp())
return jsonify(df[['时间', '风速', '风向']].to_numpy().tolist())
- 问题:
get_wind_direction函数嵌套在路由中,复用性差。- 返回数组结构(
[时间戳, 风速, 风向]),前端需解析字段顺序,可读性低。
- 优化:
返回对象数组(如[{"time": xxx, "speed": xxx, "direction": xxx}]),提高语义化。
2. /echart3(温度趋势数据)
python
运行
@app.route("/echart3")
def echart3():
query = "SELECT 城市,日期,最高温度,最低温度 FROM tempchart where 城市='北京'"
df = pd.read_sql(sql=text(query), con=engine.connect())
df = df[df['日期'] < '2023-04-20'] # 硬编码日期,无法动态查询
return jsonify({'date': date, 'array1': array1, 'array2': array2})
- 问题:
- 日期过滤条件硬编码为
'2023-04-20',无法通过参数动态调整。 - 字段名
array1、array2语义不明确,建议改为max_temp、min_temp。
- 日期过滤条件硬编码为
3. /echart7(省份温度平均值)
python
运行
@app.route("/echart7")
def echart7():
df = pd.read_sql("SELECT 城市,温度 FROM day", con=engine.connect())
df['province'] = df['城市'].apply(get_province) # 使用 cpca 库解析省份
df = df.groupby('province')['温度'].mean().reset_index()
return jsonify([{'name': p['province'], 'value': round(p['avg(温度)'], 2)} for p in df.to_dict('records')])
- 优点:
- 使用
cpca库解析城市对应的省份,实现数据聚合。
- 使用
- 问题:
cpca库依赖可能增加部署复杂度,且部分城市解析可能不准确(如直辖市)。
四、安全与性能优化
-
密码安全:
- 必须使用密码哈希(如
bcrypt),避免明文存储。
python
运行
from flask_bcrypt import Bcrypt bcrypt = Bcrypt(app) user.password = bcrypt.generate_password_hash('password').decode('utf-8') - 必须使用密码哈希(如
-
权限控制:
- 所有页面路由需添加
@login_required装饰器,确保未登录用户重定向到登录页。
- 所有页面路由需添加
-
数据库连接优化:
- 使用 Flask-SQLAlchemy 的
db.session执行查询,避免重复创建引擎:python
运行
from models.models import WeatherData # 假设存在气象数据模型 df = pd.read_sql(WeatherData.query.filter_by(城市='北京').statement, con=db.engine)
- 使用 Flask-SQLAlchemy 的
-
API 响应优化:
- 避免返回冗余数据(如
echart1中的城市字段已过滤为北京,可移除)。 - 对大数据量接口添加分页(如
limit、offset参数)。
- 避免返回冗余数据(如
五、代码规范与可维护性
-
导入语句混乱:
- 重复导入
from flask import Flask, ...,应整理导入顺序,避免冗余。
- 重复导入
-
函数命名不规范:
- 路由函数名(如
echart1)应更具描述性,如get_wind_speed_data。
- 路由函数名(如
-
缺少注释与文档:
- 关键逻辑(如数据转换、业务规则)未添加注释,影响后续维护。
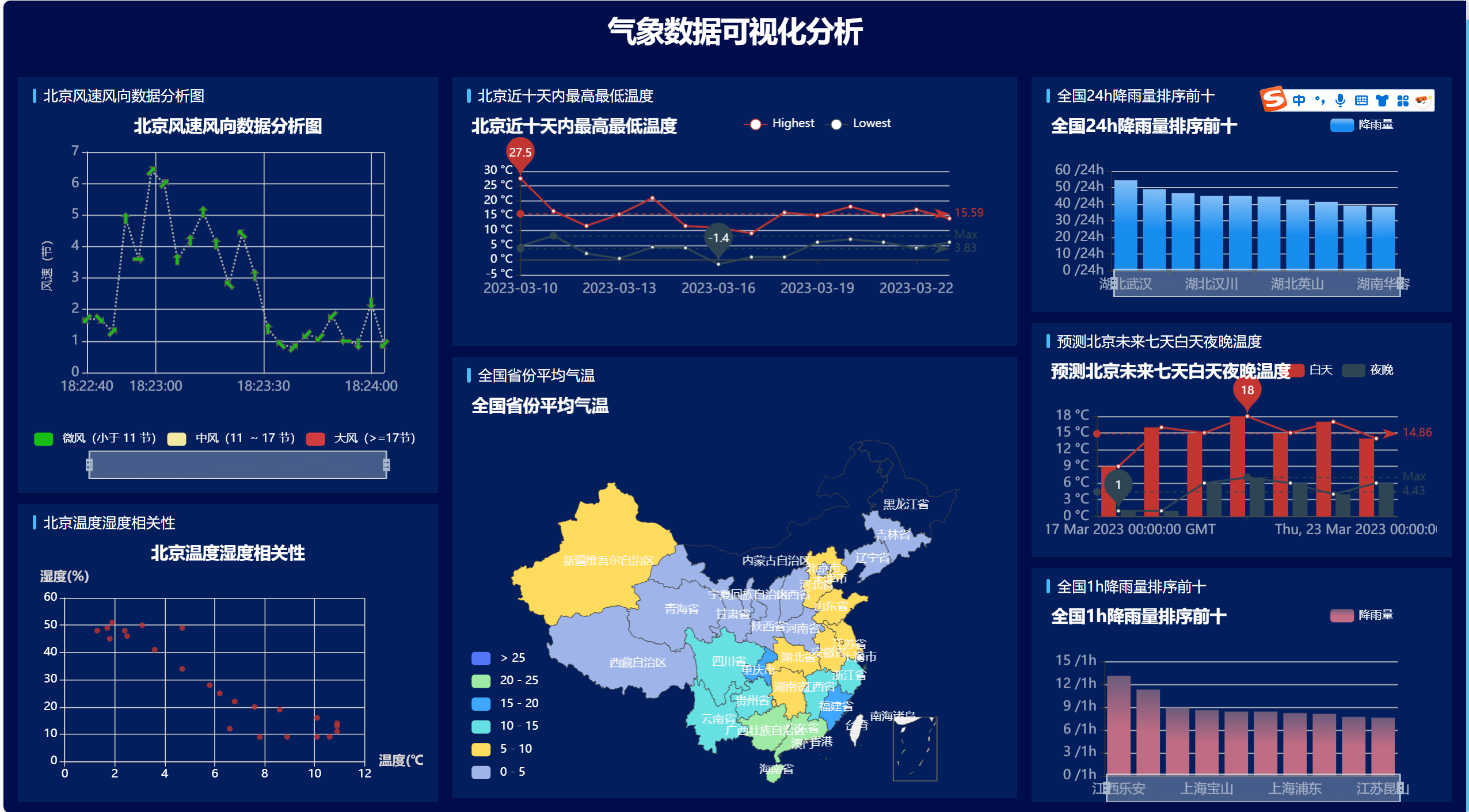
效果展示:



















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











