







今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
前言
在Java开发中,集合类是非常常用的一种数据类型。而集合类中的Set集合是一种不允许重复元素的集合。在Set集合中,除了HashSet和TreeSet之外,还有一种集合类叫做LinkedHashSet。本文将会介绍LinkedHashSet的概念,源代码解析,应用场景案例,优缺点分析,类代码方法介绍以及测试用例。
摘要
LinkedHashSet是一种Set集合类,它是HashSet和LinkedHashMap的结合体。它既有HashSet的快速查找和不允许重复元素的特性,又有LinkedHashMap的有序性和迭代器的快速遍历特性。因此,在需要保持元素顺序的情况下,我们可以使用LinkedHashSet。
LinkedHashSet
简介
LinkedHashSet是Java集合框架中Set接口的实现类,它继承自HashSet,并且实现了Set接口。LinkedHashSet底层是通过一个由链表和哈希表组成的数据结构来实现的。其中,链表用于保证元素插入的顺序,而哈希表用于保证元素的唯一性。
与HashSet相比,LinkedHashSet可以保证元素的插入顺序,这是因为LinkedHashSet内部维护了一个链表来记录元素的插入顺序。与TreeSet相比,LinkedHashSet的元素不是按照自然排序或者指定的Comparator排序,而是按照插入顺序排序。
源代码解析
LinkedHashSet的源代码中,我们可以看到它实现了Set接口,并且继承了HashSet类,HashSet又继承了AbstractSet类。而AbstractSet类实现了Set接口中的一些方法。
LinkedHashSet的构造函数如下:
public LinkedHashSet() {
super();
map = new LinkedHashMap<>();
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super();
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public LinkedHashSet(int initialCapacity) {
super();
map = new LinkedHashMap<>(initialCapacity);
}
public LinkedHashSet(Collection<? extends E> c) {
super();
map = new LinkedHashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
可以看到,LinkedHashSet提供了多个构造函数,允许用户指定不同的初始容量和负载因子。其中,最后一个构造函数会通过调用addAll方法来添加集合中的所有元素。
LinkedHashSet的主要方法如下:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
public Object clone() {
LinkedHashSet<?> clone = (LinkedHashSet<?>) super.clone();
clone.map = (LinkedHashMap<E,Object>) map.clone();
return clone;
}
其中,add方法和remove方法都是通过调用LinkedHashMap中的put方法和remove方法来实现的。LinkedHashMap的put方法和remove方法都是基于哈希表实现的,而又通过双向链表来维护元素的插入顺序。
除此之外,LinkedHashSet还实现了Set接口中的一些方法,如contains、isEmpty、size等方法,这些方法都是基于LinkedHashMap来实现的。LinkedHashSet还提供了迭代器、并发修改异常等特性。
如下是部分源码截图:

应用场景案例
-
维护元素的顺序: 在需要维护元素插入顺序的情况下,可以使用
LinkedHashSet。例如,在一个流式处理数据的应用中,需要对元素进行去重和排序操作。 -
避免并发修改异常: 在多线程程序中,使用
LinkedHashSet可以避免并发修改异常。例如,在一个多线程爬虫程序中,需要对爬取到的URL进行去重操作,就可以使用LinkedHashSet来避免并发修改异常。
优缺点分析
优点
-
LinkedHashSet支持元素的快速查找和不允许重复元素的特性。
-
LinkedHashSet具有有序性,可以保证元素的插入顺序。
-
LinkedHashSet内部维护了一个链表,可以利用迭代器快速遍历元素。
-
使用LinkedHashSet可以避免并发修改异常。
缺点
-
LinkedHashSet的性能比HashSet略低,因为LinkedHashSet需要维护链表。
-
LinkedHashSet相对于TreeSet来说,缺少排序功能。
类代码方法介绍
构造函数
public LinkedHashSet();
public LinkedHashSet(int initialCapacity);
public LinkedHashSet(int initialCapacity, float loadFactor);
public LinkedHashSet(Collection<? extends E> c);
- 构造函数可以指定不同的初始容量和负载因子。
基本方法
public boolean add(E e);
public boolean remove(Object o);
public void clear();
public Object clone();
-
add方法和remove方法都是通过调用LinkedHashMap中的put方法和remove方法来实现的。
-
LinkedHashSet的clone方法会返回一个包含当前元素的拷贝集合。
Set接口方法
LinkedHashSet实现了Set接口中的一些方法,如contains、isEmpty、size等方法。
迭代器
LinkedHashSet支持迭代器,它继承了HashSet的迭代器,而HashSet的迭代器又继承了AbstractSet的迭代器。
以下是一个通过迭代器遍历LinkedHashSet中元素的例子:
// 创建一个LinkedHashSet
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("orange");
// 创建迭代器
Iterator<String> iterator = set.iterator();
// 遍历元素
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
测试用例
测试代码
以下是一个使用LinkedHashSet的测试用例,该测试用例用于统计一段文本中每个单词出现的次数:
package com.example.javase.collection;
import java.util.LinkedHashSet;
import java.util.Scanner;
/**
* @Author ms
* @Date 2023-10-22 21:41
*/
public class LinkedHashSetTest {
public static void main(String[] args) {
// 读入文本
Scanner scanner = new Scanner(System.in);
String text = scanner.nextLine();
// 分割单词
String[] words = text.split("\\s+");
// 创建集合
LinkedHashSet<String> set = new LinkedHashSet<>();
// 统计每个单词出现的次数
int[] count = new int[words.length];
for (int i = 0; i < words.length; i++) {
if (!set.contains(words[i])) {
set.add(words[i]);
}
count[i] = 1;
for (int j = i + 1; j < words.length; j++) {
if (words[i].equals(words[j])) {
count[i]++;
}
}
}
// 输出结果
System.out.println("单词\t出现次数");
for (String word : set) {
int sum = 0;
for (int i = 0; i < words.length; i++) {
if (word.equals(words[i])) {
sum += count[i];
}
}
System.out.println(word + "\t" + sum);
}
}
}
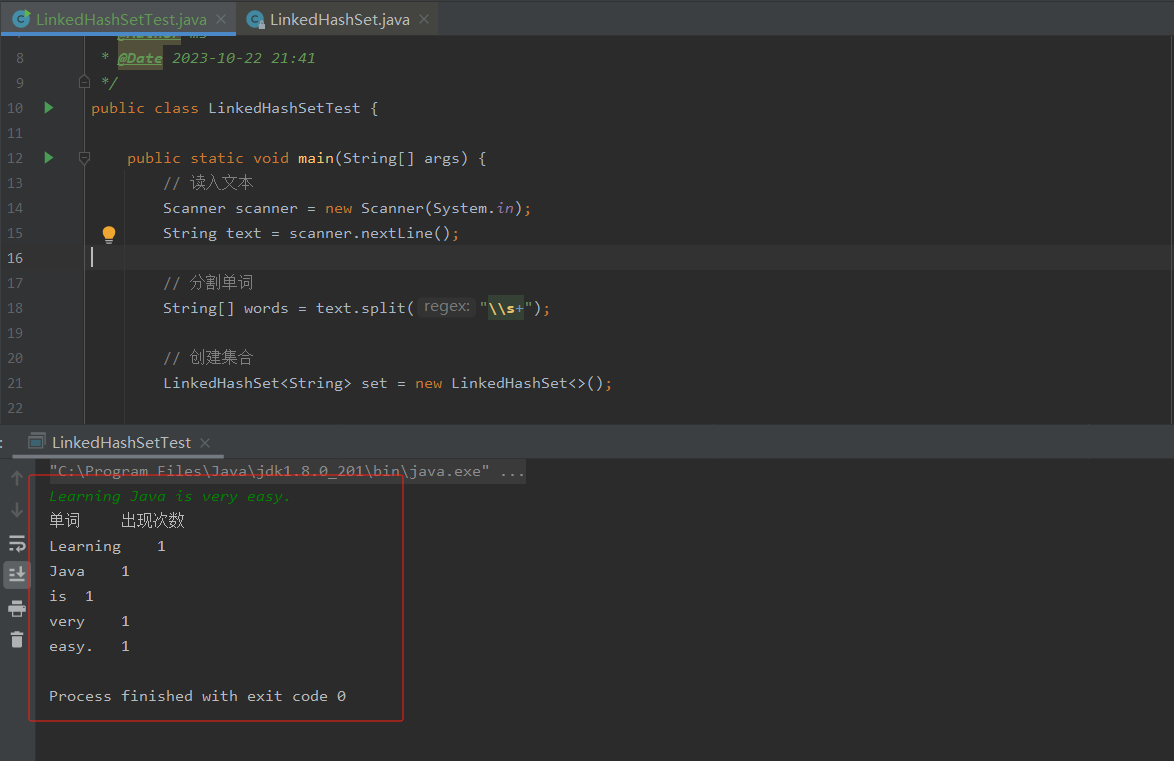
演示结果
根据如上测试用例,本地测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加更多的测试数据或测试方法,进行熟练学习以此加深理解。
代码分析
根据如上测试用例,在此我给大家进行深入详细的解读一下测试代码,以便于更多的同学能够理解并加深印象。这是一个使用 LinkedHashSet 统计给定文本中每个单词出现次数的程序。
首先通过 Scanner 读入文本,然后使用 split 方法将文本分割成单词数组。
接着创建一个 LinkedHashSet 集合,用于存储出现过的单词,并通过循环遍历单词数组,将每个单词存入集合中。
接下来,遍历单词数组,统计每个单词出现的次数。通过一个 count 数组记录每个单词的出现次数,count[i] 表示第 i 个单词的出现次数,初值为 1,然后再循环遍历之后的单词数组,如果找到了相同的单词,则将当前单词的出现次数加 1。
最后再次遍历集合中的每个单词,利用 count 数组计算每个单词出现的总次数,并输出结果。
全文小结
本文介绍了Java集合框架中的LinkedHashSet,包括概念、源代码解析、应用场景案例、优缺点分析、类代码方法介绍和测试用例。LinkedHashSet是一种既有HashSet的快速查找和不允许重复元素特性,又有LinkedHashMap的有序性和迭代器快速遍历特性的集合类。在需要保持元素顺序的情况下,我们可以使用LinkedHashSet。
总结
本文介绍了Java集合框架中的LinkedHashSet,它是一种既有HashSet的快速查找和不允许重复元素特性,又有LinkedHashMap的有序性和迭代器快速遍历特性的集合类。LinkedHashSet的底层是通过一个由链表和哈希表组成的数据结构来实现的,其中链表用于保证元素插入顺序,哈希表用于保证元素的唯一性。相比于HashSet,LinkedHashSet可以保证元素插入顺序;相比于TreeSet,LinkedHashSet的元素不是按照自然排序或者指定的Comparator排序,而是按照插入顺序排序。在需要维护元素插入顺序的情况下,我们可以使用LinkedHashSet。同时,使用LinkedHashSet可以避免并发修改异常。
… …
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
… …
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









