






文章目录
序列
- 序列是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个值的连续的内存空间。(存储地址)
列表
列表:用于存储任意数目、任意类型的数据集合。
| 方法 | 描述 |
|---|---|
| list.append(x) | 将元素x增加到列表list尾部 |
| list.extend(alist) | 将列表alist所有元素加到列表list尾部 |
| list.insert(index,x) | 在列表list指定位置index处插入元素x |
| list.remove(x) | 在列表list中删除首次出现的指定元素x |
| list.pop([index]) | 删除并返回列表list指定为止index出现的元素,默认是最后一个元素 |
| list.clear() | 删除列表所有元素,不是删除对象 |
| list.index(x) | 返回第一个x的索引位置,若不存在则抛出异常 |
| list.count(x) | 返回指定元素x在list中出现的次数 |
| len(list) | 返回列表中包含元素的个数 |
| list.reverse() | 所有元素原地翻转 |
| list.sort() | 所有元素原地排序 |
| list.copy() | 返回列表对象的浅拷贝 |
Python列表大小可变,根据需要随时增大或缩小
列表的创建
- 基本语法创建
a=[10,0,99,"good"]
a=[ ] #创建一个空的列表对象
- list创建
使用list()可以将任何可迭代的数据转化成列表
a=list() #创建一个空的列表对象
a=list("gaoqi")
- range()创建整数列表
语法格式为:range([start],end,[step])
start参数:可选,表示起始数字,默认数字为0
end参数:必选,表示结尾数字
step参数:可选,表示步长,默认为1
Python3中range()返回的是一个range对象,通过list方法转换成列表对象
list(range(10))
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list(range(0,10,3))
# [0, 3, 6, 9]
- 推导式生成列表
a=[x*2 for x in range(5)] #循环创建多个对象
#[0,2,4,6,8]
a=[x*2 for x in range[10] if x%9==0 ]#利用if过滤元素
#[0,18]
列表元素的增加
- append()方法
原地修改列表对象,是真正的列表尾部添加新的元素,速度最快
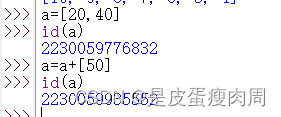
a=[20,40]
a.append(80)
- +运算符操作
并不是尾部添加元素,而是创建新的列表对象
- extend()方法
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象
a=[20,40]
a.extend([50])
- insert()插入元素
可以将指定元素插入到列表对象的任意制定位置,这样会让后面所有元素进行移动,影响处理速度。涉及大量元素,尽量避免使用。
a=[10,20,30]
a.insert(2,100)
- 乘法扩展(新列表元素是原列表元素的多次重复)
a=['sxt',100]
b=a*3
# b=['sxt',100,'sxt',100,'sxt',100]
列表元素的删除
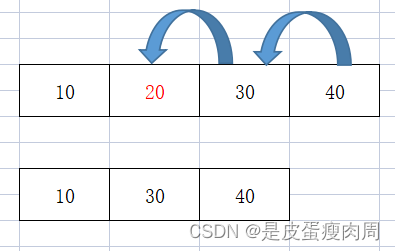
- del删除
删除列表指定位置的元素,相当于后面的元素往前移一位
a=[10,20,30,40]
del a[1]
- pop()方法
删除并返回指定位置的元素,如果未指定则默认操作列表的最后一个元素
a=[10,20,30]
a.pop() #结果:30
a.pop(1)#结果:20
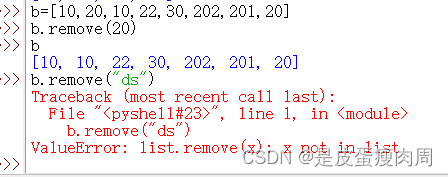
- remove()方法
删除首次出现的指定元素,如果没有则抛出异常
列表元素访问和计数
- 通过索引直接访问
- index()获得指定元素在列表中首次出现的索引
- count()出现的次数(通过count()可以判断该元素是否存在)
a=[10,20,30,20]
a.index(20)
#结果:1
a.count(20)
#结果:2
切片操作(slice)
标准格式:[起始偏移量:终止偏移量:步长]
- 典型操作(三个量均为正数)
| 操作和说明 | 示例和结果 |
|---|---|
| [:] 提取整个列表 | [10,20,30] [:] 结果: [10,20,30] |
| [start:] 从start索引到结尾 | [10,20,30] [1:] 结果:[20,30] |
| [:end] 从头开始直到end-1 | [10,20,30] [:2] 结果:[10,20] |
| [start:end] 从start到end-1 | [10,20,30,40] [1:3] 结果:[20,30] |
| [start🔚step] 从start提取到end-1,步长step | [10,20,30,40,50,60,70] [1,6,2] 结果:[20,40,60] |
- 其他操作(三个量为负数)
| 示例 | 说明和结果 |
|---|---|
| [10,20,30,40,50,60,70] [-3:] | 倒数三个 [50,60,70] |
| [10,20,30,40,50,60,70] [-5:-3] | 倒数第五个到倒数第三个(包头不包尾) [30,40] |
| [10,20,30,40,50,60,70] [ :: -1] | 步长为负,从右到左反向提取 [70,60,50,40,30,20,10]] |
列表排序
- 修改原列表,不建新列表的排序(调用列表对象的方法)
a.sort() #默认为升序排列
a.sort(reverse=True) #降序排列
a=[1,3,2,5]
import random
random.shuffle(a) #打乱顺序
- 建新列表的排序(通过内置函数sorted()进行排序)生成新对象
a=[1,3,5,2,9]
a=sorted(a) #默认升序
- reversed()返回迭代器
reversed()支持逆序排列,只能用一次,返回迭代器对象
a=[20,10,30,40]
c=reversed(a)
list(c)
max()返回最大值
min()返回最小值
sum()求和,对于非数值型运算会报错
多维列表
a=[]
a=[
["高小一",18,3000,"北京"],
["高小二",19,2000,"上海"],
["高小五",20,1000,"深圳"]
]
print(a)
#[['高小一', 18, 3000, '北京'], ['高小二', 19, 2000, '上海'], ['高小五', 20, 1000, '深圳']]
print(a[0])
#['高小一', 18, 3000, '北京']
print(a[0][3])
#'北京'
- 遍历二维列表
a=[
["高小一",18,3000,"北京"],
["高小二",19,2000,"上海"],
["高小五",20,1000,"深圳"]
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行换行
元组tuple
列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的元素。
元组的创建
- 通过()创建,小括号可以省略
如果元组只有一个元素,则必须后面加逗号。这是因为解释器会把(1)解释为整数1,(1,)解释为元组
a=(1,) #或者 a=1,
type(a)
- 通过tuple()创建元组
b=tuple() #创建一个空元组对象
b=tuple("abc")
b=tuple(range(3))
b=tuple([1,"2"])
元组元素访问和计数
- 元组的元素访问和列表一样,只不过返回的还是元组
- 元组排序只能使用内置函数sorted(tupleObj),生成新的列表对象
生成器推导式创建元组
zip
zip(列表1,列表2,…)将多个列表对应的元素组合成元组,并返回这个zip对象
a=[10,20,30]
b=[40,50,50]
d=zip(a,b)
print(d)
#<zip object at 0x000001821119C380>
list(d)
#[(10, 40), (20, 50), (30, 50)]
字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含“键对象”和“值对象”。可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。
字典的创建
- 通过{}、dict()创建字典对象
a={"name":"gaoqi","age":18}
b=dict(name="gaoqi",age=18)
c=dict([("name","gaoqi"),("age",18)])
- 通过zip()创建字典对象
a=["name","age"] #key
b=["gaoqi",18] #value
c=dict(zip(a,b))
- 通过fromkeys创建值为空的字典
a=dict.fromkeys(["name","age"])
元素访问
测试方便,这里设定一个字典对象:
a={“name”:“gaoqi”,“age”:18,“job”:“programmer”}
-
通过[键]获得“值”,若键不存在,则抛出异常

-
通过get()方法获得“值”。推荐使用。优点是:指定键不存在,返回None,也可以设定指定键不存在时默认返回的对象。
a.get("name")
#结果:'gaoqi'
print(a.get("gaoqi"))
#结果:None
a.get("gaoqi","一个男人")
#结果:一个男人
- 列出所有的键值对
a.items()
#dict_items([('name', 'gaoqi'), ('age', 18), ('job', 'programmer')])
- 列出所有的键,列出所有的值
a.keys()
#dict_keys(['name', 'age', 'job'])
a.values()
#dict_values(['gaoqi', 18, 'programmer'])
- len()键值对的个数
len(a)
- 检测一个“键”是否在字典中
"name" in a
# True
字典元素添加、修改、删除
- 给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对,如果不存在,则新增“键值对”
a["address"]="北京"
a["age"]=16
- 使用update()将新字典中所有键值对全部添加到旧字典对象上。如果key有重复。则直接覆盖
a={"name":"gaoqi","age":18,"job":"programmer"}
b={"name":"gaoxixi","money":1000,"sex":"男的"}
a.update(b)
print(a)
#{'name': 'gaoxixi', 'age': 18, 'job': 'programmer', 'money': 1000, 'sex': '男的'}
- 字典中元素的删除,可以使用del()方法;或者clear()删除所有键值对;pop()删除指定键值对,并返回对应的“值对象”
a={"name":"gaoqi","age":18,"job":"programmer"}
del(a["name"])
print(a)
#{'age': 18, 'job': 'programmer'}
b=a.pop("age")
print(b)
#18
print(a)
#{'job': 'programmer'}
a.clear()
print(a)
#{}
- popitem():随机删除和返回该键值对。字典是“无序可变序列”,因此没有第一个元素、最后一个元素的概念;popitem弹出随机的项,因为字典没有“最后的元素”或者其他有关顺序的概念。
a={"name":"gaoqi","age":18,"job":"programmer"}
a.popitem()
#('job', 'programmer')
print(a)
#{'name': 'gaoqi', 'age': 18}
a.popitem()
#('age', 18)
print(a)
#{'name': 'gaoqi'}
序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值。
x,y,z=(10,20,30)
- 序列解包用于字典时,默认对“键”进行操作;如果需要对"键值对",使用items();如果需要对“值”进行操作,使用values()
a={"name":"gaoqi","age":18,"job":"programmer"}
x,y,z=a
print(x)
# 'name'
e,d,f=a.values()
print(e)
# 'gaoqi'
h,i,j=a.items()
print(h)
# ('name', 'gaoqi')
- 表格数据使用字典和列表存储,并实现访问
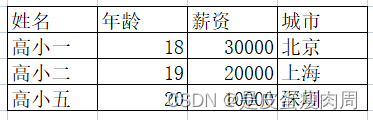
r1={"name":"高小一","age":18,"salary":30000,"city":"北京"}
r2={"name":"高小二","age":19,"salary":20000,"city":"上海"}
r3={"name":"高小五","age":20,"salary":10000,"city":"深圳"}
tb=[r1,r2,r3]
#获得第二行人的薪资
print(tb[1].get("salary"))
#打印表中的所有人的薪资
for m in range(len(tb)):
print(tb[m].get("salary"),end="\n")
#打印表的所有数据
for m in range(len(tb)):
print(tb[m].get("name"),tb[m].get("age"),tb[m].get("salary"),tb[m].get("city"),end="\n")















 2479
2479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









