






1、 集合
1.1 什么是集合
集合相当于将一堆类整合到一个对象中,有一点类似于数组
1.2 为什么学习集合
有数组了为什么要学习集合?
1、数组会根据他的申明时固定的长度决定他的最大长度。
//此时array的长度就是5 int[] array=int[5];
2、数组只可以存在单独的一个数据类型
//此时array只可以存放int数据 int[] array=int[5];
而集合不同,集合可以进行自动的扩容,并且集合可以存放多种类型的数据。
1.3 常用集合包括,如图:
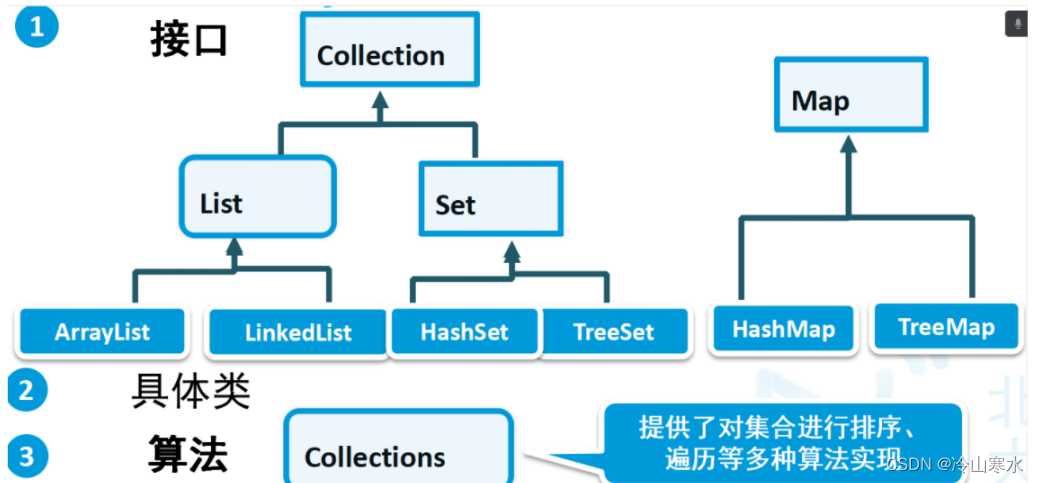
接口层:
Collection接口
-List接口
-Set接口
//List和Set接口继承了Collection接口
Map接口
具体类:
List接口:
-ArrayList
-LinkedList
Set接口:
-HashSet
-TreeSet
Map接口:
-HashMap
-TreeMap
算法类:
Collections
Arrays
1.4 四个大接口的作用于不同
Collection 接口存储一组 不唯一,无序的对象
List 接口存储一组不唯一,有序(插入顺序)的对象
不唯一:说明可以重复
有序
Set 接口存储一组唯一,无序的对象
唯一:说明不能重复
无序
Map 接口存储一组键值对象,提供key到value的映射。
关于map的特点如下图
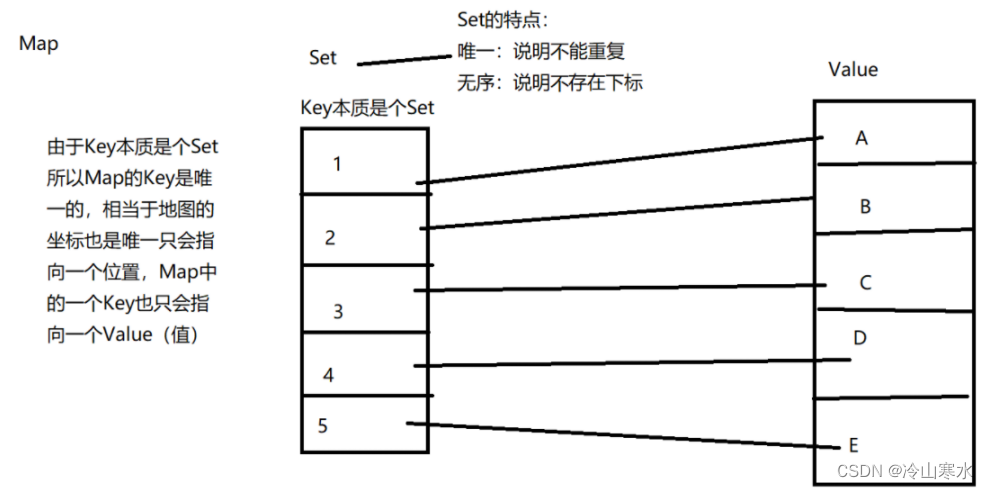
如果用身份证和人名的关系来进行比较的话
Key一定是身份证,因为身份中不可以重复
Value是人名,一个身份证号只会对应一个人,一个人只会有一个名字,就算你可以改名字,但是你同时只会有一个名字,这个名字是有可能和别的身份证号指向的名字相同的,这是正常的,Map也是如此。不同的Key可能会指向相同的value
2、 List
2.1 ArrayList
ArrayList,数组集合,他是通过Array——一维对象数组来实现关于List的可重复和有序。
由于ArrayList是存放对象数据,众所周知,基本数据类型不属于对象,基本数据类型是不继承Object的。所以,我们需要吧基本数据类型转化成对象,我们采用的是包装类,包装类内容见后续
import java.util.Arrays;
public class MyArrayList {
//定义默认长度的一个常量值
private static final int DEFAULT_CAPACITY=10;
//存储核心数据,对象数组
private Object[] elementData;
//可以存储当前真实数据长度的值
private int size;
//无参构造方法,用于初始化MyArrayList
public MyArrayList(){
//初始化大小为0
this.size=0;
//初始化对象数组——
this.elementData =new Object[DEFAULT_CAPACITY];
}
//有参构造,允许修改默认的数组长度
public MyArrayList(int myCapacity){
this.size=0;
//有参构造和无参的区别是在于确定对象的初始化对象数组长度
this.elementData=new Object[myCapacity];
}
//增加方法
public boolean add(Object obj){
//再新增之前我们需要判断当前的数组长度是否允许新增对象
ensureInternal(size+1);
//进行两步,将我们需要插入的obj都西昂插入到当前数组的末尾,
elementData[size++]=obj;
return true;
}
//获取值
public Object get(int index){
return elementData[index];
}
//获取当前元素的真实长度
public int getSize(){
return this.size;
}
//删除元素
public boolean remove(int index){
//不需要考虑缩容的问题
//将当前位置之后的所有元素向前移动一位,最后将末尾的元素移除
for(int i=index;i< elementData.length-1;i++){
elementData[i]=elementData[i+1];
}
//删除末尾元素
elementData[--size]=null;
return true;
}
//判断是否需要扩容,参数为当前最小的允许长度
private void ensureInternal(int minCapacity) {
//如果我们需要的最小容量大于了我们的数组长度,那么我们需要将数组扩容
if (minCapacity - elementData.length > 0) {
//扩容方法
grow(minCapacity);
}
}
private void grow(int minCapacity){
int oldCapacity = elementData.length;
//新的长度为原本长度的1.5倍,使用位移运算,计算机的运算效率比使用乘法高
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (minCapacity - newCapacity > 0) {
//说明当前的扩容长度不够,依旧不能满足我们的要求
//直接将目标长度编程当前需要的最小长度
newCapacity = minCapacity;
}
//复制我们的原本内容到新的长度数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
}2.2 LinkedList
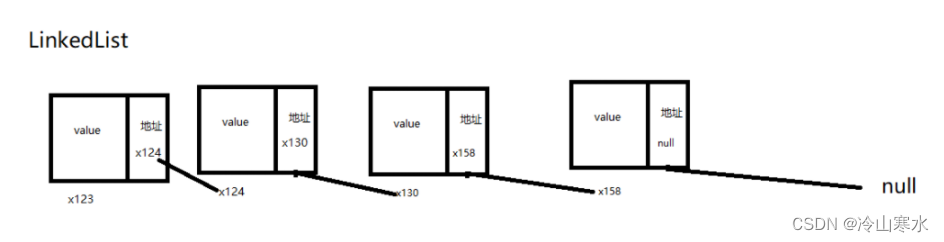
LinkedList,链表通过链表数据结构新增一个Node类,将值存储在Node的属性Object value中,再将他的下一个元素存储在Node的属性Node next中,从而实现链结构,并且由于他是存储了自己的下一个元素,所以他满足了List的有序要求,由于他的Object是可以重复存储相同的值,所以他实现了List的不唯一这个特点。
首次在实例化的LinkedList中新增元素
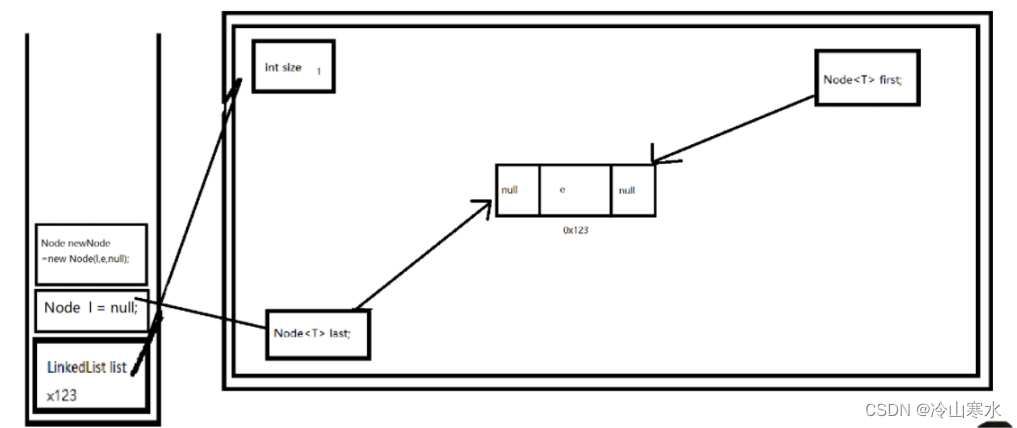
第二次在LinkedList中增加元素
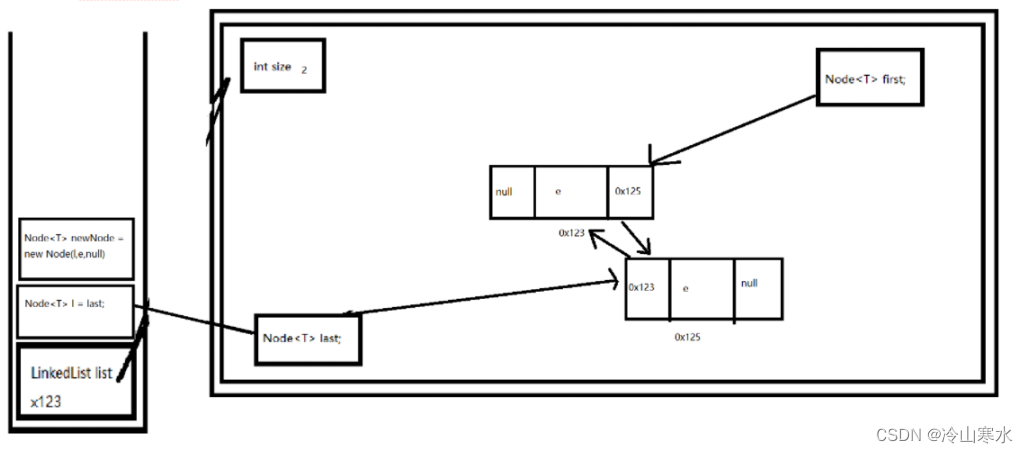
新增元素
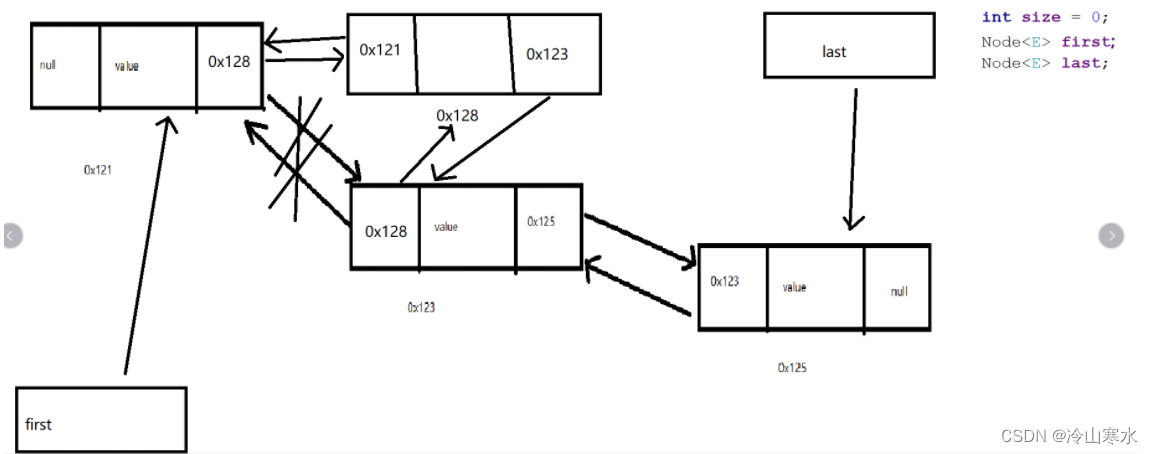
删除元素
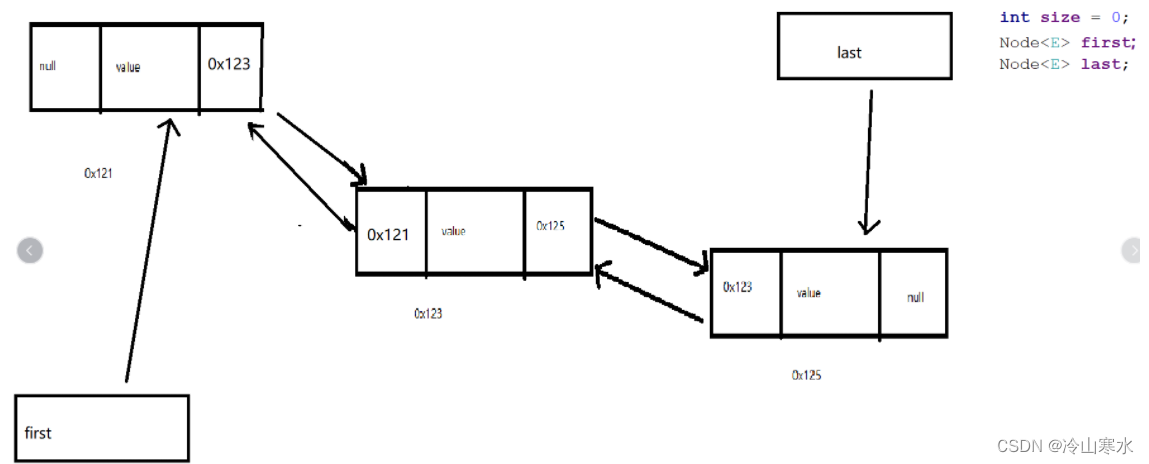
//LinkedList源码遍历——比麻烦
for(Node<E> x=first;x!=null;x=x.next){
if(o.equals(x.item)){
unlink(x);
return true;
}
}比较一下ArrayList和LinkedList
①查找
我们在查找固定下标位置的时候,比如查找3那么ArrayList会直接return数组下标为2的元素,而LinkedList需要使用遍历,逐个寻找,直到找到第三个位置再返回,所以,LinkedList查找不如ArrayList。
②增删
由于ArrayList插入元素后,需要将原本的元素进行位置的移动,需要循环整个数组,而LInkedList值需要修改几个prev和next属性就可以实现,所以ArrayList做增删不如LinkedList。
所以,具体情况具体选择合适的集合。
3、 Set
Set的常用类为HashSet和TreeSet
3.1 TreeSet
TreeSet在输出时会自动排序
public static void main(String[] args){
//Set 不可重复,并且是无序的
//说明这里的无序指的是插入的顺序和输出的顺序不一致
//所有的基本数据类型和String在TreeSet输出时会自动排序
//String的排序是先通过比较第一个字符的大小,再去比较后面的
Set<String> set=new TreeSet<>();
Set.add("11");
Set.add("5");
Set.add("2");
Set.add("5");
Set.add("5");
Set.add("10");
Set.add("1256");
//第一种遍历方式
//for(String i:set){
// System.out.println(i);
//}
//第二种使用迭代器迭代打印Set
Iterator<String> interator=set.iterator();
while(iterator.hasNext()){
Syetem.out.println(iterator.next());
}
}3.2 HashSet
Hash哈希表又可以称之为散列表
HashSet其本质是一个HashMap,只不过每次添加的时候我们向Map的Key添加值内容,Value添加一个固定的常量叫做PRESENT,是一个new Object();
遍历方式和上述的TreeSet一样,有两种遍历方式
4、 数据结构
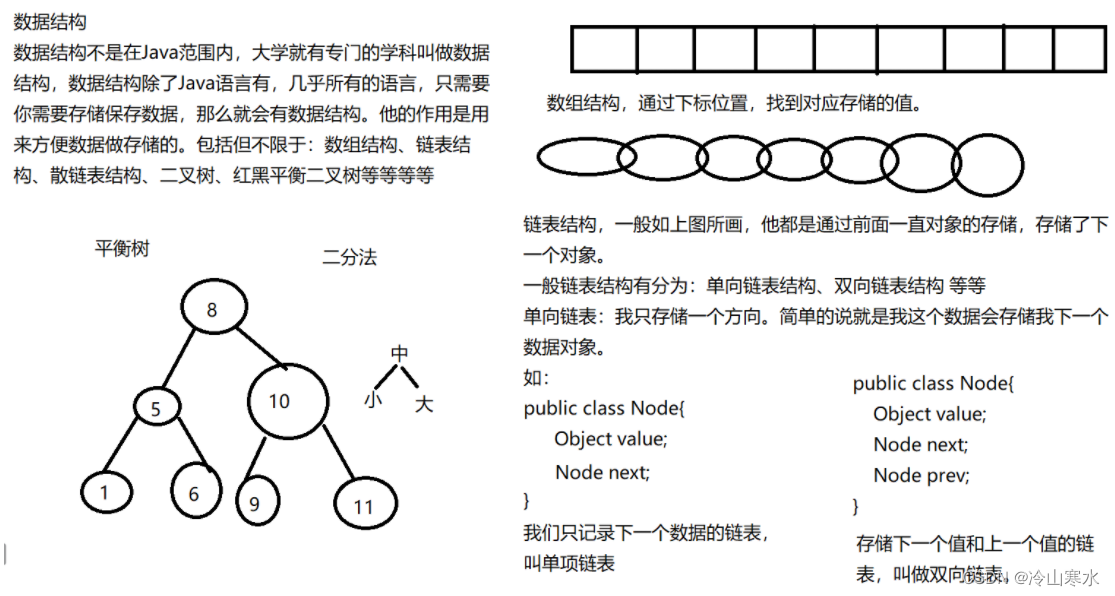
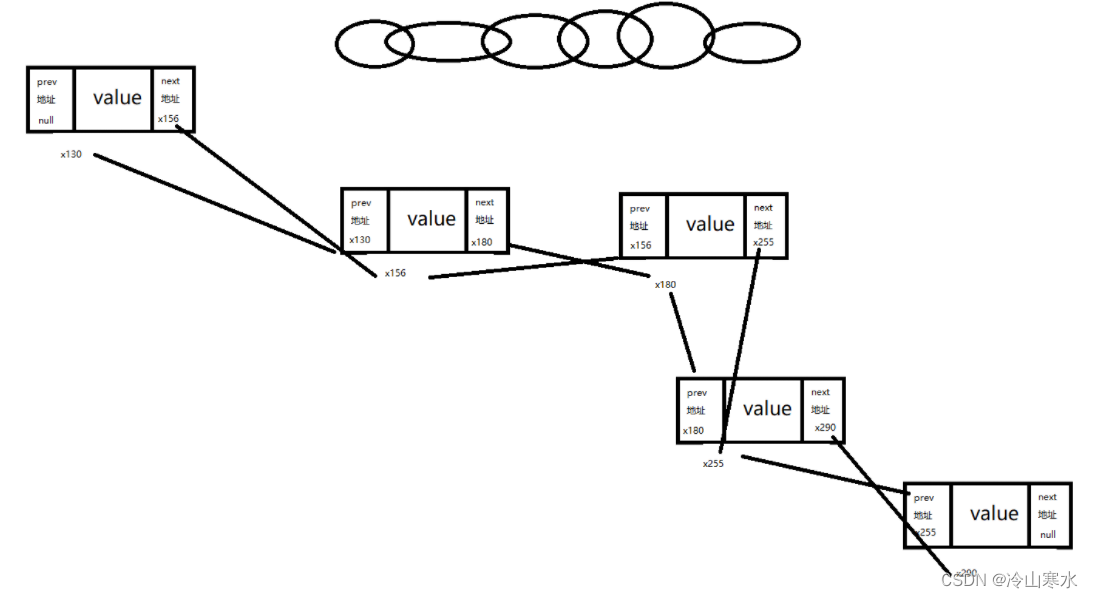
链表数据结构
单项链表

双向链表















 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









