









前言:在公司云原生 k8s 二开平台的日常运维中,工程师分享的一串通用性命令,让我萌生了将其转化为自动化脚本的想法。但写脚本从来不是一蹴而就的过程,它需要不断根据实际执行输出情况进行调整与优化。
起初设计的版本一,我在脚本开头添加了一条环境变量,执行脚本后,系统会提示输入需要查询的命名空间,输出信息则会追加到以当前年月日时命名的自动生成 txt 文件中。随着使用场景的拓展,我对脚本进行了迭代升级,版本二实现了自动生成中文排头标题,并直接输出 csv 文件,省去了手动将 txt 转化为 excel 表的繁琐步骤。
然而,在使用版本二的过程中,我发现生成的 csv 文件里,副本数和容器镜像信息难以清晰区分。面对这个问题,我决定采用在文本格式处理上更具优势的 python 重写脚本,经过反复调试与修改,最终成功解决了难题。
需要特别说明的是,我们使用的 k8s 容器平台为二开版本,且由于我当前试验的命名空间业务具有特殊性,脚本中采集的 “就绪探针” 和 “存活探针” 相关参数,实际为资源限制 CPU 和资源限制 Memory。因此在使用该脚本时,各位需根据自身 deployments.apps 的配置参数灵活调整,让脚本更好地适配实际需求。
查询数值:
namespaceName:部署所在的命名空间
deploymentName:部署的名称
replicas:部署的副本数量
image:容器的镜像
resourcesRequest:容器请求的资源
resourcesLimits:容器资源的限制
readinessProbe:就绪探针的配置
livenessProbe:存活探针的配置
skyworkingNamespace:环境变量 SW_AGENT_NAMESPACE 的值
lopLogsApplog:环境变量 lop_logs_applog 的值
通用命令:
kubectl get deployments.apps -n 需要查询的命名空间 -o jsonpath='{range .items[*]} {"\n\n"} namespaceName={.metadata.namespace}{"\t"} deploymentName={.metadata.name} {"\t"} replicas={.spec.replicas} {range .spec.template.spec.containers[*]} image={.image} {"\t"} resourcesRequest={.resources.requests} {"\t"} resourcesLimits={.resources.limits} {"\t"} readinessProbe={.readinessProbe} {"\t"} livenessProbe={.livenessProbe} {"\t"}{end} skyworkingNamespace={.spec.template.spec.containers[0].env[?(@.name=="SW_AGENT_NAMESPACE")].*} {"\t"} lopLogsApplog={.spec.template.spec.containers[0].env[?(@.name=="lop_logs_applog")].*} {end} {"\n"}'
版本一:shell脚本
#!/bin/bash
# 设置环境变量
export ENV_VARIABLE="SomeValue"
read -p "请输入需要查询的命名空间: " namespace
# 获取日期和时间并格式化作为文件名
current_date=$(date +%Y%m%d%H)
filename="${current_date}.txt"
# 执行 kubectl 命令并将结果追加到文件中
kubectl get deployments.apps -n "$namespace" -o jsonpath='{range.items[*]} {"\n\n"} namespaceName={.metadata.namespace}{"\t"} deploymentName={.metadata.name} {"\t"} replicas={.spec.replicas} {range.spec.template.spec.containers[*]} image={.image} {"\t"} resourcesRequest={.resources.requests} {"\t"} resourcesLimits={.resources.limits} {"\t"} readinessProbe={.readinessProbe} {"\t"} livenessProbe={.livenessProbe} {"\t"}{end} skyworkingNamespace={.spec.template.spec.containers[0].env[?(@.name=="SW_AGENT_NAMESPACE")].*} {"\t"} lopLogsApplog={.spec.template.spec.containers[0].env[?(@.name=="lop_logs_applog")].*} {end} {"\n"}' >> "$filename"
echo "输出已追加到 $filename 文件中。"
执行结果:

版本二:shell脚本:
#!/bin/bash
export ENV_VARIABLE="SomeValue"
read -p "请输入需要查询的命名空间: " namespace
current_date=$(date +%Y%m%d%H)
filename="${current_date}.csv"
# 使用以下命令生成 CSV 格式的输出并追加到文件中
kubectl get deployments.apps -n "$namespace" -o jsonpath='{range.items[*]}{"\n"}'$'\t'"{.metadata.namespace}"$'\t'"{.metadata.name}"$'\t'"{.spec.replicas}"$'\t'"{range.spec.template.spec.containers[*]}{.image}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.resources.requests}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.resources.limits}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.readinessProbe}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.livenessProbe}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.spec.template.spec.containers[0].env[?(@.name==\"SW_AGENT_NAMESPACE\")].value}{end}"$'\t'"{range.spec.template.spec.containers[*]}{.spec.template.spec.containers[0].env[?(@.name==\"lop_logs_applog\")].value}{end}" >> "$filename"
echo "输出已追加到 $filename 文件中。"
执行结果:
版本三:
 改了很多版,这里就直接展示成功吧
改了很多版,这里就直接展示成功吧
通用版-python脚本:
import subprocess
import datetime
# 获取用户输入的命名空间
namespace = input("请输入当前需要查询的命名空间: ")
# 获取当前时间并生成文件名
timestamp = datetime.datetime.now().strftime("%Y%m%d%H")
output_file = f"{timestamp}.csv"
# 设置标题行
with open(output_file, 'w') as f:
f.write("命名空间,名称,副本数,容器镜像,资源请求,资源限制,就绪探针,存活探针,环境变量\n")
# 执行 kubectl 命令并处理结果
command = f"kubectl get deployments.apps -n {namespace} -o json".split()
result = subprocess.check_output(command).decode()
import json
data = json.loads(result)
def format_probe(probe):
if not probe:
return "N/A"
probe_type = ""
details = ""
if "httpGet" in probe:
probe_type = "HTTP GET"
http_get = probe["httpGet"]
details = f"{probe_type}: Path: {http_get.get('path', 'N/A')}, Port: {http_get.get('port', 'N/A')}"
elif "tcpSocket" in probe:
probe_type = "TCP Socket"
tcp_socket = probe["tcpSocket"]
details = f"{probe_type}: Port: {tcp_socket.get('port', 'N/A')}"
elif "exec" in probe:
probe_type = "Exec"
exec_command = probe["exec"]
details = f"{probe_type}: Command: {' '.join(exec_command)}"
elif "cpu" in probe and "memory" in probe:
details = f"Resource: CPU {probe['cpu']}, Memory {probe['memory']}"
else:
return "N/A"
return details
def format_resources(resources):
if not resources:
return "N/A"
cpu = resources.get('cpu', 'N/A')
memory = resources.get('memory', 'N/A')
return f"CPU: {cpu}, Memory: {memory}"
with open(output_file, 'a') as f:
for item in data.get('items', []):
namespace_name = item['metadata']['namespace']
deployment_name = item['metadata']['name']
replicas = item['spec']['replicas']
images = [container['image'] for container in item['spec']['template']['spec']['containers']]
image = images[0] if images else "N/A"
request = format_resources(item['spec']['template']['spec']['containers'][0]['resources']['requests'])
limit = format_resources(item['spec']['template']['spec']['containers'][0]['resources']['limits'])
readiness_probe = "N/A"
if item['spec']['template']['spec']['containers'] and 0 < len(item['spec']['template']['spec']['containers']) and 'readinessProbe' in item['spec']['template']['spec']['containers'][0]:
readiness_probe = format_probe(item['spec']['template']['spec']['containers'][0]['readinessProbe'])
liveness_probe = "N/A"
if item['spec']['template']['spec']['containers'] and 0 < len(item['spec']['template']['spec']['containers']) and 'livenessProbe' in item['spec']['template']['spec']['containers'][0]:
liveness_probe = format_probe(item['spec']['template']['spec']['containers'][0]['livenessProbe'])
env_var = "N/A"
if item['spec']['template']['spec']['containers'] and 'env' in item['spec']['template']['spec']['containers'][0]:
env_var = next((env['value'] for env in item['spec']['template']['spec']['containers'][0]['env'] if env['name'] == "SW_AGENT_NAMESPACE"), "N/A")
f.write(f"{namespace_name},{deployment_name},{replicas},{image},{request},{limit},{readiness_probe},{liveness_probe},{env_var}\n")
print(f"查询结果已写入文件:{output_file}")
定制版-python脚本:
import subprocess
import datetime
# 获取用户输入的命名空间
namespace = input("请输入当前需要查询的命名空间: ")
# 获取当前时间并生成文件名
timestamp = datetime.datetime.now().strftime("%Y%m%d%H")
output_file = f"{timestamp}.csv"
# 设置标题行
with open(output_file, 'w') as f:
f.write("命名空间,名称,副本数,容器镜像,资源预留 CPU,资源预留 Memory,资源限制 CPU,资源限制 Memory,环境变量\n")
# 执行 kubectl 命令并处理结果
command = f"kubectl get deployments.apps -n {namespace} -o json".split()
result = subprocess.check_output(command).decode()
import json
data = json.loads(result)
def format_probe(probe):
if not probe:
return "N/A"
probe_type = ""
details = ""
if "httpGet" in probe:
probe_type = "HTTP GET"
http_get = probe["httpGet"]
details = f"{probe_type}: Path: {http_get.get('path', 'N/A')}, Port: {http_get.get('port', 'N/A')}"
elif "tcpSocket" in probe:
probe_type = "TCP Socket"
tcp_socket = probe["tcpSocket"]
details = f"{probe_type}: Port: {tcp_socket.get('port', 'N/A')}"
elif "exec" in probe:
probe_type = "Exec"
exec_command = probe["exec"]
details = f"{probe_type}: Command: {' '.join(exec_command)}"
elif "cpu" in probe and "memory" in probe:
details = f"Resource: CPU {probe['cpu']}, Memory {probe['memory']}"
else:
return "N/A"
return details
def format_resources(resources):
if not resources:
return "N/A"
cpu = resources.get('cpu', 'N/A')
memory = resources.get('memory', 'N/A')
return f"CPU: {cpu}, Memory: {memory}"
with open(output_file, 'a') as f:
for item in data.get('items', []):
namespace_name = item['metadata']['namespace']
deployment_name = item['metadata']['name']
replicas = item['spec']['replicas']
images = [container['image'] for container in item['spec']['template']['spec']['containers']]
image = images[0] if images else "N/A"
request = format_resources(item['spec']['template']['spec']['containers'][0]['resources']['requests'])
limit = format_resources(item['spec']['template']['spec']['containers'][0]['resources']['limits'])
readiness_probe = "N/A"
if item['spec']['template']['spec']['containers'] and 0 < len(item['spec']['template']['spec']['containers']) and 'readinessProbe' in item['spec']['template']['spec']['containers'][0]:
readiness_probe = format_probe(item['spec']['template']['spec']['containers'][0]['readinessProbe'])
liveness_probe = "N/A"
if item['spec']['template']['spec']['containers'] and 0 < len(item['spec']['template']['spec']['containers']) and 'livenessProbe' in item['spec']['template']['spec']['containers'][0]:
liveness_probe = format_probe(item['spec']['template']['spec']['containers'][0]['livenessProbe'])
env_var = "N/A"
if item['spec']['template']['spec']['containers'] and 'env' in item['spec']['template']['spec']['containers'][0]:
env_var = next((env['value'] for env in item['spec']['template']['spec']['containers'][0]['env'] if env['name'] == "SW_AGENT_NAMESPACE"), "N/A")
# 按照新的标题格式写入数据
parts_request = request.split(", ") if request!= "N/A" else ["N/A", "N/A"]
parts_limit = limit.split(", ") if limit!= "N/A" else ["N/A", "N/A"]
f.write(f"{namespace_name},{deployment_name},{replicas},{image},{parts_request[0].replace('CPU: ', '')},{parts_request[1].replace('Memory: ', '')},{parts_limit[0].replace('CPU: ', '')},{parts_limit[1].replace('Memory: ', '')},{env_var}\n")
print(f"查询结果已写入文件:{output_file}")
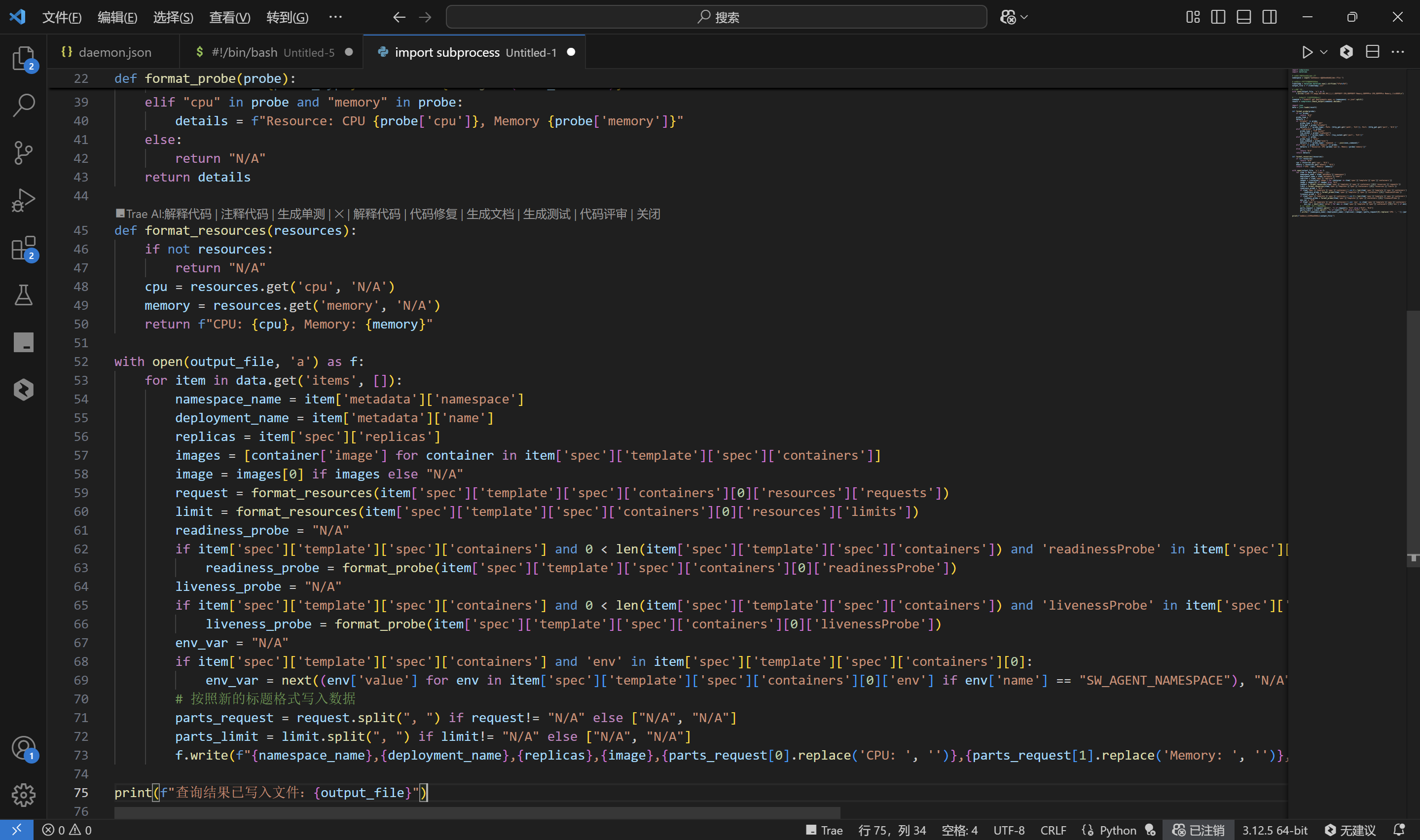
执行: 执行结果:
执行结果:

自动化脚本和输出结果递交上去后,受到公司 高级系统架构师(兼技术专家组云原生高级架构师)、云原生k8s二开工程师以及其他同事和领导的点赞。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











