






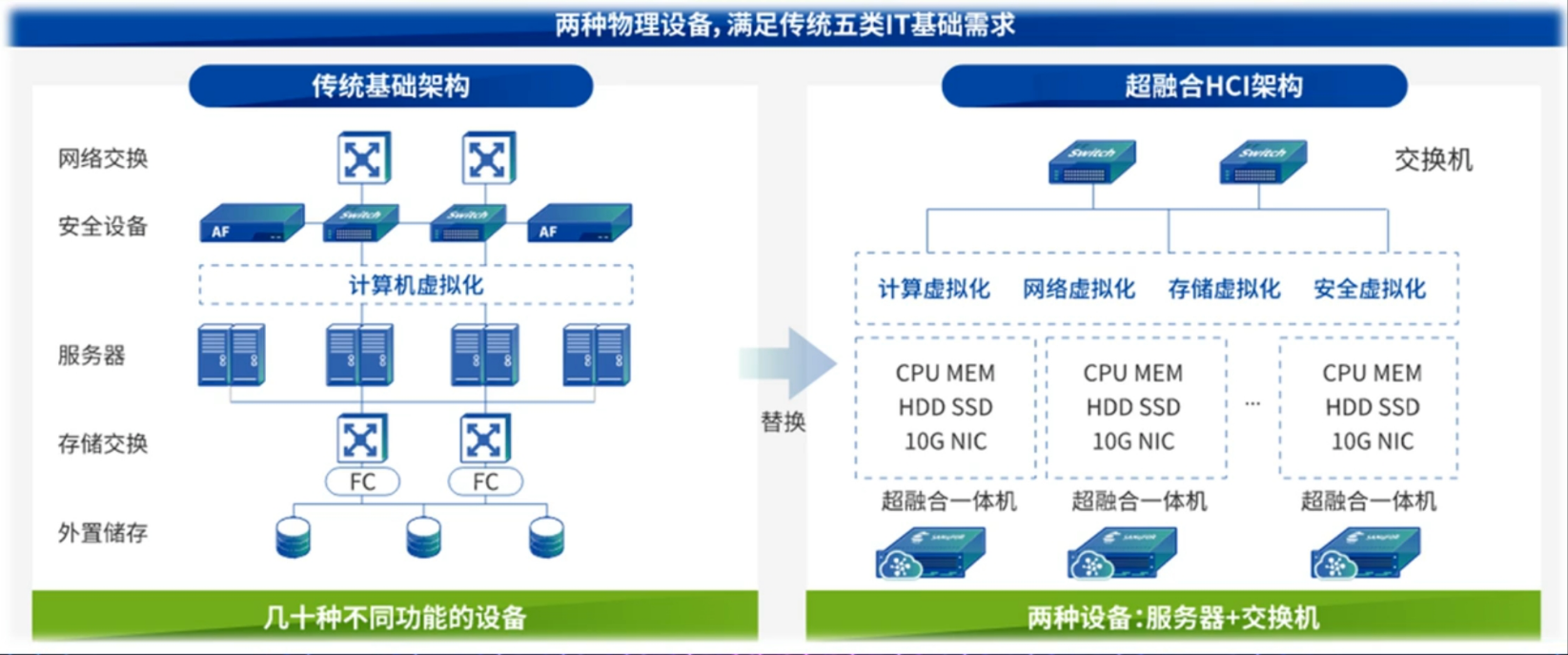
前言:超融合(Hyper-Converged Infrastructure, HCI)是将计算、存储、网络和虚拟化资源整合到统一硬件平台中,并通过软件定义技术实现资源池化与灵活管理的架构。H3C(新华三)和华为作为国内领先的ICT厂商,其超融合平台在技术实现上既有共性,也有各自的产品特性。以下从通用原理和两家厂商的具体实现展开分析,并加入“全无损超融合架构”的相关内容。
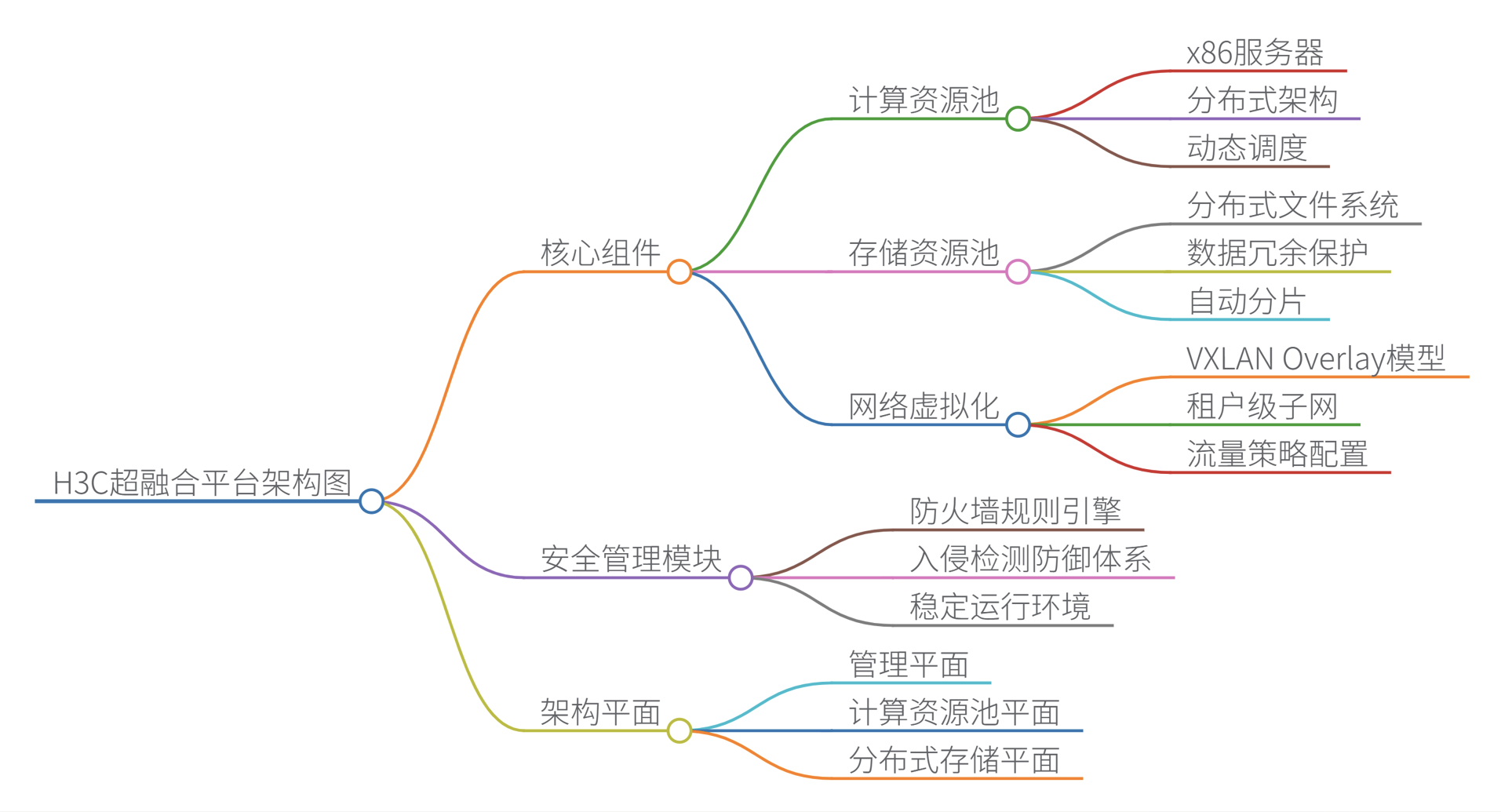
一、超融合平台通用技术原理
超融合的核心是通过软件定义技术(SDI)抽象物理硬件资源,形成统一的资源池,实现计算、存储、网络的融合与协同。其关键组件包括:
1. 计算虚拟化
- 目标:将物理服务器的CPU、内存等资源通过Hypervisor(虚拟化层)虚拟为多个虚拟机(VM),实现资源隔离与灵活分配。
- 技术实现:
- 主流Hypervisor包括VMware ESXi、KVM、Microsoft Hyper-V等。
- 支持动态资源调度(如负载均衡、HA高可用)、热迁移(VMotion)等功能,保障业务连续性。
2. 分布式存储(DS)
- 目标:利用多节点本地硬盘构建分布式存储集群,替代传统集中式存储,实现数据的分布式存储与冗余。
- 技术实现:
- 数据分布:通过哈希算法(如一致性哈希)将数据分片存储到不同节点,支持横向扩展。
- 冗余机制:副本(Replication)或纠删码(Erasure Coding)保障数据可靠性,通常提供2-3副本或N+M纠删码(如3+1)。
- 一致性协议:采用Raft、Paxos等分布式共识算法,确保跨节点数据一致性。
- 缓存优化:利用SSD分层缓存(读/写缓存)提升IO性能。
3. 软件定义网络(SDN)
- 目标:将网络控制平面与数据平面分离,通过软件集中管理虚拟网络资源。
- 技术实现:
- 虚拟交换机(如vSwitch、Open vSwitch)实现VM间流量转发。
- SDN控制器(如OpenDaylight、华为CloudFabric控制器)集中配置网络策略(VLAN、ACL、QoS等)。
- 支持Overlay网络(如VXLAN),实现大二层组网和多租户隔离。
4. 统一管理平台
- 目标:通过单一界面管理计算、存储、网络资源,简化运维。
- 功能:
- 资源池化:自动发现硬件,创建计算/存储资源池。
- 自动化部署:模板化部署VM、应用,支持一键扩容。
- 监控与告警:实时监控节点状态、性能指标,故障自动告警。
- 容灾与备份:支持跨集群数据复制、快照备份、异地容灾。
二、全无损超融合架构的技术内涵
“全无损”通常指在数据中心的计算、存储、网络三层交互中,通过硬件加速、协议优化、智能调度等机制,实现零丢包、低延迟、高吞吐的极致性能,避免传统超融合因流量竞争导致的性能波动或数据丢失风险。其核心技术特征包括:
- 无损网络架构
- 基于RDMA(远程直接数据存取)、RoCE(基于融合以太网的RDMA)或iWARP协议,结合智能流控(如PFC优先级流量控制)、ECN(显式拥塞通知)等技术,实现网络层零丢包。
- 典型应用:H3C的“绿洲”网络架构、华为的“无损数据中心网络”均采用类似技术。
- 存储层无损设计
- 通过NVMe over Fabrics(NVMe-oF)协议、分布式存储副本/纠删码机制、缓存分层技术(如SSD+内存缓存),减少数据写入延迟和IO路径损耗,确保存储性能稳定。
- 计算与资源调度优化
- 结合CPU指令集优化(如Intel QAT压缩加速)、容器/虚拟机资源预留机制,避免多租户场景下的资源抢占导致的性能“有损”。
三、H3C超融合平台(如aCloud)技术原理
H3C超融合以UIS(Unified Infrastructure System)系列硬件为载体,软件平台为aCloud,强调开放性与场景化适配。
1. 计算虚拟化
- Hypervisor:基于开源KVM深度优化,支持轻量化部署,兼容x86服务器。
- 特性:
- 支持混合云管理,可对接公有云(如阿里云、AWS)。
- 容器虚拟化融合:通过aCMP(容器管理平台)支持Kubernetes,适配云原生应用。
2. 分布式存储(UIS存储)
- 架构:采用Scale-Out横向扩展架构,支持2-64节点集群。
- 技术细节:
- 数据分布:基于哈希算法分片,支持动态负载均衡。
- 可靠性:默认3副本(可配置纠删码降低冗余成本),通过Raft协议实现元数据一致性。
- 性能优化:分层存储(SSD+HDD)、智能缓存(写缓存采用NVDIMM/NVMe SSD)。
- 协议支持:提供iSCSI、NFS、CIFS接口,兼容传统企业应用。
3. 软件定义网络(SDN)
- 方案:集成H3C SDN控制器,支持与物理网络(如H3C S5800/S6800交换机)联动。
- 核心功能:
- 虚拟网络与物理网络策略统一管理(如VLAN透传、QoS映射)。
- 支持VXLAN Overlay,实现跨数据中心大二层互联。
- 与H3C SecPath防火墙联动,实现微分段安全隔离。
4. 管理平台(aCloud Manager)
- 特性:
- 全图形化界面,支持拓扑可视化、资源利用率分析。
- 自动化运维:故障自动定位(如硬盘故障时自动触发数据重建)、补丁批量升级。
- 行业解决方案:针对政府、教育、医疗等场景预定义模板(如等保合规配置)。
四、华为超融合平台(如FusionCube)技术原理
华为超融合以FusionCube为代表,基于Fusion系列软件(FusionCompute、FusionStorage、FusionNetwork),强调与华为硬件生态的深度集成。
1. 计算虚拟化(FusionCompute)
- Hypervisor:自研VRM(Virtual Resource Manager)管理平台,基于KVM优化,支持裸金属部署。
- 特性:
- 内存复用技术(内存气球、内存共享)提升资源利用率。
- 与华为服务器(如RH2288 V5)深度适配,支持硬件透传(GPU、PCIe设备)。
2. 分布式存储(FusionStorage)
- 架构:Scale-Out分布式块存储,支持2-2000节点集群,适配大规模数据中心。
- 技术细节:
- 数据分布:通过DHT(分布式哈希表)实现数据分片,元数据集中管理(MDC节点)。
- 可靠性:支持副本(2/3副本)与EC(纠删码,如12+4),故障域隔离(按机架/机房划分)。
- 性能优化:NVMe over Fabrics(RoCE网络)加速存储访问,智能IO调度(分层缓存、热点数据识别)。
- 协议支持:提供块存储接口(对接FusionCompute),兼容Ceph生态(通过插件扩展)。
3. 软件定义网络(FusionNetwork)
- 方案:集成华为CloudFabric控制器,与华为交换机(如CE6800)深度联动。
- 核心功能:
- 虚拟网络与物理网络统一配置(如VPC、安全组),支持EVPN-VXLAN。
- 智能负载均衡:基于流的负载分担(ECMP),支持NVGRE隧道。
- 与华为防火墙(USG6000)、负载均衡器(ADC)联动,实现端到端安全策略。
4. 管理平台(FusionSphere OpenStack)
- 特性:
- 基于OpenStack开源架构,支持私有云、混合云管理。
- 自动化编排:通过Heat模板实现应用级部署(如LAMP栈一键部署)。
- 智能运维:AI驱动的故障预测(如通过历史数据预判硬盘故障)、容量趋势分析。
五、H3C与华为超融合对比
| 维度 | H3C aCloud | 华为FusionCube |
|---|---|---|
| 生态定位 | 开放兼容,支持多品牌硬件与公有云对接 | 深度集成华为服务器、网络设备,封闭生态 |
| 存储技术 | 支持纠删码与副本灵活切换,侧重中小场景 | 大规模集群优化,EC纠删码效率更高 |
| 网络集成 | 与H3C SDN设备解耦,支持第三方网络 | 与华为CloudFabric深度绑定,性能优化更优 |
| 管理平台 | 轻量化,侧重易运维 | 功能全面,适合大型数据中心复杂管理需求 |
| 典型场景 | 中小企业、分支机构、混合云 | 大型企业、电信运营商、高密度计算场景 |
六、超融合适用场景与发展趋势
适用场景:
- 中小企业IT架构:替代传统“服务器+存储+网络”三层架构,降低部署与维护成本。
- 分支机构集中管理:通过总部超融合集群统一管理分支节点,简化远程运维。
- 云原生应用:支持容器化部署(如Kubernetes),适配微服务架构。
- 边缘计算:轻量化节点部署在边缘站点,处理实时数据(如工业物联网、智能门店)。
发展趋势:
- 融合容器与VM:支持“双引擎”虚拟化,统一管理虚拟机与容器(如H3C aCloud集成K8s)。
- AI驱动运维:通过机器学习优化资源调度、预测故障(如华为FusionSphere的智能分析)。
- 硬件加速:利用DPU(数据处理单元)卸载网络与存储流量,释放CPU资源。
- 绿色节能:高密度硬件设计(如2U4节点)、动态电源管理,降低数据中心能耗。
七、H3C与华为超融合平台对全无损架构的差异化实现
1. H3C超融合平台(以H3C UniServer R5300 G5为例)
- 网络层:
- 集成H3C S5830/S6850系列交换机,支持RoCE v2和智能无损算法(如动态PFC调优),通过“流缓存”技术动态分配缓冲区,避免小包转发时的队头阻塞(HOL Blocking)。
- 案例:在虚拟化桌面(VDI)场景中,通过无损网络降低桌面启动时的广播风暴延迟,提升并发性能。
- 存储层:
- 采用H3C CAS存储引擎,基于分布式块存储(CVM)实现数据分条(Striping)与副本冗余,结合SSD缓存池(Write Buffer)减少机械硬盘(HDD)的随机写入压力,提升IOPS稳定性。
- 支持NVMe-oF直连存储节点,降低主机与存储间的协议开销(相比传统SATA/SAS接口延迟降低50%以上)。
- 计算与调度:
- 通过H3C CAS虚拟化平台的“资源预留”功能,为关键业务(如数据库)固定CPU核心和内存资源,避免弹性扩缩容时的性能波动。
2. 华为超融合平台(以FusionCube为例)
- 网络层:
- 基于华为CloudEngine系列交换机,实现“端到端无损网络”,支持智能拥塞控制(iQCN)算法,通过实时监测网络流量动态调整发送速率,避免PFC引起的全局阻塞(Global Pause)。
- 典型应用:在AI训练场景中,无损网络可降低多节点模型参数同步的延迟,提升分布式训练效率。
- 存储层:
- 采用FusionStorage分布式存储,通过全闪存架构(All-Flash)和NVMe SSD盘阵,结合智能IO调度(如热点数据自动分层至内存缓存),实现微秒级延迟。
- 数据保护方面,支持EC(纠删码)与副本混合策略,在保证可靠性的同时减少存储冗余开销(如3副本场景下空间利用率从33%提升至50%以上)。
- 计算与调度:
- FusionCompute虚拟化平台支持“内存热迁移”和“CPU NUMA优化”,减少跨节点资源访问延迟,尤其适合Oracle RAC等对延迟敏感的数据库场景。
八、为何需要在超融合原理中加入全无损架构?
- 技术演进的必然性:
传统超融合架构(如基于IP网络的TCP/IP协议)在高并发场景下易出现网络拥塞丢包、存储IO瓶颈等问题,而“全无损”通过硬件与协议革新,解决了超融合在关键业务(如数据库、实时分析、高性能计算)中的性能痛点。 - 厂商产品的差异化卖点:
H3C和华为均将“无损架构”作为高端超融合产品的核心竞争力:- H3C强调“端到端智能无损”,通过自研网络设备与超融合节点深度协同;
- 华为则依托“云网一体化”优势,将无损网络与云原生调度结合,适配混合云场景。
- 应用场景的需求升级:
在金融交易、医疗影像、工业实时控制等场景中,数据传输的实时性和完整性至关重要。全无损架构可确保:- 交易类业务(如银行核心系统)的事务处理延迟稳定在毫秒级,避免因网络拥塞导致的交易失败;
- 实时数据同步(如双活数据中心)的零丢包传输,保障业务连续性。
九、如何将全无损架构融入超融合原理讲解?
建议框架(以对比H3C与华为为例):
- 超融合基础架构回顾:
- 传统超融合的“软件定义一切”理念:计算虚拟化(Hypervisor)、分布式存储(SDS)、软件定义网络(SDN)。
- 传统架构的局限性:网络拥塞导致的性能抖动、存储IO队列深度不足引发的延迟毛刺。
- 全无损架构的技术突破:
- 网络层革新:
- H3C:RoCE v2+智能流控+硬件卸载(如CRC校验 offload);
- 华为:iQCN算法+ECN+100G/200G高速光模块。
- 存储层优化:
- H3C:NVMe-oF直连+缓存分层+数据分条技术;
- 华为:全闪存阵列+智能IO优先级调度+EC数据保护。
- 计算与调度协同:
- 资源预留机制(如H3C CAS的CPU绑定、华为FusionCompute的内存大页);
- 硬件加速:H3C集成QAT压缩卡、华为采用鲲鹏芯片的智能网卡(SmartNIC)。
- 网络层革新:
- 典型场景与性能对比:
场景 传统超融合(TCP/IP) 全无损超融合(RoCE+iQCN) 数据库OLTP(TPC-C) 延迟波动±20% 延迟波动<5% 虚拟化桌面启动风暴 平均启动时间45秒 平均启动时间28秒 分布式AI训练(ResNet) 单节点迭代时间120秒 单节点迭代时间85秒 - 厂商产品定位与选型建议:
- H3C:适合对网络设备兼容性要求高、需利旧现有H3C交换机的企业,如教育、政府行业;
- 华为:适合构建云网一体化架构、需对接华为云的企业,如金融、大型制造业。
十、总结:全无损架构的价值
“全无损超融合架构”并非颠覆传统超融合,而是通过硬件加速+协议优化+智能调度的组合拳,解决传统架构在高性能场景下的“有损”问题。对于H3C和华为而言,这一架构是其超融合产品向关键业务场景渗透的核心技术壁垒。在讲解时,可结合具体场景(如数据库、实时分析)对比传统与无损架构的差异,帮助读者理解技术演进的逻辑和厂商的差异化竞争力。
十一、H3C UIS超融合运维面试题及答案
1. H3C UIS超融合的核心架构组件有哪些?各组件的作用是什么?
答案:
H3C UIS架构包含三大核心组件:
- UIS Manager管理平台:统一管理计算、存储、网络资源,提供Web控制台及CLI接口(
uisctl命令),支持集群监控、虚拟机生命周期管理、固件升级等。 - H3C CAS虚拟化平台:基于KVM的Hypervisor,提供虚拟机运行环境,通过
virsh命令管理虚拟机(如virsh start vm_name)。 - 分布式存储UIS Storage:采用H3C自研分布式存储引擎,支持副本/纠删码冗余,通过
storagectl命令管理存储池(如storagectl pool list)。 - 网络组件:虚拟交换机(vSwitch)支持VLAN划分,物理网络通过H3C CX系列网卡实现万兆/IB连接。
2. 如何通过UIS Manager实现虚拟机的高可用性?
答案:
- HA配置:
- 在UIS Manager控制台进入「集群→高可用性」,启用HA功能,设置故障恢复策略(如自动重启、迁移)。
- 底层通过
corosync+pacemaker实现集群心跳检测,当节点故障时,通过virsh migrate命令将虚拟机迁移至其他节点。
- 存储冗余:存储池默认采用2副本策略(可配置纠删码),确保数据不丢失,通过
storagectl pool show --name default查看冗余配置。
3. 存储池空间不足时,如何扩容?支持哪些扩容方式?
答案:
- 扩容方式:
- 纵向扩容:向现有节点添加磁盘,通过UIS Manager「存储→存储池→扩容」选择新磁盘加入(命令行:
storagectl pool add-disks --pool-name default --disk-ids 1,2)。 - 横向扩容:添加新节点至集群,新节点磁盘自动加入存储池(需在「集群→节点」中执行加入操作)。
- 纵向扩容:向现有节点添加磁盘,通过UIS Manager「存储→存储池→扩容」选择新磁盘加入(命令行:
- 注意事项:扩容前通过
storagectl pool status --name default确认存储池状态,扩容过程中避免批量虚拟机创建/删除操作。
4. 如何排查节点间的心跳中断故障?
答案:
- 排查步骤:
- 物理连接:检查管理网(默认eth0)和存储网(默认eth1)网线是否松动,交换机端口状态(
ethtool eth0查看链路速率)。 - 心跳服务:
systemctl status corosync # 检查集群心跳服务状态 corosync-cmapctl | grep members # 查看节点成员列表,确认故障节点是否在列表中 - 防火墙配置:确保管理网端口(5404/5405)未被阻断(
firewall-cmd --list-ports | grep 5404)。 - 底层日志:
tail -f /var/log/corosync/corosync.log # 查看心跳日志,定位超时或断开原因
- 物理连接:检查管理网(默认eth0)和存储网(默认eth1)网线是否松动,交换机端口状态(
5. 虚拟机频繁蓝屏/重启,可能的原因有哪些?如何定位?
答案:
- 可能原因:
- 硬件兼容性问题(如CPU指令集不匹配、内存故障);
- 存储IO瓶颈(磁盘队列深度过高);
- 虚拟机配置冲突(如MAC地址重复、CPU超分配)。
- 定位方法:
- 硬件日志:通过ILO管理口查看服务器硬件日志,检查内存/CPU错误(H3C服务器:
h3c_ima_cli -u admin -p password sel list)。 - 虚拟机日志:
virsh dombless-log vm_name # 获取KVM虚拟机日志 grep -i "error" /var/log/libvirt/qemu/vm_name.log # 搜索错误关键词 - 资源监控:通过UIS Manager「监控→性能」查看虚拟机CPU/内存使用率,存储侧通过
storagectl volume stats --volume-id 1查看IO延迟。
- 硬件日志:通过ILO管理口查看服务器硬件日志,检查内存/CPU错误(H3C服务器:
十二、日常运维实操命令(精确到H3C UIS CLI)
其实现在的超融合平台管理界面做的很智能,图形化界面操作,很多功能都是中文字面意思,基本上足够完成运行维护工作,不过这里不方便展示管理管理界面。
1. 集群健康检查
- 整体状态:
uisctl cluster status # 查看集群运行状态(正常为Healthy) uisctl node list # 查看节点列表及状态(Status应为Normal) - 存储健康:
storagectl pool status --name default # 查看默认存储池状态(Health应为Normal) storagectl disk list --node-id 1 # 查看节点1的磁盘状态(State应为Online) - 网络状态:
uisctl network interface list # 查看节点网络接口配置及链路状态 ethtool eth0 # 查看管理网接口详细信息(如速率、双工模式)
2. 虚拟机管理
- 创建/启动/停止:
uisctl vm create --name web-vm --cpu 4 --memory 16384 # 创建4核16GB虚拟机 uisctl vm start --vm-id 1 # 启动ID为1的虚拟机 uisctl vm stop --vm-id 1 --graceful # 优雅关闭虚拟机(等价于ACPI关机) - 迁移与快照:
uisctl vm migrate --vm-id 1 --target-node 2 # 手动迁移虚拟机至节点2 uisctl vm snapshot create --vm-id 1 --name pre-upgrade # 创建升级前快照
3. 存储与磁盘操作
- 存储池管理:
storagectl pool create --name backup-pool --redundancy 2 # 创建2副本存储池 storagectl volume create --pool-name default --size 100GB --name db-volume # 创建100GB卷 - 磁盘操作:
storagectl disk scan --node-id 1 # 扫描节点1的新磁盘 storagectl disk retire --disk-id 5 # 退役故障磁盘(需先迁移数据)
4. 性能监控与日志
- 实时监控:
uisctl monitor vm stats --vm-id 1 # 查看虚拟机实时CPU/内存/IO数据 sar -n DEV 1 # 查看节点网络接口流量(需安装sysstat工具) - 日志收集:
uisctl support collect --type all # 收集全集群诊断日志(用于售后支持) tail -f /var/log/uis/uis-manager.log # 查看UIS Manager服务日志
十三、故障处理实战(H3C UIS典型场景)
场景1:节点离线(Status变为Offline)
处理步骤:
- 快速隔离:
uisctl node offline --node-id 3 # 手动标记节点3为离线状态(防止脑裂) - 硬件排查:
- 通过ILO登录节点,检查电源/风扇状态,重启服务器(
h3c_ima_cli server reboot)。 - 若硬件正常,检查管理网IP配置(
ip addr show dev eth0),修复网络连接。
- 通过ILO登录节点,检查电源/风扇状态,重启服务器(
- 重新加入集群:
uisctl node join --node-ip 192.168.1.3 --cluster-token xxxx # 使用集群令牌重新加入 - 数据同步:等待存储池自动重建数据,通过
storagectl pool status监控重建进度(Reconstructing状态)。
场景2:存储卷IO延迟过高(>50ms)
排查修复:
- 定位瓶颈:
storagectl volume stats --volume-id 2 # 查看卷IOPS、吞吐量、延迟 iostat -x /dev/nsd1 # 查看底层分布式存储设备IO(nsd为UIS存储设备前缀) - 优化措施:
- 若磁盘利用率>80%,添加SSD缓存盘(UIS支持分层存储):
storagectl cache add --node-id 1 --disk-ids 6,7 # 将节点1的磁盘6、7加入缓存层 - 若网络拥塞,检查存储网流量(
ethtool -S eth1 | grep rx_bytes),扩容万兆网卡或启用负载均衡。
- 若磁盘利用率>80%,添加SSD缓存盘(UIS支持分层存储):
场景3:虚拟机能ping通IP但无法访问业务端口
处理流程:
- 安全组检查:
uisctl security-group rule list --vm-id 4 # 查看虚拟机关联的安全组规则 uisctl security-group rule add --protocol tcp --port 80 --direction ingress # 添加HTTP入站规则 - 虚拟交换机配置:
ovs-vsctl show # 查看Open vSwitch桥接状态(UIS虚拟网络基于OVS) ovs-ofctl dump-flows br-int # 检查流表是否允许目标端口流量通过 - 虚拟机防火墙:
ssh vm_ip sudo firewall-cmd --list-ports # 检查虚拟机内部防火墙规则 sudo firewall-cmd --add-port 80/tcp --permanent # 添加允许端口并重启防火墙
场景4:UIS Manager管理平台登录异常
修复步骤:
- 服务状态检查:
systemctl status uis-manager # 检查管理平台主服务状态 systemctl restart uis-manager # 重启服务(若状态为failed) - 数据库连接:
mysql -u uis -pUIS@12345 -e "show databases;" # 验证管理平台数据库连通性 /opt/uis-manager/scripts/reset-db.sh # 重置数据库连接(谨慎操作,需备份数据) - 控制台访问:若Web界面无法打开,检查Nginx服务:
systemctl status nginx # Nginx为UIS Manager前端服务
十四、H3C UIS核心命令速查表
| 操作分类 | 功能描述 | 命令示例 |
|---|---|---|
| 集群管理 | 查看集群状态 | uisctl cluster status |
| 添加新节点 | uisctl node join --node-ip 192.168.1.10 | |
| 虚拟机管理 | 创建虚拟机 | uisctl vm create --name app-vm --cpu 2 --memory 8192 |
| 热迁移虚拟机 | uisctl vm migrate --vm-id 1 --target-node 2 | |
| 存储管理 | 查看存储池状态 | storagectl pool status --name default |
| 创建存储卷 | storagectl volume create --pool-name default --size 200GB | |
| 网络管理 | 查看网络接口状态 | uisctl network interface list |
| 添加VLAN到虚拟交换机 | uisctl vswitch vlan add --vswitch-name vsw0 --vlan-id 100 | |
| 故障处理 | 隔离故障节点 | uisctl node offline --node-id 3 |
| 收集诊断日志 | uisctl support collect --type all | |
| 底层操作 | 查看KVM虚拟机列表 | virsh list --all |
| 检查磁盘SMART状态 | smartctl -a /dev/sda |
十五、H3C UIS运维注意事项
- 版本兼容性:升级前通过UIS Manager「系统→升级」检查固件/软件兼容性,避免跨大版本直接升级(如从7.0直接升级7.5需分阶段)。
- 备份策略:定期通过「存储→备份」创建集群配置备份(
uisctl backup create --type config),重要虚拟机开启自动快照(每日1次)。 - 硬件合规:所有硬件需通过H3C UIS兼容性列表(如CX312B-M网卡、HDD/SSD型号),非兼容硬件可能导致存储服务异常。
- 性能基线:建立集群性能基线(如正常IO延迟<20ms,CPU利用率<70%),通过UIS Manager「监控→报表」生成历史趋势分析。
通过以上内容,可系统掌握H3C UIS超融合平台的运维核心知识,覆盖面试考核点、日常操作及故障处理全流程。实际操作中需结合《H3C UIS管理平台操作手册》及现场环境,建议在测试集群验证高危命令(如磁盘退役、节点离线)后再应用于生产环境。



















 5509
5509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











