






5.kafka系统的架构

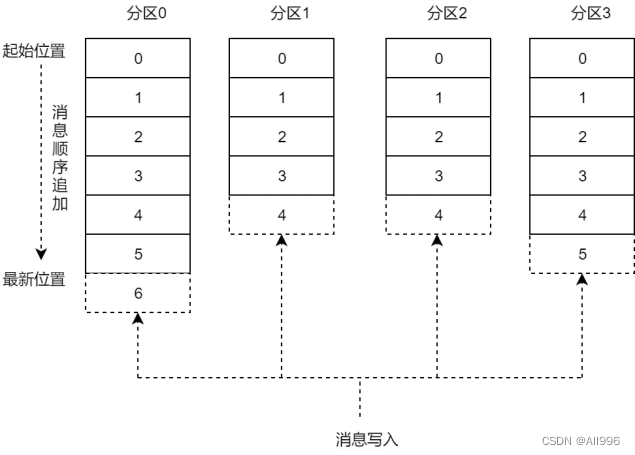
5.1主题topic和分区partition
- topic
Kafka中存储数据的逻辑分类;你可以理解为数据库中“表”的概念;
比如,将app端日志、微信小程序端日志、业务库订单表数据分别放入不同的topic
- partition分区(提升kafka吞吐量)
topic中数据的具体管理单元;(你可以理解为hbase中表的“region"概念)
- 每个partition由一个kafka broker服务器管理;
- 每个topic 可以划分为多个partition,分布到多个broker上管理;
- 每个partition都可以有多个副本;保证数据安全
| 分区对于 kafka 集群的好处是:实现topic数据的负载均衡。提高写入、读出的并发度,提高吞吐量。 |
- 分区副本replica
每个topic的每个partition都可以配置多个副本(replica),以提高数据的可靠性;
每个partition的所有副本中,必有一个leader副本,其他的就是follower副本(observer副本);follower定期找leader同步最新的数据;对外提供服务只有leader;
- 分区follower
partition replica中的一个角色,它通过心跳通信不断从leader中拉取、复制数据(只负责备份)。
如果leader所在节点宕机,follower中会选举出新的leader;
- 消息偏移量offset
partition内部每条消息都会被分配一个递增id(offset);通过offset可以快速定位到消息的存储位置;
kafka 只保证按一个partition中的消息的顺序,不保证一个 topic的整体(多个partition 间)的顺序。
我们在说到偏移量的时候,是哪一个topic的哪一个分区的哪一个,偏移量他的数据只能追加,不能被修改
自我推导设计:
- kafka是用来存数据的;
- 现实世界数据有分类,所以存储系统也应有数据分类管理功能,如mysql的表;kafka有topic;
- 如一个topic的数据全部交给一台server存储和管理,则读写吞吐量有限;
- 所以,一个topic的数据应该可以分成多个部分(partition)分别交给多台server存储和管理;
- 如一台server宕机,这台server负责的partition将不可用,所以,一个partition应有多个副本;
- 一个partition有多个副本,则副本间的数据一致性难以保证,因此要有一个leader统领读写;
- 一个leader万一挂掉,则该partition又不可用,因此还要有leader的动态选举机制;
- 集群有哪些topic,topic有哪几个分区,server在线情况,等等元信息和状态信息需要在集群内部及客户端之间共享,则引入了zookeeper;
- 客户端在读取数据时,往往需要知道自己所读取到的位置,因而要引入消息偏移量维护机制;
broker服务器:一台 kafka服务器就是一个broker。一个kafka集群由多个 broker 组成。
生产者producer:消息生产者,就是向kafka broker发消息的客户端。
消费者consumer
- consumer :消费者,从kafka broker 取消息的客户端。
- consumer group:消费组,单个或多个consumer可以组成一个消费组;
消费组是用来实现消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段;

| 消费者可以对消费到的消息位置(消息偏移量)进行记录; 老版本是记录在zookeeper中;新版本是记录在kafka中一个内置的topic中(__consumer_offsets) |
5.2kafka的数据存储结构 kafka的数据存在哪?
5.2.1kafka的整体存储结构

物理存储目录结构 __consumer_offset
存储目录 名称规范: topic名称-分区号

| 注:“t1"即为一个topic的名称; 而“t1-0 / t1-1"则表明这个目录是t1这个topic的哪个partition; |
- 数据文件 名称规范:
生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制
- 每个partition的数据将分为多个segment存储
- 每个segment对应两个文件:“.index"文件和“.log"文件。

index和log文件以当前segment的第一条消息的offset命名。

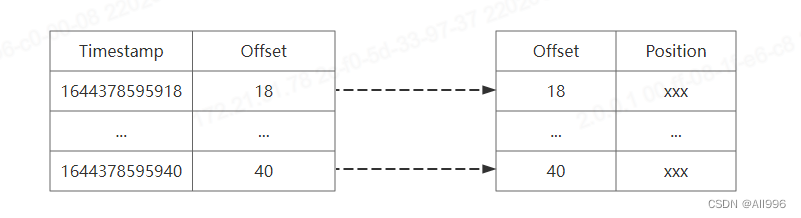
index索引文件中的数据为: 消息offset -> log文件中该消息的物理偏移量位置;
Kafka 中的索引文件以稀疏索引( sparse index )的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引;每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096 ,即 4KB )的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes的值,对应地可以缩小或增加索引项的密度;
查询指定偏移量时,使用二分查找法来快速定位偏移量的位置。
5.2.2消息message存储结构
在客户端编程代码中,消息的封装类有两种:ProducerRecord、ConsumerRecord;
简单来说,kafka中的每个massage由一对key-value构成;
Kafka中的message格式经历了3个版本的变化了:v0 、 v1 、 v2

各个字段的含义介绍如下:
- crc:占用4个字节,主要用于校验消息的内容;
- magic:这个占用1个字节,主要用于标识日志格式版本号,此版本的magic值为1
- attributes:占用1个字节,这里面存储了消息压缩使用的编码以及Timestamp类型。目前Kafka 支持 gzip、snappy 以及 lz4(0.8.2引入) 三种压缩格式;[0,1,2]三位bit表示压缩类型。[3]位表示时间戳类型(0,create time;1,append time),[4,5,6,7]位保留;
- key length:占用4个字节。主要标识 Key的内容的长度;
- key:占用 N个字节,存储的是 key 的具体内容;
- value length:占用4个字节。主要标识 value 的内容的长度;
- value:value即是消息的真实内容,在 Kafka 中这个也叫做payload。














 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









