







基于Spark的环境质量数据分析可视化系统(空气土壤水质等)
项目概述
本项目是一个基于Spark、Flask和MySQL的空气质量数据分析可视化系统,旨在对城市空气质量数据进行全面分析和可视化展示。系统通过Spark进行大数据处理,利用Flask构建Web应用,并使用MySQL存储处理后的数据,为用户提供直观的空气质量数据分析结果。通过多维度的数据分析和先进的预测算法,系统能够为环境监测、城市规划和公共健康研究等领域提供有力的数据支持。
功能模块
1. 用户管理模块
- 用户登录:系统提供安全的用户登录功能,采用会话管理确保用户验证的安全性。登录验证通过MySQL数据库中的用户表进行身份认证,支持错误提示和安全退出。
- 用户注册:新用户可以创建账号,系统会验证用户名唯一性,确保密码一致性,并将加密后的用户信息存入数据库。注册过程包含表单验证和重复用户名检查。
- 密码修改:用户可以在个人资料页面安全地修改密码,系统会先验证原密码正确性,再更新新密码。整个过程有完整的错误处理和成功提示。
- 会话管理:使用Flask-Session进行用户会话管理,支持会话持久化、过期控制和跨请求状态维护。会话数据存储在文件系统中,支持7天的长期会话保持。
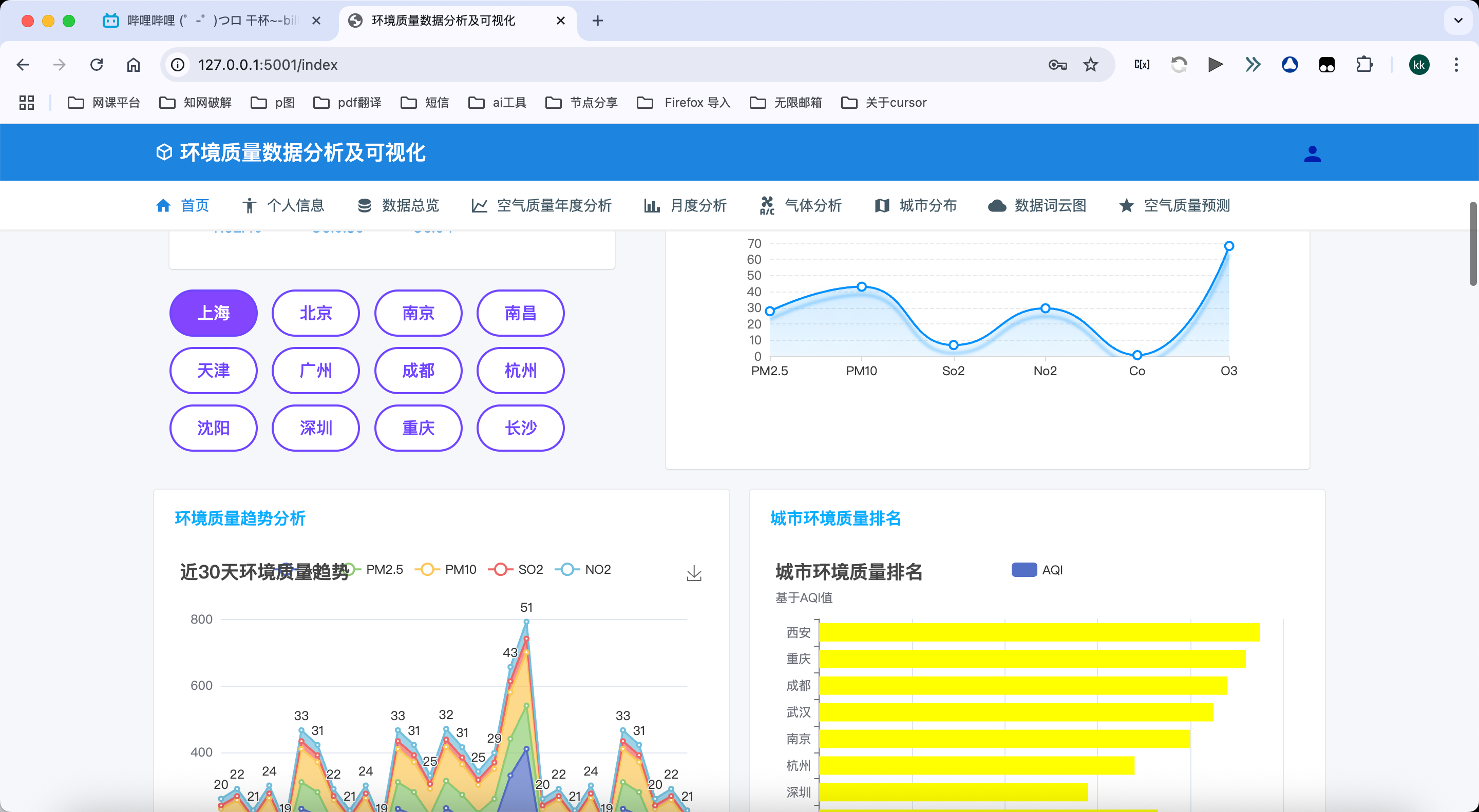
2. 数据展示模块
-
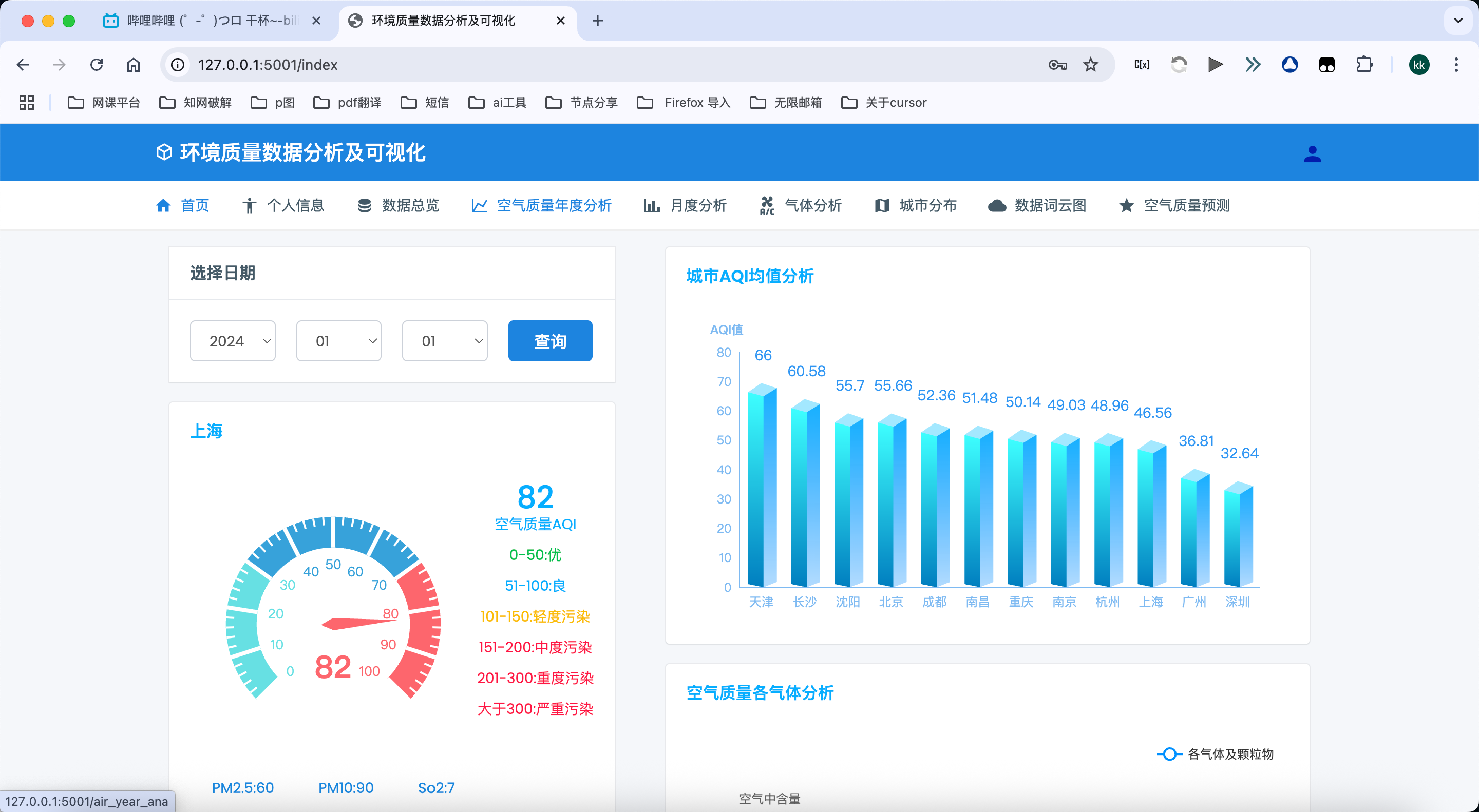
首页数据概览:
- 提供当日AQI指数、污染物浓度等核心数据的直观展示
- 支持选择不同城市、年份、月份和日期查看特定日期的空气质量数据
- 通过柱状图展示各污染物的浓度对比,直观反映污染状况
- 通过折线图展示所选城市的AQI历史变化趋势,反映长期空气质量状况
- 自动计算并显示空气质量等级和健康建议,帮助用户了解健康影响
-
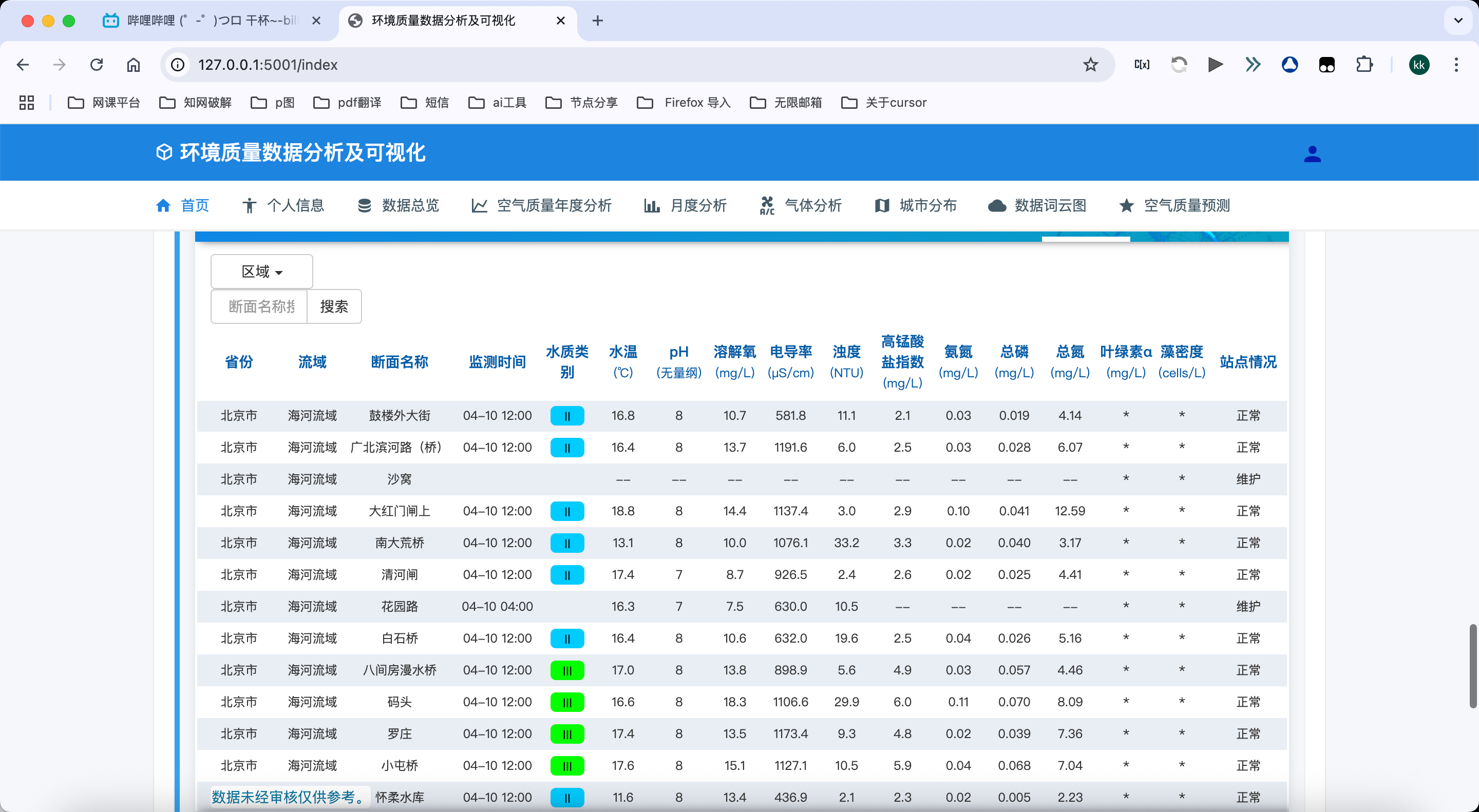
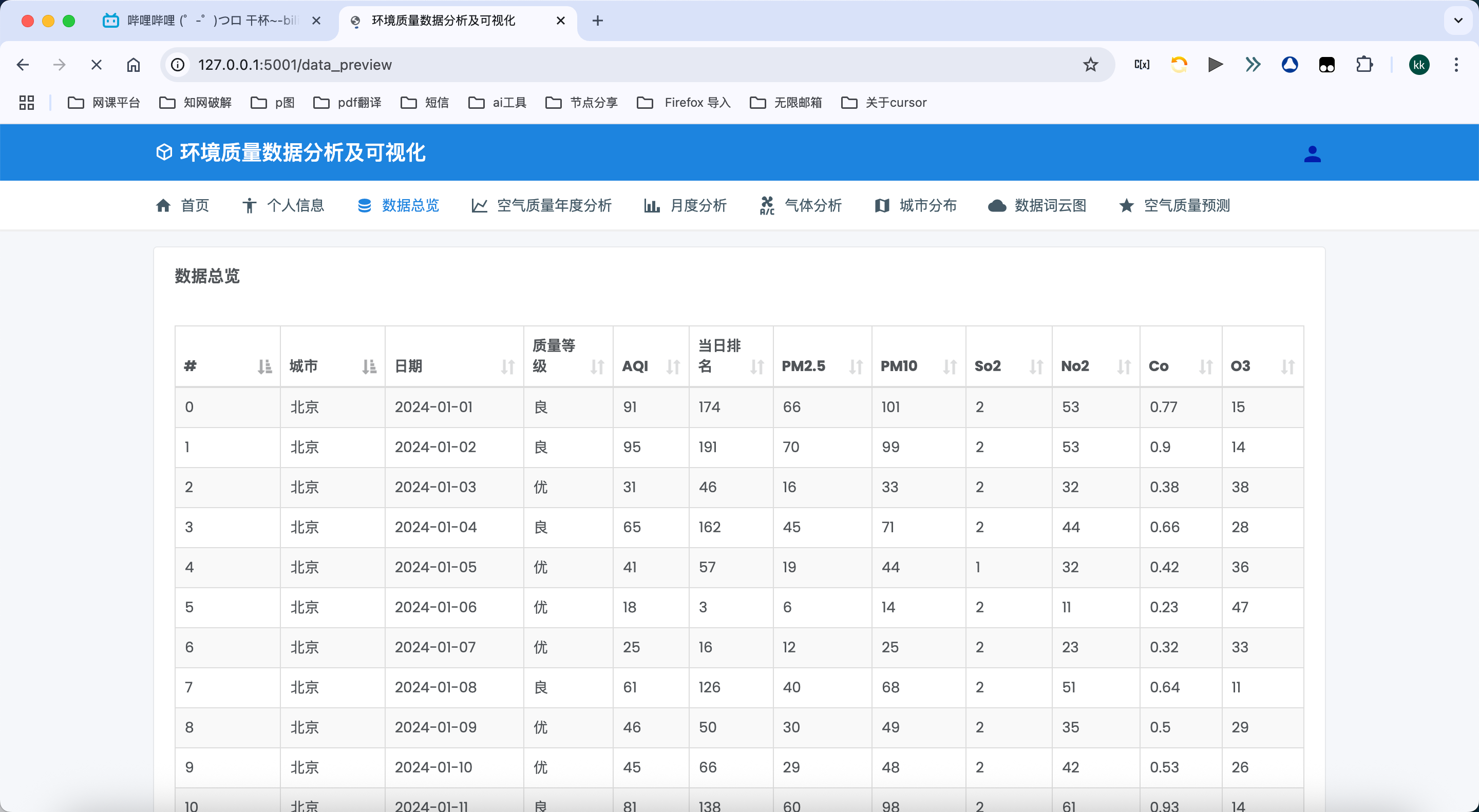
数据预览:
- 以表格形式展示原始空气质量数据,包括城市、日期、AQI指数、空气质量等级和六项污染物浓度
- 支持多页浏览,方便用户查看大量历史数据
- 表格数据按时间顺序排列,帮助用户理解数据的时间变化规律
- 直接从MySQL数据库中获取数据,确保数据的准确性和完整性
3. 空气质量年度分析模块
-
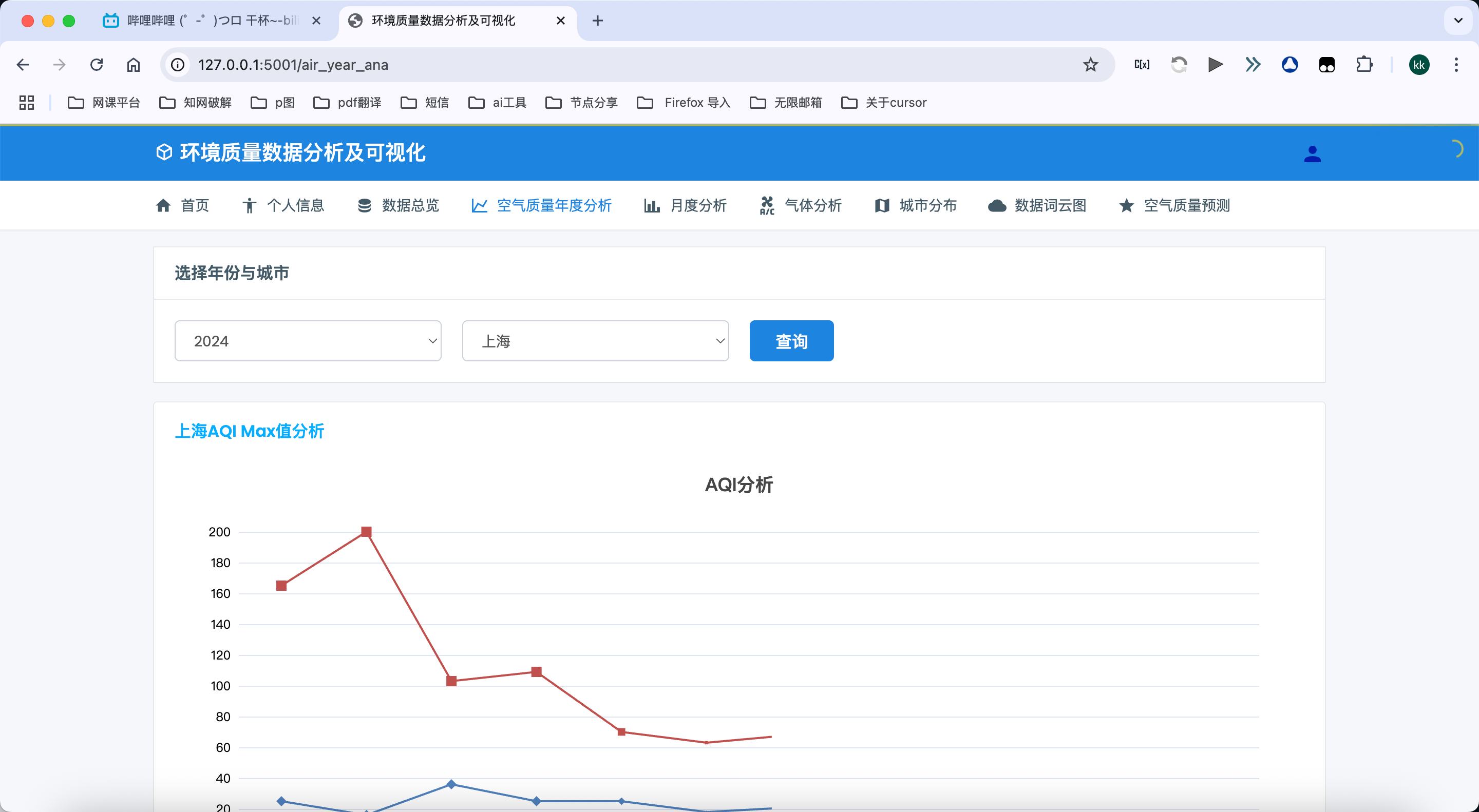
年度趋势分析:
- 展示选定城市在特定年份的空气质量月度变化趋势
- 通过交互式折线图展示AQI的月度平均值变化,直观反映年内的季节性变化
- 支持多城市和多年份选择,便于进行横向和纵向对比分析
- 自动计算年度平均值、最大值和最小值,提供年度总体评估
-
最大/最小AQI值分析:
- 详细分析并展示年度内各月份AQI的最大值和最小值
- 通过双线折线图对比展示最大值和最小值的变化趋势
- 突出显示极端值发生的时间,帮助分析极端污染事件
- 计算最大值与最小值的差异幅度,反映空气质量的波动性
-
PM2.5和PM10年度变化:
- 重点分析颗粒物污染指标的年度变化情况
- 通过多系列折线图同时展示PM2.5和PM10的月度平均浓度变化
- 计算PM2.5/PM10比值,分析细颗粒物在可吸入颗粒物中的占比
- 与AQI指数变化进行关联分析,评估颗粒物对空气质量的影响程度
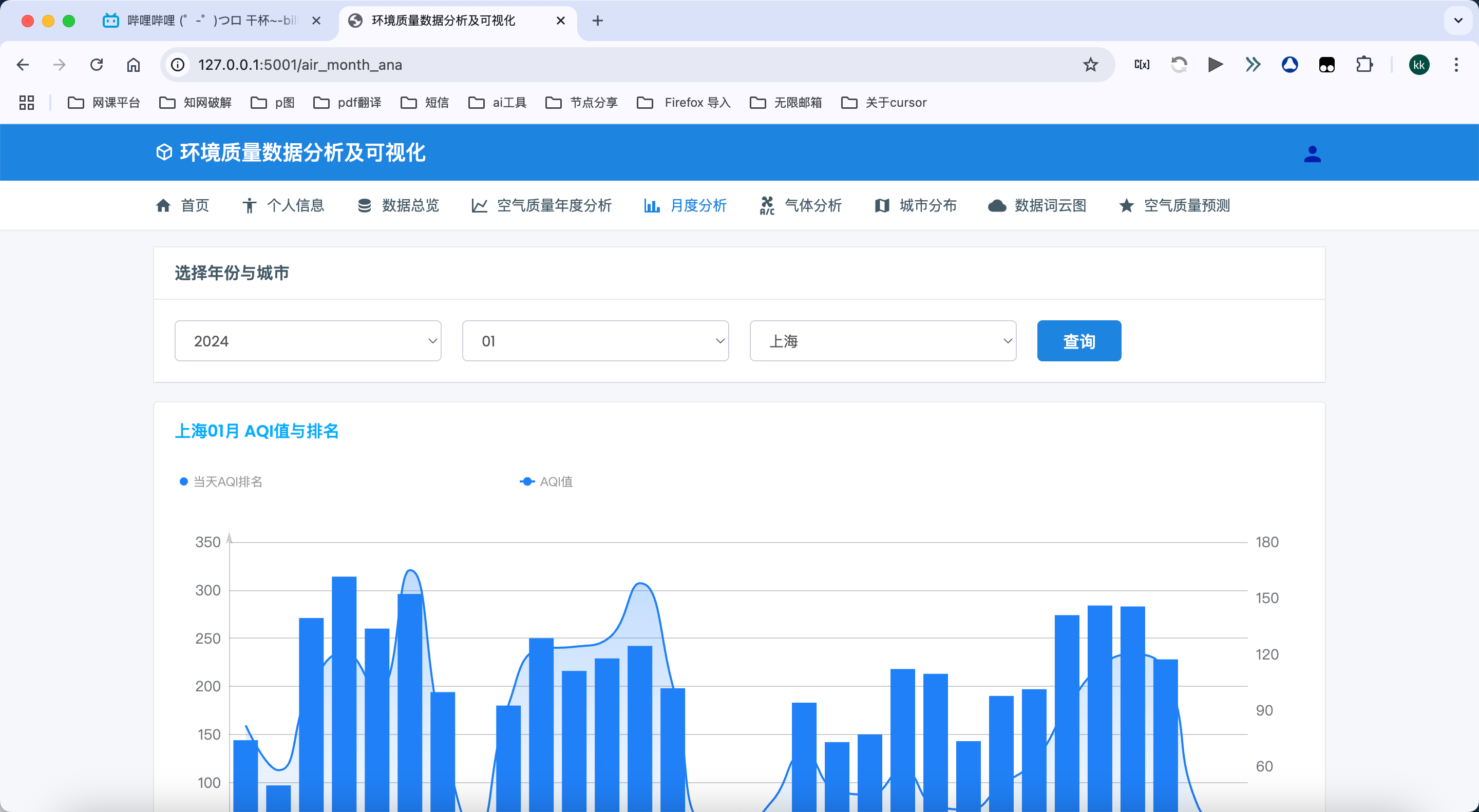
4. 空气质量月度分析模块
-
月度趋势分析:
- 展示选定城市在特定年月的空气质量日变化趋势
- 通过高精度折线图展示SO2和NO2两种主要气体污染物的每日浓度变化
- 支持多城市、多年月选择,便于对比不同时期的空气质量状况
- 自动计算并显示月度平均浓度和变化趋势,辅助识别异常变化
-
优良天数统计:
- 统计并展示月度内空气质量达到优良标准的天数
- 通过可视化图表直观展示优良天数占比
- 自动计算空气质量达标率,反映城市空气质量水平
- 与历史同期数据对比,反映空气质量的改善或恶化趋势
-
污染物浓度对比:
- 对比分析SO2、NO2等不同污染物在月度内的浓度变化
- 通过多系列图表展示不同污染物浓度的相关性
- 识别污染物浓度峰值和谷值,分析污染物之间的协同变化规律
- 计算污染物浓度比值,分析污染来源的可能特征
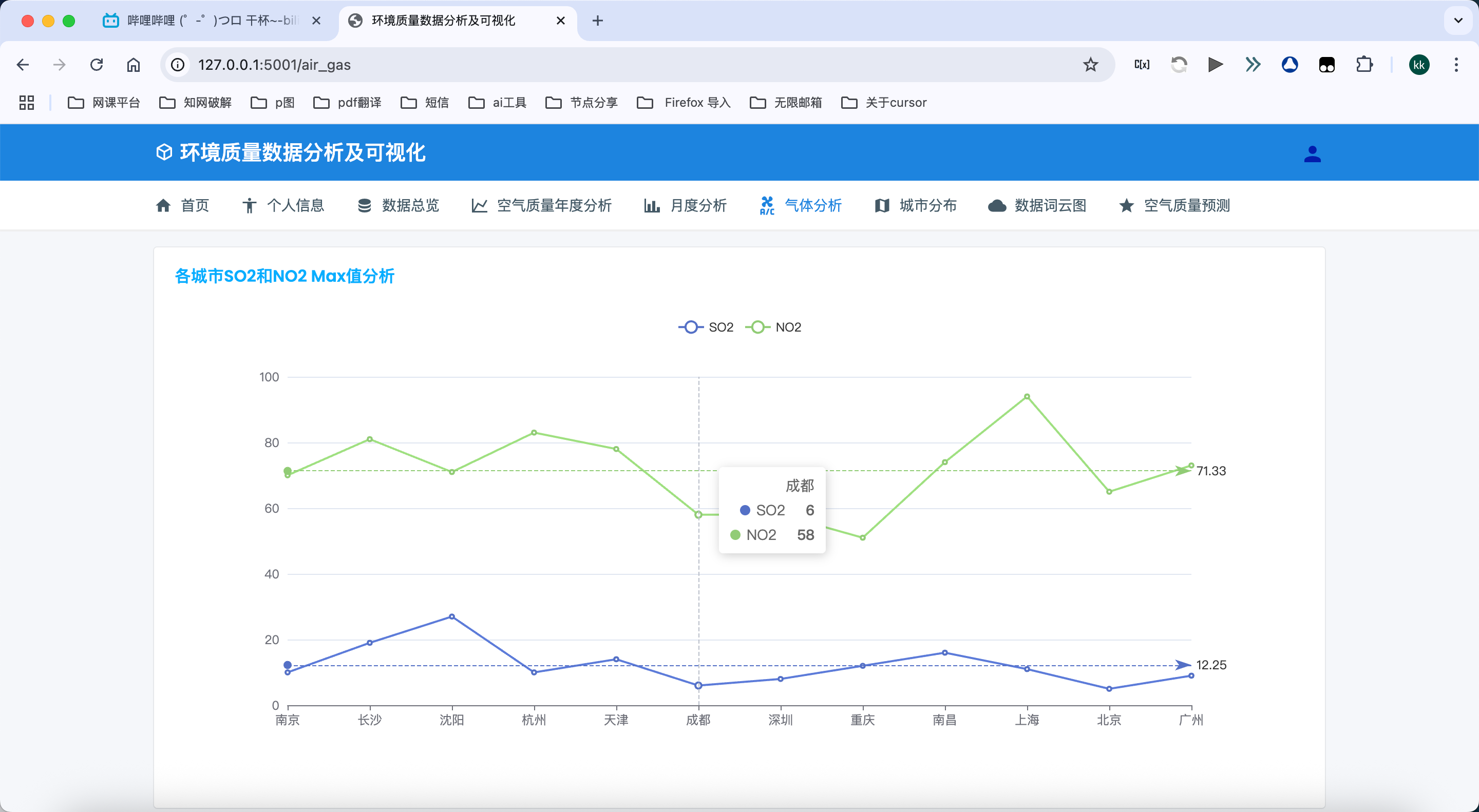
5. 气体污染物分析模块
-
CO和O3浓度分析:
- 详细分析一氧化碳和臭氧的浓度分布情况
- 通过时间序列折线图展示CO和O3浓度的长期变化趋势
- 分析臭氧8小时最大浓度值,评估光化学污染的严重程度
- 分析CO和O3浓度的季节性和周期性变化规律,揭示污染特征
-
气体污染物分类统计:
- 按照不同浓度等级对CO和O3进行精细分类统计
- CO浓度分为5个等级:0-0.25、0.25-0.5、0.5-0.75、0.75-1和1以上(单位:mg/m³)
- O3浓度分为5个等级:0-25、25-50、50-75、75-100和100以上(单位:μg/m³)
- 通过饼图直观展示不同浓度等级的分布比例,反映污染物总体水平
-
气体污染物趋势分析:
- 展示气体污染物浓度的长期变化趋势
- 通过多时间尺度的趋势分析,揭示污染物浓度的变化规律
- 分析CO和O3浓度与气象条件的关系,探索影响因素
- 对比不同气体污染物的趋势,分析它们之间的相互关系和影响
6. 城市空气质量对比分析模块
-
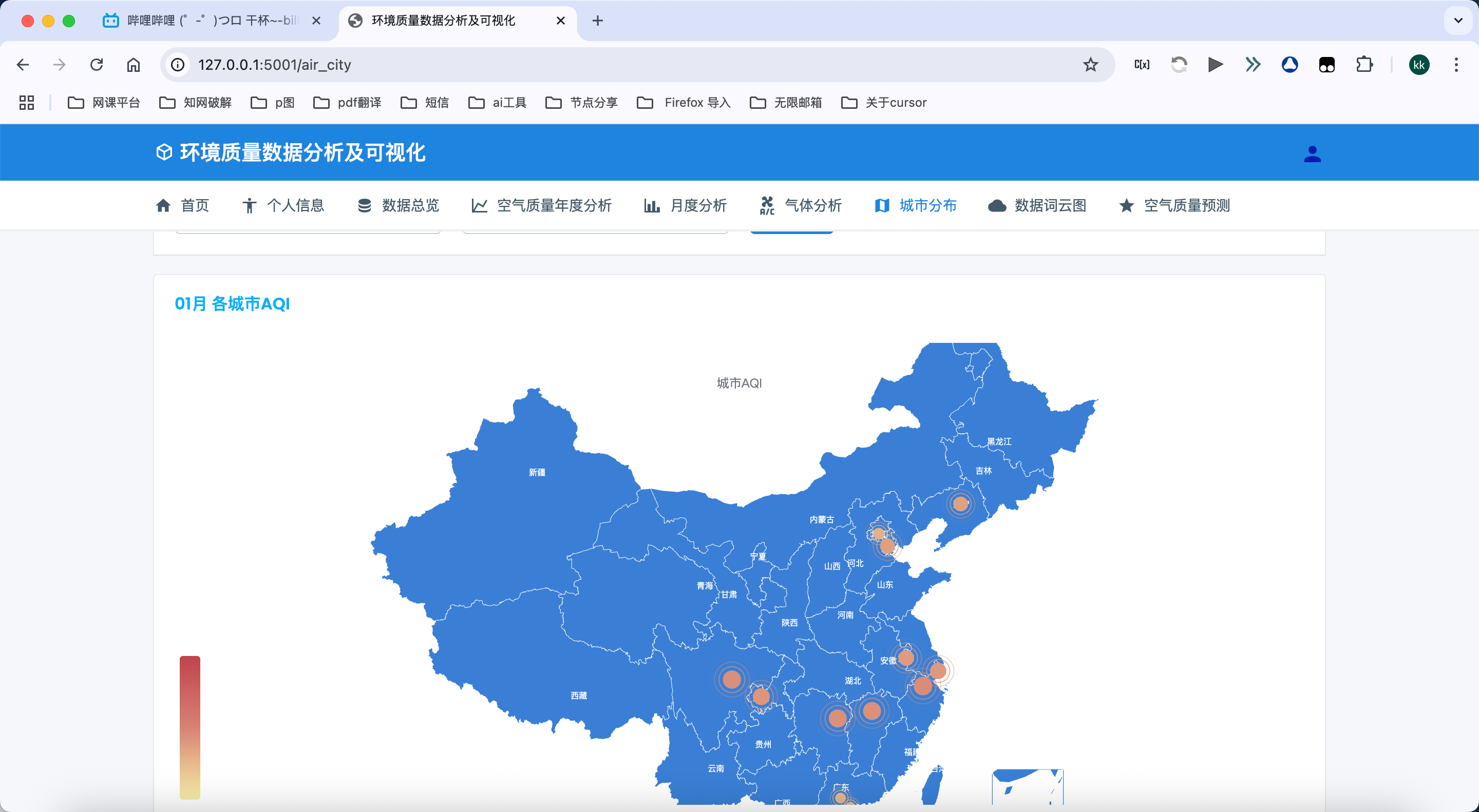
城市AQI地图展示:
- 通过地图形式直观展示不同城市的AQI指数分布
- 使用颜色梯度表示AQI级别,反映区域空气质量差异
- 支持按年份和月份筛选,展示特定时期的空气质量分布
- 提供地图缩放和鼠标悬停查看详情功能,增强用户体验
-
城市间空气质量对比:
- 多维度对比分析不同城市的空气质量状况
- 通过柱状图对比展示多个城市的平均AQI、PM2.5、PM10等指标
- 计算并展示城市间污染物浓度的差异百分比,突出显示差异显著的城市
- 支持按年份和月份筛选,便于对比不同时期的城市空气质量差异
-
时间维度的城市空气质量变化:
- 展示不同时间段各城市空气质量的变化情况
- 通过热力图展示城市-时间空气质量变化矩阵,直观反映时空变化规律
- 计算并展示城市空气质量的改善率或恶化率,评估治理效果
- 支持多时间尺度分析,从日、月、季度到年度,全面把握变化趋势
7. 词云分析模块
-
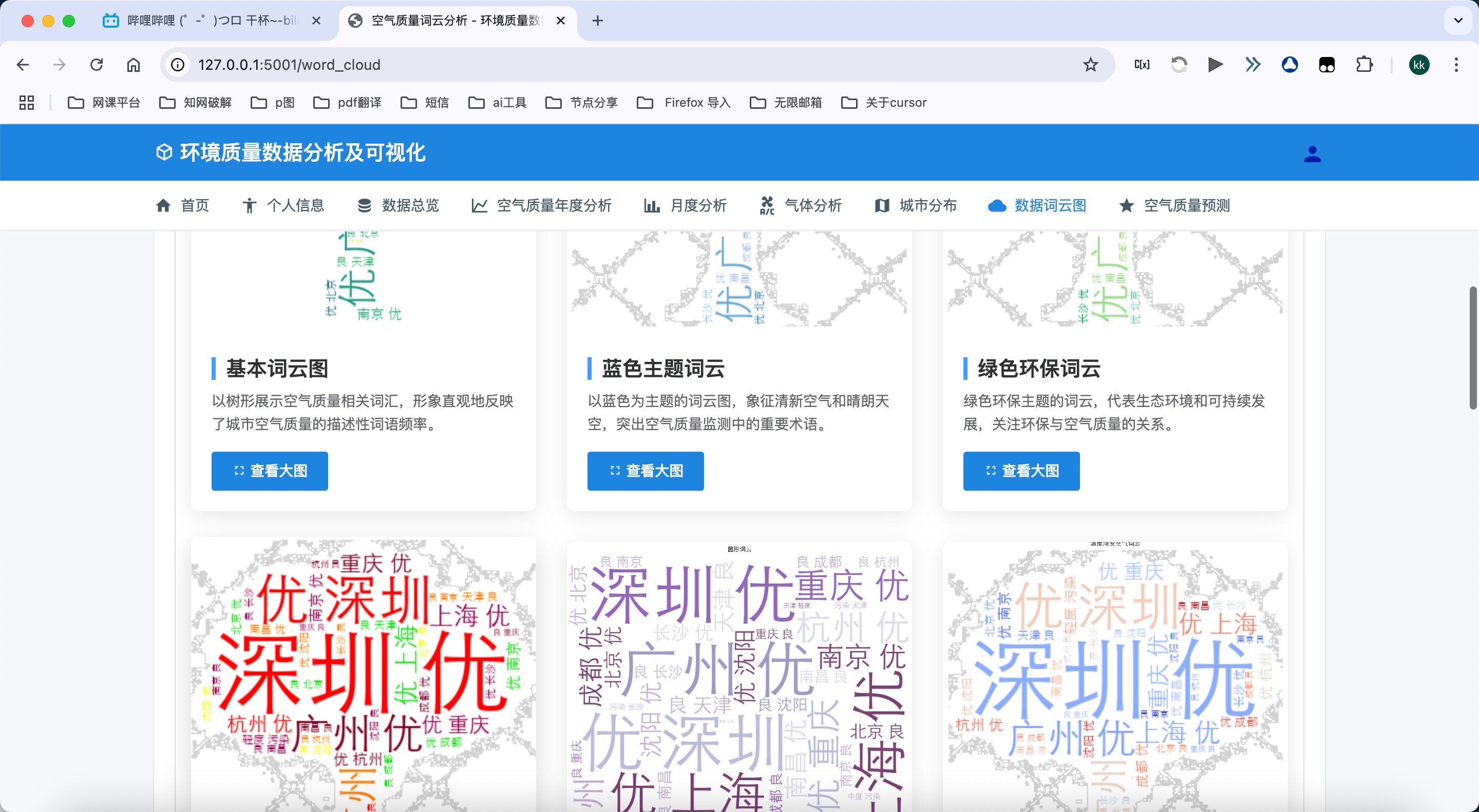
空气质量相关词云:
- 生成与空气质量相关的多种类型词云图,直观展示关键词分布
- 支持树形、圆形、心形、水滴形和星形等多种形状的词云生成
- 提供蓝色、绿色、红色、橙色、紫色、彩虹色等多种颜色方案
- 实现渐变色、彩虹色、暗黑主题和3D效果等多种特效词云,增强视觉冲击力
- 自动进行中文分词处理,支持多平台中文字体自适应,确保显示效果
-
词云元数据展示:
- 展示词云生成的相关元数据,包括词频统计、词云形状、颜色方案等
- 提供每种词云的详细说明,帮助用户理解词云的含义和特点
- 支持按词频排序展示关键词列表,直观反映重要概念
- 记录词云生成时间和参数设置,便于重复生成或调整参数
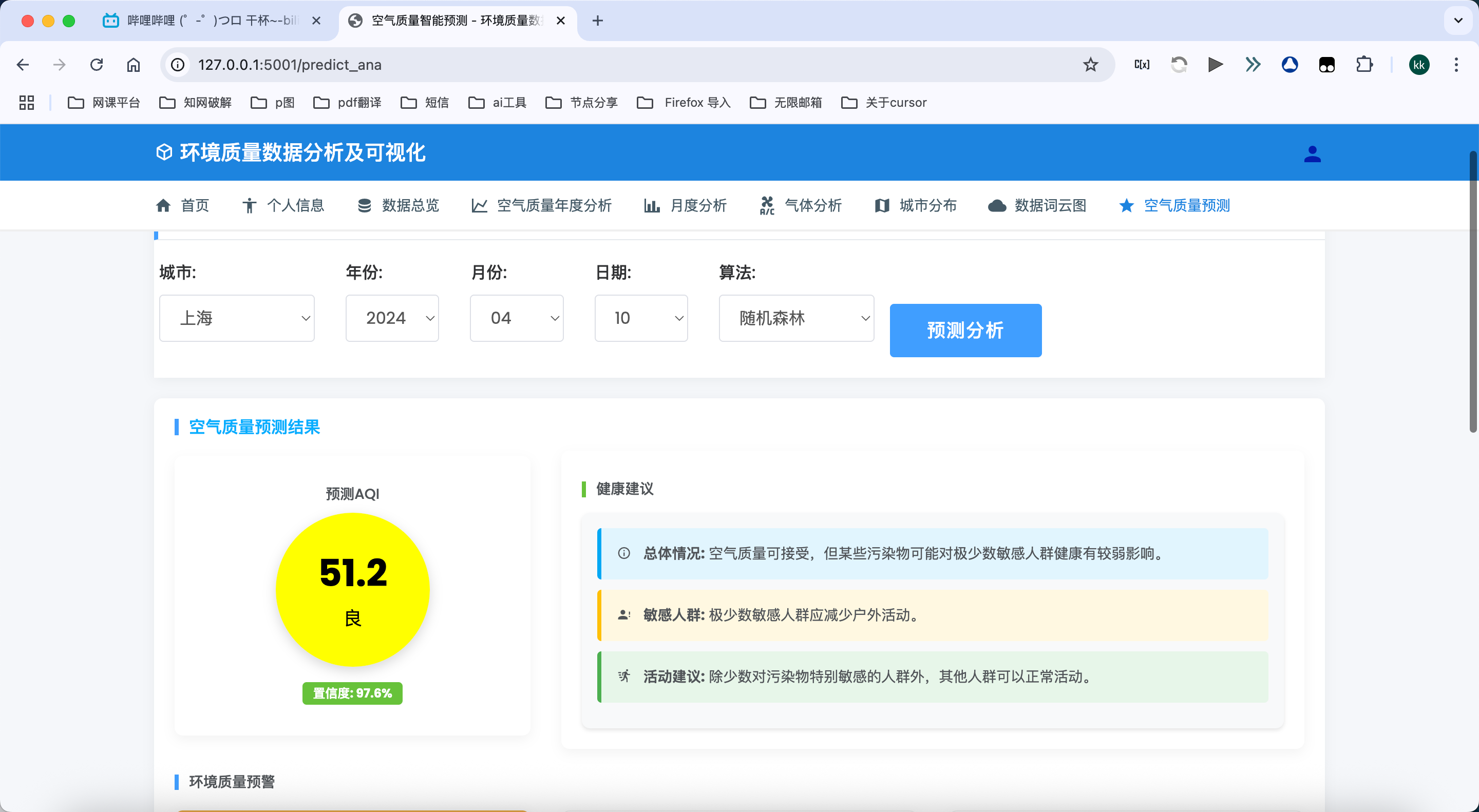
8. 空气质量预测分析模块
-
多算法预测支持:系统集成多种机器学习和深度学习算法,包括:
-
基础回归算法:
- 线性回归(Linear Regression):最基础的回归算法,通过拟合线性方程预测目标值。适用于变量间存在线性关系的数据,模型简单直观,计算效率高,但对非线性关系的拟合能力有限。
- 岭回归(Ridge Regression):添加L2正则化的线性回归,通过惩罚项控制模型复杂度,减少过拟合风险。适用于特征间存在高度相关性的情况,能有效处理多重共线性问题。
- Lasso回归(Lasso Regression):添加L1正则化的线性回归,能够自动进行特征选择,将不重要特征的系数压缩为零。适用于高维数据和需要稀疏解的场景,有助于提高模型的可解释性。
-
树模型算法:
- 决策树(Decision Tree):通过构建树形结构进行预测,每个节点表示对特征的判断条件。模型易于理解和解释,能够处理非线性关系,但容易过拟合,预测稳定性较差。
- 随机森林(Random Forest):集成多个决策树的算法,通过随机选择样本和特征构建多棵树,并将结果综合。具有较高的预测精度和稳定性,对异常值不敏感,但计算复杂度较高。
- 梯度提升决策树(GBDT):通过不断拟合残差来提高预测能力的集成算法,每棵树都是对前一棵树预测结果的修正。具有较高的预测精度,能够处理各种类型的数据,但调参复杂,训练速度较慢。
- XGBoost:高效的梯度提升实现,加入了正则化项控制模型复杂度,并引入二阶导数加速收敛。具有极高的预测精度和计算效率,支持并行计算,是目前最流行的机器学习算法之一。
- LightGBM:微软开发的高效梯度提升框架,采用基于直方图的算法和叶子优先生长策略,大幅提高训练速度。在保持高精度的同时显著降低内存消耗,适合大规模数据集。
-
其他机器学习算法:
- 支持向量回归(SVR):基于支持向量机的回归算法,通过核函数将数据映射到高维空间,寻找最优超平面。具有较强的非线性数据拟合能力和对噪声的鲁棒性,适合中小型复杂数据集。
-
深度学习算法:
- 多层感知机(MLP):使用多层神经网络进行回归预测,能够捕捉复杂的非线性关系。网络结构包含输入层、多个隐藏层和输出层,通过反向传播算法优化权重。适合复杂模式识别和高维特征空间的问题。
- 长短期记忆网络(LSTM):专为序列数据设计的递归神经网络,通过门控机制解决传统RNN的长期依赖问题。包含输入门、遗忘门和输出门三个门控单元,能有效处理长序列中的时间依赖关系,特别适合时间序列预测。
-
-
预测结果可视化:
- 直观展示预测结果,包括AQI预测值和实际值的对比图表
- 提供置信区间展示,反映预测结果的不确定性
- 通过颜色编码表示不同的空气质量等级,方便快速识别污染级别
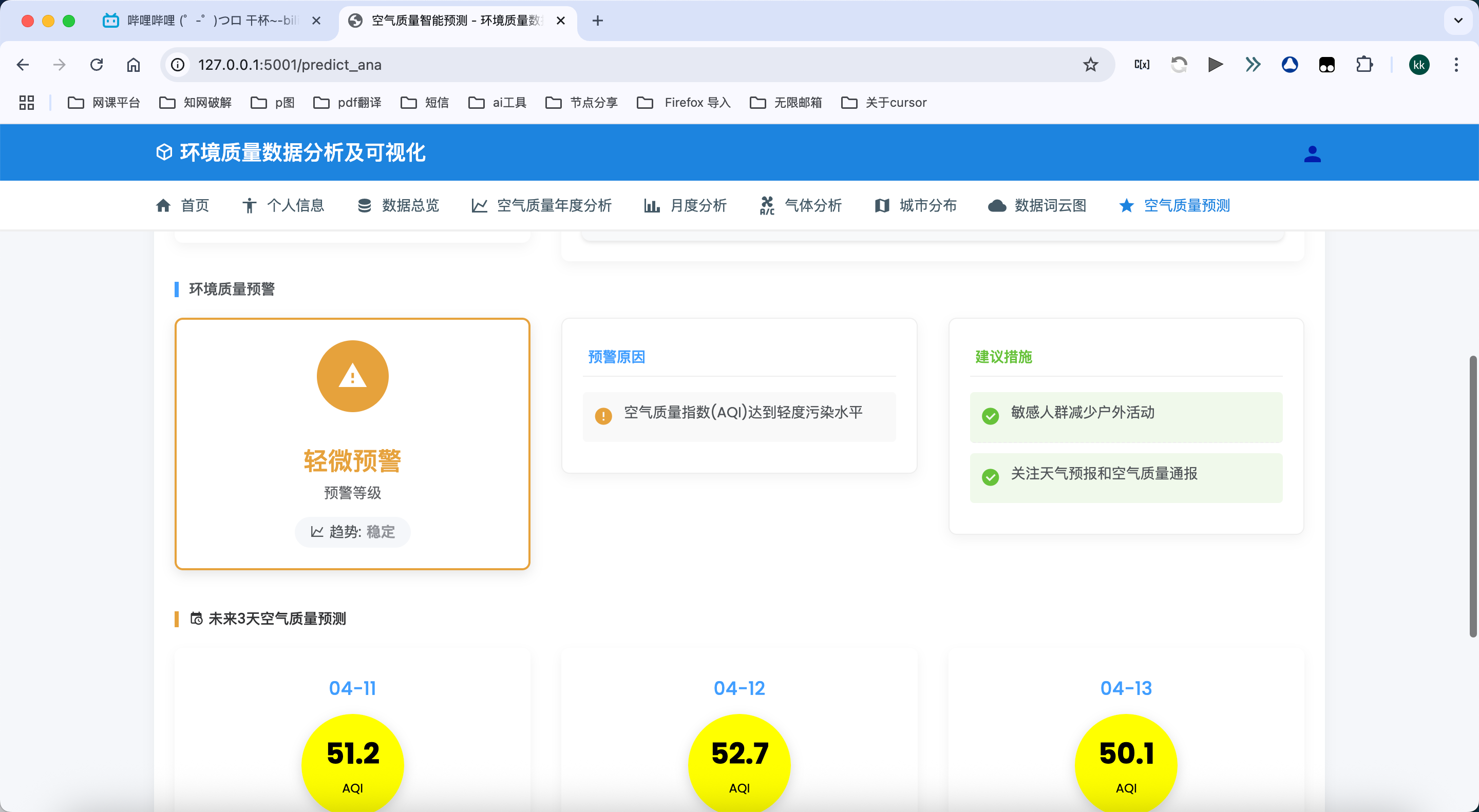
- 支持未来多天预测结果的图形化展示,帮助用户了解空气质量趋势
-
算法性能对比:
- 对比不同算法的预测性能,包括均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R²)等指标
- 通过柱状图直观展示各算法的性能指标对比,帮助选择最佳算法
- 提供详细的性能指标数据表,包含精确数值和百分比改进
- 自动对算法性能进行排名,突出显示性能最佳的算法
-
特征重要性分析:
- 分析影响空气质量的关键特征及其重要性
- 通过水平条形图直观展示各特征对预测结果的贡献程度
- 针对不同算法提取和展示特征重要性,揭示不同算法对特征的偏好
- 帮助理解污染物之间的相互关系和对空气质量的影响机制
-
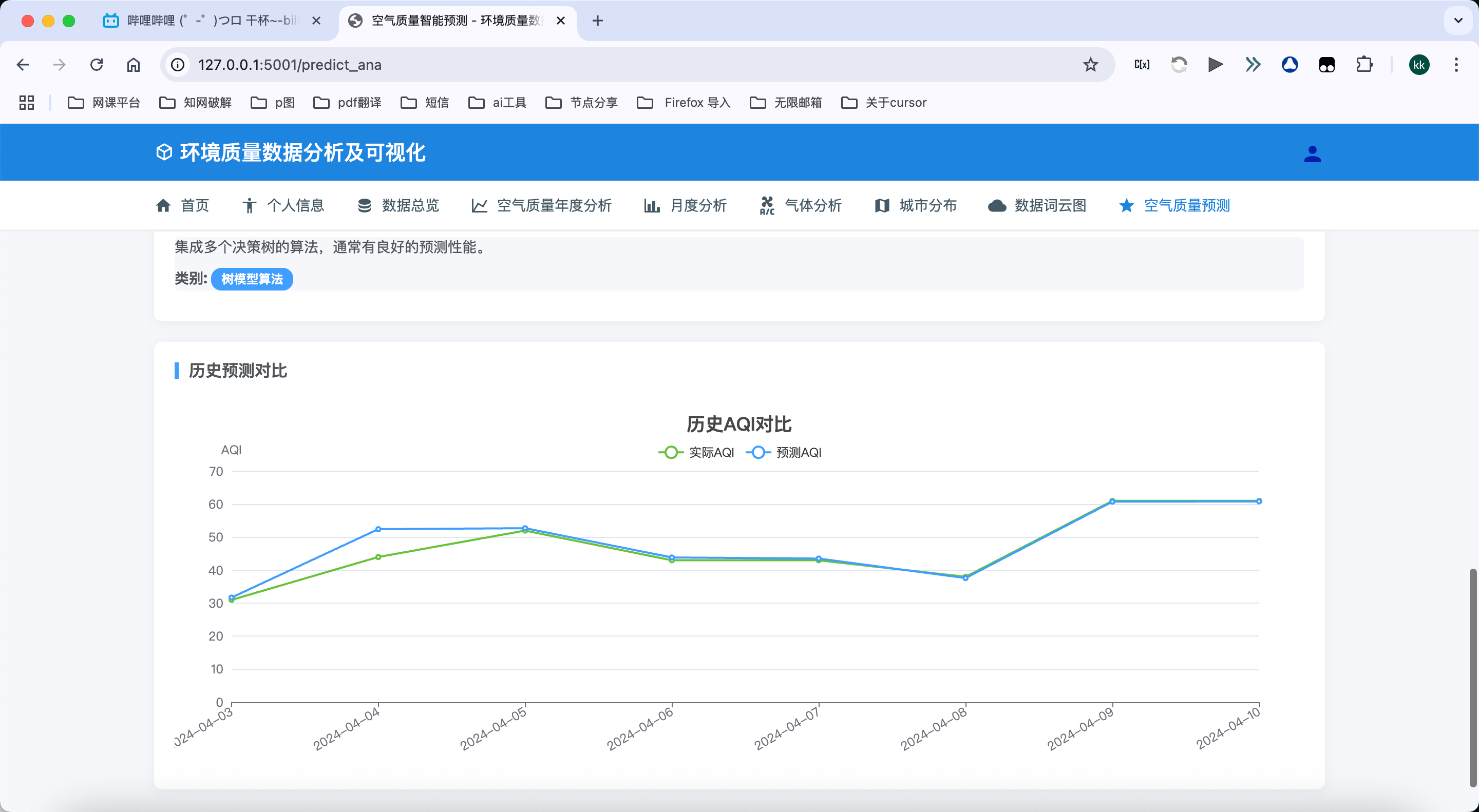
历史预测对比:
- 将历史预测结果与实际值进行对比分析
- 计算并展示预测准确率随时间的变化趋势
- 识别预测偏差较大的时段,分析可能的原因
- 支持不同算法历史预测结果的对比,评估算法的长期性能
技术架构
前端技术
- HTML/CSS/JavaScript:构建Web页面和用户界面,提供交互式体验
- Bootstrap:响应式页面布局框架,确保在不同设备上的良好显示效果
- ECharts:功能强大的数据可视化图表库,支持丰富的图表类型和交互效果
- jQuery:简化DOM操作和AJAX请求,提高前端开发效率
后端技术
- Python Flask:轻量级Web应用框架,处理HTTP请求和响应,提供路由管理和模板渲染
- Flask-Session:会话管理扩展,支持服务器端会话存储和管理
- Apache Spark:分布式大数据处理引擎,提供高效的数据分析和处理能力
- PySpark:Spark的Python API,支持使用Python编写Spark应用程序
- MySQL:关系型数据库,用于存储用户信息和处理后的分析数据
- PyMySQL:Python的MySQL客户端库,提供数据库连接和操作接口
数据分析与机器学习
- NumPy/Pandas:科学计算和数据处理库,提供高效的数组运算和数据操作功能
- Scikit-learn:功能全面的机器学习算法库,提供各类回归、分类和聚类算法
- TensorFlow/Keras:深度学习框架,支持构建和训练复杂的神经网络模型
- XGBoost/LightGBM:高效的梯度提升实现,提供卓越的预测性能
- Matplotlib/Seaborn:强大的数据可视化库,支持创建各类统计图表
数据处理流程
- 数据采集:通过专业爬虫从权威环境监测网站获取城市空气质量数据,确保数据的准确性和时效性
- 数据预处理:使用Spark对原始数据进行清洗、转换和规范化,包括缺失值处理、异常值检测和数据类型转换
- 数据分析:利用Spark SQL进行数据聚合、统计和分析,包括城市平均AQI计算、污染物分类统计和时间序列分析
- 结果存储:将分析结果存入MySQL数据库不同的表中,便于后续查询和展示
- 数据可视化:通过Web界面将数据以各类图表形式展示,提供直观的数据分析结果
- 模型训练与预测:基于历史数据训练多种机器学习模型,预测未来空气质量,并保存训练好的模型
数据库设计
系统使用MySQL数据库存储数据,主要包含以下表:
- air_data:存储原始空气质量数据,包括城市、日期、AQI、空气质量等级和六项污染物浓度
- tbl_user:存储用户信息,包括用户名、密码和其他用户属性
- city_avg_aqi:存储城市平均AQI数据,用于城市空气质量概览分析
- city_avg_six_gas:存储城市六种气体污染物(PM2.5、PM10、SO2、NO2、CO、O3)的平均浓度值
- city_year_month_max_min_aqi:存储城市年月最大和最小AQI值,用于分析空气质量的波动性
- city_avg_pm:存储城市PM2.5和PM10的年月平均值,用于分析颗粒物污染情况
- city_year_month_good_air:存储城市年月空气质量优良天数,用于评估空气质量整体水平
- city_max_so2_no2:存储城市SO2和NO2的最大值,用于分析气体污染物的极端情况
- co_category:存储CO浓度分类统计结果,反映CO污染的整体水平分布
- o3_category:存储O3浓度分类统计结果,反映臭氧污染的严重程度分布
- city_year_month_avg_aqi:存储城市年月平均AQI值,用于分析空气质量的时间变化趋势
系统特色
- 大数据处理能力:利用Spark分布式计算框架进行高效的大数据处理和分析,支持海量空气质量数据的快速处理
- 多维度分析:从时间(日、月、年)、空间(不同城市)、污染物类型等多个维度全面分析空气质量数据
- 丰富的可视化:提供柱状图、折线图、饼图、热力图、地图等多种图表类型,直观展示分析结果
- 先进的预测算法:集成10余种机器学习和深度学习算法,提供高精度的空气质量预测
- 用户友好界面:简洁直观的用户界面,良好的交互体验,便于用户操作和数据查看
- 灵活的筛选功能:支持按城市、时间等条件灵活筛选数据,满足不同分析需求
- 实时数据更新:支持数据的定期更新和实时分析,保持数据的时效性
- 词云特效分析:提供多种形状、多种特效的词云图生成,创新性地展示空气质量关键词分布
应用场景
- 环境监测部门:为环保部门提供空气质量监测和分析工具,帮助评估环境治理效果
- 城市规划:为城市规划提供空气质量数据支持,辅助制定环境友好型城市发展策略
- 公共健康研究:分析空气质量与公共健康的关系,为疾病预防和健康保护提供数据基础
- 环保政策制定:为环保政策的制定提供数据支持,帮助评估政策实施效果
- 个人健康管理:帮助个人了解所在城市的空气质量状况和预测趋势,做好健康防护
系统价值
- 数据可视化:将复杂的空气质量数据转化为直观的图表,降低理解难度,提高分析效率
- 趋势预测:通过机器学习算法预测未来空气质量趋势,为环境管理和个人防护提供前瞻性指导
- 多维分析:从多个维度分析空气质量数据,揭示潜在的规律和关联,深化对空气污染机制的理解
- 决策支持:为环保决策提供数据支持和科学依据,提高决策的科学性和有效性
- 公众教育:提高公众对空气质量的认识和关注度,促进环保意识的提升和环保行动的参与
作者:Vx:1837620622
邮箱:2040168455@qq.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









