






协程
程序:为了完成特定任务,使用某种语言编写的一组指令的集合,是一段静态的代码
进程:是程序的一次执行过程。正在运行的一个程序,进程作为资源分配的单位,在内存中会为每个进程分配不同的内存区域。进程是动态的,有产生、存在、消亡的过程
线程:进程可进一步细分为线程,是一个程序内部的一条执行路径,若一个进程同一时间并行执行多个线程,就是支持多线程的
协程:又称为微线程、纤程,协程是一种用户态的轻量级线程 作用:在执行A函数的时候可以随时中断去执行B函数,然后中断继续执行A函数(可以自由切换),注意这一切换过程并不是函数调用,过程很像多线程,但是实际只是一个线程,有一个特点就是主死从随(协程随着主线程死亡一起死亡)
类似如下图所示,将消耗时间和资源的io操作放在一边
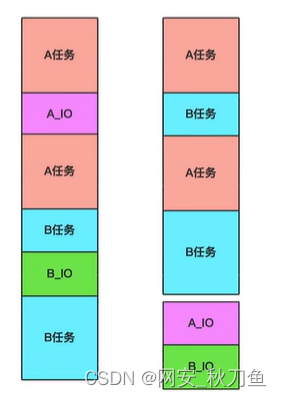
对于单线程下,我们不可避免程序中出现i0操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在-个任务遇到io阻塞时就将寄存器上下文和栈保存到某个其他地方,然后切换到另外一个任务去计算。在任务切回来的时候,恢复先前保存的寄存器上下文和栈,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的i0操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而会更多的将cpu的执行权限分配给我们的线程(注意:线程是CPU控制的,而协程是程序自身控制的,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级)
一、协程
单个协程
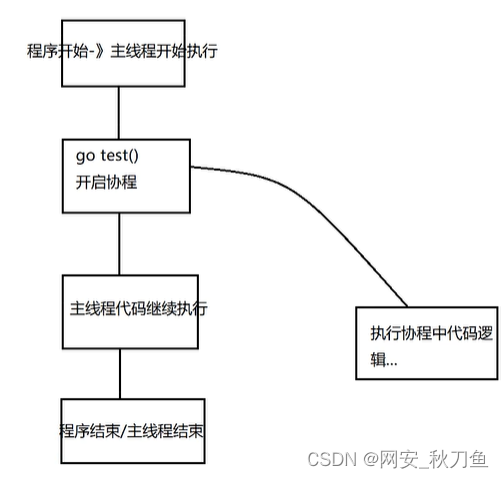
go语言开启协程非常简单,只需在调用函数前加一个go
例: go test()
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("hello golang", strconv.Itoa(i))
//阻塞1s
time.Sleep(time.Second * 1)
}
}
func main() { //主线程
go test() //开启协程
for i := 1; i <= 10; i++ {
fmt.Println("hello 秋刀鱼", strconv.Itoa(i))
//阻塞1s
time.Sleep(time.Second * 1)
}
}
在这里加入
time.Sleep(time.Second * 1)
是为了防止主线程死掉导致没有时间给协程
运行结果:
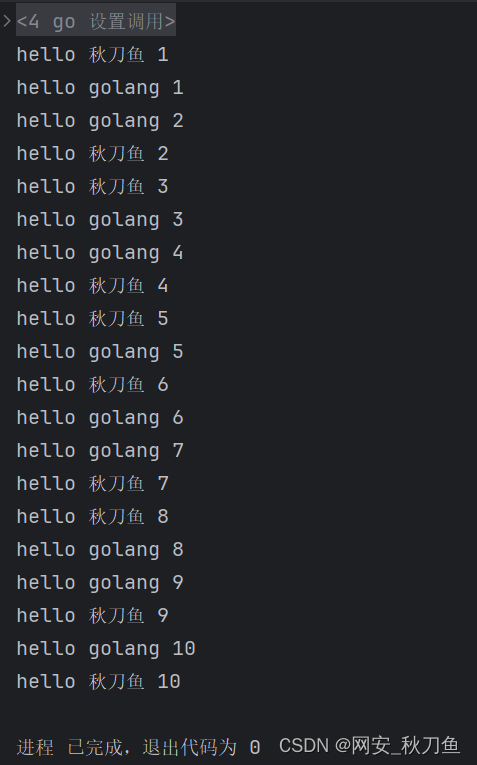
查看结果就会发现在交替运行
多个协程
func main() { //主线程
for i := 0; i <= 5; i++ {
// 启动多个协程 (使用匿名函数)
go func() {
fmt.Println(i)
}()
}
time.Sleep(1 * time.Second)
}
输出

为什么输出的不是1 2 3 4 5 6
这是因为for循环在这里是主线程,协程输出的是i变量是共享主线程的i,可能导致这种情况
想要输出无重复,直接将协程的匿名函数加一个变量,将i传入就去就行
二、WaitGroup
WaitGroup用于等待一组线程的结束,父线程调用Add方法来设定应等待的线程的数量。每个被等待的线程在结束时应调用Done方法。同时主线程里可以调用Wait方法阻塞至所有线程结束。—》解决主线程在子协程结束后自动结束
阻塞主线程,等待协程结束一起结束
// 只定义无需赋值
var wg sync.WaitGroup
func main() { //主线程
for i := 1; i <= 5; i++ {
wg.Add(1) //协程开始的时候加1
go func(n int) {
fmt.Println("hello world", n)
wg.Done() //协程结束的时候减1
}(i)
}
// 阻塞主线程 当wg减为0的时候阻塞就停止
wg.Wait()
}
var wg sync.WaitGroup 首先定义一个变量 数据类型为sync包内一个名为WaitGroup的结构体
wg.Add(1)然后在计数器内加入协程数量
wg.Done()每结束一次协程就减去1
wg.Wait()阻塞主线程 当wg减为0的时候阻塞就停止
多个协程操作同一个数据案例
多个协程操作同一个数据会导致结果不理想
请阅读下列代码
// 只定义无需赋值
var wg sync.WaitGroup
var totalNum int
func add() {
defer wg.Done()
for i := 0; i < 100000; i++ {
totalNum += 1
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000; i++ {
totalNum -= 1
}
}
func main() { //主线程
wg.Add(2)
go add()
go sub()
wg.Wait()
time.Sleep(time.Second * 2)
fmt.Println(totalNum)
}
在理想的情况下,不管两个协程的函数如何交替,最后输出的结果都应该为0,但是这里输出的是
每次执行结束结果都不一定,为什么呢
请看下图是两个函数交替执行一个轮回的图
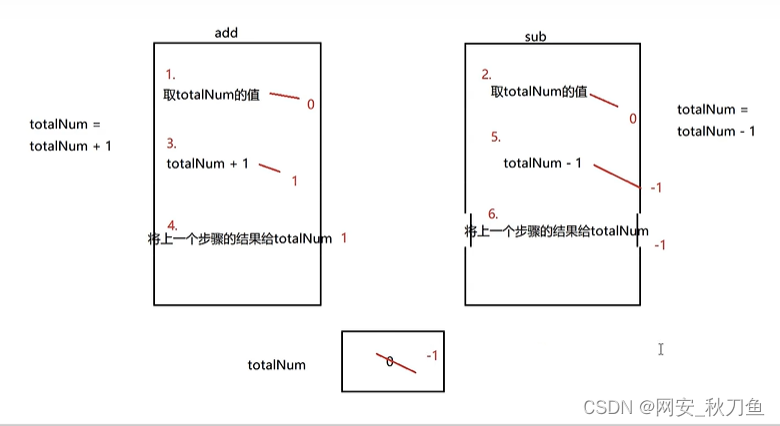
解读:
假如第一步执行的是add函数首先获取原始totalNum的值,为0,然后第二部是sub函数获取原始totalNum的值,为0,第三、四步add函数对totalNum进行加一操作并赋值给totalNum,但是第五第六步却是将totalNum的原始数据0减1后赋值给totalNum,导致一轮下来不会为0
所以说直接使用多协程操作同一个数据会导致资源竞争问题
每次执行结束结果都不一定,为什么呢
请看下图是两个函数交替执行一个轮回的图
[外链图片转存中…(img-NkB0TRcZ-1718868327943)]
解读:
假如第一步执行的是add函数首先获取原始totalNum的值,为0,然后第二部是sub函数获取原始totalNum的值,为0,第三、四步add函数对totalNum进行加一操作并赋值给totalNum,但是第五第六步却是将totalNum的原始数据0减1后赋值给totalNum,导致一轮下来不会为0
所以说直接使用多协程操作同一个数据会导致资源竞争问题
互斥锁
由多个协程操作同一个数据案例所展现的问题来看,需要一个机制来确保一个协程在执行的时候其他协程不执行,这就得用上互斥锁了
互斥锁概念:其中Mutex为互斥锁,Lock()加锁,Unlock()解锁,使用Lock()加锁后,便不能再次对其进行加锁,直到利用Unlock()解锁对其解锁后,才能再次加锁,适用于读写不确定场景,即读写次数没有明显的区别
创建互斥锁:
var lock sync.Mutex
加锁:
lock.Lock()
解锁:
lock.Unlock()
加锁后的完整代码
// 只定义无需赋值
var wg sync.WaitGroup
var totalNum int
// 加入互斥锁
var lock sync.Mutex
func add() {
defer wg.Done()
for i := 0; i < 100000; i++ {
// 加锁
lock.Lock()
totalNum += 1
// 解锁
lock.Unlock()
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000; i++ {
// 加锁
lock.Lock()
totalNum -= 1
// 解锁
lock.Unlock()
}
}
func main() { //主线程
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(totalNum)
}
执行后达成理想状态,结果为0
读写锁
RWMutex是一个读写锁,其经常用于读次数远远多于写次数的场景,和互斥锁的区别:读写锁只锁住写的操作
在读的时候,数据之间不产生影响,写和读之间才会产生影响
创建读写锁:
var lock sync.RWMutex
加锁:
lock.RLock()
闭锁:
lock.RUnlock()
上代码案例
var wg sync.WaitGroup
// 加入读写锁
var lock sync.RWMutex
func read() {
defer wg.Done()
// 如果只是读数据,那么这个锁不产生影响,但是读写同时发生的时候,就会有影响
lock.RLock()
fmt.Println("开始读取数据")
time.Sleep(time.Second) //模拟读的时间
fmt.Println("读取数据成功")
lock.RUnlock()
}
func write() {
defer wg.Done()
lock.RLock()
fmt.Println("开始修改数据")
time.Sleep(time.Second * 10) //模拟写的时间
fmt.Println("修改数据成功")
lock.RUnlock()
}
func main() { //主线程
wg.Add(6)
// 启动协程 ---> 场合:读多写少
for i := 0; i < 5; i++ {
go read()
}
go write()
wg.Wait()
}
执行后结果
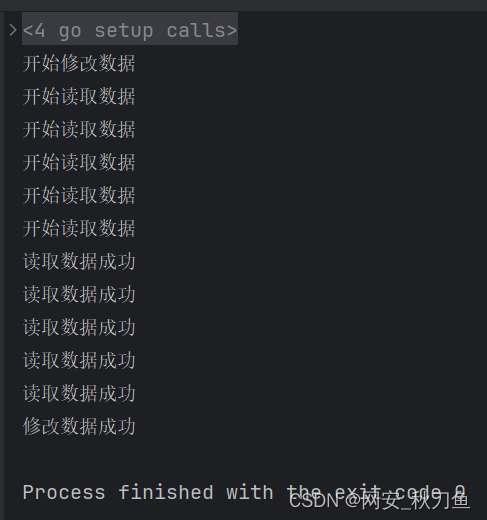
















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









