







一、项目介绍

二、简单的神经网络项目
深度学习的目的是为了得到一个好的模型
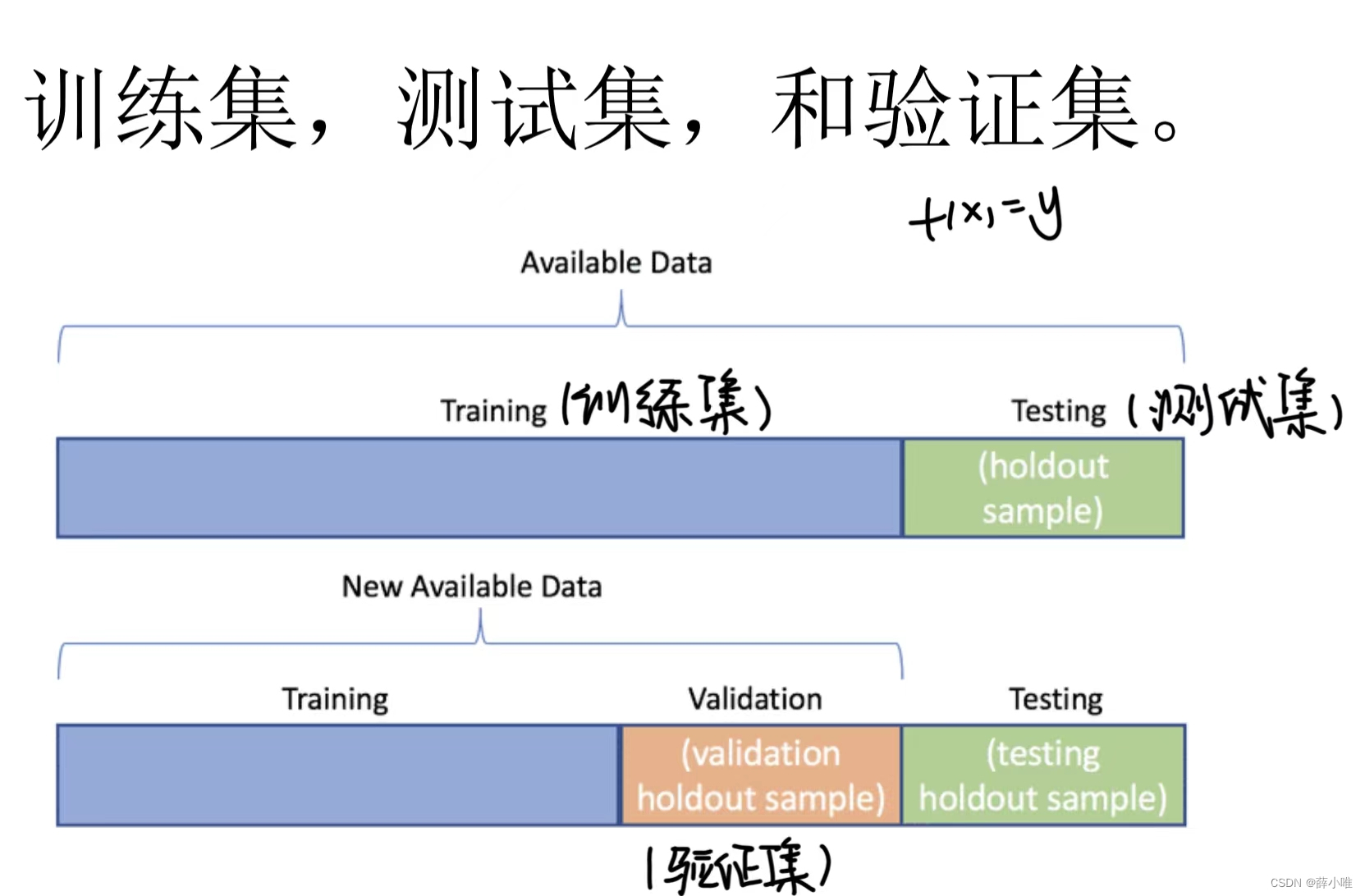
1.Data
一般输入是文件地址,或者数据内容,输出是一个存储了数据X,Y的数据结构。
torch中一般用dataloader来装载
Data分为训练集,测试集和验证集
Dataset:(数据集函数定义)

class Covid_dataset(Dataset):
def __init__(self,file_path,mode,dim=4,all_feature=True):#mode告诉数据集类型 训练集或测试集
#读文件
with open(file_path,"r") as f: #"r"以读的方式
csv_data = list(csv.reader(f))
data = np.array(csv_data[1:]) #去掉第一行
#取矩阵形式的数据 逢5扣1
#确定行 确定训练集和验证集
if mode == "train":
indices = [i for i in range(len(data)) if i % 5 !=0]
elif mode == "val":
indices = [i for i in range(len(data)) if i % 5 ==0]
if all_feature:
col_idx = [i for i in range(0, 93)]
else:
_, col_idx = get_feature_importance(data[:, 1:-1], data[:, -1],k=dim,column=csv_data[0][1:-1]) # 挑中了想要的列
if mode == "test": #测试集 不要第一列转换为float型
x = data[:,1:].astype(float)
x = torch.tensor(x[:,col_idx]) #转换为张量
else:
x = data[indices,1:-1].astype(float) #不是测试集,行不是所有行,列不包括最后一列 最后一列为y
x = torch.tensor(x[:,col_idx])
y = data[indices,-1].astype(float)
self.y = torch.tensor(y)
#列x归一化 减去平均值除以标准差 keepdim 保持形状
self.x = (x-x.mean(dim=0,keepdim=True))/x.std(dim=0,keepdim=True)
self.mode = mode
#取下标的值的函数
def __getitem__(self, item):
if self.mode == "test":
return self.x[item].float()
else:
return self.x[item].float(), self.y[item].float()
def __len__(self):
return len(self.x)
定义训练集、验证集、测试集
#两个数据 数据有三个函数
train_file = "covid.train.csv"
test_file = "covid.test.csv"
#读数据
# data = pd.read_csv(train_file)
# print(data.head()) #读出前五行
#定义训练集 验证集 测试集
train_data = Covid_dataset(train_file,"train",dim = dim,all_feature=all_feature) #all_feature为true表示不挑取特征 false为挑取
val_data = Covid_dataset(train_file,"val",dim = dim,all_feature=all_feature)
test_data = Covid_dataset(test_file,"test",dim = dim,all_feature=all_feature)
#一次取16个数据 shuffle 打乱数据 一批一批取数据
#装入dataloader
train_loader = DataLoader(train_data,batch_size=16,shuffle=True)
val_loader = DataLoader(val_data,batch_size=16,shuffle=True)
#测试集不打乱
test_loader = DataLoader(test_data,batch_size=1,shuffle=False)调试数据函数
for batch_x,batch_y in train_loader:
print(batch_x,batch_y)2.Model
定义自己的模型:输入X,输出预测值 定义f
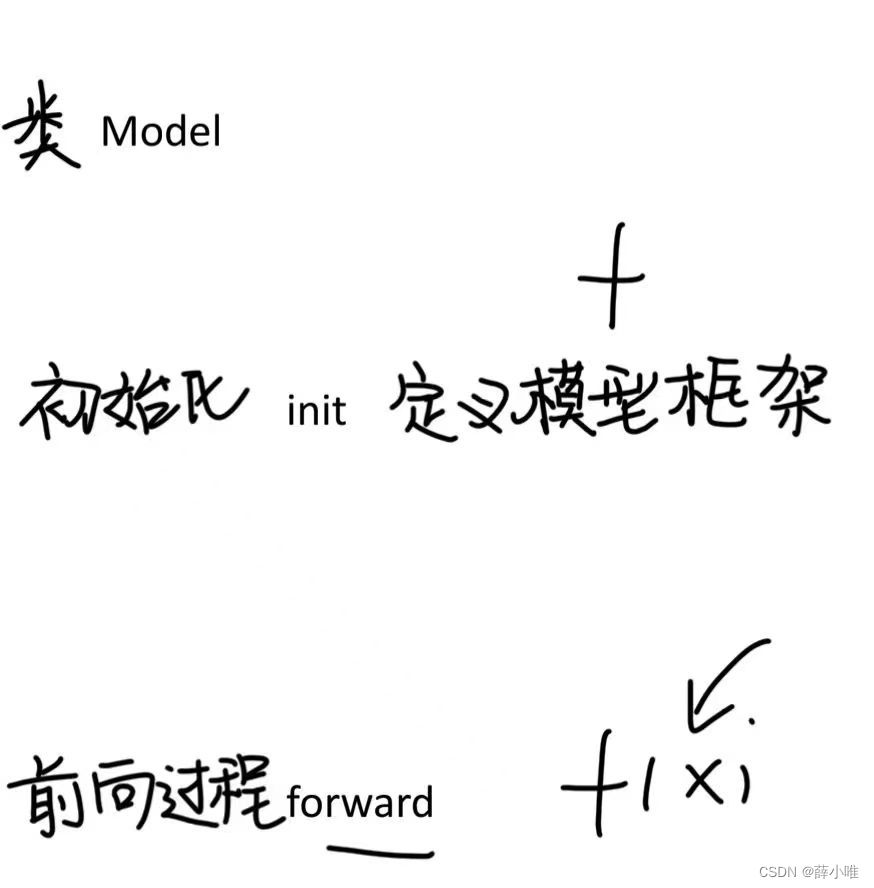
#二、Model:定义自己的模型 输入x,输出预测值 f 模型:维度变化 参数量
#定义模型框架 nn.module torch里面模型的父类
class myModel(nn.Module): #搭建框架
def __init__(self,dim): #修改父类的初始化 dim维度 输入维度 维度变化
super(myModel, self).__init__()
#模型的第一层
self.fc1 = nn.Linear(dim,100) #维度
self.relu = nn.ReLU() #激活函数
self.fc2 = nn.Linear(100,1) #只有两层全连接
def forward(self,x):#前向 数据一步一步通过模型
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
#输出的维度要和真实的维度一样 预测值和真实值的维度一样
if len(x.size())>1:
x = x.squeeze(dim=1) #把张量降低一维
return x
model = myModel(dim)3.hyperPara(除模型外的超参数)
一般包含:设备,学习率,优化器,损失函数,epochs等
#将参数值写入字典中
#超参数
config = {
"lr" : 0.001,
"momentum" : 0.9,
"epochs" : 20,
"save_path" : "model_save/model.pth" , # 在训练集上训练,在验证集上验证 保存路径
"rel_path" : "pred_csv"
}
#设备 如果 torch和cuda两个是适配的就在Gpu上算,否则就在cpu上算
device = "cuda" if torch.cuda.is_available() else "cpu"
#loss函数
loss = nn.MSELoss()
#优化器 momentum 动量 model.parameters()模型参数 lr 学习率
optimizer = optim.SGD(model.parameters(),lr=config["lr"],momentum=config["momentum"])4.训练流程
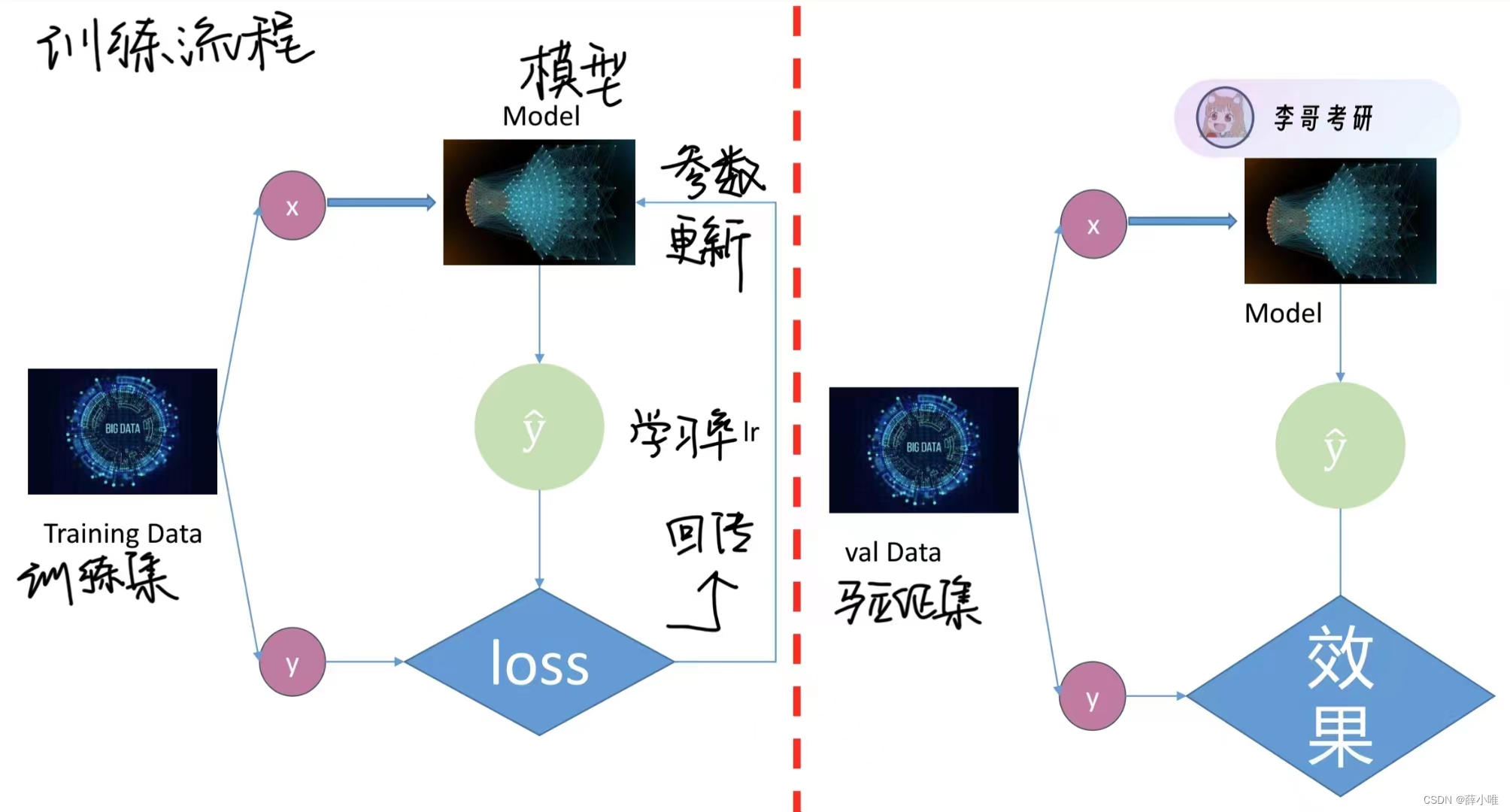
训练函数
#训练流程 训练得到一个比较好的模型 保存在save_path
train_val(model,train_loader,val_loader,device,config["epochs"],optimizer,loss,config["save_path"])#训练过程 (固定的)
def train_val(model,train_loader,val_loader,device,epochs,optimizer,loss,save_path):
model = model.to(device) #将模型放在gpu上面 模型在gpu上训练
#记录训练集 验证集上loss是怎么变化的
plt_train_loss = []
plt_val_loss = []
min_val_loss = 9999999999
#训练的标志
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
start_time = time.time()
model.train() #将模型设置为训练模式
for batch_x,batch_y in train_loader: #取数据
x, target = batch_x.to(device), batch_y.to(device) #把数据放在gpu上
pred = model(x) #一旦数据经过模型,就会积攒梯度 前向过程
train_bat_loss = loss(pred,target) #损失函数
train_bat_loss.backward() #梯度回传过程
#优化器
optimizer.step() #更新参数的过程
optimizer.zero_grad() #梯度归零
train_loss += train_bat_loss.cpu().item() #将数据取下来 训练的总loss
plt_train_loss.append(train_loss/train_loader.dataset.__len__()) #loss的均值
#训练完验证 测试模式 看模型效果
model.eval()
with torch.no_grad(): #验证时不更新参数 不积攒梯度
for batch_x, batch_y in val_loader: # 取数据
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 一旦数据经过模型,就会积攒梯度 前向过程
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
if val_loss < min_val_loss:
torch.save(model, save_path) #保存模型
min_val_loss = val_loss
#每一轮训练的plt_train_loss,plt_val_loss都记载在最后一位
print("[%03d/%03d] %2.2f secs Trainloss: %.6f Valloss: %.6f"%(epoch,epochs,time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))
#画图
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend("train", "val") #标签
plt.show()
5.验证,运用训练好的模型预测
验证函数
#加载最好的模型 最后保存在rel_path
evaluate(config["save_path"], device, test_loader, config["rel_path"])def evaluate(save_path, device, test_loader, rel_path):
model = torch.load(save_path).to(device) #加载模型放在gpu上
rel = [] #将结果记录在表中
model.eval() #将模型设置为验证模式
with torch.no_grad(): #不积攒梯度
for x in test_loader: #取数据
pred = model(x.to(device))
rel.append(pred.cpu().item()) #将记录结果放在rel上 rel为张量
print(rel)
#将结果写在文件上
with open(rel_path, "w") as f: #w写 先打开文件
csv_writer = csv.writer(f)
csv_writer.writerow(["id", "tested_positive"])
#写数据
for i in range(len(rel)):
csv_writer.writerow([str(i), str(rel[i])])
print("文件已经保存到"+rel_path)三、项目创新点

1.正则化
#创新点 自己定义MSELoss 平滑 防止过拟合
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项 平滑 防止过拟合
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失
loss = mseLoss() #定义mseloss 即 平方差损失2.相关系数:线性相关
#直接用 相关性 线性相关
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
feature_data,label_data 要求字符串形式
k为选择的特征数量
如果需要打印column,需要传入行名
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。四、完整代码
import time #计算时间的包
import matplotlib.pyplot as plt
import torch
#读数据
from torch.utils.data import DataLoader,Dataset #写数据集时使用 引入两个类
import csv #读csv文件
import pandas as pd #pandas读数据
import numpy as np #矩阵,张量计算
import torch.nn as nn
from torch import optim
from sklearn.feature_selection import SelectKBest,chi2
#直接用 相关性 线性相关
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
feature_data,label_data 要求字符串形式
k为选择的特征数量
如果需要打印column,需要传入行名
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
#神经网络项目
# 一、Data 输入文件地址,或者数据内容,输出是一个存储了数据X,Y的数据结构,torch中一般用dataloader来装载
#流感数据集
class Covid_dataset(Dataset):
def __init__(self,file_path,mode,dim=4,all_feature=True):#mode告诉数据集类型 训练集或测试集
#读文件
with open(file_path,"r") as f: #"r"以读的方式
csv_data = list(csv.reader(f))
data = np.array(csv_data[1:]) #去掉第一行 第一行为列名
#取矩阵形式的数据 逢5扣1
#确定行 确定训练集和验证集
if mode == "train":
indices = [i for i in range(len(data)) if i % 5 !=0] #列表形式
elif mode == "val":
indices = [i for i in range(len(data)) if i % 5 ==0]
if all_feature:
col_idx = [i for i in range(0, 93)]
else:
_, col_idx = get_feature_importance(data[:, 1:-1], data[:, -1],k=dim,column=csv_data[0][1:-1]) # 挑中了想要的列
if mode == "test": #测试集 不要第一列转换为float型
x = data[:,1:].astype(float)
x = torch.tensor(x[:,col_idx]) #转换为张量
else:
x = data[indices,1:-1].astype(float) #不是测试集,行不是所有行,列不包括最后一列 最后一列为y
x = torch.tensor(x[:,col_idx])
y = data[indices,-1].astype(float) #train val 既有x,也有y
self.y = torch.tensor(y)
#列x归一化 减去平均值除以标准差 keepdim 保持形状
self.x = (x-x.mean(dim=0,keepdim=True))/x.std(dim=0,keepdim=True)
self.mode = mode
#取下标的值的函数
def __getitem__(self, item):
if self.mode == "test":
return self.x[item].float()
else:
return self.x[item].float(), self.y[item].float()
def __len__(self):
return len(self.x)
#二、Model:定义自己的模型 输入x,输出预测值 f 模型:维度变化 参数量
#定义模型框架 nn.module torch里面模型的父类
class myModel(nn.Module): #搭建框架
def __init__(self,dim): #修改父类的初始化 dim维度 输入维度 维度变化
super(myModel, self).__init__()
#模型的第一层
self.fc1 = nn.Linear(dim,100) #维度
self.relu = nn.ReLU() #激活函数
self.fc2 = nn.Linear(100,1) #只有两层全连接
def forward(self,x):#前向 数据一步一步通过模型
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
#输出的维度要和真实的维度一样 预测值和真实值的维度一样
if len(x.size())>1:
x = x.squeeze(dim=1) #把张量降低一维
return x
#训练过程 (固定的)
def train_val(model,train_loader,val_loader,device,epochs,optimizer,loss,save_path):
model = model.to(device) #将模型放在gpu上面 模型在gpu上训练
#记录训练集 验证集上loss是怎么变化的
plt_train_loss = []
plt_val_loss = []
min_val_loss = 9999999999
#训练的标志
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
start_time = time.time()
model.train() #将模型设置为训练模式
for batch_x,batch_y in train_loader: #取数据
x, target = batch_x.to(device), batch_y.to(device) #把数据放在gpu上
pred = model(x) #一旦数据经过模型,就会积攒梯度 前向过程
train_bat_loss = loss(pred,target) #损失函数
train_bat_loss.backward() #梯度回传过程
#优化器
optimizer.step() #更新参数的过程
optimizer.zero_grad() #梯度归零
train_loss += train_bat_loss.cpu().item() #将数据取下来 训练的总loss
plt_train_loss.append(train_loss/train_loader.dataset.__len__()) #loss的均值
#训练完验证 测试模式 看模型效果
model.eval()
with torch.no_grad(): #验证时不更新参数 不积攒梯度
for batch_x, batch_y in val_loader: # 取数据
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 一旦数据经过模型,就会积攒梯度 前向过程
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
if val_loss < min_val_loss:
torch.save(model, save_path) #保存模型
min_val_loss = val_loss
#每一轮训练的plt_train_loss,plt_val_loss都记载在最后一位
print("[%03d/%03d] %2.2f secs Trainloss: %.6f Valloss: %.6f"%(epoch,epochs,time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))
#画图
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend("train", "val") #标签
plt.show()
def evaluate(save_path, device, test_loader, rel_path):
model = torch.load(save_path).to(device) #加载模型放在gpu上
rel = [] #将结果记录在表中
model.eval() #将模型设置为验证模式
with torch.no_grad(): #不积攒梯度
for x in test_loader: #取数据
pred = model(x.to(device))
rel.append(pred.cpu().item()) #将记录结果放在rel上 rel为张量
print(rel)
#将结果写在文件上
with open(rel_path, "w") as f: #w写 先打开文件
csv_writer = csv.writer(f)
csv_writer.writerow(["id", "tested_positive"])
#写数据
for i in range(len(rel)):
csv_writer.writerow([str(i), str(rel[i])])
print("文件已经保存到"+rel_path)
# train_data = Covid_dataset(train_file,"train")
#
# #一次取16个数据 shuffle 打乱数据 一批一批取数据
# train_loader = DataLoader(train_data,batch_size=16,shuffle=True)
# model = myModel(93)
#
# for batch_x,batch_y in train_loader:
# print(batch_x,batch_y)
# pred = model(batch_x) #传入x直接进入forward函数
#三、hyperPara:除模型外的超参数 一般包含:学习率,优化器,损失函数 回归损失函数
#维度
all_feature = True
if all_feature:
dim = 93
else:
dim = 6
#如果 torch和cuda两个是适配的就在Gpu上算,否则就在cpu上算
device = "cuda" if torch.cuda.is_available() else "cpu"
# print(device)
#两个数据 数据有三个函数
train_file = "covid.train.csv"
test_file = "covid.test.csv"
#读数据
# data = pd.read_csv(train_file)
# print(data.head()) #读出前五行
#定义训练集 验证集 测试集
train_data = Covid_dataset(train_file,"train",dim = dim,all_feature=all_feature) #all_feature为true表示不挑取特征 false为挑取
val_data = Covid_dataset(train_file,"val",dim = dim,all_feature=all_feature)
test_data = Covid_dataset(test_file,"test",dim = dim,all_feature=all_feature)
#一次取16个数据 shuffle 打乱数据 一批一批取数据
#装入dataloader
train_loader = DataLoader(train_data,batch_size=16,shuffle=True)
val_loader = DataLoader(val_data,batch_size=16,shuffle=True)
#测试集不打乱
test_loader = DataLoader(test_data,batch_size=1,shuffle=False)
# for batch_x,batch_y in train_loader:
# print(batch_x,batch_y)
#超参数
config = {
"lr" : 0.001,
"momentum" : 0.9,
"epochs" : 20,
"save_path" : "model_save/model.pth" , # 在训练集上训练,在验证集上验证 保存路径
"rel_path" : "pred_csv"
}
model = myModel(dim)
#loss函数
loss = nn.MSELoss()
#创新点 自己定义MSELoss
# def mseLoss(pred, target, model):
# loss = nn.MSELoss(reduction='mean')
# ''' Calculate loss '''
# regularization_loss = 0 # 正则项 平滑 防止过拟合
# for param in model.parameters():
# # TODO: you may implement L1/L2 regularization here
# # 使用L2正则项
# # regularization_loss += torch.sum(abs(param))
# regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
# return loss(pred, target) + 0.00075 * regularization_loss # 返回损失
# loss = mseLoss() #定义mseloss 即 平方差损失
#优化器 momentum 动量 model.parameters()模型参数 lr 学习率
optimizer = optim.SGD(model.parameters(),lr=config["lr"],momentum=config["momentum"])
#训练流程 训练得到一个比较好的模型 保存在save_path
train_val(model,train_loader,val_loader,device,config["epochs"],optimizer,loss,config["save_path"])
#加载最好的模型 最后保存在rel_path
evaluate(config["save_path"], device, test_loader, config["rel_path"])















 4888
4888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









