







目录
类功能
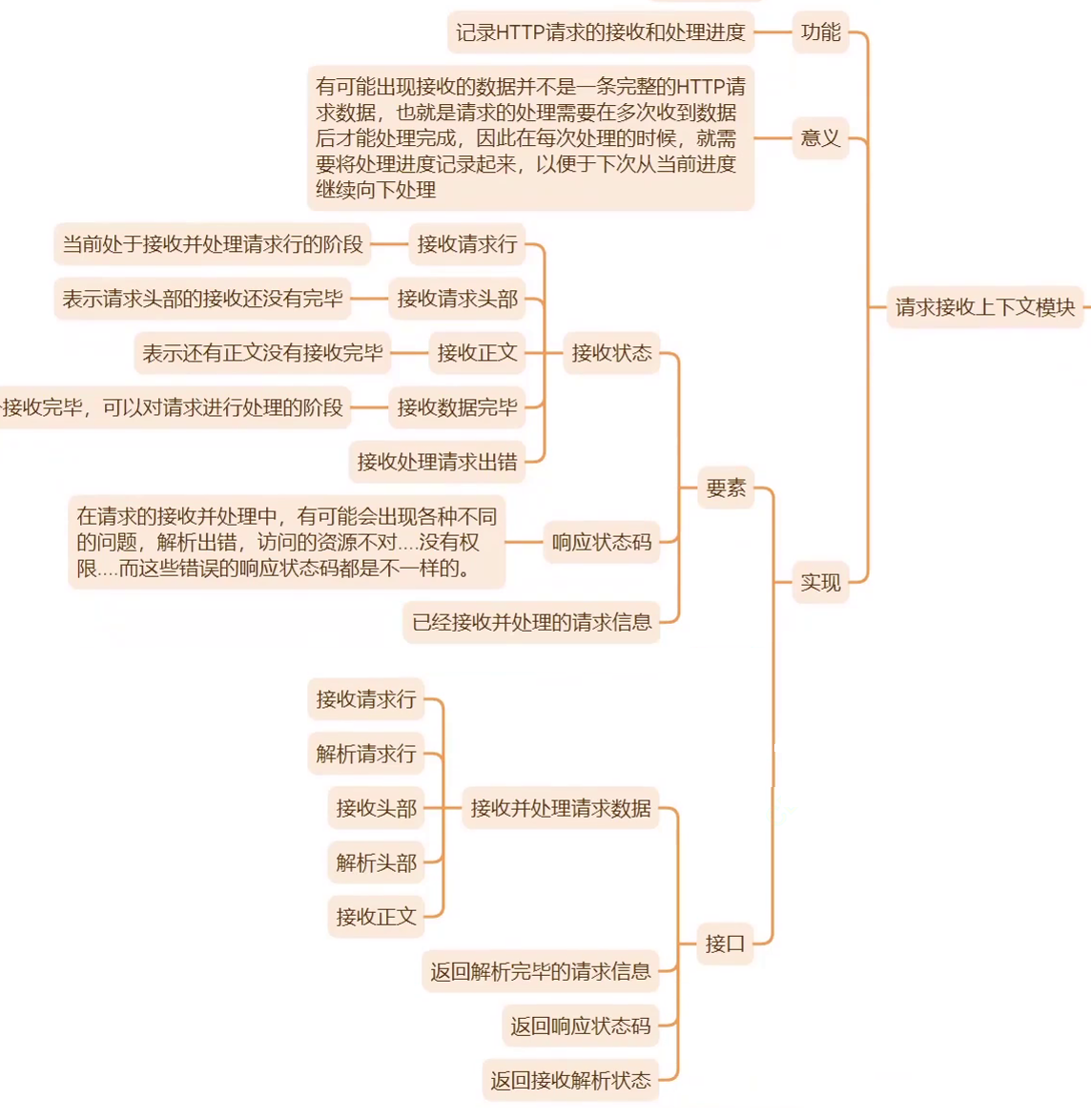
类定义
// HttpContext接收请求上下文模块功能设计
typedef enum
{
RECV_HTTP_ERROR,
RECV_HTTP_LINE,
RECV_HTTP_HEAD,
RECV_HTTP_BODY,
RECV_HTTP_OVER
} HttpRecvStatu;
class HttpContext
{
private:
int _resp_statu; // 响应状态码
HttpRecvStatu _recv_statu; // 当前接收及解析的阶段状态
HttpRequest _request; // 已经解析得到的请求信息
private:
bool ParseHttpLine(); // 解析请求行
bool RecvHttpLine();
bool RecvHttpHead();
bool ParseHttpHead();
bool RecvHttpBody();
public:
HttpContext();
int RespStatu();
HttpRecvStatu RecvStatu();
HttpRequest &Request();
void RecvHttpRequest(); // 接收并解析HTTP请求
};类实现
// HttpContext接收请求上下文模块功能设计
typedef enum
{
RECV_HTTP_ERROR,
RECV_HTTP_LINE,
RECV_HTTP_HEAD,
RECV_HTTP_BODY,
RECV_HTTP_OVER
} HttpRecvStatu;
#define MAX_LINE 8192 // 8K
class HttpContext
{
private:
int _resp_statu; // 响应状态码
HttpRecvStatu _recv_statu; // 当前接收及解析的阶段状态
HttpRequest _request; // 已经解析得到的请求信息
private:
// 解析请求行
bool ParseHttpLine(const std::string &line)
{
std::smatch matches;
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?");
bool ret = std::regex_match(line, matches, e);
if (ret == false)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400; // BAD REQUEST
return false;
}
// 0 : GET /qingfeng/login?user=xiaoming&pass=123123 HTTP/1.1
// 1 : GET
// 2 : /qingfeng/login
// 3 : user=xiaoming&pass=123123
// 4 : HTTP/1.1
// 请求方法的获取
_request._method = matches[1];
// 资源路径的获取,需要进行URL解码操作,但是不需要+转空格
_request._path = Util::UrlDecode(matches[2], false);
// 协议版本的获取
_request._version = matches[4];
// 查询字符串的获取与处理
std::vector<std::string> query_string_arry;
std::string query_string = matches[3];
// 查询字符串的格式, key=val&key=val......, 先以 & 符号进行分割,得到各个子串
Util::Split(query_string, "&", &query_string_arry);
// 针对各个子串,以 = 符号进行分割,得到 key 和 val, 得到之后也需要进行URL解码
for (auto &str : query_string_arry)
{
size_t pos = str.find("=");
if (pos == std::string::npos)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400; // BAD REQUEST
return false;
}
std::string key = Util::UrlDecode(str.substr(0, pos), true);
std::string val = Util::UrlDecode(str.substr(pos + 1), true);
_request.SetParam(key, val);
}
return true;
}
// 获取请求行
bool RecvHttpLine(Buffer *buf)
{
if (_recv_statu != RECV_HTTP_LINE)
return false;
// 1. 获取一行数据
std::string line = buf->GetLineAndPop();
// 2. 需要考虑的一些要素,缓冲区的数据不足一行, 获取的一行数据超大
if (line.size() == 0)
{
// 缓冲区中的数据不足一行,则需要判断缓冲区的可读数据长度,如果很长了都不足一行,这是有问题的
if (buf->ReadAbleSize() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414; // URI TOO LONG 查看statu文件中可以看到414状态对应的信息
return false;
}
// 缓冲区中数据不足一行,但是也不多,就等待新数据的到来
return true;
}
if (line.size() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414; // URI TOO LONG
return false;
}
bool ret = ParseHttpLine(line);
if (ret == false)
return false;
// 首行处理完毕,进入头部处理阶段
_recv_statu == RECV_HTTP_HEAD;
return true;
}
bool RecvHttpHead(Buffer *buf)
{
// 状态不对直接返回
if (_recv_statu != RECV_HTTP_HEAD)
return false;
// 一行一行取出数据,直到遇到空行为止,头部的格式 key: val\r\nkey: val\r\n......
while (1)
{
std::string line = buf->GetLineAndPop();
// 2. 需要考虑的一些要素,缓冲区的数据不足一行, 获取的一行数据超大
if (line.size() == 0)
{
// 缓冲区中的数据不足一行,则需要判断缓冲区的可读数据长度,如果很长了都不足一行,这是有问题的
if (buf->ReadAbleSize() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414; // URI TOO LONG 查看statu文件中可以看到414状态对应的信息
return false;
}
// 缓冲区中数据不足一行,但是也不多,就等待新数据的到来
return true;
}
if (line.size() > MAX_LINE)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414; // URI TOO LONG
return false;
}
if (line == "\n" || line == "\r\n")
break;
bool ret = ParseHttpHead(line);
if (ret == false)
return false;
}
// 头部处理完毕,进入正文处理阶段
_recv_statu == RECV_HTTP_BODY;
return true;
}
bool ParseHttpHead(const std::string &line)
{
// key: val\r\nkey: val\r\n......
size_t pos = line.find(": ");
if (pos == std::string::npos)
{
if (pos == std::string::npos)
{
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400; // BAD REQUEST
return false;
}
std::string key = line.substr(0, pos);
std::string val = line.substr(pos + 2);
_request.SetHeader(key, val);
}
}
bool RecvHttpBody(Buffer *buf)
{
if (_recv_statu != RECV_HTTP_BODY)
return false;
// 1. 获取正文长度
size_t content_length = _request.ContentLength();
if (content_length == 0)
{
// 没有正文,则请求接收解析完毕
_recv_statu = RECV_HTTP_OVER;
return true;
}
// 2. 当前已经接收了多少正文 取决于_request._body, 其中放了多少数据
size_t real_len = content_length - _request._body.size(); // 实际还需要接收的正文长度
// 3. 接收正文放到body中,但是也要考虑当前缓冲区中的数据,是否是全部的正文
// 3.1 缓冲区中的数据,包含了当前请求的所有正文,则取出所需的数据
if (buf->ReadAbleSize() >= real_len)
{
_request._body.append(buf->ReadPosition(), real_len);
buf->MoveReadOffset(real_len);
_recv_statu = RECV_HTTP_OVER;
return true;
}
// 3.2 缓冲区中的数据,无法满足当前正文的需要,数据不足,取出数据,然后等待新数据到来
_request._body.append(buf->ReadPosition(), buf->ReadAbleSize());
buf->MoveReadOffset(buf->ReadAbleSize());
return true;
}
public:
HttpContext() : _resp_statu(200), _recv_statu(RECV_HTTP_LINE) {}
void ReSet()
{
_resp_statu = 200;
_recv_statu = RECV_HTTP_LINE;
_request.ReSet();
}
int RespStatu() { return _resp_statu; }
HttpRecvStatu RecvStatu() { return _recv_statu; }
HttpRequest &Request() { return _request; }
// 接收并解析HTTP请求
void RecvHttpRequest(Buffer *buf)
{
// 不同的状态,做不同的事情,但是这里不要break,因为处理完请求行后,应该立即处理头部,而不是退出等待新数据的到来
// 后面并不需要break,因为要保证后续都解析完,并且不用担心接收失败
// 在各个函数的开头就检查了处理阶段,如果不对就会错误返回了
switch (_recv_statu)
{
case RECV_HTTP_LINE:
RecvHttpLine(buf);
case RECV_HTTP_HEAD:
RecvHttpHead(buf);
case RECV_HTTP_BODY:
RecvHttpBody(buf);
}
return;
}
};编译测试
关于正则表达式的使用可以参考之前的文章
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











