






使用说明
1、分组不连续排序(跳跃排序)
rank() over(partition by order by )
partition by用于对数据进行分组,它和聚合函数使用group by分组不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只返回一条反映统计值的记录。
order by用于对每个分组内的记录进行排序。
有两个相同值都排第二名时,接下来就是第四名(同样是在各个分组内)。
举个例子:
模拟一个场景,有一个比较时髦的学校决定借助大数据技术来提高教学质量,其中就有一张表存放了全校每个学生的考试成绩,按照学期进行分区,创建这张表:
create table t_score (
class string,
name string,
score int
) partitioned by (term string);
insert into t_score partition (term="201702")
values
("一班", "小黑", 80),
("一班", "小白", 90),
("一班", "小赤", 100),
("二班", "小橙", 80),
("二班", "小红", 90),
("二班", "小绿", 100),
("三班", "小青", 90),
("三班", "小蓝", 100),
("三班", "小紫", 100);
现在校长想知道在2017年下学期的考试中一年级三个班级的学生考试分数的排名情况:
select *, rank() over (partition by class order by score desc) from t_score where term="201702";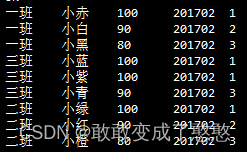
仔细看下查询结果,我们会发现这样一种情况,三班的排名出现了两个并列第一,然后紧接着就是第三名,没有第二名了,按照我们一般的想法,如果有并列的话那么后面的就会排名提前,使用dense_rank可以实现这个效果。
2、分组连续排序
dense_rank() over(partition by order by )
select *, dense_rank() over (partition by class order by score desc) from t_score where term="201702";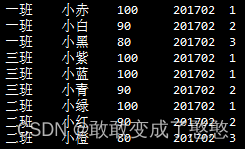
三班的两个相同分数并列第一,然后紧接着就是第二名。
dense的意思是稠密的,dense_rank()稠密意味着生成的排名序列中没有空隙(连续的),而rank()生成的排名序列中可能有空隙(可能是不连续的)。
但是这时候校长不高兴了,他不喜欢这种并列的排名方式,他说要重新制定排名规则:
首先按照成绩排序
成绩相同的不要并列,而是再按照姓名排序,姓氏靠后的认倒霉吧
对于成绩和姓名都完全相同的情况,校长大人没有指定就假装不存在这种情况好啦
没办法,校长最大,只能再改下我们的sql,因为rank在生成排名序列的时候都会出现并列的情况,稀的稠的都不行,所以不能采用rank这种方式了,不过没事我们还有招,还有一个叫做row_number的函数,它不考虑并列的情况,就是单纯的排序,按照顺序挨个的发序号。
3、分组不会出现相同排序
row_number() over(partition by order by )
row_number()不会出现相同排序,就算两条记录参与排序的字段数值一样,排序也是不一样。
select *, row_number() over (partition by class order by score desc, name) from t_score where term="201702";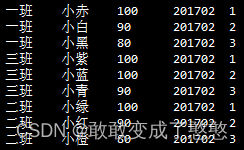
没有出现并列的情况,最后校长又补充了一个需求,就是不分班级统计排名,而是全年级拉通排名。
4、不分组排序
rank() over(order by )
partition by如果没有指定的话,那么它把整个结果集作为一个分组,即不分组排序
select *, row_number() over (order by score desc, name) from t_score where term="201702";
总结一下:
rank / dense_rank / row_number的语法都是一样的,不同的只是几个特性:
rank / dense_rank / row_number从1开始排序,均返回bigint数据类型字段;
rank / dense_rank都考虑了并列的情况,所以序号可能不唯一(所以不要用rank() 和dense_rank()函数来剔重),rank在出现并列之后会不连续,而dense_rank是连续的;
row_number不考虑并列的情况,所以序号是唯一的(可以使用row_number()来删除重复数据),并且也不会出现序号不连续。
原文链接:https://blog.csdn.net/baidu_38432186/article/details/110238317















 2026
2026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









