







本文章以python为例!
一、力扣第1281题:整数的各位积和之差
问题描述:
1281. 整数的各位积和之差
给你一个整数 n,请你帮忙计算并返回该整数「各位数字之积」与「各位数字之和」的差。
示例 1:
输入:n = 234
输出:15
解释:
各位数之积 = 2 * 3 * 4 = 24
各位数之和 = 2 + 3 + 4 = 9
结果 = 24 - 9 = 15
示例 2:
输入:n = 4421
输出:21
解释:
各位数之积 = 4 * 4 * 2 * 1 = 32
各位数之和 = 4 + 4 + 2 + 1 = 11
结果 = 32 - 11 = 21
提示:
1 <= n <= 10^5
解题思路:把n的数值转换为字符串,然后分成一个一个的,方便逐位处理。然后逐个遍历,最后用乘积减去和,返回结果。
算法描述:
初始化两个变量 x 和 y 分别为1和0,用来分别表示各位数字之积和各位数字之和。
将整数 n 转换为字符串 a,方便逐位处理。
遍历字符串 a 中的每个字符,每次迭代都执行以下步骤: a. 将当前字符转换为整数 s。 b. 计算 x *= s,将当前字符的值与 x 相乘,更新各位数字之积。 c. 计算 y += s,将当前字符的值与 y 相加,更新各位数字之和。
循环结束后,计算 result = x - y,得到各位数字之积与各位数字之和的差值。
返回 result 作为最终结果。
时间复杂度分析:
这个算法的时间复杂度取决于整数 n 的位数,设 n 有 k 位数字。因为需要将 n 转换成字符串,并且对每个位上的数字进行遍历,所以时间复杂度为 O(k)。
题解:
class Solution:
def subtractProductAndSum(self, n: int) -> int:
x=1
y=0
a=str(n)
for b in a:
s=int(b)
x*=s
y+=s
result=x-y
return result讨论与总结:
这是一道较为简单的算法题目,很容易就有解题思路,但是用的是python,习惯了c语言的代码编程,有点不适应,经过这道题目,初步掌握了python的一些基础代码。
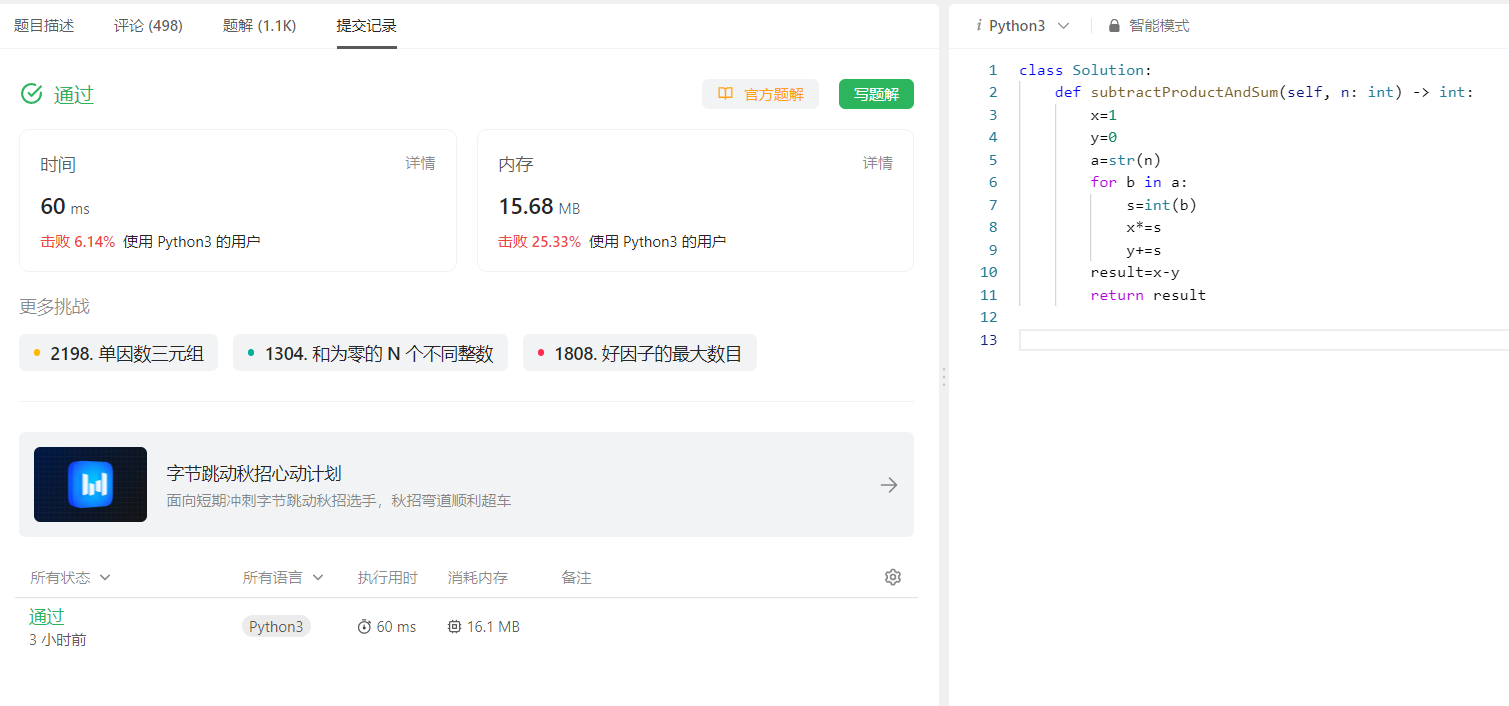
- 力扣提交结果(截图贴到答案框,截图应该能看到你的代码以及提交记录)
二、力扣:面试题 01.01. 判定字符是否唯一
题目:
实现一个算法,确定一个字符串 s 的所有字符是否全都不同。
示例 1:
输入: s = "leetcode"
输出: false
示例 2:
输入: s = "abc"
输出: true
限制:
0 <= len(s) <= 100s[i]仅包含小写字母- 如果你不使用额外的数据结构,会很加分。
方法一:
解题方法
利用set特性去重,再与原字符串比较长度是否相等。
class Solution:
def isUnique(self, astr: str) -> bool:
return len(set(astr)) == len(astr)这段代码的工作原理:
-
class Solution::这行代码定义了一个名为Solution的类。这个类通常用于封装解决特定问题的方法和功能。 -
def isUnique(self, astr: str) -> bool::这是Solution类中的一个方法定义。它声明了一个名为isUnique的方法,接受一个参数astr,该参数是一个字符串,并且返回一个布尔值(-> bool表示返回值类型为布尔型)。 -
return len(set(astr)) == len(astr):这是isUnique方法的实现。它使用了Python中的一些内置函数和数据结构来判断字符串中的字符是否都是唯一的。具体步骤如下:-
set(astr):首先,将输入字符串astr转换为一个集合(set)。集合是一种无序、不重复的数据结构,它会自动去除重复的元素,只保留唯一的元素。 -
len(set(astr)):接下来,计算集合的长度,也就是集合中唯一元素的个数。 -
len(astr):同时,计算原始字符串astr的长度,也就是字符串中字符的总个数。 -
len(set(astr)) == len(astr):最后,将集合的长度与原始字符串的长度进行比较。如果它们相等,说明字符串中的字符都是唯一的,此时返回True;否则,返回False。
-
这个代码的核心思想是,如果一个字符串中的字符都是唯一的,那么将字符串转换为集合后,集合的长度应该与原始字符串的长度相等。如果有重复的字符存在,集合的长度会小于原始字符串的长度,因此返回False,表示字符串中存在重复字符。否则,返回True,表示字符串中的字符全部都是唯一的。这是一种简洁而有效的方法来解决判断字符串中字符唯一性的问题。
方法二:
解题思路
一看到题目想到的就是直接暴力,使用双重循环,逐一比较字符串中的字符是否相同。如果在任何时候找到相同的字符,就返回 False,否则在遍历完成后返回 True,表示字符串中的字符全部都是唯一的。这种实现方式没有使用额外的数据结构,适用于不使用额外空间的情况。
算法描述(可以使用代码加注释、伪代码、纯文字描述均可)、时间复杂度分析
算法描述:class Solution:
def isUnique(self, astr: str) -> bool:
# 使用双重循环来比较字符是否相同
for i in range(len(astr)):
for j in range(i + 1, len(astr)):
if astr[i] == astr[j]:
return False
# 如果没有找到相同的字符,返回True
return True
时间复杂度分析:这个算法的时间复杂度是O(n^2),其中n是字符串s的长度。
该算法使用了双重循环来比较字符串中的字符是否相同。外层循环需要遍历整个字符串,内层循环从外层循环的下一个字符开始遍历剩余字符。因此上述算法的时间复杂度为O(n^2)。
题解:
class Solution:
def isUnique(self, astr: str) -> bool:
for i in range(len(astr)):
for j in range(i + 1, len(astr)):
if astr[i] == astr[j]:
return False
return True讨论与总结
直接暴力时间复杂度比较高,而且没有什么学习价值,但是学习到了python的双重循环是怎么样写的。
方法三:
用Python编写一个不使用额外数据结构的算法来确定一个字符串的所有字符是否都不相同。一种方法是使用双重循环,但这不是最优解。更好的方法是使用位运算,因为你知道输入字符串只包含小写字母。
以下是一个示例代码,使用位运算来检查字符串是否包含重复字符:
class Solution:
def isUnique(self, astr: str) -> bool:
# 创建一个用于存储出现过的字符的位向量,初始值为0
char_set = 0
for char in astr:
# 计算字符的ASCII码值
char_val = ord(char)
# 使用位运算检查字符是否已经出现过
if (char_set & (1 << char_val)) > 0:
return False
# 将对应字符位置的位设为1
char_set |= (1 << char_val)
return True
# 创建Solution类的实例
solution = Solution()
# 示例
print(solution.isUnique("leetcode")) # 输出: False
print(solution.isUnique("abc")) # 输出: True
下面是对代码的详细解释:
-
我们首先定义了一个名为
Solution的类,该类包含了一个名为isUnique的方法,该方法接受一个字符串astr作为输入,并返回一个布尔值,指示字符串中的字符是否都是唯一的。 -
在
isUnique方法内部,我们创建了一个名为char_set的整数变量,用于存储出现过的字符的信息。初始时,char_set的所有位都被设置为0,因为我们还没有遇到任何字符。 -
接下来,我们使用
for循环遍历输入字符串astr中的每个字符。 -
对于每个字符,我们使用
ord(char)来获取其对应的ASCII码值,这个值将用于确定该字符在char_set中的位置。 -
我们使用位运算来检查字符是否已经出现过。具体做法是将1左移
char_val位,并与char_set进行按位与运算。如果结果大于0,说明该字符已经出现过,因此我们返回False表示字符串中有重复字符。 -
如果字符没有重复,我们将更新
char_set,将对应字符位置的位设为1,以表示该字符已经出现过。这是通过将1左移char_val位并与char_set进行按位或运算来实现的。 -
最终,如果我们遍历完整个字符串而没有发现重复字符,那么我们返回
True,表示字符串中的所有字符都是唯一的。
这个算法的核心思想是使用一个整数的二进制位来表示每个字符是否出现过,以达到空间复杂度O(1)的要求。同时,它的时间复杂度为O(n),其中n是字符串的长度,因为我们需要遍历整个字符串。
注释:ord()函数
ord()函数是一个内置的Python函数,用于获取一个字符的Unicode码点(整数表示)。Unicode是一种用于表示世界上大多数字符的标准编码系统,包括ASCII字符和许多其他字符,因此ord()` 函数可以用于获取字符的唯一整数标识。
具体来说,ord() 函数接受一个字符作为参数,并返回该字符对应的Unicode码点,例如
char = 'A'
unicode_value = ord(char)
print(unicode_value) # 输出: 65
在上面的示例中,ord('A') 返回65,因为大写字母"A"的Unicode码点是65。
ord() 函数通常在需要将字符与其相应的整数表示进行比较或转换时使用。与之相反的函数是 chr(),它接受一个整数(Unicode码点)作为参数,并返回对应的字符。这两个函数一起允许在字符和整数之间进行。
通过一个具体的示例来演示这个方法的整个过程,以便理解:
假设输入字符串 astr 为 "abcabc"。
-
我们首先创建一个整数
char_set,初始值为0,用于表示字符的出现状态。 -
开始遍历字符串
astr的字符:-
对于第一个字符 'a',其Unicode码点为97,我们计算
char_val = ord('a'),因此char_val等于 97。 -
我们检查
char_set中的位,看看字符 'a' 是否已经出现过。首先,我们将 1 左移char_val位,得到一个二进制数,只有第 97 位为1,其他位都为0,即1 << 97等于 158456325028528675187087900672。然后,我们使用按位与运算来检查这一位是否已经被设置在char_set中,即char_set & (1 << char_val)。由于char_set的初始值为0,按位与的结果也为0,表示字符 'a' 还没有出现过。 -
接下来,我们将更新
char_set,将字符 'a' 对应的位设为1,使用按位或运算,即char_set |= (1 << char_val)。此时,char_set的值变为 158456325028528675187087900672,表示字符 'a' 已经出现过。
-
-
然后,我们继续遍历字符串的下一个字符 'b',并重复相同的过程。
-
计算
char_val = ord('b'),得到char_val等于 98。 -
使用按位与运算检查字符 'b' 是否已经出现过,即
char_set & (1 << char_val)。此时,由于char_set的第 97 位已经被设置为1,按位与的结果不再是0,表示字符 'b' 已经出现过。 -
由于字符 'b' 已经出现过,我们不再更新
char_set,继续遍历下一个字符 'c'。
-
-
对于字符 'c',我们执行相同的过程:
-
计算
char_val = ord('c'),得到char_val等于 99。 -
使用按位与运算检查字符 'c' 是否已经出现过,即
char_set & (1 << char_val)。此时,由于char_set的第 97 和 98 位都已经被设置为1,按位与的结果不再是0,表示字符 'c' 已经出现过。 -
由于字符 'c' 已经出现过,我们不再更新
char_set。
-
-
最后,我们遍历完整个字符串,发现字符串中有重复字符 'a'、'b' 和 'c',因此函数返回
False表示字符串中不是所有字符都唯一。
这就是使用位运算检查字符串中是否有重复字符的过程。通过将字符的Unicode码点映射到整数,并使用位运算来表示字符的出现状态,我们可以高效地解决这个问题。















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









