







目录
1、二分查找
学习目标:
- 掌握手写二分查找的代码和细节
- 快速解答二分查找的选择题
二分查找步骤分析:
1. 前提:有已经排好序的数组A
2. 定义左边界L,有边界R,确定搜素范围,循环执行二分查找
3. 获取中间索引M=Floor((L+R)/2)
4. 中间索引的值 A[M]与待搜索的值T比较
- A[M]==T,返回中间索引
- A[M] > T,中间值右侧的其它元素大于T,中间索引左边去找,R=M-1 设置有边界,重新查找
- A[M] < T,中间值左侧的其它元素都小于T,中间索引右边去找,L=M+1 设置左边界,重新查找
5. 当L > R时,表示没有找到,结束循环。
算法代码分析:
public class BinarySearch {
public static void main(String[] args){
int[] array = {1,5,8,11,19,22,31,35,40,45,48,49,50};
int target = 48;
int idx = binarySearch(array, target);
System.out.println(idx);
}
//二分查找找到返回元素的索引
public static int binarySearch (int[] a, int t) {
int l = 0, r = a.length -1, m;
while (l <= r){
m = (l + r) / 2;
if (a[m] == t) {
return a[m];
} else if (a[m] > t){
return r = m - 1;
} else {
return l = m + 1;
}
}
return -1;
}
}如何避免中间索引整数溢出的问题?
public class IntegerOverflow {
public static void main(String[] args) {
int l = 0;
int r = Integer.MAX_VALUE - 1;
int m = (l + r) / 2; //l/2 + r/2 ====> l + (-l/2 + r/2) ===>l + (r-l)/2
int m = l + (r-l)/2; //方法一:解决溢出问题
int m = (l + r) >>> 1; //方法二:无符号右移位1位
System.out.println(m);
//在右侧;溢出
l = m + 1;
m = l + (r-l)/2;
m = (l + r) >>> 1;
System.out.println(m);
System.out.println(126 + 63);
System.out.println((126 + 63)/2);
System.out.println((126 + 63) >>> 1);
}
}面试真题:
1. 有一个有序表1,5,8,11,19,22,31,35,40,45,48,49,50 当二分查找48时,查找成功需要比较的次数(4次)?(京东实习生招聘)

2.使用二分法在序列1,4,6,7,15,33,39,50,64,78,75,81,89,96 查找81需要经过(4)次查找?(美团点评校招)

奇数二分取中间;偶数二分取中间靠左
3. 在已经的128个数组中二分查找一个数,需要比较的次数最多不超过多少次?(北京易道博识社招)

2、冒泡排序
学习目标:
- 掌握常见的排序算法(快排、冒泡、选择、插入等)的实现思路
- 手写冒泡、快排的代码
- 了解各个排序算法的特性,如时空复杂度、是否稳定
思路分析:
1. 依次比较数组中相邻两个元素大小,如果a[i] > a[i+1],则交换两个元素,两两比较一遍称为一轮冒泡,结果让最大的元素排至最后
2. 重复以上步骤。
算法代码分析:
public class BubbleSort {
public static void main(String[] args) {
int[] a = {5,9,7,4,1,3,2,8};
// int[] a = {1,2,3,4,5,6,7,8,9};
bubble(a);
}
public static void bubble(int[] a) {
/**
原始冒泡代码
*/
for (j=0; j < a.length-1; j++){
//一轮冒泡后的结果
for (int i = 0; i < a.length - 1;i++) {
System.out.println("比较次数:" + i);
if (a[i] > a[i+1]) {
swap(a, i, i+1);
}
}
System.out.println("第"+j+"轮冒泡"+Array.toString(a));
}
/**
优化一轮的比较次数
*/
for (j=0; j < a.length-1; j++){
//一轮冒泡后的结果
for (int i = 0; i < a.length - 1 - j;i++) {
System.out.println("比较次数:" + i);
if (a[i] > a[i+1]) {
swap(a, i, i+1);
}
}
System.out.println("第"+j+"轮冒泡"+Array.toString(a));
}
/**
优化需要经过几轮的冒泡次数
*/
for (j=0; j < a.length-1; j++){
//一轮冒泡后的结果
boolean swaped = false; //判断相邻两次是否发生交换
for (int i = 0; i < a.length - 1 - j;i++) {
System.out.println("比较次数:" + i);
if (a[i] > a[i+1]) {
swap(a, i, i+1);
}
}
System.out.println("第"+j+"轮冒泡"+Array.toString(a));
if (!swaped) {
break;
}
}
/**
最终优化代码:当前索引作为下一轮的比较次数
*/
int n = a.length - 1;
while (true) {
//一轮冒泡后的结果
int last = 0; //表示最后一次交换索引的位置
for (int i = 0; i < n;i++) {
System.out.println("比较次数:" + i);
if (a[i] > a[i+1]) {
swap(a, i, i+1);
n == last;
}
}
System.out.println("第轮冒泡"+Array.toString(a));
if (n == 0) {
break;
}
}
}
public static void swap(int[] a, int i, int j) {
int t = a[i];
a[i] = a[j];
a[j] = t;
}
}3、选择排序
算法代码实现:
public class SelectSort {
public static void main(String[] args) {
int[] a = {5,3,7,2,1,9,8,4};
selection(a);
}
public static void selection(int[] a) {
for (int i = 0; i < a.length - 1; i++){
//i 代表每轮选择最小元素要交换的目标索引
int s = i; //代表最小元素的索引
for (int j = s + 1; j < a.length; j++){
if (a[s] > a[j]){
s = j;
}
}
if (s != i) {
swap(a, s, i);
}
System.out.println("每轮选择排序"+Array.toString(a));
}
}
}思路分析:
- 将数组分为两个子集,排序和未排序的,每一轮从未排序的子集中选出最小的元素,放入已排序的子集。
- 重复以上步骤,直到整个数组有序
冒泡排序和选择排序的比较:
1. 二者平均时间复杂度O(n^2)
2. 选择排序一般快于冒泡,因为交换次数少
3. 如果集合的有序度高,冒泡优于选择
4. 冒泡属于稳定的排序算法,而选择属于不稳定排序
4、插入排序
算法代码实现
public class InsertSort {
public static void main(String[] args){
int[] a = {9,3,7,2,5,8,1,4};
insert(a);
}
private static void insert(int[] a){
//i 代表待插入元素的索引
for (int i = 1; i < a.length; i++){
int t = a[i]; //临时变量,存待插入的元素值
int j = i - 1; //代表已排序区域的元素索引
while(j >= 0){
if (t < a[j]){
a[j+1] = a[j];
}else {
break; //退出循环,减少比较次数
}
j--;
}
a[j+1] = t;
System.out.println(Arrays.toString(a)); //打印每一轮循环的结果
}
}
}思路分析
文字描述:
1. 将数组分为两个区域,已排序和未排序区域,每一轮从未排序区域中取出第一个元素,插入到排序区域
2. 重复以上步骤,直到整个数组有序
优化方式:
1. 待插入元素进行比较时,遇到比自己小的元素,就代表找到了插入位置,无需进行后续比较
2. 插入时可以直接移动元素,而不是交换元素
与选择排序进行比较:
1. 二者平均时间复杂度O(n^2)
2. 大部分情况下,插入都略优于选择
3. 有序集合插入的时间复杂度O(n)
4. 插入排序是稳定的,选择是不稳定的
5、希尔排序
1. 数组中间隙相同的划分一组,同一组的元素进行插入排序。较大的元素在右边,较小的元素在左边。
2. 改变间隙序列,重复以上步骤。
间隙序列:[N/2],[N/4],...,1
面试真题
1. 使用直接插入排序算法对序列18,23,19,9,23,15进行排序,第三趟的排序结果()
18, 23, 19, 9, 23, 15
18, 19, 23, 9, 23, 15
9, 18, 19, 23, 23, 15
2. 使用直接选择排序算法对序列18,23,19,9,23,15进行排序,第三趟排序后的结果()
9,23,19,18,23,15
9,15,19,18,23,23
9,15,18,19,23,23
6、快速排序
思路描述:
1. 每一轮排序选择一个基准点(pivot)进行分区
1)让小于基准点的元素的进入一个分区,大于基准点的元素进入另一个分区
2)当分区完成时,基准点元素的位置就是其最终位置
2. 在子分区内重复以上过程,直至子分区元素个数小于等于1(divide-and-conquer)
实现方式:
1. 单边循环(lomuto分区) ------- 洛穆托算法
选择最右元素作为基准点元素
j指针负责找到比基准点小的元素,一旦找到则与i进行交换
i指针维护小于基准点元素的边界,也是每次交换的目标索引
最后基准点与i交换,i即是分区位置
2. 双边循环 ------ 霍尔分区算法
选择最左元素作为基准点元素
j指针负责从右向左找比基准点小的元素,i指针负责从左向右找比基准点大的元素,一旦找到交换,直至i, j相交
最后基准点与i(此时 i 和 j 相等)交换,i 是分区位置
单边循环快排:
public class QuickSort {
public static void main(String[] args){
int[] a = {5,3,7,2,9,8,1,4};
partition(a, l=0, h=a.length - 1);
}
public static int partition (int[] a, int l, int h){
int pv = a[h]; //基准点元素
int i = l;
for (int j = l; j < h; j++){
if (a[j] < pv){
swap(a, i, j);
i++;
}
}
swap(a, h, i);
System.out.println(Array.toString(a) + "i=" + i);
//返回值代表基准点元素所在的正确索引,用它确定下一轮分区的边界
return i;
}
}递归实现单边快排
public class QuickSort {
public static void main(String[] args){
int[] a = {5,3,7,2,9,8,1,4};
quick(a, l=0, h=a.length - 1);
}
public static void quick(int[] a, int l, int h){
if (l >= h){
return;
}
int p = partition(a, l, h); //基准点所指的正确索引值
quick(a, l, p - 1); //左边界分区
quick(a, p + 1, h); //右边界分区
}
public static int partition (int[] a, int l, int h){
int pv = a[h]; //基准点元素
int i = l;
for (int j = l; j < h; j++){
if (a[j] < pv){
if (i != j){
swap(a, i, j);
}
i++;
}
}
if (i != h){
swap(a, h, i);
}
System.out.println(Array.toString(a) + "i=" + i);
//返回值代表基准点元素所在的正确索引,用它确定下一轮分区的边界
return i;
}
}递归实现双边循环快排:
//双边循环快排
@SuppressWarnings("all")
public class QuickSort2 {
public static void main(String[] args){
int[] a = {5, 3, 7, 2, 9, 8, 1, 4};
System.out.println(Arrays.toString(a));
quick(a, 0, a.length - 1);
}
public static void quick(int[] a, int l, int h){
if (l >= h){
return ;
}
int p = partition(a, l, h);
quick(a, l, p - 1);
quick(a, p + 1, h);
}
public static int partition(int[] a, int l, int h){
int pv = a[l]; //选择最左的元素作为基准点
int i = l;
int j = h;
while (i < j) {
//j 从右向左找比基准点小的元素
while (i < j && a[j] > pv) {
j--;
}
//i 从左向右找比基准点大的元素
while (i < j && a[i] <= pv){
i++;
}
swap(a, i, j);
}
swap(a, l, j);
System.out.println(Arrays.toString(a) + "j = " + j);
return j;
}
}双边循环注意的要点:
1. 基准点在左边,并且先 j 从右向左 后 i 从左向右
2. while(i < j && a[j] > pv) j--
3. while(i < j && a[i] <= pv) i++
快速排序的特点:
1. 平均时间复杂度是O(nlog2N),最坏时间复杂度O(n^2)
2. 数据量较大时,优势非常明显
3. 不稳定排序
7、设计模式
单例模式
目标:
1. 掌握单例模式常见的五种实现方式;
2. 了解JDK中有哪些地方体现了单例模式;
//1. 饿汉式:提前创建静态成员变量
public class SingletonMode1 implements Serializable {
//构造私有
private SingletonMode1 (){
System.out.println("private SingletonMode1");
}
//静态成员变量
private static final SingletonMode1 INSTANCE = new SingletonMode1();
//公共的静态方法访问静态成员变量
public static SingletonMode1 getInstance(){
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod() .....");
}
}public static void main(String[] args) {
SingletonMode1.otherMethod();
System.out.println("======================");
System.out.println(SingletonMode1.getInstance());
System.out.println(SingletonMode1.getInstance());
}
//反射破坏单例
reflectiion(SingletonMode1.class);
private static void reflectiion(Class<?> clazz) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
//无参构造私有化
Constructor<?> constructor = clazz.getDeclaredConstructor();
constructor.setAccessible(true);
System.out.println("反射创建的实例:"+constructor.newInstance());
}
预防反射破坏单例
//构造私有
private SingletonMode1 (){
if (INSTANCE != null){
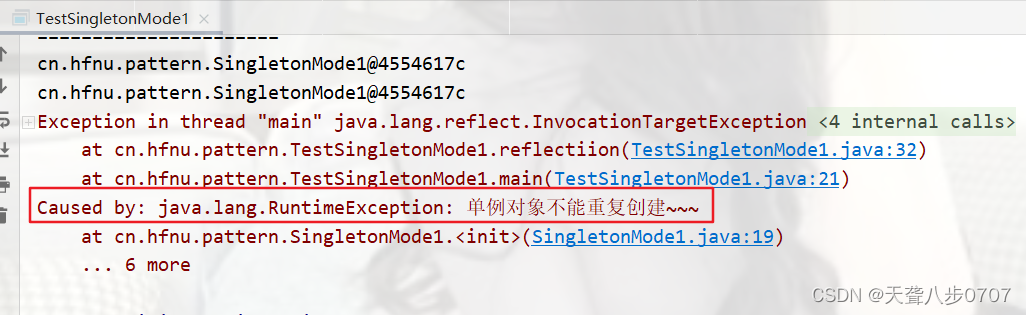
throw new RuntimeException("单例对象不能重复创建~~~");
}
System.out.println("private SingletonMode1");
}
//反序列化破坏单例
serializable(SingletonMode1.getInstance());
private static void serializable(Object instance) throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(instance);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
System.out.println("反序列化创建实例:"+ois.readObject());
}
预防反序列化破坏单例
public Object readResolve(){
return INSTANCE;
}
//Unsafe破坏单例
unsafe(SingletonMode1.class);
private static void unsafe(Class<?> clazz) throws InstantiationException {
Object o = Unsafe.getUnsafe().allocateInstance(clazz);
System.out.println("unsafe 创建实例:"+ o);
}//2. 枚举类饿汉式单例
public enum SingletonMode2 {
//枚举类实例变量
INSTANCE;
SingletonMode2(){
System.out.println("private singleton2");
}
@Override
public String toString(){
return getClass().getName() + "@" +Integer.toHexString(hashCode());
}
public static SingletonMode2 getInstance() {
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod");
}
}//反序列化破坏单例
serializable(SingletonMode2.getInstance());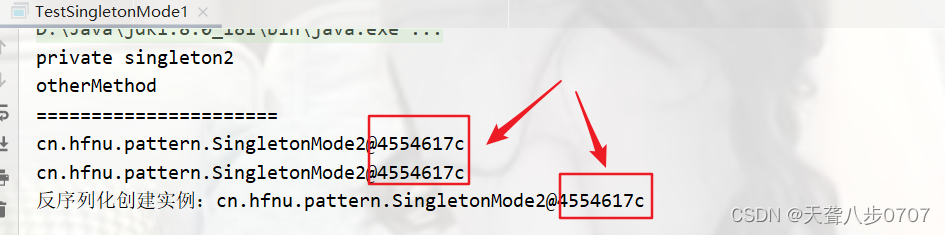
反序列化不会破坏枚举单例。
//反射破坏单例
reflectiion(SingletonMode2.class);
private static void reflectiion(Class<?> clazz) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
//无参构造私有化
//Constructor<?> constructor = clazz.getDeclaredConstructor();
Constructor<?> constructor = clazz.getDeclaredConstructor(String.class, int.class);
constructor.setAccessible(true);
System.out.println("反射创建的实例:"+constructor.newInstance("other", 2));
}
反射不会破坏枚举对象。
//3. 懒汉式单例模式
public class SingletonMode3 implements Serializable {
private SingletonMode3 (){
System.out.println("private singleton3");
}
private static SingletonMode3 INSTANCE = null;
public static synchronized SingletonMode3 getInstance() {
if (INSTANCE == null){
INSTANCE = new SingletonMode3();
}
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod");
}
}
懒汉式单例模式考虑多线程调用getInstance(),保护线程安全。
public static synchronized SingletonMode3 getInstance() {
if (INSTANCE == null){
INSTANCE = new SingletonMode3();
}
return INSTANCE;
}//3. 懒汉式单例模式 - DCL (双检锁)
public class SingletonMode4 implements Serializable {
private SingletonMode4(){
System.out.println("private singleton4");
}
//volatile 线程共享变量:可见性和有序性
private static volatile SingletonMode4 INSTANCE = null;
public static SingletonMode4 getInstance() {
if (INSTANCE == null){
synchronized (SingletonMode4.class){
if (INSTANCE == null){
INSTANCE= new SingletonMode4();
}
}
}
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod");
}
}//5. 懒汉式单例模式 - 内部类
public class SingletonMode5 implements Serializable {
private SingletonMode5(){
System.out.println("private singleton5");
}
//静态内部类 线程安全
private static class Holder{
static SingletonMode5 INSTANCE = new SingletonMode5();
}
public static SingletonMode5 getInstance(){
return Holder.INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod");
}
}在jdk中体现单例模式

以上是个人在基础数据结构中查找和排序的算法学习总结。需要自己理解原理!自己在不看笔记的情况下才能自己写出来。尤其是重点的算法代码!!!















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











