






前面一节说到了,使用堆空间的速度要比栈空间慢,我们从几个方面来说明一些这个原因。
首先,堆空间和栈空间都在内存上面,它两个是内存上的两个不同的区域。
1. 从分配方式方面
栈空间
- 首先来说栈内内存
我们的局部变量等都是存储在站内存上面的, 函数的调用也依赖于栈空间,线程等都离不开栈。那么栈空间的分配是怎么样的呢?
简单来说它就是利用一个空间指针来分配空间的。 如图:- 一般这个栈指针存放在特定的寄存器中,当我们操作栈的时候,直接调用对应寄存器存放的空间指针就好,这样速度更快,不用从内存中获取。
图一:
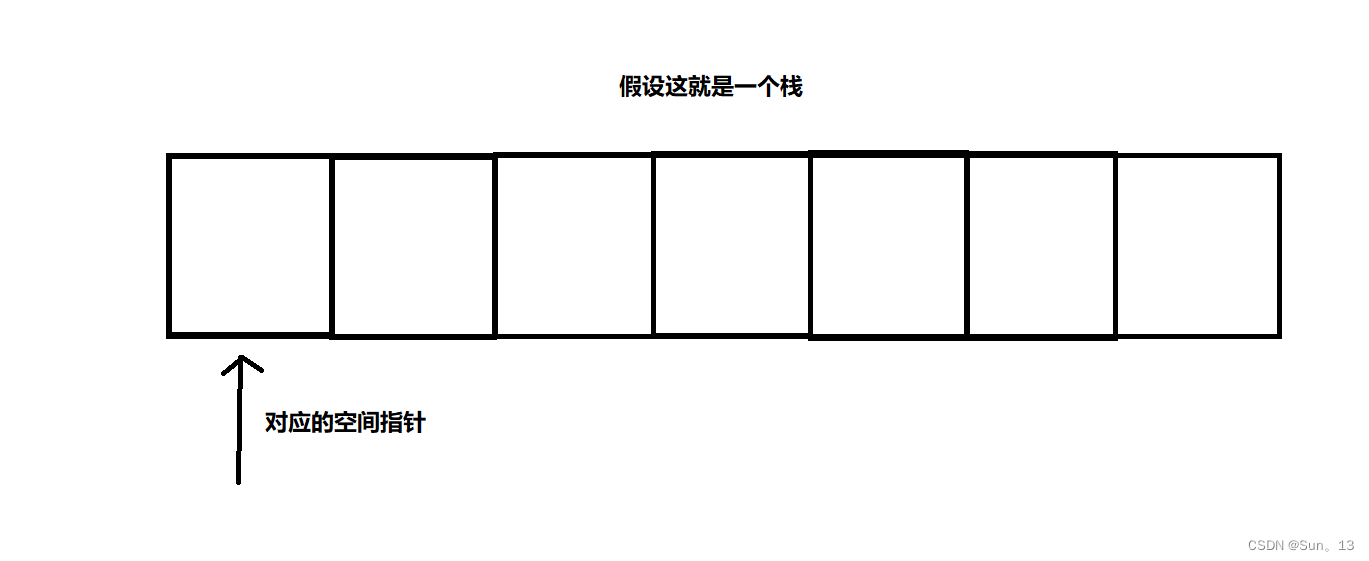
假设我们要分配四字节的空间
图二:
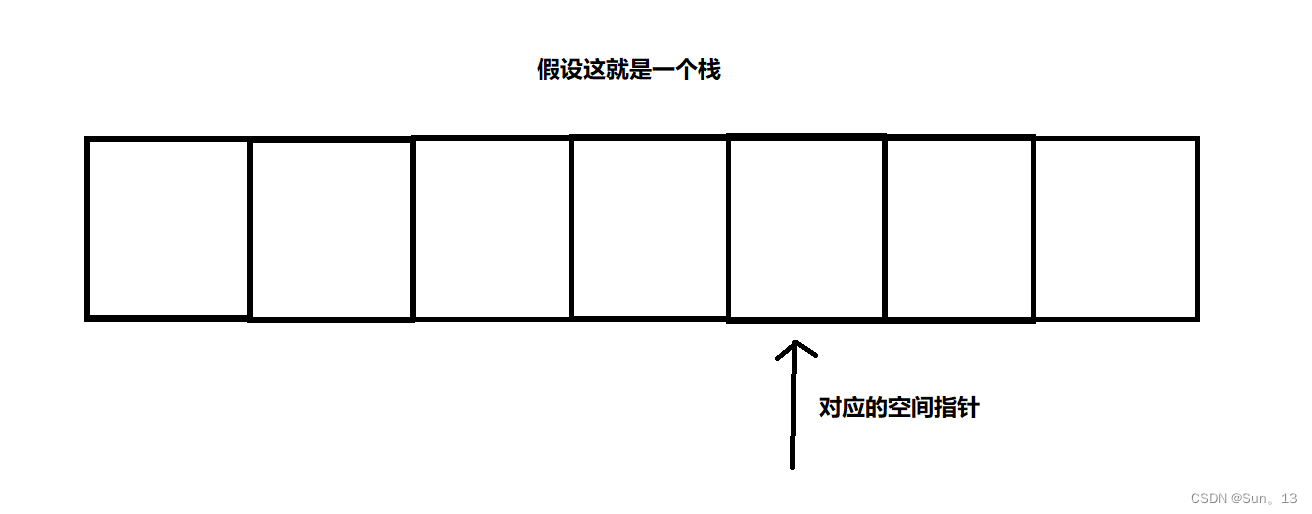
如图,空间指针就会向后偏移4个字节,前面的空间就是分配的空间。如果分配的空间被释放,只需要将指针移动会原来的位置就行。(只需移动指针,释放内存中存放的数据并不用删除)
- 对于分配的栈空间,其周围会有一些没有初始化的空间(内存中都为c),用来确定范围,就是判断我们访问内存是是否越界,是一种安全机制。
- 而且相邻定义的局部变量在栈内存中是距离很近的。
使用栈空间的局限性:
栈空间是为了保证数据有序和紧凑,但是栈空间的大小很有限,如果存放的数据很大,会出现栈溢出等问题。
而且栈存储数据是连续的,如果我们像向一个数组中添加数据,如果不提前开辟好空间,会会出现覆盖后面数据的情况。基于这些我们使用堆内存。
堆空间
- 堆空间
首先堆空间的开辟是使用new运算符的,其实new运算符底层会去先访问C语言的malloc函数,然后去开辟空间。
这些函数(malloc,realloc,calloc,free)会维护一个空闲列表(可用内存池),内部存放了一些指向空闲空间的指针,当我们申请开辟堆空间的时候,这些函数会先到空闲列表中去查找空间至少>=我们申请的空间大小的空间指针。
然后,返回这个指针,如果,没有找到符合要求的,malloc函数会像操作系统请求,要求得到更多的内存,并在这块新内存上分配任务。如果操作系统无法像malloc提供更多的内存,那么malloc函数会返回NULL的空指针。从这个操作上来看,就可以看出堆空间的效率低了(因为栈空间开辟空间只需要向后移动空间指针就行)- 而且堆空间存储的数据不是相邻的,返回的是指向空间的指针,所以这些空间并不是连续的(比如说链表)。
- 而且当我们调用delete去释放空间的时候,其底层会调用C语言的free(),而且,当释放空间的时候,会删除掉在内存中的数据。(栈是不需要删除数据的)
2. 从vs的内存调试窗口来说明
我们查看下面代码的内存情况
int main() {
int value = 5;
int array[5] = { 1,2,3,4,5 };
int* hvalue = new int(10);
int* harray = new int[5] {11, 12, 13, 14, 15};
std::cin.get();
return 0;
}我们打一个断点,进入调试模式,在调试->窗口->内存->内存1。
栈内存
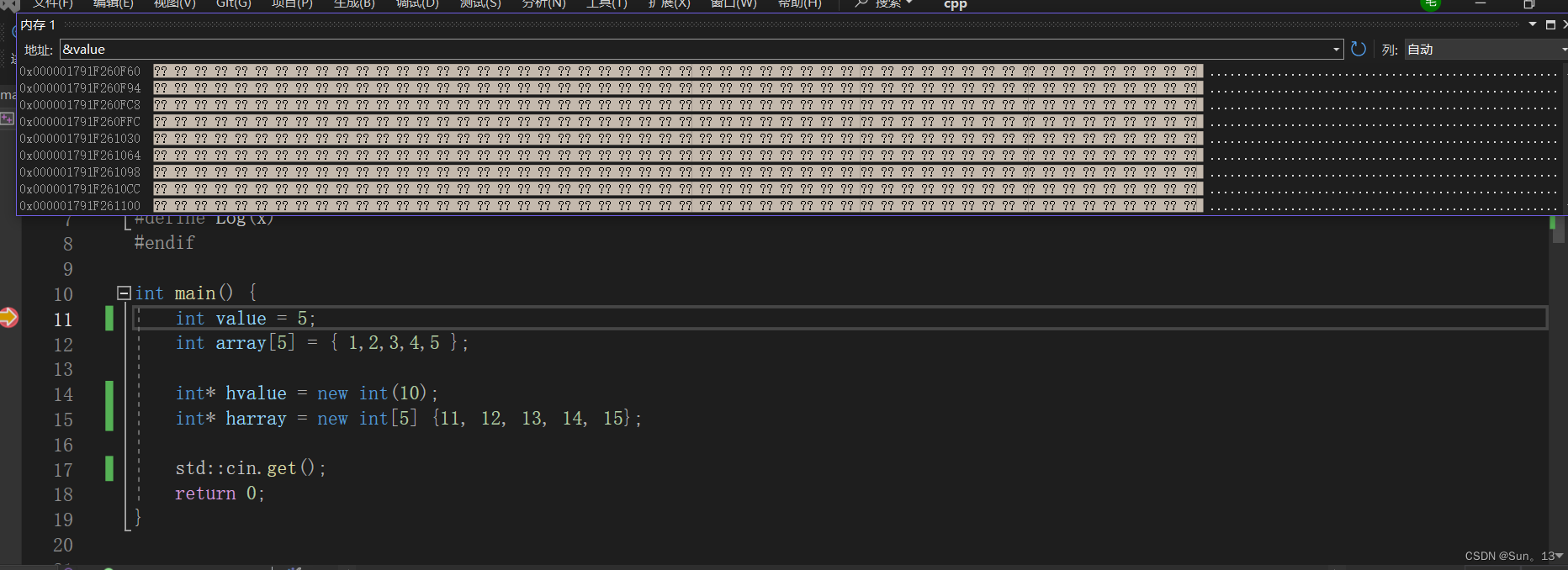 在视图的上面写上&value就可以查看到它的内存了
在视图的上面写上&value就可以查看到它的内存了
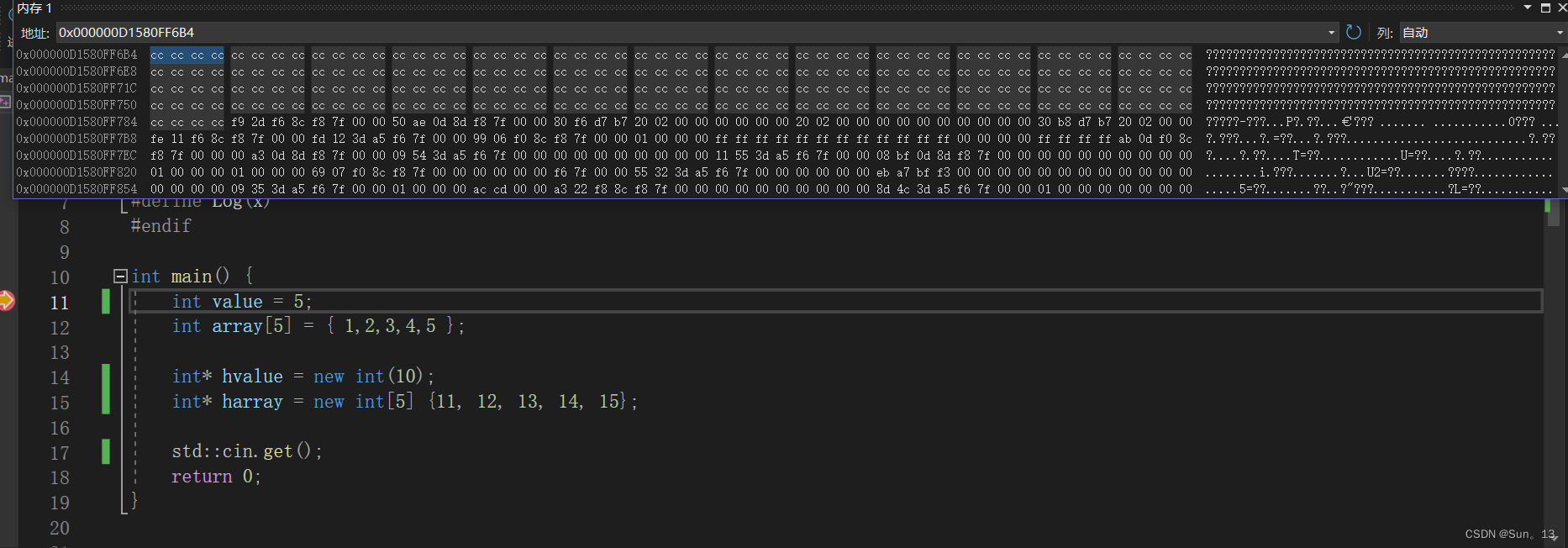
按下回车键,会发现内存中都是cccc,我们前面说了,在内存没有初始化的时候,内存中的值都是c。(因为我们在value初始化的位置打了断点,这条语句还没有执行,我们按F11往下执行)
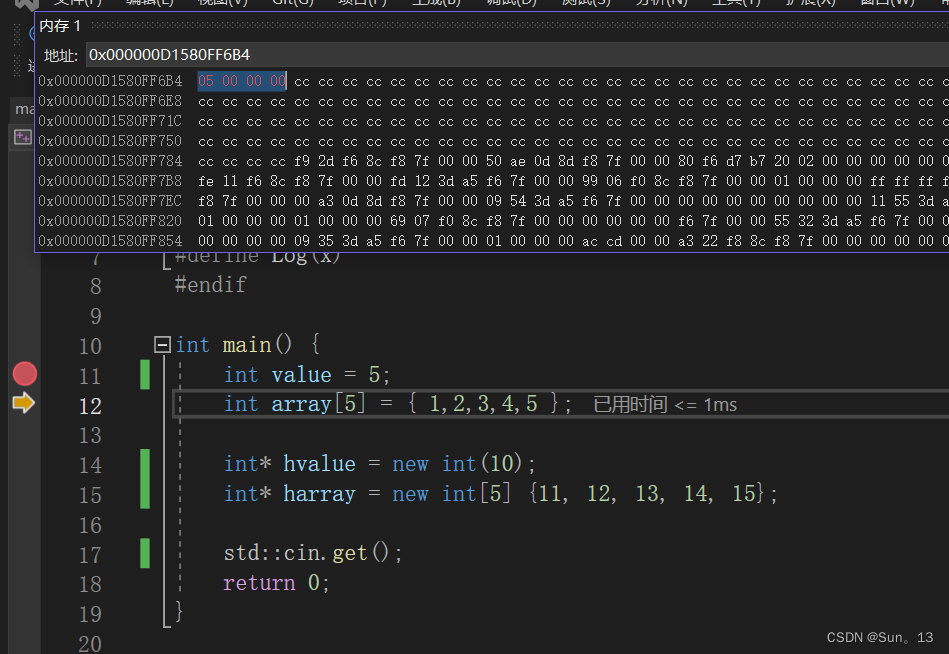 你会发现,右侧的箭头指向了下一行语句,说明value的初始化语句已经执行了,可以看到视图中对应的位置,内存中存放了4个字节的数据,值就是5。
你会发现,右侧的箭头指向了下一行语句,说明value的初始化语句已经执行了,可以看到视图中对应的位置,内存中存放了4个字节的数据,值就是5。
我们再来看array数组的 ,还是一样在上面的框中写入array(因为array本身就是指针所以不用写取地址符),然后我们再往下执行,让数据初始化。
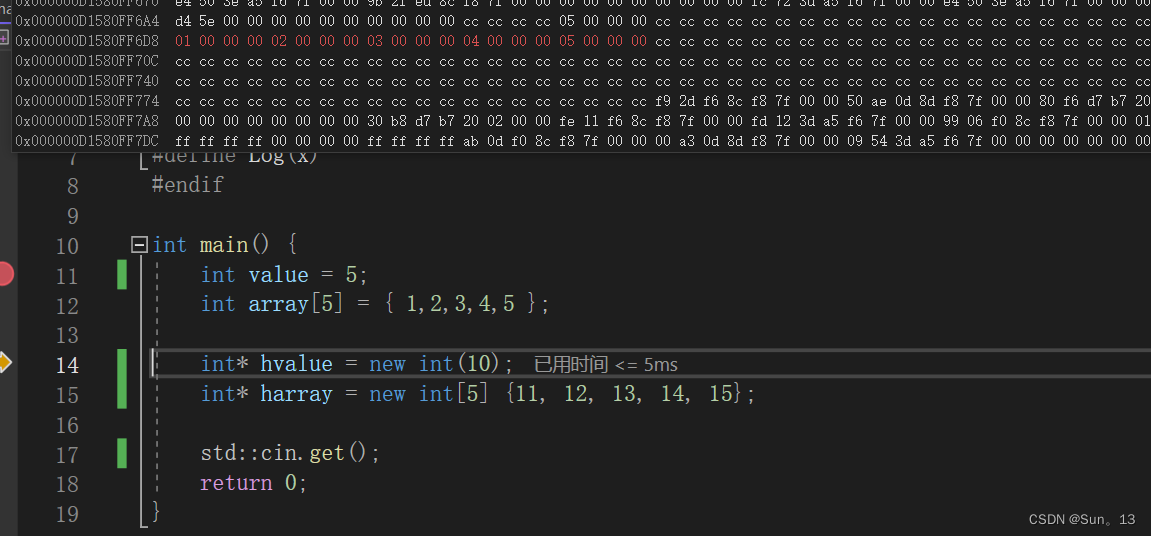 你会发现红色的部分就是数组的所有元素,你在这些数据向上看,你会注意到value的栈内存为止距离array的不远。
你会发现红色的部分就是数组的所有元素,你在这些数据向上看,你会注意到value的栈内存为止距离array的不远。
再来看一看栈内存的释放,我们将变量value放到一个块中,这样在块结束之后其就会释放。
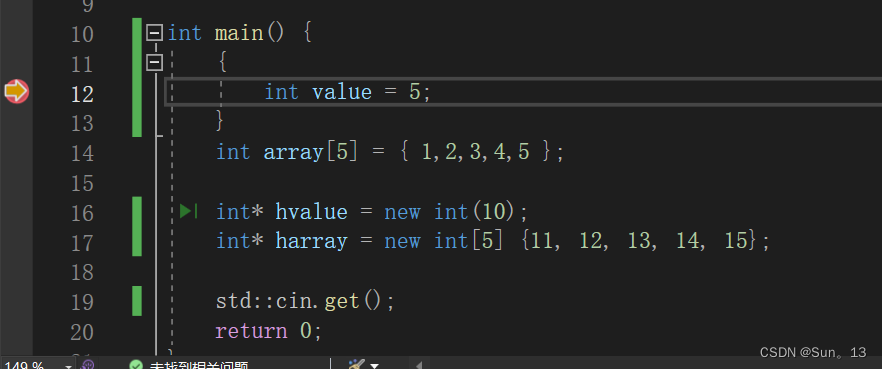
同样执行上面的步骤,查看value的地址 ,并且让代码向下执行
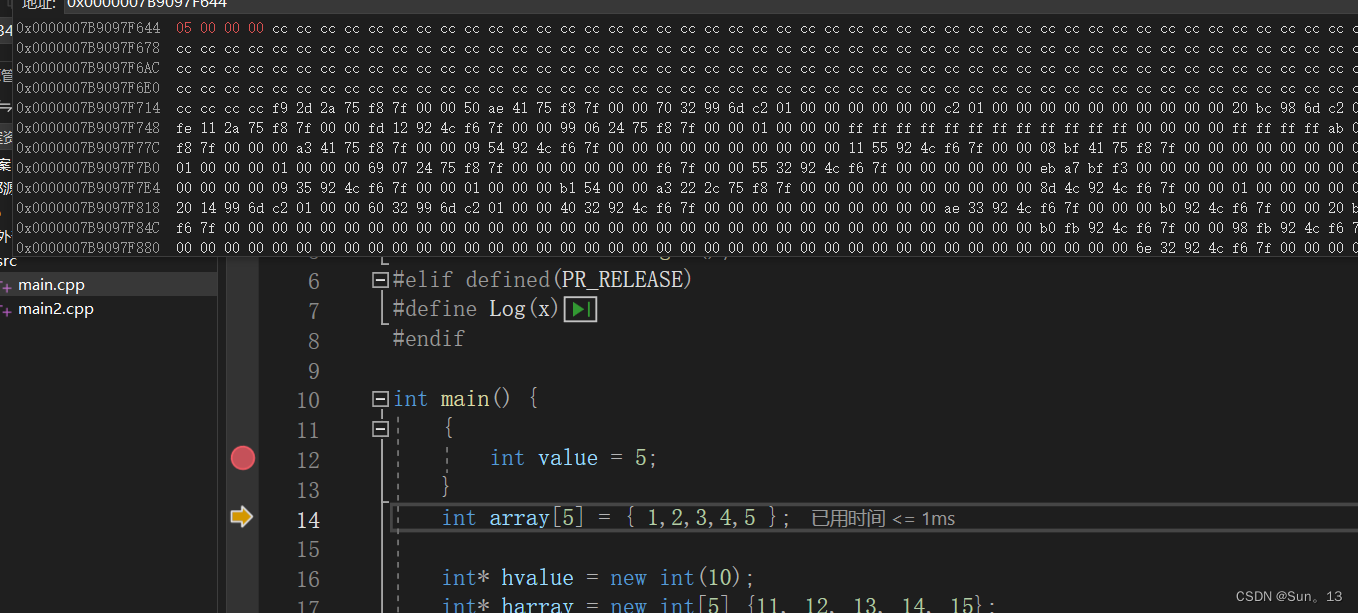 你会发现,我们value变量已经释放了,但是原来内存中的值还没有修改,当下次再使用这块空间的时候再将里面的数据覆盖。
你会发现,我们value变量已经释放了,但是原来内存中的值还没有修改,当下次再使用这块空间的时候再将里面的数据覆盖。
堆内存
同样的道理访问下面的堆内存,直接写hvalue和harray就行
hvalue的堆内存
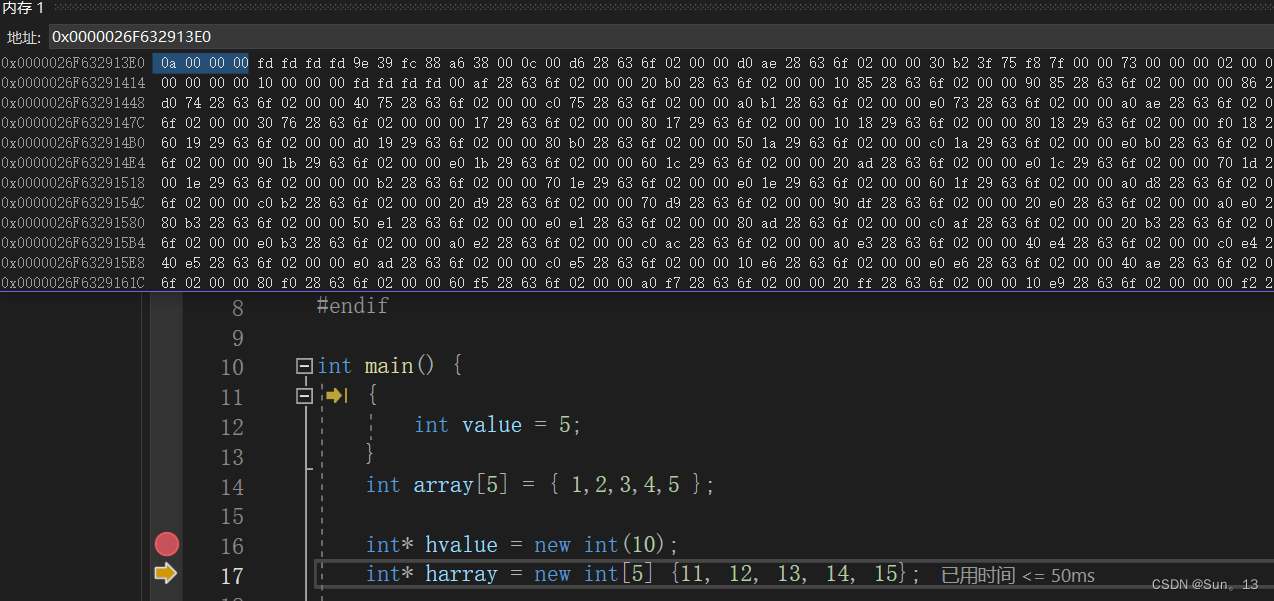
harray的堆内存
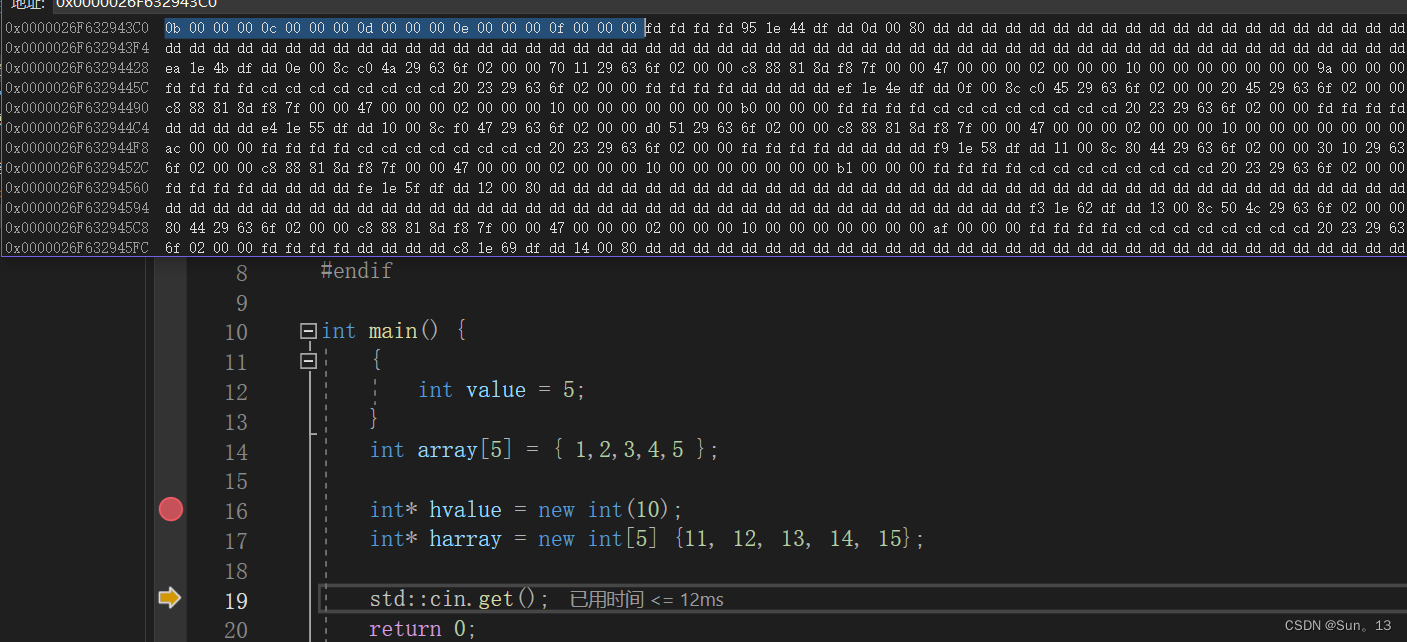
你会发现,这两个空间相距很远,距离并不近。
堆内存释放
删除前:
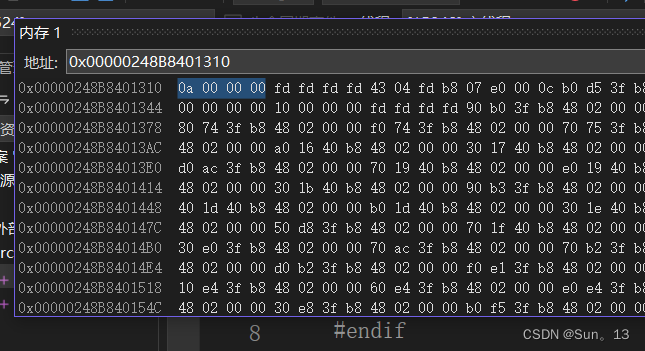
删除后 :
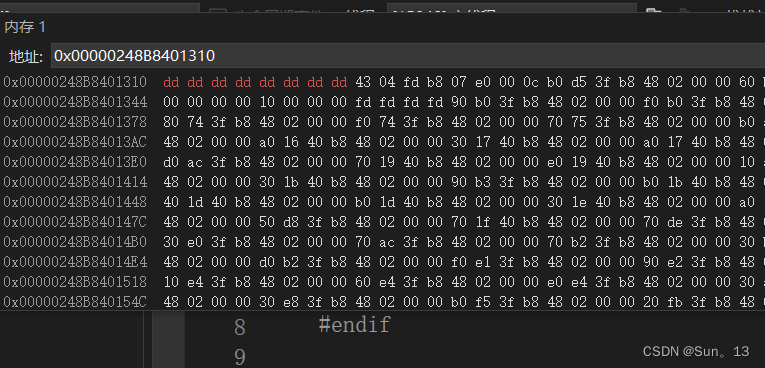
你会发现删除之后,存储在堆空间的原来的数据已经被删除了。
3. 使用汇编代码查看
同样在调试的情况下,右键选择转到反汇编,查看分配空间时候的汇编代码
value栈空间的汇编代码
 你会发现,它仅仅使用了一条指令而已。
你会发现,它仅仅使用了一条指令而已。
hvalue堆空间的汇编代码
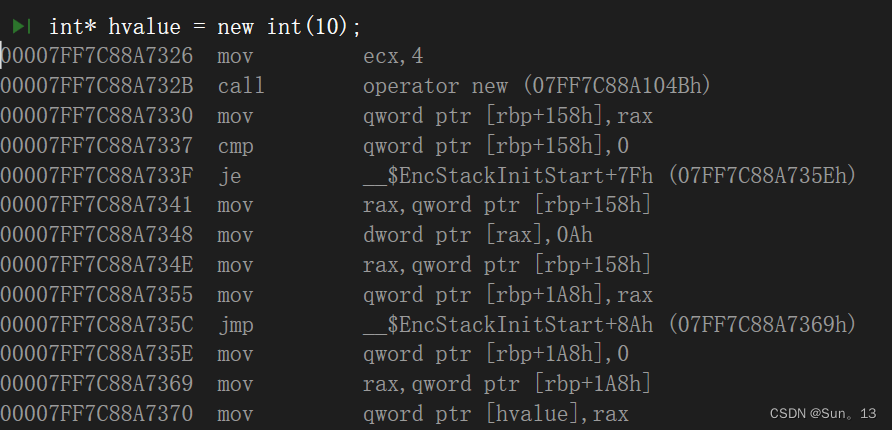 你会发现,同样是开辟空间在栈上只需要一条指令,而在堆上呢?(至于数组和空间释放的对比,其实是类似的,可以自行查看)
你会发现,同样是开辟空间在栈上只需要一条指令,而在堆上呢?(至于数组和空间释放的对比,其实是类似的,可以自行查看)
函数调用的栈空间
每个函数所拥有的栈空间我们称之为栈帧, 函数的调用是通过栈来实现的,这里只是大体介绍一下。
当一个函数被另外一个函数调用的时候,操作系统会记录当前调用函数的位置,方便之后执行完调用函数之后,跳回到调用处执行后面的代码。
这是存储在寄存器中的栈指针会被使用,然后函数中的数据入栈。入栈的顺序为,首先会是一个返回值链接(用来存放函数的返回值),然后是,函数的参数,它们默认以从右到左的顺序入栈,然后就是函数中的代码了,直到执行到return语句,函数的返回值写入到返回值链接中去。这时候,函数执行结束,函数指针回退到返回值链接的位置,然后根据记录的执行位置,返回到调用函数。
为什么要有堆栈
因为,我们程序要运行,程序就需要载入内存,所以程序中的数据就要放入内存,如果不进行管理,数据就会无规律的存放,可能会造成很多的内存碎片以及访问到这些数据会比较消耗性能。
所以操作系统就对内存进行了管理,程序载入内存的时候,需要先经过操作系统,然后操作系统会给其分配空间,通过栈的形式来存放局部数据,可以使得存放的更加的紧凑,使得数据有效存放,提高效率。
因为,我们的程序是无法直接去操控硬件的(不安全,也不方便),我们程序要使用硬件的时候需要通过操作系统(比如其提供的一些接口等),内存也是硬件之一,所以要使用内存自然也是需要通过操作系统。
栈会在程序运行之前会提前开辟一定的空间,不需要在程序运行的时候再去开辟(这也是栈之所以快的一个原因)
在程序运行之前,操作系统会预先分配一个大小的栈空间给程序,往往一般为几个mb,所以程序在运行的时候就不需要去申请空间了。
但是,如果在程序运行期间,原先分配的栈空间空间不足,这时候就会去扩充栈的空间(当然能扩充的大小是有限的,超过会发生栈溢出),这个过程是在程序运行期间发生的,也就是动态的。
注意,这里的扩充其实并不是真正意义上的扩充,你可以理解为栈空间编译的时候已经分配好了大小,其大小是不会改变的。但是最开始栈空间我们可以使用的是几个mb,但是随着数据的变多,几个mb不够用,这时候我们就会使用栈之后的内存。所以变化的是存放在栈中的数据而不是栈。
总结
所以堆空间和栈空间的区别主要在分配,这也能直观的看出为什么栈空间的效率高,所以我们应该优先选择栈空间,当然如果需要用到堆空间的时候,依然要使用堆空间。(例如: 需要大空间,变量的生命周期由自己控制,函数返回数据等等)。















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









