







二进制部署kubernetes-1.25.4
一、部署说明
1.资源列表
| 主机 | IP | 系统版本 | 备注 |
|---|---|---|---|
| k8s-master1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) | kubernetes-master节点一&ETCD-1&VIP=10.0.13.110 |
| k8s-master2 | 10.0.13.81 | CentOS Linux release 7.5.1804 (Core) | kubernetes-master节点二&ETCD-2&VIP=10.0.13.110 |
| k8s-node1 | 10.0.13.73 | CentOS Linux release 7.5.1804 (Core) | kubernetes-node节点一&ETCD-3 |
| k8s-node2 | 10.0.13.75 | CentOS Linux release 7.5.1804 (Core) | kubernetes-node节点二 |
2.资源包下载
各应用版本信息:
Docker版本:docker-20.10.15
Cri-Docker版本:cri-dockerd-0.2.3.amd64
Kubernetes版本:v1.25.4/kubernetes-client-linux-amd64
Cfssl工具版本:1.6.2~1.6.3_linux_amd64
Etcd版本:etcd-v3.5.3-linux-amd64
Haproxy版本:haproxy-2.6.12
Keepalived版本:keepalived-2.2.7
Calico.yaml版本:v3.24.5
Calicoctl版本:v3.21.5
Cni插件版本:cni-plugins-linux-amd64-v1.1.1
Containerd版本:cri-containerd-cni-1.6.8-linux-amd64
Helm版本:v3.11
安装包官网下载地址:
docker-20.10.15.tgz下载地址:
https://download.docker.com/linux/static/stable/x86_64/docker-20.10.15.tgz
cri-dockerd-0.2.3.amd64.tgz下载地址:
https://github.com/Mirantis/cri-dockerd/releases/download/v0.2.3/cri-dockerd-0.2.3.amd64.tgz
kubernetes-server-linux-amd64.tar.gz下载地址:
https://dl.k8s.io/v1.25.4/kubernetes-server-linux-amd64.tar.gz
cfssl工具包下载地址:
https://pan.baidu.com/s/1P4gck7ZmbS7gYYD92QAOWg?pwd=zska
etcd-v3.5.3-linux-amd64.tar.gz下载地址:
https://github.com/etcd-io/etcd/releases/download/v3.5.3/etcd-v3.5.3-linux-amd64.tar.gz
haproxy-2.6.12.tar.gz下载地址:
https://www.haproxy.org/download/2.6/src/haproxy-2.6.12.tar.gz
keepalived-2.2.7下载地址:
https://keepalived.org/software/keepalived-2.2.7.tar.gz
calico.yaml下载地址:
https://github.com/projectcalico/calico/blob/v3.24.5/manifests/calico.yaml
cni-plugins-linux-amd64-v1.1.1.tar.gz下载地址:
https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz
cri-containerd-cni-1.6.8-linux-amd64.tar.gz下载地址:
https://github.com/containerd/containerd/releases/download/v1.6.8/cri-containerd-cni-1.6.8-linux-amd64.tar.gz
helm-canary-linux-amd64.tar.gz下载地址:
https://get.helm.sh/helm-canary-linux-amd64.tar.gz
若以上链接无法使用,使用以下链接进行下载(百度网盘):
docker-20.10.15.tgz下载地址:
链接:https://pan.baidu.com/s/1-PQ2gyBAVPRnW2EMJ4zN_w?pwd=zska
提取码:zskacri-dockerd-0.2.3.amd64.tgz下载地址:
链接:https://pan.baidu.com/s/1TgbL4hFsTyc_Uyydipl0PQ?pwd=zska
提取码:zskakubernetes-server-linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1UkF4IHirUXP6Yp4mYBd2mg?pwd=zska
提取码:zskacfssl工具包下载地址:
链接:https://pan.baidu.com/s/1P4gck7ZmbS7gYYD92QAOWg?pwd=zska
提取码:zskaetcd-v3.5.3-linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1hBRP9JwJAfC5pE3eTpOYrA?pwd=zska
提取码:zskahaproxy-2.6.12.tar.gz下载地址:
链接:https://pan.baidu.com/s/1mfZ58x_prEviHcP2sRTsOQ?pwd=zska
提取码:zskakeepalived-2.2.7下载地址:
链接:https://pan.baidu.com/s/12V8ZpUOxCsZoGn5pdLR8bg?pwd=zska
提取码:zskacni-plugins-linux-amd64-v1.1.1.tar.gz下载地址:
链接:https://pan.baidu.com/s/1OWHxyHsBINiF4YNJkr8Uvw?pwd=zska
提取码:zskacri-containerd-cni-1.6.8-linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1hWheGsnYnkGaZ8ZdNRluCg?pwd=zska
提取码:zskahelm-canary-linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1K-d55SiigoO0nb5NDyeEbw?pwd=zska
提取码:zska
3.服务说明

Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
4.核心概念
Master
Master主要负责资源调度,控制副本,和提供统一访问集群的入口。–核心节点也是管理节点,也可作为服务节点
Node
Node是Kubernetes集群架构中运行Pod的服务节点。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机,由Master管理,并汇报容器状态给Master,同时根据Master要求管理容器生命周期。
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,是真是存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信;
Pod
Pod直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个Pod)。在k8s中我们不会直接操作容器,而是把容器包装成Pod再进行管理运行于Node节点上, 若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通信。Pod是k8s进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
总之,Pod 就是 k8s 集群里的"应用";而一个平台应用,可以由多个容器组成, 且每个Pod可以设置限额的计算机资源有CPU和Memory;
pause容器
每个Pod中都有一个pause容器,pause容器做为Pod的网络接入点,Pod中其他的容器会使用容器映射模式启动并接入到这个pause容器。
属于同一个Pod的所有容器共享网络的Namespace。
如果Pod所在的Node宕机,会将这个Node上的所有Pod重新调度到其他节点上

Pod Volume
Docker Volume对应Kubernetes中的Pod Volume;
数据卷,挂载宿主机文件、目录或者外部存储到Pod中,为应用服务提供存储,也可以解决Pod中容器之间共享数据。
Event
是一个事件记录,记录了事件最早产生的时间、最后重复时间、重复次数、发起者、类型,以及导致此事件的原因等信息。Event通常关联到具体资源对象上,是排查故障的重要参考信息
Pod IP
Pod的IP地址,是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,位于不同Node上的Pod能够彼此通信,需要通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP流量则是通过Node IP所在的物理网卡流出的
Namespace
命名空间将资源对象逻辑上分配到不同Namespace,可以是不同的项目、用户等区分管理,并设定控制策略,从而实现多租户。命名空间也称为虚拟集群。
Replica Set
确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能。
Deployment
Deployment是一个更高层次的API/资源对象,它管理ReplicaSets和Pod,并提供声明式更新等功能。
官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象,因此Deployment将会是使用最频繁的资源对象。
RC-Replication Controller
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。
一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
service负载分发策略有两种
RoundRobin: 轮训模式,即轮序请求转发到后段的各个pod上(默认模式);
SessionAffinty: 基于客户端ip地址进行会话保持的模式,第一次客户端访问后段某个pod,之后的请求都会转发到这个pod上。
Service account
service account是k8s为pod内部的进程访问apiserver创建的一种用户。其实在pod外部也可以通过sa的token和证书访问apiserver,不过在pod外部一般都是采用client 证书的方式。
User account
user account是在集群外部访问apiserver时使用的用户,比如kubectl命令就是作为kubernetes-admin用户来执行的,其中~/.kube/config指定了用户的证书,以便和apiserver互相认证。当然对于user account来说,是有多种认证方式的,参考官网,但是默认使能是x509客户端证书方式。
Service-select
service通过selector和pod建立关联;
k8s会根据service关联到pod的podip信息组成一个endpoint。
PersistentVolumeClaim
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
PersistentVolume
PersistentVolume (PV) 是外部存储系统中的一块存储空间,由管理员创建和维护。与 Volume 一样,PV 具有持久性,生命周期独立于 Pod。
Endpoint
endpoint是集群中的一个资源对象,储存在etcd中,用来记录一个service对应的pod的访问地址;
service配置serlector,endpoint controler才会自动创建对应的endpoint对象,否则,则不会创建endpoint对象。

如图示,每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,多个Pod副本组成了一个集群来提供服务
一般的做法是部署一个负载均衡器来访问它们,为这组Pod开启一个对外的服务端口如8000
并且将这些Pod的Endpoint列表加入8000端口的转发列表中
客户端可以通过负载均衡器的对外IP地址+服务端口来访问此服务。
运行在Node上的kube-proxy其实就是一个智能的软件负载均衡器
它负责把对Service的请求转发到后端的某个Pod实例上,并且在内部实现服务的负载均衡与会话保持机制。
Service不是共用一个负载均衡器的IP地址,而是每个Servcie分配一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。
5.组件说明
Kubernetes Master:
集群控制节点,负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有执行的命令基本都是在Master节点上运行的;
包含如下组件:
Kubernetes API Server
作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用。维护的REST对象持久化到Etcd中存储。Kubernetes Scheduler
为新建立的Pod进行节点(node)选择(即分配机器),负责集群的资源调度。组件抽离,可以方便替换成其他调度器。Kubernetes Controller manager
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
Replication Controller
管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。
- Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和 Pod的更新。- Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。- Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。- Service Controller
管理维护Service,提供负载以及服务代理。- EndPoints Controller
管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。- Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。- Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。- Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
- Job Controller
管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目- Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
Kubernetes Node:
除了Master,Kubernetes集群中的其他机器被称为Node节点,Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机,其上的工作负载会被Master自动转移到其他节点上去;包含如下组件:
Kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。Docker Engine(docker)
Docker引擎,负责本机的容器创建和管理工作;
Flannel
网络插件
数据库:
Etcd
数据库,可以部署到master上,也可以独立部署
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息
6.基础架构说明

用户通过Kubectl提交需要运行的Docker Container(Pod),Kubectl可以远程提交也可以本地提交
Api Server把收到的提交请求存储在Etcd库内,随后调用Scheduler扫描并分配资源到对应服务器
Kubelet找到自己需要跑的Container,在本机上运行
用户提交RC描述,Replication Controller监视集群中的容器并保持用户指定的数量
用户提交Service描述文件,由Kube Proxy负责具体的工作流量转发

通过kubectl命令执行创建
kubectl apply -f rs.yaml创建pod时,经历的流程如上图,大概流程为
- Apiserver接收Kubectl的创建资源的请求;
- Apiserver将创建请求写入Etcd;
- Apiserver接收到Etcd的回调事件;
- Apiserver将回调事件发送给ControllerManager;
- ControllerManager中的ReplicationController处理本次请求,创建RS,然后它会调控RS中的Pod的副本数量处于期望值,比期望值小就新创建Pod,于是它告诉ApiServer要创建Pod;
- Apiserver将创建Pod的请求写入Etcd集群;
- Apiserver接收Etcd的创建Pod的回调事件;
- Apiserver将创建Pod的回调事件发送给Scheduler,由它为Pod挑选一个合适的宿主Node;
- Scheduler告诉Apiserver,这个Pod可以调度到哪个Node上;
- Apiserver将Scheduler告诉他的事件写入Etcd;
- Apiserver接收到Etcd的回调,将更新Pod的事件发送给对应Node上的Kubelet进程;
- Kubelet通过CRI接口同容器运行时(Docker)交互,维护更新对应的容器。
二、环境调配
以下四台服务器,部署前均需要进行环境的调配工作
| 主机 | IP | 系统版本 |
|---|---|---|
| k8s-master | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
| k8s-master2 | 10.0.13.81 | CentOS Linux release 7.5.1804 (Core) |
| k8s-node1 | 10.0.13.73 | CentOS Linux release 7.5.1804 (Core) |
| k8s-node2 | 10.0.13.75 | CentOS Linux release 7.5.1804 (Core) |
1.免密配置
以下操作所有服务器依次执行,所有服务器之间做免密操作-注意IP要更换
#创建密钥,执行后一直回车即可
ssh-keygen
#定义服务器集群变量
all='10.0.13.72 10.0.13.81 10.0.13.73 10.0.13.75'
#分发密钥
for i in $all ; do ssh-copy-id $i ; done
2.主机名修改
以下操作所有服务器依次执行,注意主机名的更改
#master1节点操作
hostnamectl set-hostname k8s-master1
#master2节点操作
hostnamectl set-hostname k8s-master2
#node1节点操作
hostnamectl set-hostname k8s-node1
#node2节点操作
hostnamectl set-hostname k8s-node2
随后重新进行ssh连接即可
3.关闭防火墙
以下操作所有节点依次执行
#关闭firewalld
systemctl disable --now firewalld
#关闭selinux
setenforce 0
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
4.本地解析
以下操作所有服务器依次执行
#写入系统解析文件
cat >> /etc/hosts << EOF
10.0.13.72 k8s-master01
10.0.13.81 k8s-master02
10.0.13.73 k8s-node01
10.0.13.75 k8s-node02
EOF
#测试配置是否成功
ping k8s-master01
5.时间同步
以下为k8s-master节点操作
#调整时区
timedatectl set-timezone 'Asia/Shanghai'
#下载时间同步工具
yum -y install chrony
#编辑配置文件
vim /etc/chrony.conf
#注释所有server配置,并添加对应时间服务器地址
server ntp1.aliyun.com iburst
server ntp.ntsc.ac.cn iburst
#添加对应开放访问网段
allow 10.0.13.0/24

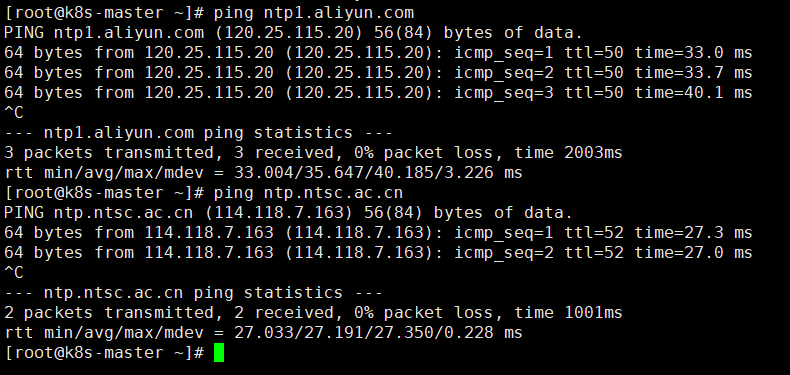
#查看是否可以ping通时间服务器
ping ntp1.aliyun.com
ping ntp.ntsc.ac.cn
#启动服务
systemctl restart chronyd
#时间配置项配置
timedatectl set-ntp yes
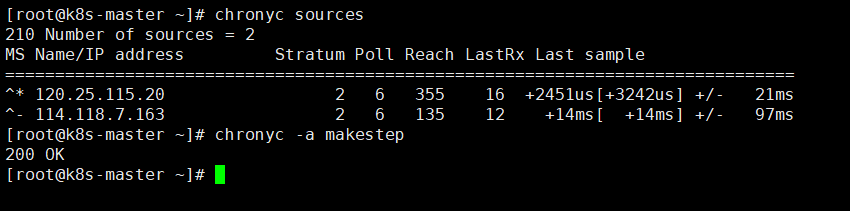
#查看源状态
chronyc sources
#查看存活状态
systemctl status chronyd | grep Active
#配置加载
chronyc -a makestep
#添加开机自启
systemctl enable chronyd
以下为其余服务器操作
#调整时区
timedatectl set-timezone 'Asia/Shanghai'
#下载时间同步工具
yum -y install chrony
#编辑配置文件
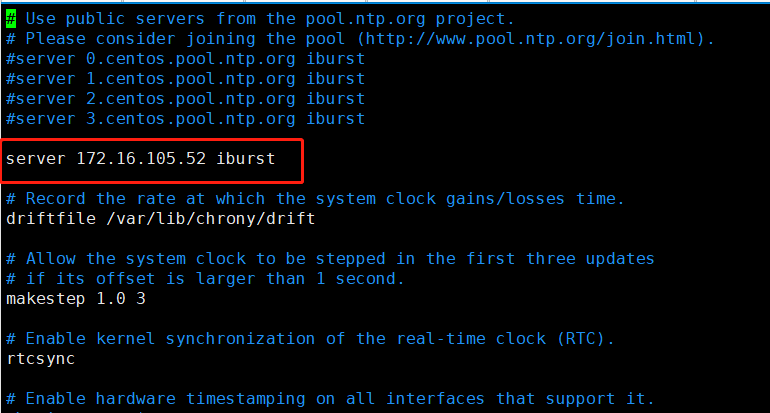
vim /etc/chrony.conf
#注释所有server配置,并添加对应时间服务器地址
server 10.0.13.72 iburst
#查看是否可以ping通时间服务器
ping 10.0.13.72
#启动服务
systemctl restart chronyd
#时间配置项配置
timedatectl set-ntp yes
#查看源状态
chronyc sources
#查看存活状态
systemctl status chronyd | grep Active
#配置加载
chronyc -a makestep
#添加开机自启
systemctl enable chronyd

6.关闭swap
以下操作所有服务器依次执行
#禁止所有swap交换分区
swapoff -a
#永久关闭swap分区
sed -ri 's/.*swap.*/#&/' /etc/fstab

7.修改内核参数
以下操作所有服务器依次执行
#编辑配置
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
net.ipv6.conf.lo.disable_ipv6 = 0
net.ipv6.conf.all.forwarding = 1
EOF
#加载配置
sysctl --system
8.网络配置
以下操作所有节点执行
#编辑配置
cat > /etc/NetworkManager/conf.d/calico.conf << EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*
EOF
#重启服务
systemctl restart NetworkManager
9.配置ulimit
以下操作所有节点执行
#命令设置
ulimit -SHn 65535
#写入文件
cat >> /etc/security/limits.conf <<EOF
* soft nofile 655360
* hard nofile 131072
* soft nproc 655350
* hard nproc 655350
* seft memlock unlimited
* hard memlock unlimitedd
EOF
10.添加启用源
以下操作所有服务器执行
#安装对应rpm包
yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm -y
#通过sed更改对应配置
sed -i "s@mirrorlist@#mirrorlist@g" /etc/yum.repos.d/elrepo.repo
sed -i "s@elrepo.org/linux@mirrors.tuna.tsinghua.edu.cn/elrepo@g" /etc/yum.repos.d/elrepo.repo
#创建数据源
yum makecache fast
11.安装ipvsadm
以下操作所有服务器执行
#下载指定服务
yum install ipvsadm ipset sysstat conntrack libseccomp -y
#编辑配置
cat >> /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
#重启服务
systemctl restart systemd-modules-load.service
#效果验证
lsmod | grep -e ip_vs -e nf_conntrack

12.升级内核版本
以下操作所有服务器依次执行
#导入公钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#安装yum组件
yum -y install yum-plugin-fastestmirror
#查看elrepo源里有什么版本的内核
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
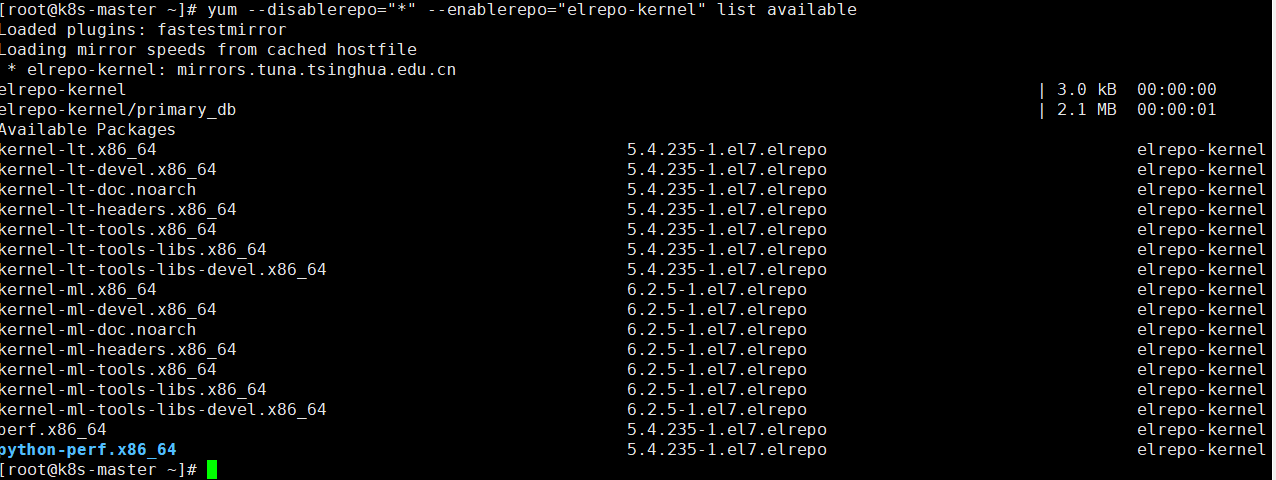
#安装长期稳定版本
yum -y --enablerepo=elrepo-kernel install kernel-lt
#查看内核是否载入到grub2
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg

#grub默认设置为0
grub2-set-default 0
#生成 grub 配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#重启linux系统
reboot
#重启完成后,查看内核版本及相关包
uname -r
rpm -qa | grep kernel

#移除旧内核版本相关的包
yum -y remove kernel-3.10.0-862*
#使用rpm过滤剩余的旧版本内核包,并删除
yum -y remove kernel-tools-3.10.0-862.el7.x86_64 kernel-tools-libs-3.10.0-862.el7.x86_64
#重新安装新版本依赖包
yum --enablerepo=elrepo-kernel -y install kernel-lt-devel kernel-lt-doc kernel-lt-headers \
kernel-lt-tools kernel-lt-tools-libs kernel-lt-tools-libs-devel
#重新安装依赖
yum -y install gcc gcc-c++ glibc-devel glibc-headers
#查看当前版本内核包
rpm -qa | grep kernel
#重启服务器
init 6

三、安装Runtime组件
在kubernetesv1.24版本后默认不支持docker作为容器运行时
如果需要使用docker-ce作为容器运行时需要额外安装cri-docker
这里推荐使用Containerd作为容器运行时
docker-ce与containerd两个选择一个进行部署即可,注意无论是docker还是containerd所有kubernetes集群内的节点都需要进行安装
1.安装Containerd(推荐)
首先下载本文档第一章节《部署说明》内的第二小节“资源包下载”,下载cni-plugins-linux-amd64-v1.1.1.tar.gz与cri-containerd-cni-1.6.8-linux-amd64.tar.gz至所有服务器上
#创建cni插件所需目录
mkdir -p /etc/cni/net.d /opt/cni/bin
#解压cni二进制包至/opt/cni/bin
tar -zxvf cni-plugins-linux-amd64-v1.1.1.tgz -C /opt/cni/bin/
#解压containerd二进制包至根目录
tar -zxvf cri-containerd-cni-1.6.8-linux-amd64.tar.gz -C /
#创建服务的启动文件
cat > /etc/systemd/system/containerd.service <<EOF
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
EOF
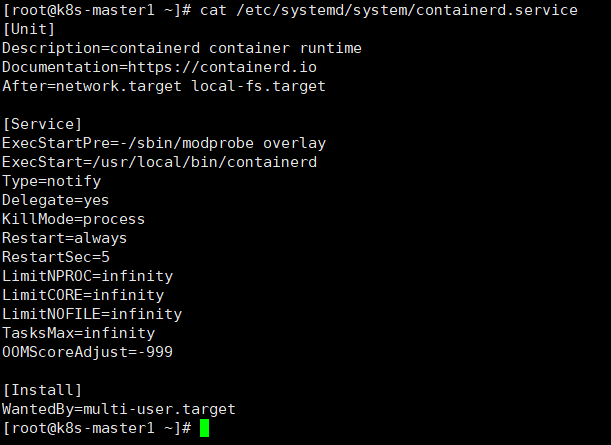
#配置Containerd所需的模块
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF

#加载模块
systemctl restart systemd-modules-load.service
#配置Containerd所需内核
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
#加载内核
sysctl --system

#创建Containerd的配置文件存储目录
mkdir -p /etc/containerd
#配置其配置文件
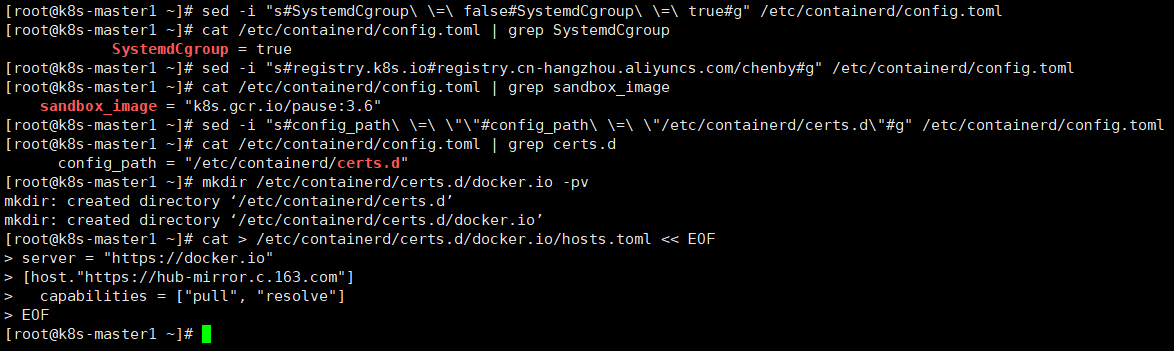
containerd config default | tee /etc/containerd/config.toml
#修改Containerd的配置文件
sed -i "s#SystemdCgroup\ \=\ false#SystemdCgroup\ \=\ true#g" /etc/containerd/config.toml
cat /etc/containerd/config.toml | grep SystemdCgroup
sed -i "s#registry.k8s.io#registry.cn-hangzhou.aliyuncs.com/chenby#g" /etc/containerd/config.toml
cat /etc/containerd/config.toml | grep sandbox_image
sed -i "s#config_path\ \=\ \"\"#config_path\ \=\ \"/etc/containerd/certs.d\"#g" /etc/containerd/config.toml
cat /etc/containerd/config.toml | grep certs.d
#创建存储目录
mkdir /etc/containerd/certs.d/docker.io -pv
#编辑镜像源配置文件
cat > /etc/containerd/certs.d/docker.io/hosts.toml << EOF
server = "https://docker.io"
[host."https://hub-mirror.c.163.com"]
capabilities = ["pull", "resolve"]
EOF
#重载service文件
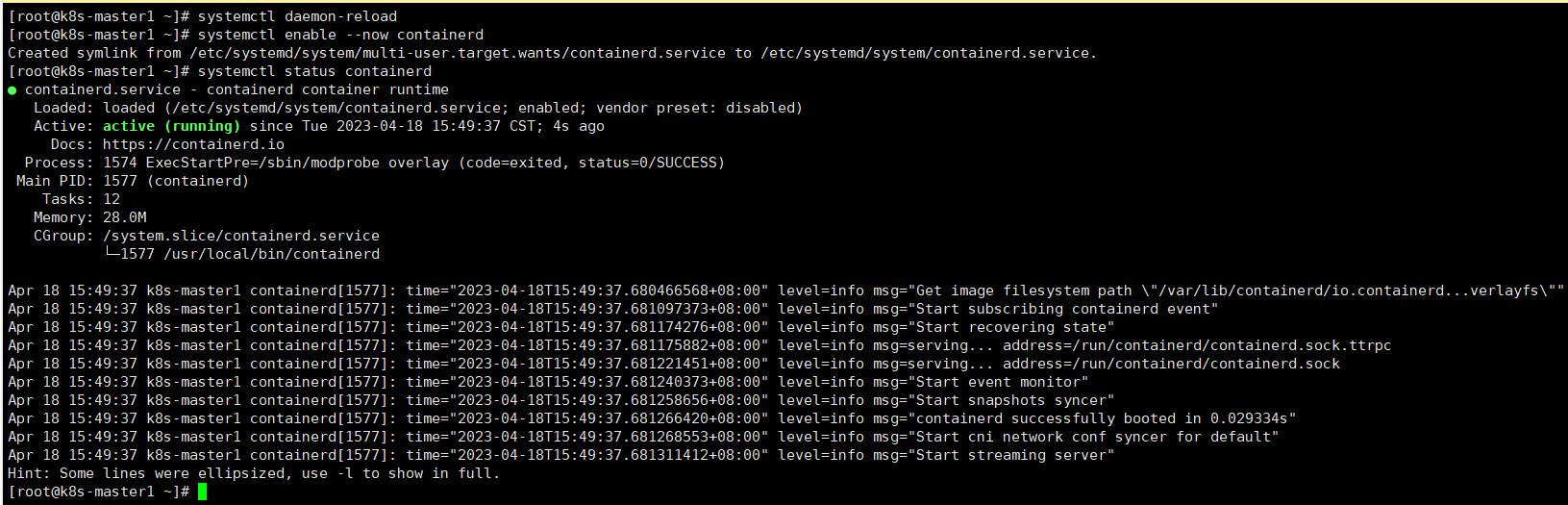
systemctl daemon-reload
#启动并开机自启
systemctl enable --now containerd
#查看启动状态
systemctl status containerd
2.安装docker(不推荐)
首先下载本文档第一章节《部署说明》内的第二小节“资源包下载”,下载docker-20.10.15.tgz至所有服务器上

#解压服务
tar -zxvf docker-20.10.15.tgz
#拷贝二进制文件
cp docker/* /usr/bin/
#创建containerd的service文件
cat >> /etc/systemd/system/containerd.service << EOF
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=1048576
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
EOF
#启动服务
systemctl enable --now containerd.service
#创建docker的service文件
cat >> /etc/systemd/system/docker.service << EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service containerd.service
Wants=network-online.target
Requires=docker.socket containerd.service
[Service]
Type=notify
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecReload=/bin/kill -s HUP \$MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
OOMScoreAdjust=-500
[Install]
WantedBy=multi-user.target
EOF
#准备docker的socket文件
cat >> /etc/systemd/system/docker.socket << EOF
[Unit]
Description=Docker Socket for the API
[Socket]
ListenStream=/var/run/docker.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF
#创建docker组
groupadd docker
#启动docker
systemctl enable --now docker.socket && systemctl enable --now docker.service
#验证
docker info
docker -v

#配置docker拉取的镜像源配置文件
mkdir /etc/docker
#编辑配置
cat >> /etc/docker/daemon.json << EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com"
],
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"data-root": "/var/lib/docker"
}
EOF
#重启服务
systemctl restart docker
2.1安装并启动cri-docker
在kubernetesv1.24版本后如果需要使用docker-ce作为容器运行时需要额外安装cri-docker
cri-dockerd的资源包下载地址在第一章节《部署说明》内的第二节‘资源包下载’内
首先将cri-dockerd-0.2.3.amd64.tgz下载至服务所有服务器内

#解压服务
tar -zxvf cri-dockerd-0.2.3.amd64.tgz
#拷贝二进制文件
cp cri-dockerd/* /usr/bin/
#生成socket文件
cat >> /usr/lib/systemd/system/cri-docker.socket << EOF
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF
#生成service文件
cat >> /usr/lib/systemd/system/cri-docker.service << EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
ExecReload=/bin/kill -s HUP \$MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
#启动服务
systemctl daemon-reload ; systemctl enable cri-docker --now
四、生成集群证书并分发
以下操作在k8s-master一台节点操作即可
| 主机 | IP | 系统版本 |
|---|---|---|
| k8s-master | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
1.安装证书工具及服务
首先按照第一章节《部署说明》内的第二小节"资源包下载",下载kubernetes-server-linux-amd64.tar.gz至服务器

#安装cfssl工具包,k8s-master1节点安装即可
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.3/cfssl_1.6.3_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.2/cfssljson_1.6.2_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.2/cfssl-certinfo_1.6.2_linux_amd64
若以上链接下载较慢,可使用以下链接下载,并上传至服务器:
链接:https://pan.baidu.com/s/1P4gck7ZmbS7gYYD92QAOWg?pwd=zska
提取码:zska

#给服务包改名
mv cfssl_1.6.3_linux_amd64 cfssl
mv cfssljson_1.6.2_linux_amd64 cfssljson
mv cfssl-certinfo_1.6.2_linux_amd64 cfssl-certinfo
#给予执行权限
chmod +x cfssl*
#转移至bin目录下,供全局使用
mv cfssl* /usr/bin/
#解压kubernetes二进制包,k8s-master1节点安装即可,交由k8s-master1节点进行分发,压缩包在资源下载处下载
tar -zxvf kubernetes-server-linux-amd64.tar.gz
#转移kubernets-master组件到bin目录下,供全局使用
cp kubernetes/server/bin/{kube-apiserver,kube-controller-manager,kube-scheduler,kube-proxy,kubelet,kubectl} /usr/bin/
#分发kubernetes的二进制文件,以下变量赋值为自己的ip地址
master="10.0.13.81"
node="10.0.13.73 10.0.13.75"
#分发master组件
for i in $master ; do scp kubernetes/server/bin/{kube-apiserver,kube-controller-manager,kube-scheduler,kube-proxy,kubelet,kubectl} $i:/usr/bin ; done
#分发node组件
for i in $node;do scp kubernetes/server/bin/{kube-proxy,kubelet} $i:/usr/bin ; done

2.创建etcd集群证书
以下操作k8s-master1节点执行,由k8s-master1节点进行证书的创建及分发
#创建证书操作目录
mkdir -p /opt/pki/etcd
#切换工作目录
cd /opt/pki/etcd
#创建etcd的ca证书文件
mkdir ca && cd ca
#生成配置文件
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
#生成申请文件
cat > ca-csr.json <<EOF
{
"CA":{"expiry":"87600h"},
"CN": "etcd-cluster",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "etcd-cluster",
"OU": "System"
}
]
}
EOF
#生成ca证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca

#切换目录
cd /opt/pki/etcd/
#生成etcd服务端证书文件,注意hosts前三行是etcd集群地址,请规划好etcd部署的节点,选择三台即可
cat > etcd-server-csr.json << EOF
{
"CN": "etcd-server",
"hosts": [
"10.0.13.72",
"10.0.13.81",
"10.0.13.73",
"127.0.0.1"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "etcd-server",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert \
-ca=ca/ca.pem \
-ca-key=ca/ca-key.pem \
-config=ca/ca-config.json \
-profile=etcd \
etcd-server-csr.json | cfssljson -bare etcd-server

#切换目录
cd /opt/pki/etcd/
#生成etcd客户端证书申请文件
cat > etcd-client-csr.json << EOF
{
"CN": "etcd-client",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "etcd-client",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert \
-ca=ca/ca.pem \
-ca-key=ca/ca-key.pem \
-config=ca/ca-config.json \
-profile=etcd \
etcd-client-csr.json | cfssljson -bare etcd-client
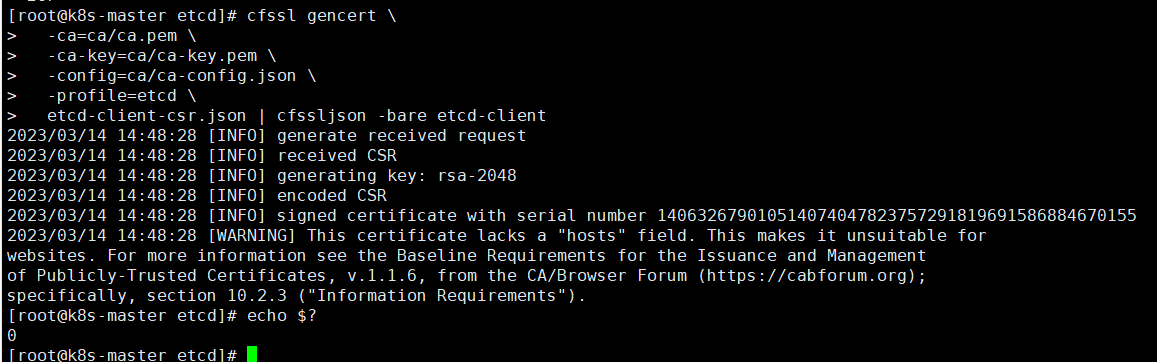
#查看证书文件是否已经建立
yum -y install tree
#查看
tree .

#拷贝到etcd节点与master节点,注意是master节点也要拷贝
master_etcd="10.0.13.72 10.0.13.81 10.0.13.73"
#发送
for i in $master_etcd ; do ssh $i "mkdir /etc/etcd/ssl -p" ; scp /opt/pki/etcd/ca/ca.pem /opt/pki/etcd/{etcd-server.pem,etcd-server-key.pem,etcd-client.pem,etcd-client-key.pem} $i:/etc/etcd/ssl/ ; done

3.创建kubernetes集群证书
以下操作在k8s-master节点操作
3.1生成kubernetes-ca证书
#创建目录
mkdir -p /opt/pki/kubernetes/
#切换目录
cd /opt/pki/kubernetes
#创建ca目录
mkdir ca && cd ca
#创建ca配置文件
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
#创建ca申请文件
cat > ca-csr.json <<EOF
{
"CA":{"expiry":"87600h"},
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "kubernetes",
"OU": "System"
}
]
}
EOF
#生成ca证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca

3.2生成kube-apiserver证书
#创建目录
mkdir -p /opt/pki/kubernetes/kube-apiserver
#切换目录
cd /opt/pki/kubernetes/kube-apiserver
#生成证书申请文件,hosts栏内填写集群所有ip及vip地址,建议多填几个预留IP,注意其中10.200.0.1是后续配置kubernetes的service网段(10.200.0.0/16),如果您想要的网段为192.0.0.0/16则替换为该网段的其中IP,例如192.0.0.1
cat > kube-apiserver-csr.json <<EOF
{
"CN": "kube-apiserver",
"hosts": [
"127.0.0.1",
"10.0.13.72",
"10.0.13.81",
"10.0.13.73",
"10.0.13.75",
"10.0.13.76",
"10.0.13.77",
"10.0.13.78",
"10.0.13.79",
"10.0.13.80",
"10.0.13.81",
"10.0.13.82",
"10.0.13.110",
"10.200.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "kube-apiserver",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert \
-ca=../ca/ca.pem \
-ca-key=../ca/ca-key.pem \
-config=../ca/ca-config.json \
-profile=kubernetes \
kube-apiserver-csr.json | cfssljson -bare kube-apiserver
#分发kube-apiserver证书文件到master节点
master="10.0.13.72 10.0.13.81"
for i in $master ; do ssh $i "mkdir /etc/kubernetes/pki -p" ; scp /opt/pki/kubernetes/ca/{ca.pem,ca-key.pem} /opt/pki/kubernetes/kube-apiserver/{kube-apiserver-key.pem,kube-apiserver.pem} $i:/etc/kubernetes/pki ; done
#分发kube-apiserver证书文件到node节点
node="10.0.13.73 10.0.13.75"
for i in $node ; do ssh $i "mkdir /etc/kubernetes/pki -p" ; scp /opt/pki/kubernetes/ca/ca.pem $i:/etc/kubernetes/pki ; done
3.3生成proxy-client和ca证书
#创建目录
mkdir /opt/pki/proxy-client
#切换目录
cd /opt/pki/proxy-client
#生成ca配置文件
cat > front-proxy-ca-csr.json <<EOF
{
"CA":{"expiry":"87600h"},
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
}
}
EOF
#生成ca文件
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare front-proxy-ca

#生成客户端证书申请文件
cat > front-proxy-client-csr.json <<EOF
{
"CN": "front-proxy-client",
"key": {
"algo": "rsa",
"size": 2048
}
}
EOF
#生成证书
cfssl gencert \
-ca=front-proxy-ca.pem \
-ca-key=front-proxy-ca-key.pem \
-config=../kubernetes/ca/ca-config.json \
-profile=kubernetes front-proxy-client-csr.json | cfssljson -bare front-proxy-client
#拷贝证书到master节点
master="10.0.13.72 10.0.13.81"
for i in $master ; do scp /opt/pki/proxy-client/{front-proxy-ca.pem,front-proxy-client.pem,front-proxy-client-key.pem} $i:/etc/kubernetes/pki ; done
#拷贝证书到node节点
node="10.0.13.73 10.0.13.75"
for i in $node ; do scp /opt/pki/proxy-client/front-proxy-ca.pem $i:/etc/kubernetes/pki ; done

3.4生成kube-controller-manager证书和文件
#创建目录
mkdir -p /opt/pki/kubernetes/kube-controller-manager
#切换工作目录
cd /opt/pki/kubernetes/kube-controller-manager
#生成证书请求文件
cat > kube-controller-manager-csr.json <<EOF
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "system:kube-controller-manager",
"OU": "System"
}
]
}
EOF
#生成证书文件
cfssl gencert \
-ca=../ca/ca.pem \
-ca-key=../ca/ca-key.pem \
-config=../ca/ca-config.json \
-profile=kubernetes \
kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
#生成配置文件,注意后面赋值的IP,是我们的vip(虚拟IP)
export KUBE_APISERVER="https://10.0.13.110:8443"
#使用kubectl进行配置
kubectl config set-cluster kubernetes \
--certificate-authority=../ca/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=kube-controller-manager.pem \
--client-key=kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config use-context default --kubeconfig=kube-controller-manager.kubeconfig
#分发证书到master节点
master="10.0.13.72 10.0.13.81"
#发送
for i in $master ; do scp /opt/pki/kubernetes/kube-controller-manager/kube-controller-manager.kubeconfig $i:/etc/kubernetes/ ; done

3.5生成kube-scheduler证书
#创建目录
mkdir /opt/pki/kubernetes/kube-scheduler
#切换目录
cd /opt/pki/kubernetes/kube-scheduler
#生成证书申请文件
cat > kube-scheduler-csr.json <<EOF
{
"CN": "system:kube-scheduler",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "system:kube-scheduler",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert \
-ca=../ca/ca.pem \
-ca-key=../ca/ca-key.pem \
-config=../ca/ca-config.json \
-profile=kubernetes \
kube-scheduler-csr.json | cfssljson -bare kube-scheduler
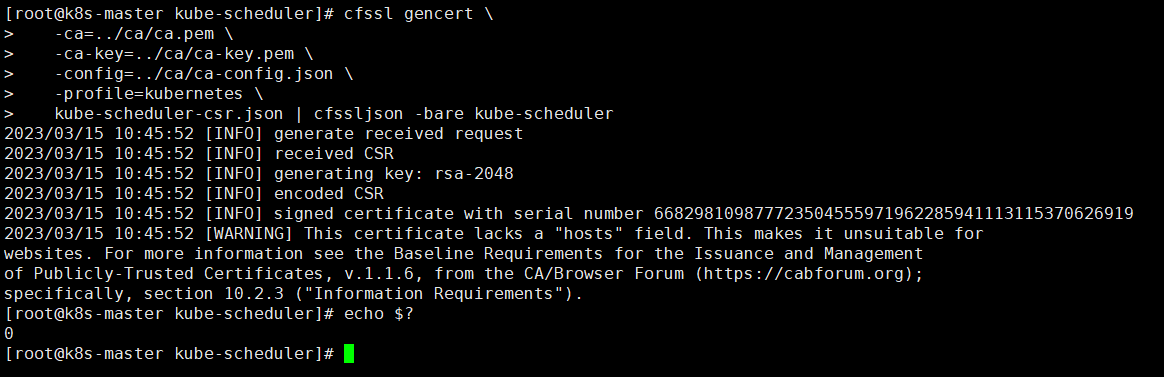
#生成配置文件,注意后面赋值的IP,是我们的vip(虚拟IP)
export KUBE_APISERVER="https://10.0.13.110:8443"
#使用kubectl进行配置
kubectl config set-cluster kubernetes \
--certificate-authority=../ca/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-credentials system:kube-scheduler \
--client-certificate=kube-scheduler.pem \
--client-key=kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config use-context default --kubeconfig=kube-scheduler.kubeconfig
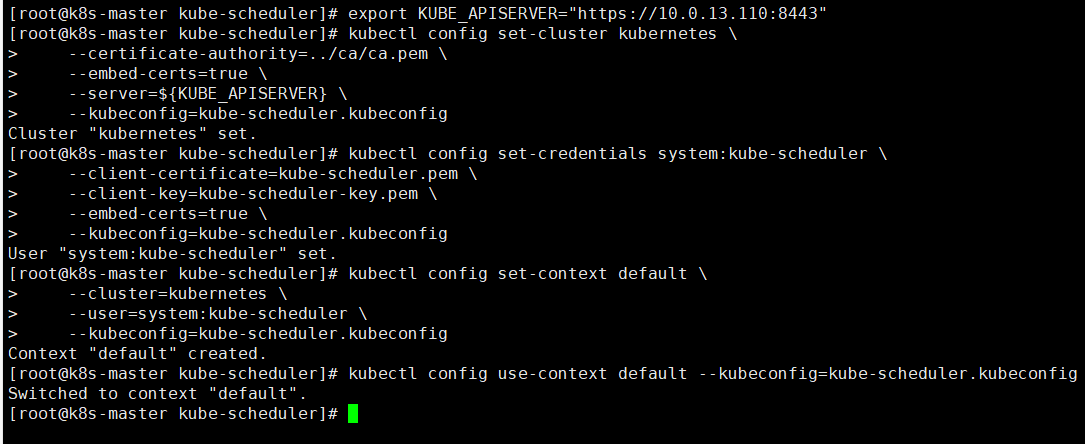
#拷贝文件到master节点
master="10.0.13.72 10.0.13.81"
#发送
for i in $master ; do scp /opt/pki/kubernetes/kube-scheduler/kube-scheduler.kubeconfig $i:/etc/kubernetes ; done
3.6生成集群管理员证书
#创建目录
mkdir /opt/pki/kubernetes/admin
#切换目录
cd /opt/pki/kubernetes/admin
#生成证书申请文件
cat > admin-csr.json <<EOF
{
"CN": "admin",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"TS": "Beijing",
"L": "Beijing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
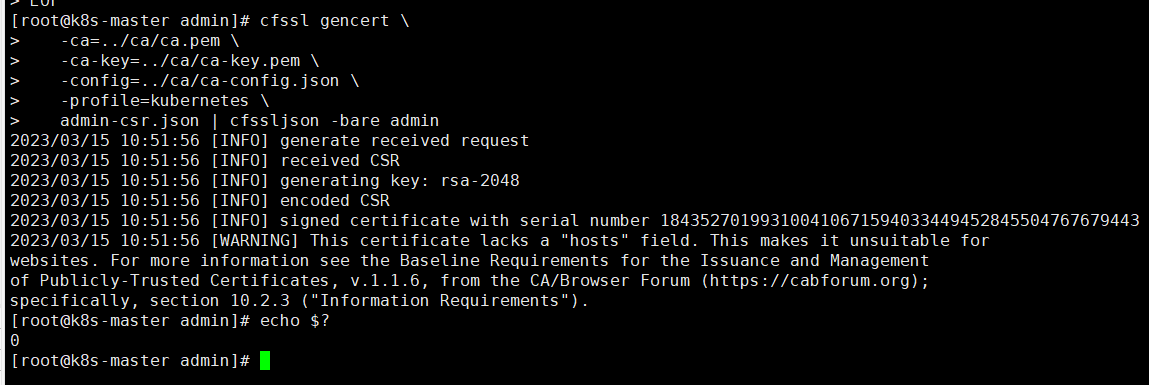
#生成证书
cfssl gencert \
-ca=../ca/ca.pem \
-ca-key=../ca/ca-key.pem \
-config=../ca/ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare admin
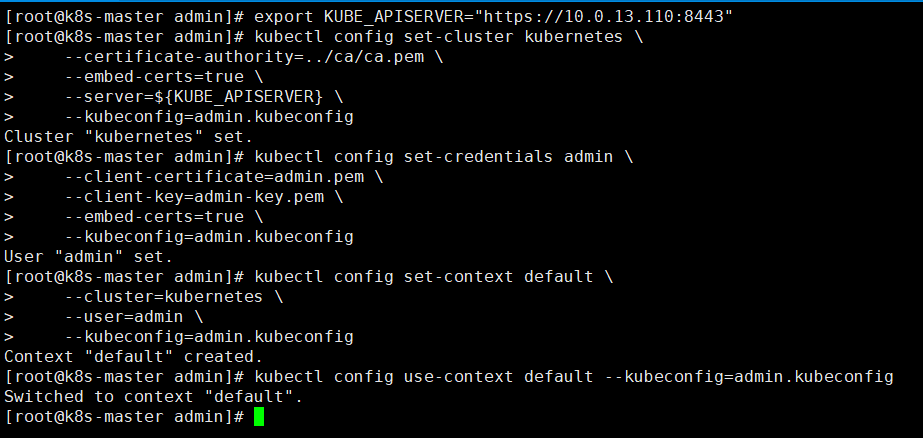
#生成配置文件,,注意后面赋值的IP,是我们的vip(虚拟IP)
export KUBE_APISERVER="https://10.0.13.110:8443"
#使用kubectl进行配置
kubectl config set-cluster kubernetes \
--certificate-authority=../ca/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=admin.kubeconfig
kubectl config set-credentials admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem \
--embed-certs=true \
--kubeconfig=admin.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user=admin \
--kubeconfig=admin.kubeconfig
kubectl config use-context default --kubeconfig=admin.kubeconfig
#拷贝证书文件到master
master="10.0.13.72 10.0.13.81"
#发送
for i in $master ; do scp /opt/pki/kubernetes/admin/admin.kubeconfig $i:/etc/kubernetes ; done
五、安装ETCD集群
以下操作为etcd集群节点的轮次操作
需要先将本文章第二章节《部署说明》内"资源包下载"栏中的etcd-v3.5.3-linux-amd64.tar.gz下载并上传至Etcd集群各节点服务器内
我的etcd分配节点为
| 主机 | IP | 备注 |
|---|---|---|
| k8s-master1 | 10.0.13.72 | ETCD-1 |
| k8s-master2 | 10.0.13.73 | ETCD-2 |
| k8s-node1 | 10.0.13.81 | ETCD-3 |
1.节点一部署
以下为ETCD节点一操作,将etcd-v3.5.3-linux-amd64.tar.gz上传至etcd节点一上,注意是之前申请证书就已经定义好的etcd节点,不要随便找台机器部署
#解压二进制资源包
tar -zxvf etcd-v3.5.3-linux-amd64.tar.gz
#复制到环境内,供全局使用
cp etcd-v3.5.3-linux-amd64/etcd* /usr/bin/
#创建etcd配置文件,注意将本机IP和集群IP改为自己的IP,其中etcd-1='10.0.13.72',etcd-2='10.0.13.81',etcd-3='10.0.13.73',证书路径之前分发过即可不用更改,没有分发请再手动分发
cat >> /etc/etcd/etcd.config.yml << EOF
name: 'etcd-1'
data-dir: /var/lib/etcd
wal-dir: /var/lib/etcd/wal
snapshot-count: 5000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'https://10.0.13.72:2380'
listen-client-urls: 'https://10.0.13.72:2379,https://127.0.0.1:2379'
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: 'https://10.0.13.72:2380'
advertise-client-urls: 'https://10.0.13.72:2379'
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: 'etcd-1=https://10.0.13.72:2380,etcd-2=https://10.0.13.81:2380,etcd-3=https://10.0.13.73:2380'
initial-cluster-token: 'etcd-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
peer-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
peer-client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
debug: false
log-package-levels:
log-outputs: [default]
force-new-cluster: false
EOF
2.节点二部署
以下为ETCD节点二操作,将etcd-v3.5.3-linux-amd64.tar.gz上传至etcd节点二上,注意是之前申请证书就已经定义好的etcd节点,不要随便找台机器部署
#解压二进制资源包
tar -zxvf etcd-v3.5.3-linux-amd64.tar.gz
#复制到环境内,供全局使用
cp etcd-v3.5.3-linux-amd64/etcd* /usr/bin/
#创建etcd配置文件,注意将本机IP和集群IP改为自己的IP,其中etcd-1='10.0.13.72',etcd-2='10.0.13.81',etcd-3='10.0.13.73',证书路径之前分发过即可不用更改,没有分发请再手动分发
cat >> /etc/etcd/etcd.config.yml << EOF
name: 'etcd-2'
data-dir: /var/lib/etcd
wal-dir: /var/lib/etcd/wal
snapshot-count: 5000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'https://10.0.13.81:2380'
listen-client-urls: 'https://10.0.13.81:2379,https://127.0.0.1:2379'
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: 'https://10.0.13.81:2380'
advertise-client-urls: 'https://10.0.13.81:2379'
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: 'etcd-1=https://10.0.13.72:2380,etcd-2=https://10.0.13.81:2380,etcd-3=https://10.0.13.73:2380'
initial-cluster-token: 'etcd-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
peer-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
peer-client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
debug: false
log-package-levels:
log-outputs: [default]
force-new-cluster: false
EOF
3.节点三部署
以下为ETCD节点三操作,将etcd-v3.5.3-linux-amd64.tar.gz上传至etcd节点三上,注意是之前申请证书就已经定义好的etcd节点,不要随便找台机器部署
#解压二进制资源包
tar -zxvf etcd-v3.5.3-linux-amd64.tar.gz
#复制到环境内,供全局使用
cp etcd-v3.5.3-linux-amd64/etcd* /usr/bin/
#创建etcd配置文件,注意将本机IP和集群IP改为自己的IP,其中etcd-1='10.0.13.72',etcd-2='10.0.13.81',etcd-3='10.0.13.73',证书路径之前分发过即可不用更改,没有分发请再手动分发
cat >> /etc/etcd/etcd.config.yml << EOF
name: 'etcd-3'
data-dir: /var/lib/etcd
wal-dir: /var/lib/etcd/wal
snapshot-count: 5000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'https://10.0.13.73:2380'
listen-client-urls: 'https://10.0.13.73:2379,https://127.0.0.1:2379'
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: 'https://10.0.13.73:2380'
advertise-client-urls: 'https://10.0.13.73:2379'
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: 'etcd-1=https://10.0.13.72:2380,etcd-2=https://10.0.13.81:2380,etcd-3=https://10.0.13.73:2380'
initial-cluster-token: 'etcd-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
peer-transport-security:
cert-file: '/etc/etcd/ssl/etcd-server.pem'
key-file: '/etc/etcd/ssl/etcd-server-key.pem'
peer-client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/ca.pem'
auto-tls: true
debug: false
log-package-levels:
log-outputs: [default]
force-new-cluster: false
EOF
4.启动ETCD服务
以下操作所有ETCD节点执行
#生成Etcd的service文件
cat >> /etc/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Service
Documentation=https://coreos.com/etcd/docs/latest/
After=network.target
[Service]
Type=notify
ExecStart=/usr/bin/etcd --config-file=/etc/etcd/etcd.config.yml
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
Alias=etcd3.service
EOF
#加载配置
systemctl daemon-reload
#启动服务,三台节点一起执行,一起启动
systemctl enable --now etcd
#配置etcdctl使用v3 api
cat >> /etc/profile.d/etcdctl.sh << EOF
#!/bin/bash
export ETCDCTL_API=3
export ETCDCTL_ENDPOINTS=https://127.0.0.1:2379
export ETCDCTL_CACERT=/etc/etcd/ssl/ca.pem
export ETCDCTL_CERT=/etc/etcd/ssl/etcd-client.pem
export ETCDCTL_KEY=/etc/etcd/ssl/etcd-client-key.pem
EOF
#加载配置
source /etc/profile
#验证集群状态
etcdctl member list --write-out='table'

六、安装kubernetes集群
各类环境及所需要服务部署完毕后,开始部署kubernetes各组件
1.安装kube-apiserver
以下操作为k8s-master1节点操作
#创建Service Account Key
openssl genrsa -out /etc/kubernetes/pki/sa.key 2048
openssl rsa -in /etc/kubernetes/pki/sa.key -pubout -out /etc/kubernetes/pki/sa.pub
#分发给其他master节点
master="10.0.13.72 10.0.13.81"
#发送
for i in $master ; do scp /etc/kubernetes/pki/{sa.pub,sa.key} $i:/etc/kubernetes/pki/ ; done

以下操作k8s-master(10.0.13.72)节点与k8s-master2(10.0.13.81)节点依次执行
#定义a变量,赋值为本机IP(便于理解)
a='10.0.13.72'
#master2节点也定义为自己的IP
a='10.0.13.81'
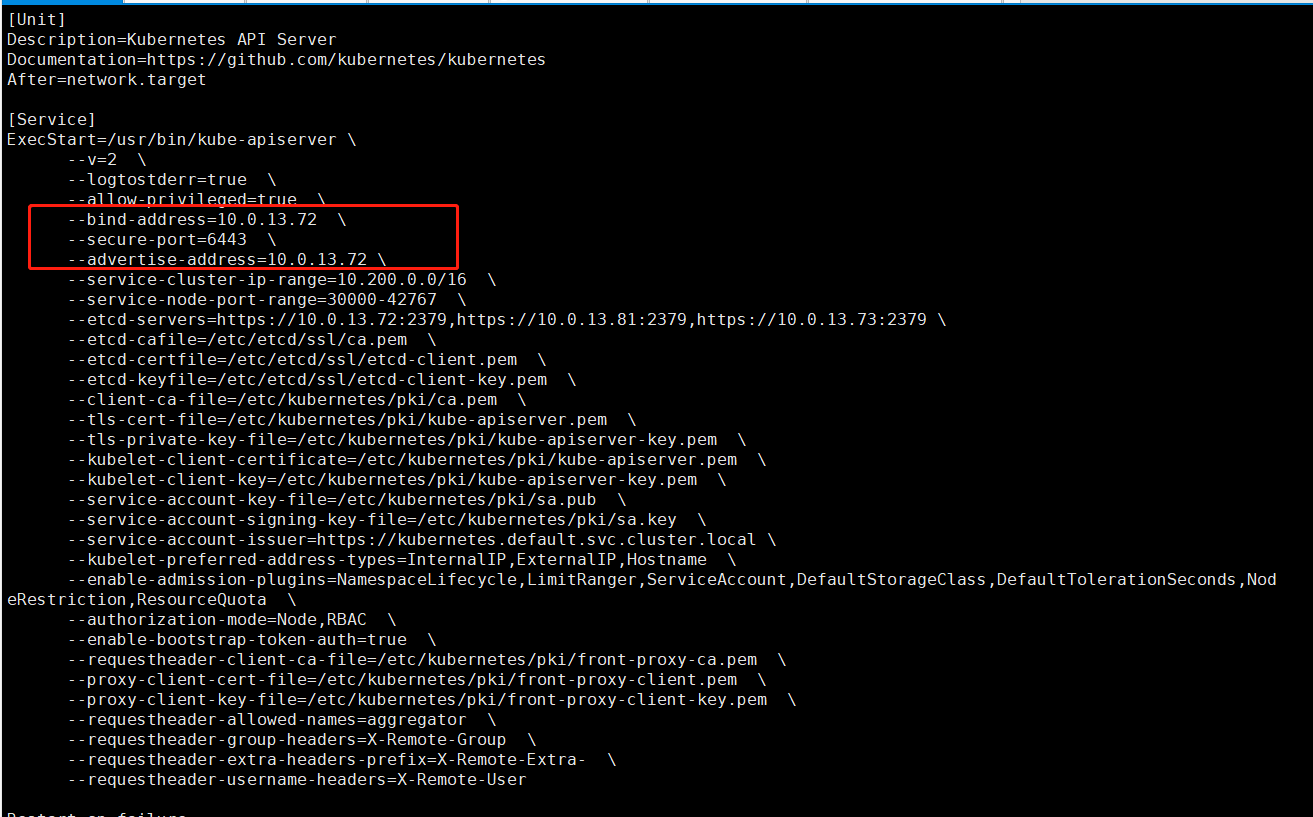
#创建service文件,以下配置项值采用$a的,代表要填写的是本机IP,etcd-servers后填写自己etcd集群的IP地址即可
cat >> /etc/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-apiserver \\
--v=2 \\
--logtostderr=true \\
--allow-privileged=true \\
--bind-address=$a \\
--secure-port=6443 \\
--advertise-address=$a \\
--service-cluster-ip-range=10.200.0.0/16 \\
--service-node-port-range=30000-42767 \\
--etcd-servers=https://10.0.13.72:2379,https://10.0.13.81:2379,https://10.0.13.73:2379 \\
--etcd-cafile=/etc/etcd/ssl/ca.pem \\
--etcd-certfile=/etc/etcd/ssl/etcd-client.pem \\
--etcd-keyfile=/etc/etcd/ssl/etcd-client-key.pem \\
--client-ca-file=/etc/kubernetes/pki/ca.pem \\
--tls-cert-file=/etc/kubernetes/pki/kube-apiserver.pem \\
--tls-private-key-file=/etc/kubernetes/pki/kube-apiserver-key.pem \\
--kubelet-client-certificate=/etc/kubernetes/pki/kube-apiserver.pem \\
--kubelet-client-key=/etc/kubernetes/pki/kube-apiserver-key.pem \\
--service-account-key-file=/etc/kubernetes/pki/sa.pub \\
--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \\
--service-account-issuer=https://kubernetes.default.svc.cluster.local \\
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \\
--authorization-mode=Node,RBAC \\
--enable-bootstrap-token-auth=true \\
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \\
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \\
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \\
--requestheader-allowed-names=aggregator \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-extra-headers-prefix=X-Remote-Extra- \\
--requestheader-username-headers=X-Remote-User
Restart=on-failure
RestartSec=10s
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
EOF
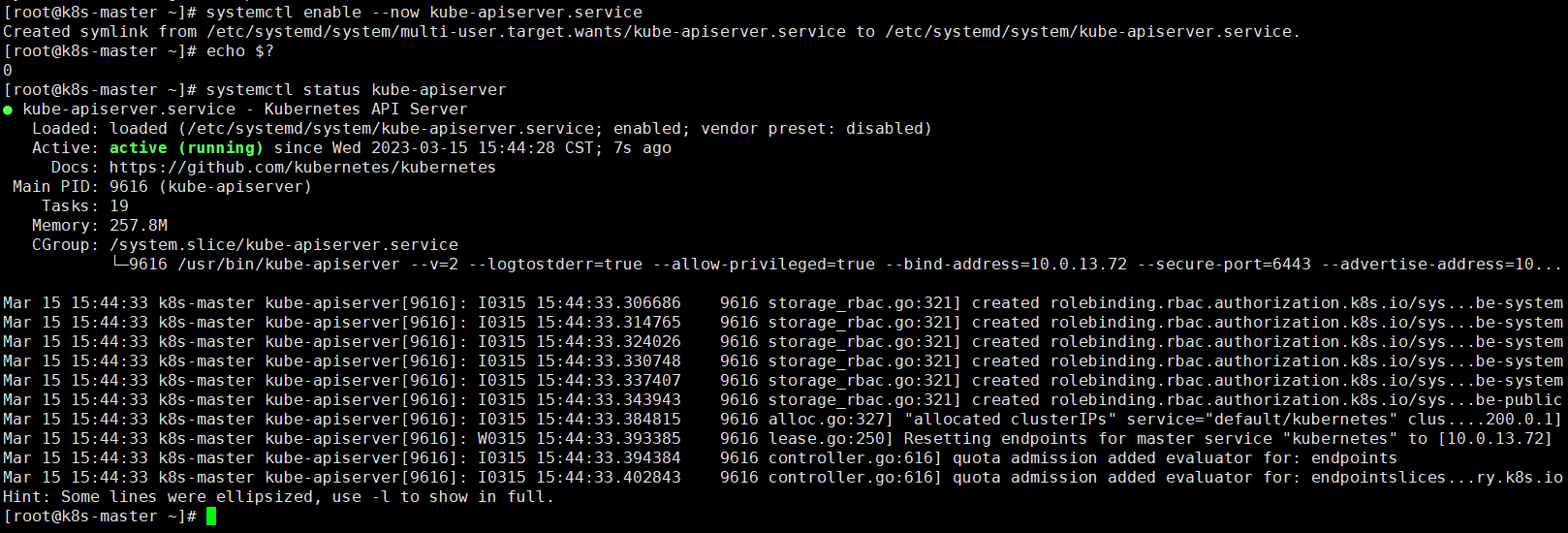
#启动服务
systemctl enable --now kube-apiserver.service
2.Apiserver高可用配置
以下操作可以单独找两台服务器做,也可以直接在两台master节点上操作
最终目的都是代理两台master节点,作为集群的前置机,至于要两台是为了防止单点故障,这一点我们采用keepalived实现
本次部署采用将代理服务以及keepalived部署在两台master节点上
| 主机 | IP | 系统版本 |
|---|---|---|
| k8s-master&Nginx-master | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
| k8s-master2&Nginx-backup | 10.0.13.81 | CentOS Linux release 7.5.1804 (Core) |
2.1部署并配置Keepalived
首先下载本文档第一章节《部署说明》内的第二小节“资源包下载”,下载keepalived-2.2.7.tar.gz至master节点上
以下操作master节点或代理节点依次执行

#安装编译依赖
yum install -y openssl*
yum install -y openssh*
yum install -y gcc* pcre pcre-devel zlib zlib-devel
#创建安装操作目录,建议选择磁盘空间充足目录进行创建(已存在则跳过)
mkdir /data
#解压至指定目录
tar -zxvf keepalived-2.2.7.tar.gz -C /data/
#创建安装目录
mkdir /data/keepalived
#切换目录
cd /data/keepalived-2.2.7/
#指定编译安装目录
./configure --prefix=/data/keepalived
#编译安装
make && make install
#创建命令软链
ln -s /data/keepalived/sbin/keepalived /usr/local/sbin/keepalived
#验证命令及查看版本
keepalived -v
以下是节点一(master)配置操作
#切换目录
cd /data/keepalived/etc/keepalived
#备份原配置文件
cp keepalived.conf.sample keepalived.conf
#编辑keepalived.conf
vim keepalived.conf
#删除所有内容后,添加以下内容,注意将IP改为自己实际的IP
! Configuration File for keepalived
##keepalived-vrrp配置
##配置路径:/data/keepalived/etc/keepalived/keepalived.conf
##声明全局配置
global_defs {
#声明设备名称,各节点不同
router_id haproxy-1
#启用脚本执行安全模式,例如路径为非root可写,不要配置脚本为root用户执行
enable_script_security
#声明脚本执行用户名
script_user root
}
##vrrp脚本声明
vrrp_script chk_apiserver {
#脚本执行路径
script "/data/keepalived/sh/check_apiserver.sh"
#检测脚本执行间隔,单位秒
interval 2
#脚本执行成功后,优先级改变,正为增加,负为减少
weight -5
}
##vrrp实例定义
vrrp_instance VI_1001 {
#设置初始状态,若需要设置为非抢占模式,建议初始状态均为BACKUP,
state MASTER
#VRRP绑定的设备网络接口
interface ens192
#发送多播包的地址,为本地ens192的实际IP
mcast_src_ip 10.0.13.72
#虚拟路由ID,所有设备均要一致
virtual_router_id 101
#设置设备初始优先级,各节点不同分别为87\101
priority 110
#发送组播包的时间间隔,默认1秒
advert_int 1
#设置单播通告源地址,即为本地ens192的实际IP
unicast_src_ip 10.0.13.72
#设置单播的目的地址,即其他主机IP,如有多个,一行写一个
unicast_peer {
10.0.13.81
}
#通信认证
authentication {
#认证类型,有PASS简单密码和AH:IPSEC两种类型
auth_type PASS
#通信密码字符串,最长为8位
auth_pass kaixin
}
#VIP配置
virtual_ipaddress {
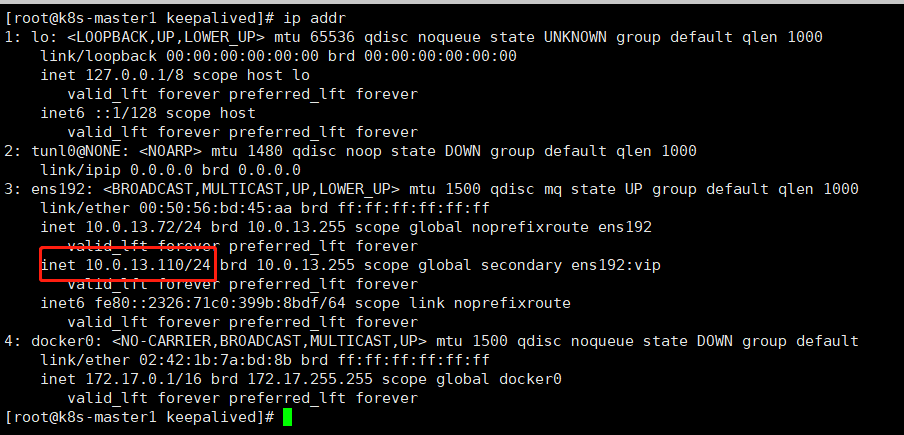
10.0.13.110/24 brd 10.0.13.255 dev ens192 label ens192:vip
}
#调用检测脚本
track_script {
chk_apiserver
}
}
以下为节点二(bakcup)配置操作
#切换目录
cd /data/keepalived/etc/keepalived
#备份原配置文件
cp keepalived.conf.sample keepalived.conf
#编辑keepalived.conf
vim keepalived.conf
#删除所有内容后,添加以下内容,注意将IP改为自己实际的IP
! Configuration File for keepalived
##keepalived-vrrp配置
##配置路径:/data/keepalived/etc/keepalived/keepalived.conf
##声明全局配置
global_defs {
#声明设备名称,各节点不同
router_id haproxy-2
#启用脚本执行安全模式,例如路径为非root可写,不要配置脚本为root用户执行
enable_script_security
#声明脚本执行用户名
script_user root
}
##vrrp脚本声明
vrrp_script chk_apiserver {
#脚本执行路径
script "/data/keepalived/sh/check_apiserver.sh"
#检测脚本执行间隔,单位秒
interval 2
#脚本执行成功后,优先级改变,正为增加,负为减少
weight -5
}
##vrrp实例定义
vrrp_instance VI_1001 {
#设置初始状态,若需要设置为非抢占模式,建议初始状态均为BACKUP,
state BACKUP
#VRRP绑定的设备网络接口
interface ens192
#发送多播包的地址,为本地ens192的实际IP
mcast_src_ip 10.0.13.81
#虚拟路由ID,所有设备均要一致
virtual_router_id 101
#设置设备初始优先级,各节点不同分别为87\101
priority 87
#发送组播包的时间间隔,默认1秒
advert_int 1
#设置单播通告源地址,即为本地ens192的实际IP
unicast_src_ip 10.0.13.81
#设置单播的目的地址,即其他主机IP,如有多个,一行写一个
unicast_peer {
10.0.13.72
}
#通信认证
authentication {
#认证类型,有PASS简单密码和AH:IPSEC两种类型
auth_type PASS
#通信密码字符串,最长为8位
auth_pass kaixin
}
#VIP配置
virtual_ipaddress {
10.0.13.110/24 brd 10.0.13.255 dev ens192 label ens192:vip
}
#调用检测脚本
track_script {
chk_apiserver
}
}
依次启动服务先启master后启backup
#首先创建配置软链,keepalived默认会读取etc下的配置
ln -s /data/keepalived/etc/keepalived /etc/keepalived
#启动并设置开机自启keepalived
systemctl enable --now keepalived
#主节点查看Vip挂载情况
ip addr
2.2部署并配置Haproxy
首先下载本文档第一章节《部署说明》内的第二小节“资源包下载”,下载haproxy-2.6.12.tar.gz至master节点上
以下操作两台代理节点依次执行,我使用的是k8s的master节点也充当代理节点,所以在两台master节点执行
#安装编译环境
yum -y install make gcc pcre-devel bzip2-devel openssl-devel systemd-devel
#解压haproxy压缩包
tar -zxvf haproxy-2.6.12.tar.gz
#创建haproxy用户
useradd -r -M -s /sbin/nologin haproxy
#切换目录
cd haproxy-2.6.12
#编译
make clean
make -j $(grep 'processor' /proc/cpuinfo |wc -l) \
TARGET=linux-glibc \
USE_OPENSSL=1 \
USE_ZLIB=1 \
USE_PCRE=1 \
USE_SYSTEMD=1
#配置安装目录,选择磁盘空间充足分区
make install PREFIX=/data/haproxy
#复制命令到环境变量目录内,供全局使用
cp ~/haproxy-2.6.12/haproxy /usr/sbin/
#设置Linux内核参数,开启路由转发
cat >> /etc/sysctl.conf << EOF
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
EOF
#使配置生效
sysctl -p
#创建配置目录
mkdir /etc/haproxy
#编辑配置文件,注意更改IP为自己的IP
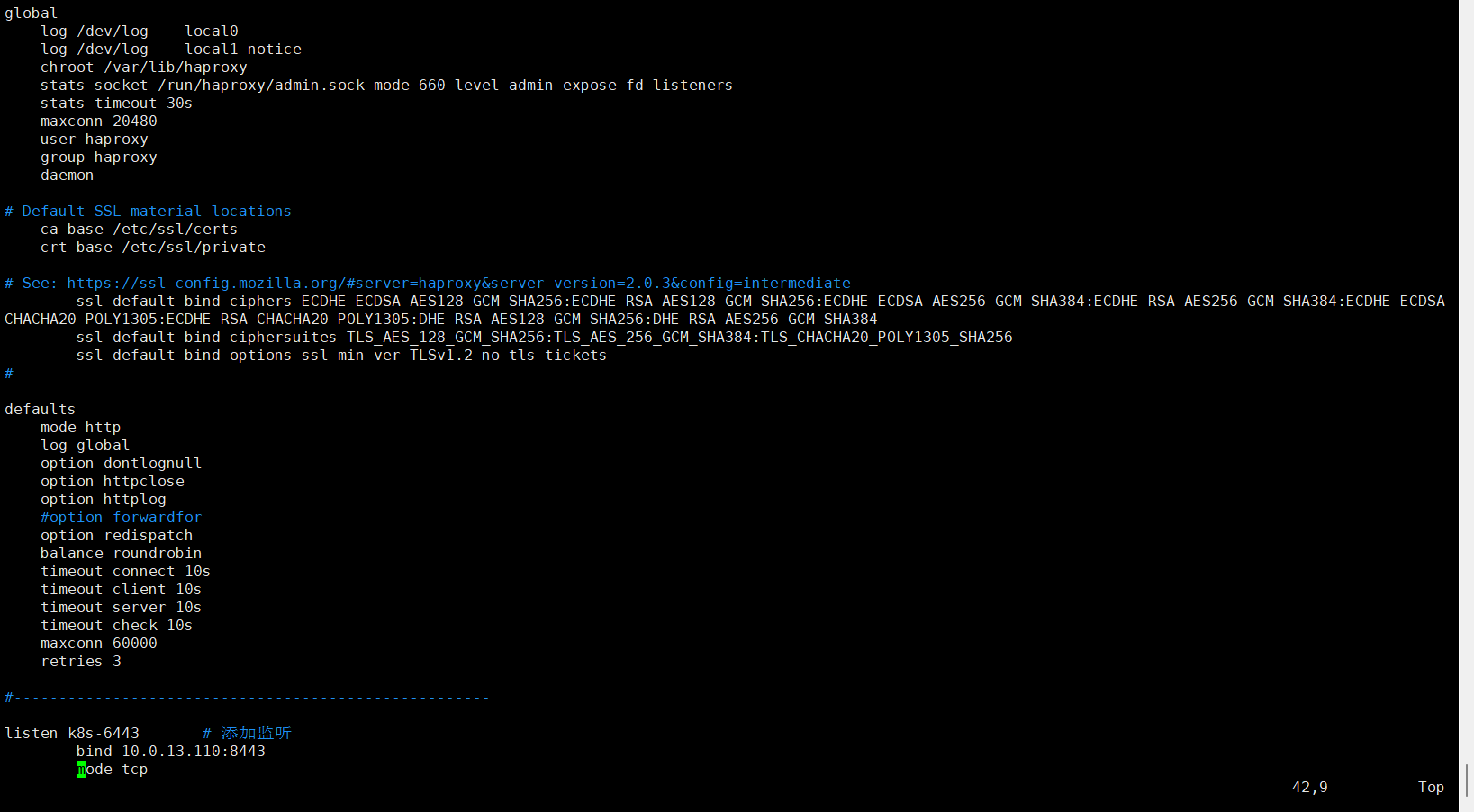
cat >/etc/haproxy/haproxy.cfg <<EOF
global
log 127.0.0.1 local0 info
#log loghost local0 info
maxconn 20480
#chroot /usr/local/haproxy
pidfile /var/run/haproxy.pid
#maxconn 4000
user haproxy
group haproxy
daemon
#---------------------------------------------------------------------
#common defaults that all the 'listen' and 'backend' sections will
#use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option dontlognull
option httpclose
option httplog
#option forwardfor
option redispatch
balance roundrobin
timeout connect 10s
timeout client 10s
timeout server 10s
timeout check 10s
maxconn 60000
retries 3
#--------------Api-Server代理配置------------------
listen k8s-6443
bind 10.0.13.110:8443
stats enable
mode tcp
log global
server k8s1 10.0.13.72:6443 check inter 3s fall 3 rise 5 # 每三秒一次健康检查
server k8s2 10.0.13.81:6443 check inter 3s fall 3 rise 5
EOF
#编写haproxy的service文件,注意目录地址根据实际做出更改
cat > /usr/lib/systemd/system/haproxy.service << EOF
[Unit]
Description=HAProxy Load Balancer
After=syslog.target network.target
[Service]
ExecStartPre=/data/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg -c -q
ExecStart=/data/haproxy/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid
ExecReload=/bin/kill -USR2 \$MAINPID
[Install]
WantedBy=multi-user.target
EOF
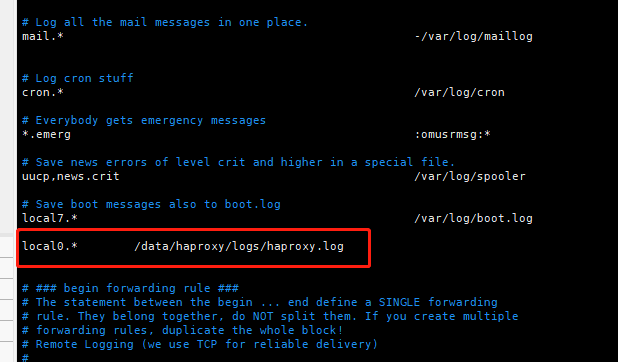
#编辑配置服务
vim /etc/rsyslog.conf
#添加haproxy配置文件内定义的日志名,我们定义的是local0,即添加以下内容
local0.* /data/haproxy/logs/haproxy.log
#并将以下行注释打开后,再保存退出
$ModLoad imudp
$UDPServerRun 514
$ModLoad imtcp
$InputTCPServerRun 514

尽量添加在配置文件内定义日志位置的区域
#创建存放日志目录
mkdir /data/haproxy/logs
#使更新的service文件生效
systemctl daemon-reload
#重启日志服务
systemctl restart rsyslog
#添加开机自启
systemctl enable rsyslog
#添加开机自启
systemctl enable --now haproxy
#访问VIP进行测试,并查看是否有日志产生
curl 10.0.13.110:8443
tail /data/haproxy/logs/haproxy.log
#若没有日志文件,检查/etc/rsyslog.conf文件是否按照上方进行配置

2.3配置监测脚本
以下操作为编写keepalived的监测脚本操作,在所有keepalived服务器执行
两台代理节点依次执行以下操作
#创建脚本存储目录
mkdir /etc/keepalived/sh
#编写脚本
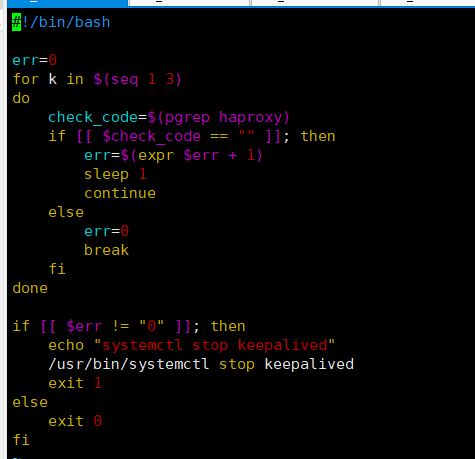
cat > /etc/keepalived/sh/check_apiserver.sh <<EOF
#!/bin/bash
err=0
for k in \$(seq 1 3)
do
check_code=\$(pgrep haproxy)
if [[ \$check_code == "" ]]; then
err=\$(expr \$err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ \$err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
EOF
#赋予执行权限
chmod +x /etc/keepalived/sh/check_apiserver.sh
3.安装kube-controller-manager
以下操作所有master节点操作,既master节点安装kube-controller-manager组件
#回到家目录
cd ~
#生成servive文件
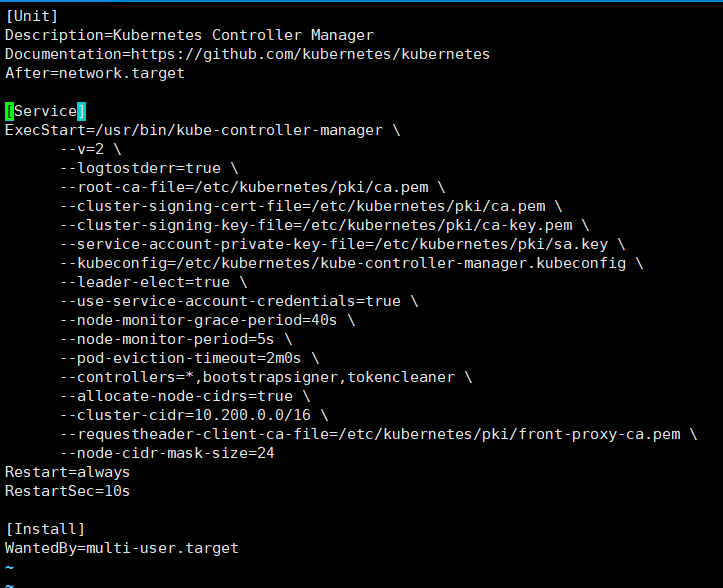
cat > /etc/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-controller-manager \\
--v=2 \\
--logtostderr=true \\
--root-ca-file=/etc/kubernetes/pki/ca.pem \\
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \\
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \\
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \\
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\
--leader-elect=true \\
--use-service-account-credentials=true \\
--node-monitor-grace-period=40s \\
--node-monitor-period=5s \\
--pod-eviction-timeout=2m0s \\
--controllers=*,bootstrapsigner,tokencleaner \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.200.0.0/16 \\
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \\
--node-cidr-mask-size=24
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF
#启动kube-cotroller-manager服务
systemctl enable --now kube-controller-manager.service
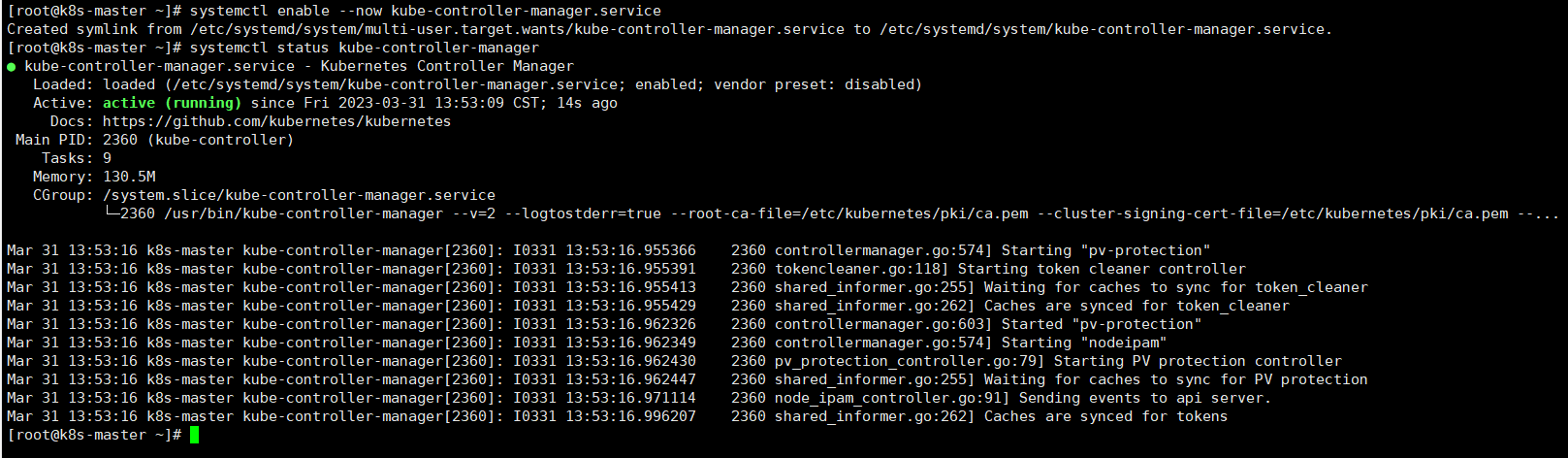
4.安装kube-scheduler
以下操作为所有master节点执行,既master节点安装kube-scheduler组件
#生成service文件
cat > /etc/systemd/system/kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-scheduler \
--v=2 \
--logtostderr=true \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF
#启动服务
systemctl enable --now kube-scheduler.service
#在k8s-master节点上配置kubelet工具,所有master节点操作,否则无法执行部分kubectl命令
#拷贝admin.kubeconfig为~/.kube/config
mkdir /root/.kube/ -p
#复制,注意这个文件是第四章节<生成集群证书并分发>内第三节<创建kubernetes集群证书>内的第六小节<生成集群管理员证书>创建的
cp /etc/kubernetes/admin.kubeconfig /root/.kube/config
#验证集群状态,以下显示信息表示master节点的所有组件正常
kubectl get cs
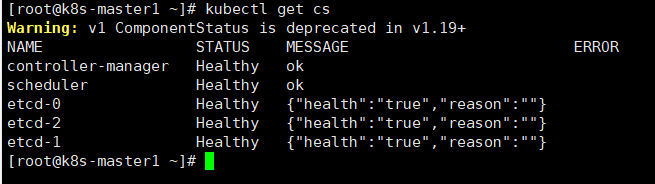
5.安装kubelet
kubelet需要安装到kubernetes集群内所有master与node节点上
5.1生成配置文件
以下操作在k8s-master节点执行,在master节点一上操作获取到文件后,发送到别的服务器
#创建目录
mkdir -p /opt/pki/kubernetes/kubelet
#切换目录
cd /opt/pki/kubernetes/kubelet
#生成随机认证key
a=`head -c 16 /dev/urandom | od -An -t x | tr -d ' ' | head -c6`
b=`head -c 16 /dev/urandom | od -An -t x | tr -d ' ' | head -c16`
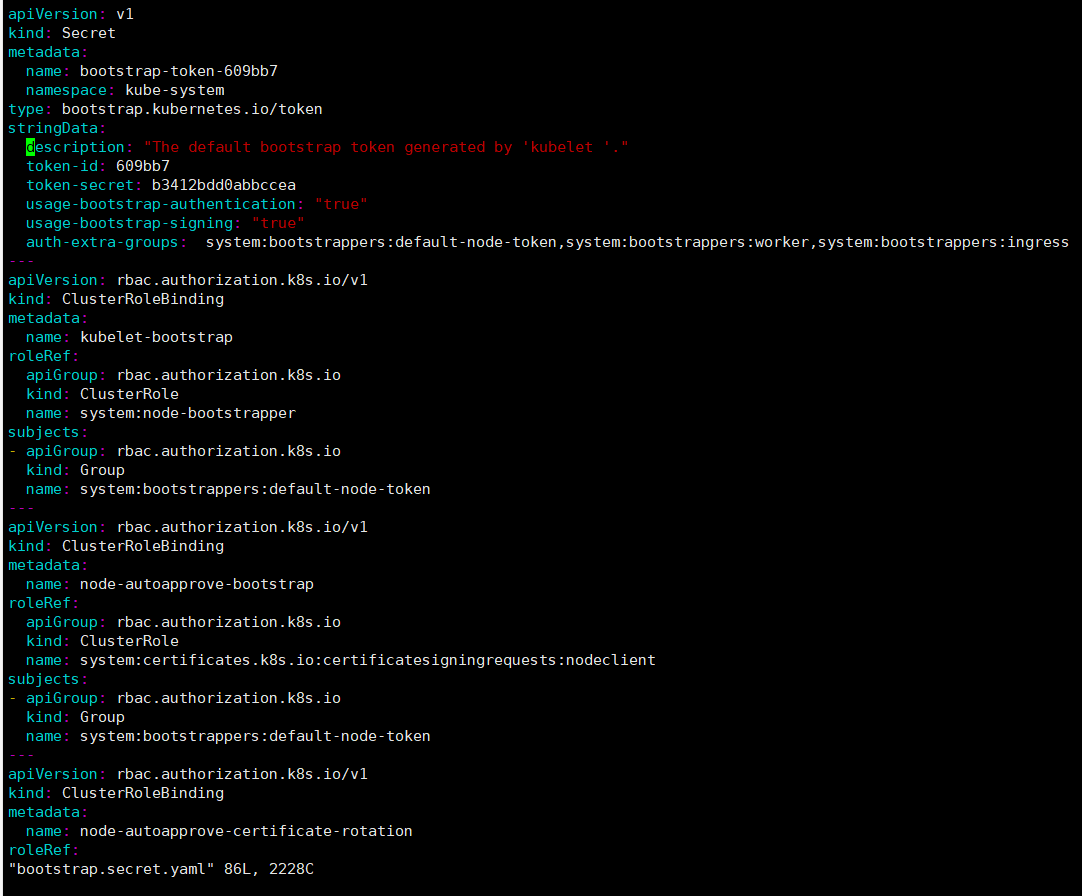
#生成权限绑定文件
cat > bootstrap.secret.yaml <<EOF
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-$a
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
description: "The default bootstrap token generated by 'kubelet '."
token-id: "$a"
token-secret: $b
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token,system:bootstrappers:worker,system:bootstrappers:ingress
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:node-bootstrapper
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:nodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-certificate-rotation
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:nodes
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kube-apiserver
EOF
#生成配置文件,注意--server后的IP为我们的虚拟IP即VIP
kubectl config set-cluster kubernetes \
--certificate-authority=../ca/ca.pem \
--embed-certs=true \
--server=https://10.0.13.110:8443 \
--kubeconfig=bootstrap-kubelet.kubeconfig
#---------
kubectl config set-credentials tls-bootstrap-token-user \
--token=$a.$b \
--kubeconfig=bootstrap-kubelet.kubeconfig
#---------
kubectl config set-context tls-bootstrap-token-user@kubernetes \
--cluster=kubernetes \
--user=tls-bootstrap-token-user \
--kubeconfig=bootstrap-kubelet.kubeconfig
#---------
kubectl config use-context tls-bootstrap-token-user@kubernetes \
--kubeconfig=bootstrap-kubelet.kubeconfig
#根据刚刚编写的yaml进行创建
kubectl apply -f bootstrap.secret.yaml
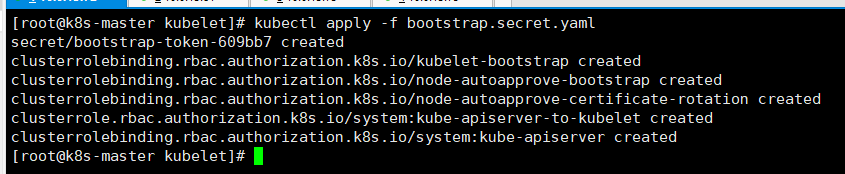
#拷贝配置文件到所有master节点和node节点
all="10.0.13.72 10.0.13.81 10.0.13.73 10.0.13.75"
#发送
for i in $all;do scp /opt/pki/kubernetes/kubelet/bootstrap-kubelet.kubeconfig $i:/etc/kubernetes;done

5.2启动服务(以container为runtime)
要与文章三《安装Runtime组件》对应,区分使用docker与使用container作为runtime的配置操作
执行以下操作保证bootstrap-kubelet.kubeconfig已经分发到所有节点的/etc/kubernetes下
以下操作kubernetes集群内所有master节点和node节点依次执行
#定义变量,ens192是我网卡的名称,根据实际情况进行修改,最终目的就是获取本机IP,也可以直接定义为本机IP如 name=10.0.13.72,定义完成可以echo $name检查一下
name=`ip a | grep ens192 | grep inet | awk 'NR==1 {print $2}' | awk -F'/' '{print $1}'`
echo $name
hostname=`hostname`
kubernetes_ssl_dir="/etc/kubernetes/pki"
#编辑配置
cat > /etc/kubernetes/kubelet.conf << EOF
KUBELET_OPTS="--hostname-override=${hostname} \\
--container-runtime=remote \\
--container-runtime-endpoint=unix:///run/containerd/containerd.sock \\
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.kubeconfig \\
--config=/etc/kubernetes/kubelet-config.yml \\
--cert-dir=${kubernetes_ssl_dir} "
EOF

#生成kubelet-config.yml文件
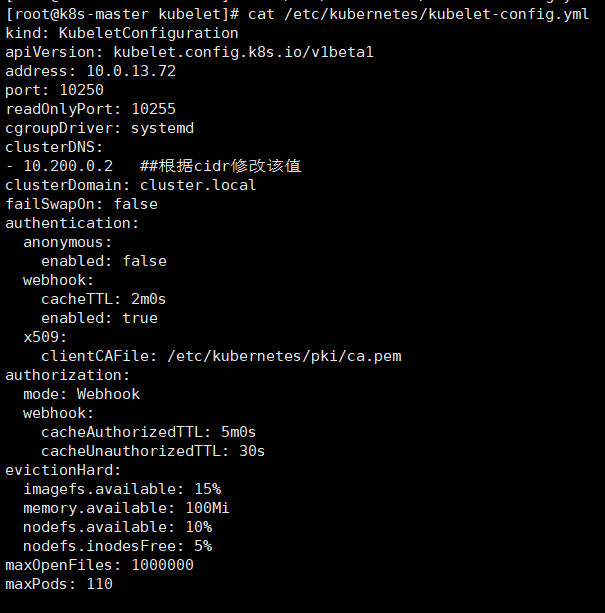
cat > /etc/kubernetes/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: ${name}
port: 10250
readOnlyPort: 10255
cgroupDriver: systemd
clusterDNS:
- 10.200.0.2 ##根据cidr修改该值
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: ${kubernetes_ssl_dir}/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
#生成service文件
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/etc/kubernetes/kubelet.conf
ExecStart=/usr/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF

#使修改生效
systemctl daemon-reload
#启动服务
systemctl enable --now kubelet
#查看node节点状态,container与docker不同,状态会显示Ready
kubectl get nodes

5.3启动服务(以docker为runtime)
要与文章三《安装Runtime组件》对应,区分使用docker与使用container作为runtime的配置操作
执行以下操作保证bootstrap-kubelet.kubeconfig已经分发到所有节点的/etc/kubernetes下
以下操作kubernetes集群内所有master节点和node节点依次执行
#定义变量,ens192是我网卡的名称,根据实际情况进行修改,最终目的就是获取本机IP,也可以直接定义为本机IP如 name=10.0.13.72,定义完成可以echo $name检查一下
name=`ip a | grep ens192 | grep inet | awk 'NR==1 {print $2}' | awk -F'/' '{print $1}'`
echo $name
hostname=`hostname`
kubernetes_ssl_dir="/etc/kubernetes/pki"
#编辑配置
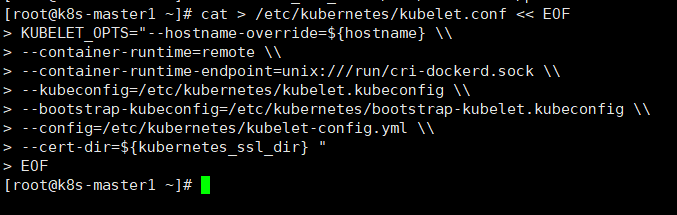
cat > /etc/kubernetes/kubelet.conf << EOF
KUBELET_OPTS="--hostname-override=${hostname} \\
--container-runtime=remote \\
--container-runtime-endpoint=unix:///run/cri-dockerd.sock \\
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.kubeconfig \\
--config=/etc/kubernetes/kubelet-config.yml \\
--cert-dir=${kubernetes_ssl_dir} "
EOF
#生成kubelet-config.yml文件
cat > /etc/kubernetes/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: ${name}
port: 10250
readOnlyPort: 10255
cgroupDriver: systemd
clusterDNS:
- 10.200.0.2 ##根据cidr修改该值
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: ${kubernetes_ssl_dir}/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF

#生成service文件
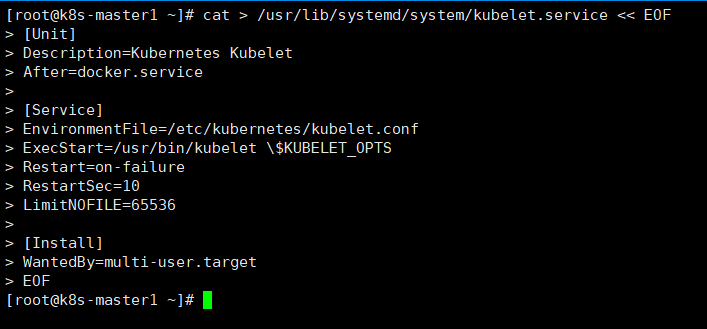
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/etc/kubernetes/kubelet.conf
ExecStart=/usr/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
#使修改生效
systemctl daemon-reload
#启动服务
systemctl enable --now kubelet
#查看node节点状态,会显示NotReady,先查看节点是否都有,部署好网络插件后再进行查看状态
kubectl get node
6.安装kube-proxy
kube-proxy需要安装到kubernetes集群内所有master与node节点上
6.1生成配置文件
以下操作在k8s-master节点执行**,在master节点一上操作**获取到文件后,发送到别的服务器
#创建目录
mkdir /opt/pki/kubernetes/kube-proxy/
#切换目录
cd /opt/pki/kubernetes/kube-proxy/
#生成配置文件
kubectl -n kube-system create serviceaccount kube-proxy
kubectl create clusterrolebinding system:kube-proxy --clusterrole system:node-proxier --serviceaccount kube-system:kube-proxy
#生成kube-proxy-scret.yml文件
cat > kube-proxy-scret.yml << EOF
apiVersion: v1
kind: Secret
metadata:
name: kube-proxy
namespace: kube-system
annotations:
kubernetes.io/service-account.name: "kube-proxy"
type: kubernetes.io/service-account-token
EOF

#根据刚刚创建的yml文件创建对应的secret
kubectl apply -f kube-proxy-scret.yml

#定义token变量
JWT_TOKEN=$(kubectl -n kube-system get secret/kube-proxy \
--output=jsonpath='{.data.token}' | base64 -d)
#使用kubectl命令进行配置,以下10.0.13.110为虚拟IP,根据实际情况进行配置
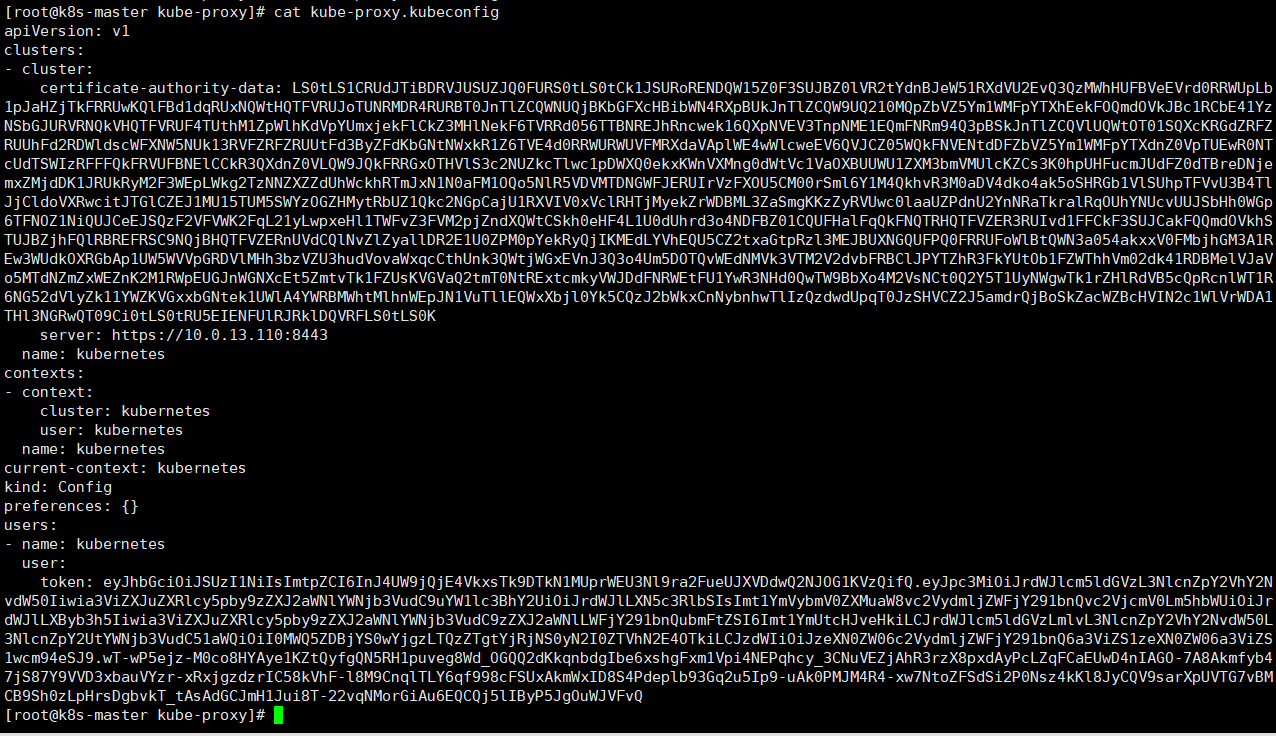
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=https://10.0.13.110:8443 \
--kubeconfig=kube-proxy.kubeconfig
#--------------------------------------
kubectl config set-credentials kubernetes \
--token=${JWT_TOKEN} \
--kubeconfig=kube-proxy.kubeconfig
#--------------------------------------
kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=kubernetes \
--kubeconfig=kube-proxy.kubeconfig
#--------------------------------------
kubectl config use-context kubernetes \
--kubeconfig=kube-proxy.kubeconfig
#查看输出的配置文件
cat kube-proxy.kubeconfig
#拷贝配置文件到所有节点
all="10.0.13.72 10.0.13.81 10.0.13.73 10.0.13.75"
#分发配置
for i in $all;do
scp /opt/pki/kubernetes/kube-proxy/kube-proxy.kubeconfig $i:/etc/kubernetes
done

6.2启动服务
执行以下操作保证kube-proxy.kubeconfig已经分发到所有节点的/etc/kubernetes下
以下操作kubernetes集群内所有master节点和node节点依次执行
#生成service文件
cat > /etc/systemd/system/kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Kube Proxy
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-proxy \
--config=/etc/kubernetes/kube-proxy.conf \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
EOF
以下操作注意所有节点依次执行
#定义变量,ens192是我网卡的名称,根据实际情况进行修改,最终目的就是获取本机IP,也可以直接定义为本机IP如 name=10.0.13.72,定义完成可以echo $a检查一下
a=`ip a | grep ens192 | grep inet | awk 'NR==1 {print $2}' | awk -F'/' '{print $1}'`
echo $a
#编辑配置
cat > /etc/kubernetes/kube-proxy.conf <<EOF
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: $a
clientConnection:
acceptContentTypes: ""
burst: 10
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
qps: 5
clusterCIDR: 10.100.0.0/16
configSyncPeriod: 15m0s
conntrack:
max: null
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
enableProfiling: false
healthzBindAddress: 0.0.0.0:10256
hostnameOverride: "$a"
iptables:
masqueradeAll: false
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s
ipvs:
masqueradeAll: true
minSyncPeriod: 5s
scheduler: "rr"
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:10249
mode: "ipvs"
nodePortAddresses: null
oomScoreAdj: -999
portRange: ""
udpIdleTimeout: 250ms
EOF
#使service文件生效
systemctl daemon-reload
#启动服务
systemctl enable --now kube-proxy.service
#给集群节点打标签
kubectl label nodes k8s-master1 node-role.kubernetes.io/master=master01
kubectl label nodes k8s-master2 node-role.kubernetes.io/master=master02
kubectl label nodes k8s-node1 node-role.kubernetes.io/node=node01
kubectl label nodes k8s-node2 node-role.kubernetes.io/node=node02
#查看节点role及lables信息
kubectl get nodes --show-labels

7.安装网络插件
可选择部署calico或cilium充当网络插件
对比分析:
Calico Cilium都支持Ovelay网络
- 好处:不受底层物理网络结构的约束,有更大的自由度,更好的易用性。
- 坏处:Overlay网络因需要封包解包操作,因此在MTU参数相同的情况,数据包信息密度较小,且额外的隧道封装会导致传输性能下降。
Calico Cilium都支持路由模式
- 好处:因直接使用路由表传输,因此不存在上述隧道封装的各种问题。
- 坏处:依赖底层网络。在跨网段网络环境中,需要中间的路由设备也支持BGP协议。
Calico Cilium都支持kubernetes network policy
Calico Cilium都支持eBPF,不同点:
- 架构、粒度不同,例如:Cilium eBPF支持7层协议过滤。
- Cilium配置了Hubble分布式网络观测平台,Calico没有。
结论:
Calico和Cilium都可为kubernetes提供基础网络功能。但二者略有不同:
- Calico侧重点在于提供一个通用的跨平台/跨应用的通用网络解决方案。
- Cilimu侧重点在于依托eBPF特性,提供用于透明保护容器应用之间网络连接的网络方案。
网络性能方面,eBPF的优势在于,允许绕过主机命名空间中的所有 iptables 和上层堆栈开销,以及遍历虚拟以太网对时的一些上下文切换开销。
根据个人需求安装需要的网络插件,7.1与7.2选择一个部署即可
7.1安装calico为网络插件
7.1.1升级libseccomp
CentOS7要升级libseccomp,不然无法安装网络组件,所有节点进行升级
#升级runc
wget https://ghproxy.com/https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
#安装
install -m 755 runc.amd64 /usr/local/sbin/runc
#复制命令到指定文件夹
cp -p /usr/local/sbin/runc /usr/local/bin/runc
cp -p /usr/local/sbin/runc /usr/bin/runc
#下载高于2.4以上的包
yum -y install http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
#查看当前版本
rpm -qa | grep libseccomp

7.1.2安装calico
以下操作在master节点操作
首先访问https://github.com/projectcalico/calico/blob/v3.24.5/manifests/calico.yaml
将配置文件复制出来,并到master节点任意目录内创建calico.yaml文件,将内容粘贴进去
也可以通过以下链接直接下载我下载好的calico.yaml文件
链接:https://pan.baidu.com/s/1M_NaTbzBm6azNp5J3qF39w?pwd=zska
提取码:zska
#编辑配置文件
vim calico.yaml
#找到以下行将其改为以下行,value根据自己的cidr进行配置
- name: CALICO_IPV4POOL_CIDR
value: "10.100.0.0/16"
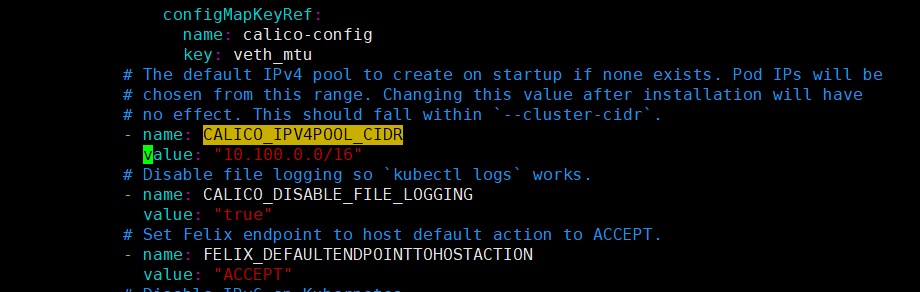
编辑好yaml文件即可开始创建对应的资源,在创建前,我们先将需要用的的容器手动导入进去,不然创建后可能由于镜像一直拉取不到卡在那里,通过以下链接下载对应的镜像包
所需镜像:
docker.io/calico/cni:v3.24.5
docker.io/calico/node:v3.24.5
docker.io/calico/kube-controllers:v3.24.5
以下<7.1.2.1>与<7.1.2.2>根据自己使用的runtime进行选择,要与第三章节<安装Runtime组件>对应
7.1.2.1使用containerd为runtime安装
如果使用containerd当作runtime需要对containerd进行配置,修改创建pod时所需要的pause容器拉取地址,否则无法创建任何pod
以下操作集群内所有master及node节点执行
#编辑containerd配置
vim /etc/containerd/config.toml
#检索pause,将以下配置
sandbox_image = "k8s.gcr.io/pause:3.6"
#改为
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6"

#保存退出后,重启containerd服务
systemctl restart containerd
将calico-image.zip下载并上传至所有master与node节点上
以Containerd为runtime下载地址(calico-image.zip):
链接:https://pan.baidu.com/s/1IQcMv5cQN4j2Jhqk_692QA?pwd=zska
提取码:zska

以下操作集群内所有master及node节点执行
#解压镜像压缩包
unzip calico-image.zip
#切换目录
cd calico_img/
#导入镜像
ctr i import cni-3.24.5.img
ctr i import node-3.24.5.img
ctr i import kube-controllers-3.24.5.img
#查看镜像是否导入成功
ctr i ls

安装calico,在配置了calico.yaml文件的master节点执行
#根据calico.yaml配置创建对应的资源
kubectl apply -f calico.yaml
#等待大概2~5分钟查看pod运行情况
kubectl get po -A -o wide

7.1.2.2使用docker为runtime安装
当您的runtime选择的是docker与cri-docker,根据以下链接下载对应的镜像压缩包并上传至所有master与node节点上
以Docker为runtime下载地址(calico-docker.tar.gz):
链接:https://pan.baidu.com/s/1pcgJteLGmDK5p-58jHg73w?pwd=zska
提取码:zska
以下操作集群内所有master及node节点执行
#解压镜像包
tar -zxvf calico-docker.tar.gz
#导入镜像
docker load -i cni-3.24.5.tar
docker load -i kube-controllers-3.24.5.tar
docker load -i node-3.24.5.tar
#查看镜像
docker images

以下操作在配置了calico.yaml文件的master节点执行
#k8s-master主节点更改配置文件内镜像名称
sed -i 's#docker.io/calico/cni:v3.24.5#calico/cni:v3.24.5#g' calico.yaml
sed -i 's#docker.io/calico/kube-controllers:v3.24.5#calico/kube-controllers:v3.24.5#g' calico.yaml
sed -i 's#docker.io/calico/node:v3.24.5#calico/node:v3.24.5#g' calico.yaml
#查看是否更改成功
cat calico.yaml | grep -w image

#根据yaml文件创建指定资源
kubectl apply -f calico.yaml
#等待两分钟,查看资源部署是否成功
kubectl get po -n kube-system
#这个时候可以查看node是否为ready状态
kubectl get node

7.2安装cilium为网络插件
Cilium 是一个用于容器网络领域的开源项目,主要是面向容器而使用,用于提供并透明地保护应用程序工作负载(如应用程序容器或进程)之间的网络连接和负载均衡。
7.2.1升级libseccomp
CentOS7要升级libseccomp,不然无法安装网络组件,所有节点进行升级
#升级runc
wget https://ghproxy.com/https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
#安装
install -m 755 runc.amd64 /usr/local/sbin/runc
#复制命令到指定文件夹
cp -p /usr/local/sbin/runc /usr/local/bin/runc
cp -p /usr/local/sbin/runc /usr/bin/runc
#下载高于2.4以上的包
yum -y install http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
#查看当前版本
rpm -qa | grep libseccomp
注意!!!
如果使用containerd当作runtime需要对containerd进行配置,修改创建pod时所需要的pause容器拉取地址,否则无法创建任何pod
以下操作集群内所有master及node节点执行
#编辑containerd配置
vim /etc/containerd/config.toml
#检索pause,将以下配置
sandbox_image = "k8s.gcr.io/pause:3.6"
#改为
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6"
#保存退出后,重启containerd服务
systemctl restart containerd
7.2.2安装helm
Helm是 Kubernetes 的包管理器。包管理器类似于我们在 Ubuntu 中使用的apt、Centos中使用的yum 或者Python中的 pip 一样,能快速查找、下载和安装软件包。
可选择直接安装,或根据本文档第一章节《部署说明》内的第二小节“资源包下载”,下载helm-canary-linux-amd64.tar.gz至kube-master1服务器上
以下操作master1节点执行
#下载安装包
wget https://get.helm.sh/helm-canary-linux-amd64.tar.gz
#解压安装包
tar xvf helm-canary-linux-amd64.tar.gz
#复制命令到全局配置
cp linux-amd64/helm /usr/local/bin/
#测试是否可以使用
helm version

7.2.3安装cilium
使用刚刚安装的helm进行cilium的安装
#添加helm源
helm repo add cilium https://helm.cilium.io
#安装到kube-system命名空间内
helm install cilium cilium/cilium --namespace kube-system --set hubble.relay.enabled=true --set hubble.ui.enabled=true --set prometheus.enabled=true --set operator.prometheus.enabled=true --set hubble.enabled=true --set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,http}" --set ipv6.enabled=true
#参数介绍
#启用ipv6增加参数
# --set ipv6.enabled=true
#启用路由信息和监控插件增加参数
# --set hubble.relay.enabled=true --set hubble.ui.enabled=true --set prometheus.enabled=true --set operator.prometheus.enabled=true --set hubble.enabled=true --set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,http}"
#等待两分钟,查看安装是否完成
kubectl get pod -A | grep cil

7.2.4安装专属监控面板
以下操作在kube-master1节点执行
#下载对应的yaml文件,链接超时就多下几次
wget https://raw.githubusercontent.com/cilium/cilium/1.12.1/examples/kubernetes/addons/prometheus/monitoring-example.yaml --no-check-certificate
#根据yaml文件部署对应的资源
kubectl apply -f monitoring-example.yaml
#等待三分钟,查看pod运行状态,镜像没拉下来就删除再建多试几次,一直拉不下来就把镜像手动拉到分配节点上
kubectl get po -n cilium-monitoring

7.2.5下载部署测试用例
以下操作在kube-master1节点执行
#下载yaml文件,下载失败请尝试多次
wget https://raw.githubusercontent.com/cilium/cilium/master/examples/kubernetes/connectivity-check/connectivity-check.yaml
#修改yaml文件
sed -i "s#google.com#oiox.cn#g" connectivity-check.yaml
#删除最下方的CiliumNetworkPolicy资源,因为它存在,所建立的pod一直无法访问外网
#使用/检索pod-to-external-fqdn-allow-google-cnp,找到文件最下方如图配置,将其全部删除
删除后为如图
#根据yaml文件创建对应资源
kubectl apply -f connectivity-check.yaml
#查看对应资源运行情况
kubectl get po

7.2.6修改svc策略
以下操作在kube-master1节点执行
#修改svc策略为NodePort,检索type将ClusterIP改为NodePort
kubectl edit svc -n kube-system hubble-ui
kubectl edit svc -n cilium-monitoring grafana
kubectl edit svc -n cilium-monitoring prometheus
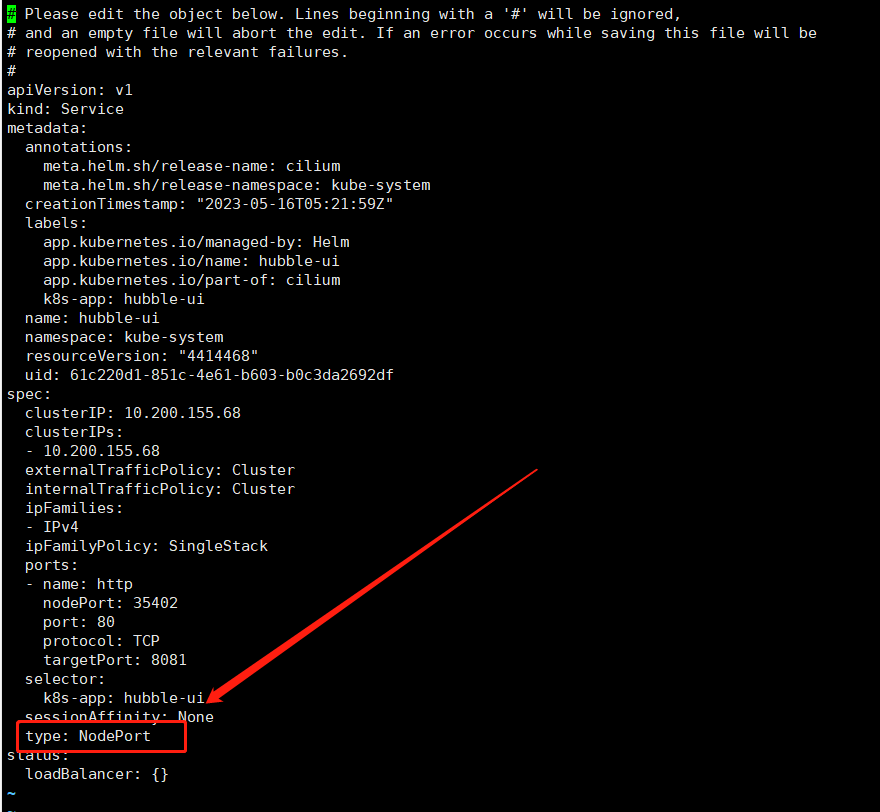
#查看更改是否生效
kubectl get svc -n kube-system

#查看更改是否生效
kubectl get svc -n cilium-monitoring

7.2.7访问测试
根据svc策略所映射的端口得到以下地址,根据自己分配的访问,我的与你不同,IP为之前绑定的VIP
hubble-ui:
10.0.13.110:35402
浏览器访问
grafana:
10.0.13.110:35835
prometheus:
10.0.13.110:34632
8.安装coredns
CoreDNS 是一种现代化的 DNS 服务器,被设计成可以与容器(如Linux和Docker容器)化环境良好地结合,尤其是在非常流行的容器编排系统Kubernetes管理的环境中。
以下操作kube-master1节点操作
#原配置文件下载地址,进入后将配置复制粘贴
https://github.com/coredns/deployment/blob/master/kubernetes/coredns.yaml.sed
#编辑配置文件
vim coredns.yaml
#更改项1 - 将复制过来的配置粘贴进去后,使用/检索Corefile,将配置改为以下
原配置:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes CLUSTER_DOMAIN REVERSE_CIDRS {
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . UPSTREAMNAMESERVER {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}STUBDOMAINS
改为:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { #这里的值要改
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 114.114.114.114 { #改为外部的dns服务器
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
} #多余的字母去掉
#更改项2 - 随后使用/检索clusterIP,更改为自己设置的CIDR网段
原配置:
clusterIP: CLUSTER_DNS_IP
改为:
clusterIP: 10.200.0.2 #我配置的CIDR地址为10.200.0.0所以配置的10.200.0.2,实际则根据自己配置的进行修改
#以上配置更改完毕后保存退出
更改项1:
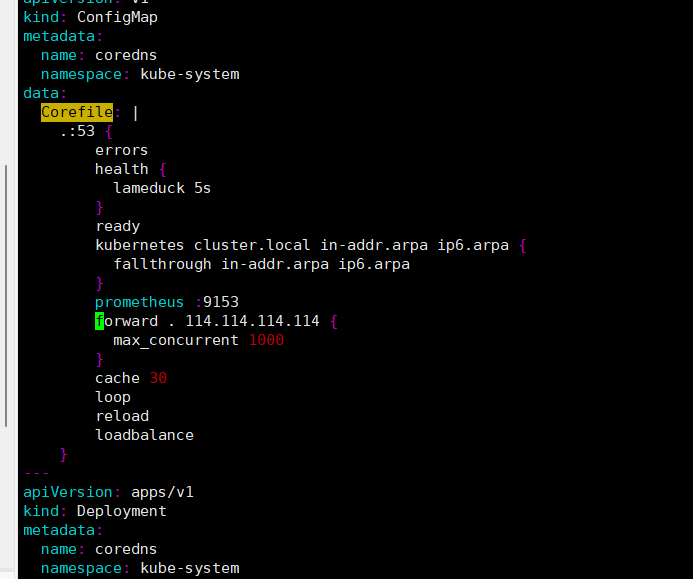
更改项2:

回到kube-master1节点
#根据刚刚更改好的配置创建对应资源
kubectl apply -f coredns.yaml
#等待一分钟,查看创建情况
kubectl get pod -A | grep core

9.安装Metrics Server
Metrics Server是kubernetes集群核心监控数据的聚合器,可以通过Metrics API的形式获取Metrics数据,不过仅仅是获取指标的最新值,不对旧值进行存储,且不负责将指标转发到第三方目标。Metrics Server 还可以与 Kubectl 工具结合使用,提供 kubectl top 命令来展示集群中的指标数据;
在kubernetesV1.11版本前使用的是Heapster来收集节点上的指标数据,例如cpu、memory、network和dist的Metric数据。
以下操作在k8s-master1节点执行
#下载对应的yaml文件,超时请尝试多次
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
#更改配置
vim components.yaml
#更改镜像地址,否则拉不到外网镜像
sed -i "s#k8s.gcr.io/metrics-server/metrics-server:v0.6.1#registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.1#g" components.yaml
#查看更改是否生效
cat components.yaml | grep -w image

#使用/检索containers,找到'containers:',在args下新增几个参数
#修改前
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
#修改后
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem
- --requestheader-username-headers=X-Remote-User
- --requestheader-group-headers=X-Remote-Group
- --requestheader-extra-headers-prefix=X-Remote-Extra-
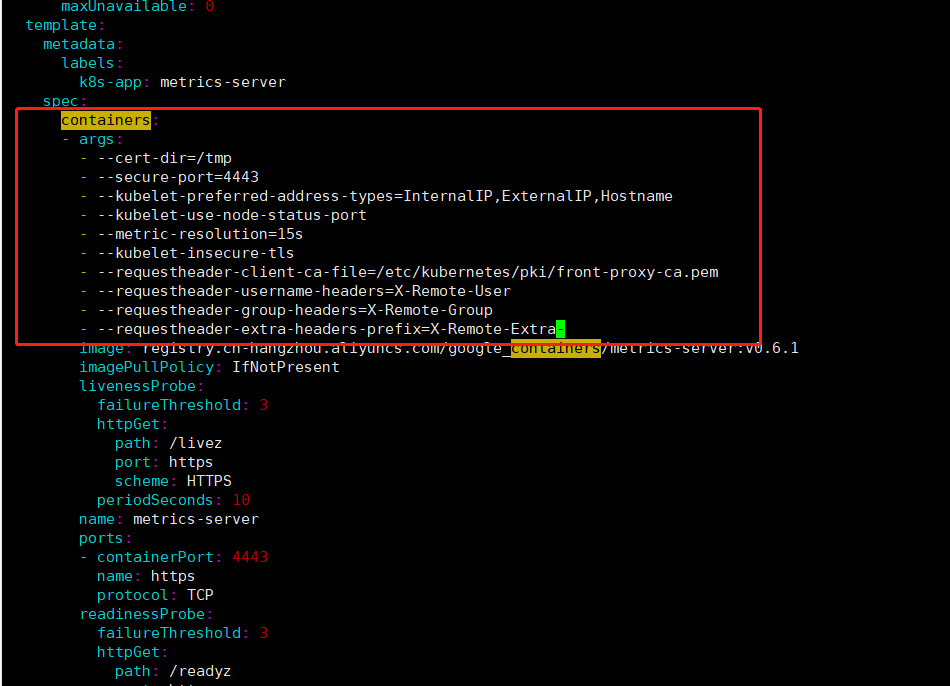
#使用/检索volumeMounts,找到volumeMounts:,添加一个挂载目录
#修改前
volumeMounts:
- mountPath: /tmp
name: tmp-dir
#修改后
volumeMounts:
- mountPath: /tmp
name: tmp-dir
- mountPath: /etc/kubernetes/pki
name: ca-ssl
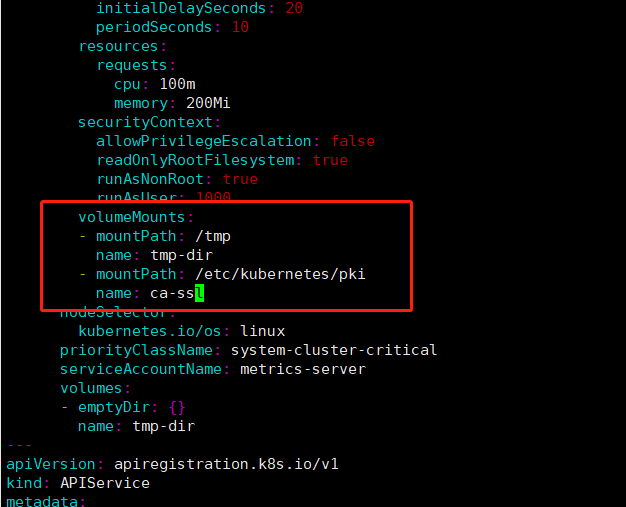
#使用/检索volumes,找到volumes:,添加挂载目录
#修改前
volumes:
- emptyDir: {}
name: tmp-dir
#修改后
volumes:
- emptyDir: {}
name: tmp-dir
- name: ca-ssl
hostPath:
path: /etc/kubernetes/pki
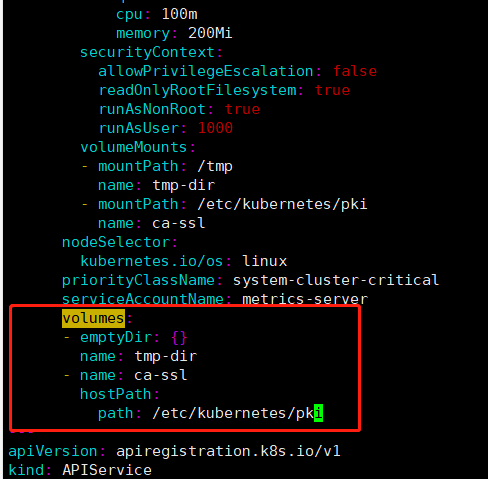
#根据yaml文件创建对应的资源
kubectl apply -f components.yaml
#获取节点资源信息,测试metrics-server可用性
kubectl top nodes

七、集群验证(扩展)
在kubernetes集群部署完毕后,我们对其进行些简单的测试
7.1部署pod资源测试
以下操作k8s-master1节点执行
#编写yaml文件
cat >> busybox.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: docker.io/library/busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
EOF
#创建
kubectl apply -f busybox.yaml
#检查pod的运行情况
kubectl get po -o wide | grep busybox
#若出现镜像拉取失败的情况,请在每台手动拉取docker.io/library/busybox:1.28的镜像
#docker执行 docker pull docker.io/library/busybox:1.28
#container执行 ctr i pull docker.io/library/busybox:1.28

7.2pod内解析测试
#获取默认空间下kubernetes的IP,如下图我的是10.200.0.1
kubectl get svc | grep kubernetes

#容器内解析测试
kubectl exec busybox -- nslookup kubernetes

#容器内跨命名空间解析测试
kubectl exec busybox -- nslookup kube-dns.kube-system

#每个集群内节点要能访问kubernetes的kubernetes svc 443端口和kube-dns的svc 53端口,以下操作所有节点执行
#若没有telnet命令可yum下载,或离线安装(具体方式网上随便找个文档)
#kubernetes svc
telnet 10.200.0.1 443
#kube-dns svc
telnet 10.200.0.2 53
#kube-dns svc
curl 10.200.0.2 53

#pod与pod之间ping测试,使用以下命令获取一个除了我们刚刚创建的busybox的podip
kubectl get po -n kube-system -o wide
#进入busybox进行ping其他pod的操作
kubectl exec -it busybox -- sh
#ping其他的pod,我其他的podip选择的是10.0.0.134,请根据自己的podip进行修改
ping 10.0.0.134

7.3资源调度测试
以下操作在k8s-master1节点执行
#编写一个测试用例使用deployment对象进行创建4个实例,查看是否会落在不同的节点上,测试没问题后可以删除
cat > deployments.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/library/nginx:1.14.2
ports:
- containerPort: 80
EOF
#根据yaml文件进行deployment的创建
kubectl apply -f deployments.yaml
#若出现ErrImagePull的情况,请在各节点上手动拉取镜像后,在重新创建对象
#以docker为runtime执行:
#docker pull docker.io/library/nginx:1.14.2
#以containerd为runtime执行:
#ctr i pull docker.io/library/nginx:1.14.2

#如上图创建没什么问题,可以对deployment资源进行删除
kubectl delete -f deployments.yaml
八、安装dashboard(扩展)
Dashboard是基于网页的Kubernetes用户界面。您可以使用Dashboard将容器应用部署到Kubernetes集群中,也可以对容器应用排错,还能管理集群资源。您可以使用Dashboard获取运行在集群中的应用的概览信息,也可以创建或者修改Kubernetes资源( 如Deployment,Job,DaemonSet等等)
Dashboard同时展示了Kubernetes集群中的资源状态信息和所有报错信息
以下操作在k8s-master1节点执行
#获取对应的yaml文件,下载超时多次尝试即可
wget https://raw.githubusercontent.com/cby-chen/Kubernetes/main/yaml/dashboard.yaml
wget https://raw.githubusercontent.com/cby-chen/Kubernetes/main/yaml/dashboard-user.yaml
#更改拉取的镜像地址
sed -i "s#kubernetesui/dashboard#registry.cn-hangzhou.aliyuncs.com/google_containers/dashboard#g" dashboard.yaml
sed -i "s#kubernetesui/metrics-scraper#registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-scraper#g" dashboard.yaml
#根据yaml文件创建资源
kubectl apply -f dashboard.yaml
kubectl apply -f dashboard-user.yaml
#更改dashboard的svc策略为Nodeport
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
#使用/检索type,找到 type: ClusterIP
#修改前:
type: ClusterIP
#修改后:
type: NodePort
#查看端口号
kubectl get svc -n kubernetes-dashboard

#创建token,登录使用,注意保存
kubectl -n kubernetes-dashboard create token admin-user
#我获取到的token
eyJhbGciOiJSUzI1NiIsImtpZCI6ImNJQTJNS2VkYnl3Z0lYdGFmaXprMUJMamhxSEJCdkI1Z0ZNSjV4UEdDa00ifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjg0NDc2ODE5LCJpYXQiOjE2ODQ0NzMyMTksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiN2ExYjc1ZmItMjgzNy00ZDgyLWFmYjAtMDQ4Y2I2MWI2NDAyIn19LCJuYmYiOjE2ODQ0NzMyMTksInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.Rdu4Um1yzM1AWejMwXsP1J1YTkWrg_L1FHIU4k6u3KNxHwF6eKxoX6LK9MCEOPjxtOa9tHhoxqw23qSnNvFBREeEBkRAuOrD5l34Pe0FflgEWW9pgWdZA13U3sVyc87nHyJE_2Jv1_a0DxY1r8NlsYmm5iR7kBaGB4pPCdk9yjnFX9nxxir4nCSkCIkzN7NS55vRt8ezf7PUDf8g3r3gsFCZOg_t70r2wYbAyY3OwMvXzBjGlmQaTxMYc9t3IZOb6NxzJGkxQxrR2iPfW9BSia0XxaIrYrQJLpwBi3Z1NcgJd2GN5AevSoIpOW3qkviBsAg_DEpN2uQgdh5HKBYY6Q

根据svc映射的端口访问dashboard页面,地址格式为 虚拟IP:svcport
我访问的是
https://10.0.13.110:36026
访问页面—>选择token—>复制粘贴刚刚生成的token—>登录
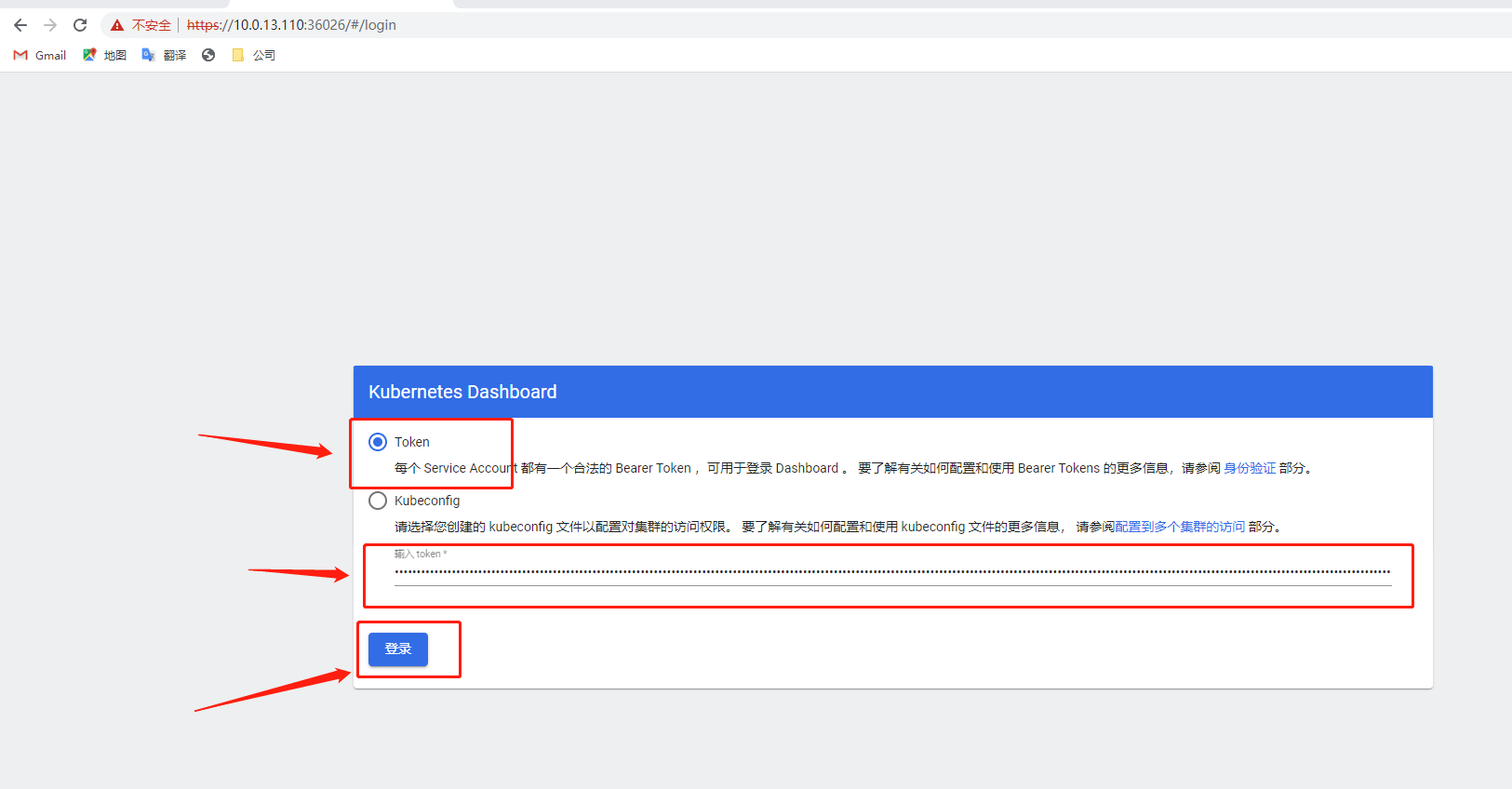
九、安装kubernetes命令补全功能
以下操作所有master节点执行
#下载工具,不可在线安装请将安装包下载后离线安装
yum install bash-completion -y
#使其生效
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
#添加用户变量内
echo "source <(kubectl completion bash)" >> ~/.bashrc
#测试命令补全即可
















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









