






目录
一、注意事项
1、环境背景
注意:此次使用的是CentOS 7 , Hadoop的版本是3.2.4,jdk是jdk-8u351-linux-x64.rpm
2、小小请求
内容有点长,但是步骤十分详细,跟着来一定会成功!!请耐心看完
各位小伙伴们有什么问题可以私信我,如果想要内容里面的软件包的话可以在评论区@我。最后给我点个赞呗(❤)
二、Hadoop的搭建
1、安装及配置虚拟机
1)配置网络
Liux系统的网络配置参数是写在配置文件里的,ifcfg-ens33是CentOS 7版本的Linux系统中的网络配置文件,可以设置P地址、子网码等网络配置信息。
修改/etc/sysconfig/network-scripts/ifcfg-ens33配置文件。将该文件中ONBOOT的值修改为“yes ” ,将BOOTPROTO的值修改为“static ” ,并添加IP地址IPADDR、子网掩码NETMASK、网关GATEWAY以及域名解析服务器DNS1的网络配置信息。
localhost login: root
Password:
[root@localhost ~] vi /etc/sysconf ig/network-scripts/ifcfg-ens33
#这是ifcfg-ens33的文件,需要修改的注释表明
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static #这是第一个修改的地方
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=ba47e21a-c46d-4a38-8eaf-6a6475775a9a
DEVICE=ens33
ONBOOT=yes #第二个
#这四个是需要添加的
IPADDR=192.168.128.130
GATEWAY=192.168.128.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
重启网卡服务
service network restart
查看IP是否已被更改
ip addr

2)下载远程链接器(可选)
Xmanager是应用于Windows系统的Xserver服务器软件,通过Xmanager用户可以将远程的Linux桌面无缝导入至Windows系统中。这个过程可以自行选择,这个只是一个辅助器为了方便操作。
(1)下载Xshell
通过Xmanager官网下载Xmanager安装包,安装包名称为Xme5.exe。
下载安装包后,双击Xme5.exe进入Xmanager安装界面,选择Xmanager的安装位置后即可快速完成Xmanager的安装。
Xmanager官网点击此处
(2)Linux虚拟网络
使用Xmanager连接虚拟机前,需要先设置VMware Workstation的虚拟网络。在VMware的“编辑”菜单中单击“虚拟网络编辑器(N)…”选项。

进入“虚拟网络编辑器”对话框后,需要管理员权限才能修改网络配置。如果没有管理员权限,那么单击“更改设置”按钮,重新进入对话框即可。选择“VMnet8”选项所在行,再将“子网IP(I) ”修改为“192.168.128.0 ” ,单击“确定”按钮关闭该对话框。

(3)准备连接Xshell
打开一下载好的Xshell
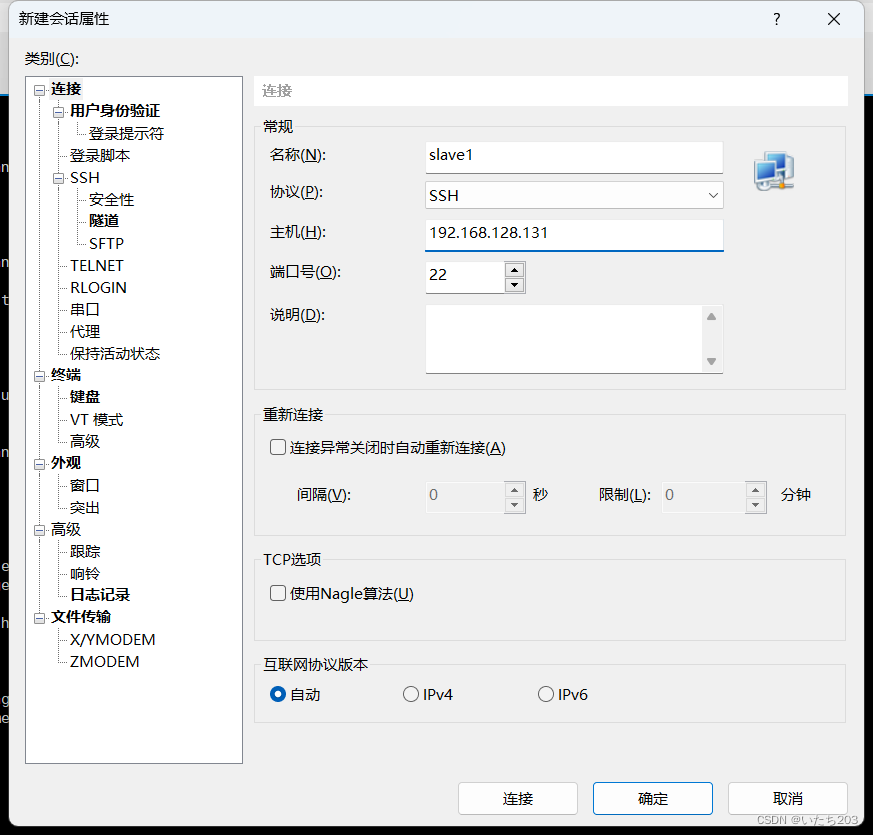
单击“文件”菜单,在出现的菜单栏中选择“新建(N)…”选项,建立会话。


配置新建会话。在弹出的“新建会话属性”对话框中,“名称”对应的文本框中输入“master ” 。该会话名称是由用户自行指定的,建议与要连接的虚拟机主机名称保持一致。“主机(H) ”对应的文本框中输入“192.168.128.130 ” ,表示master虚拟机的IP地址

再单击左侧的“用户身份验证”选项,在右侧输入用户名“root ”和密码 ,如右图,单击“确定”按钮,创建会话完成
最后成果如图所示
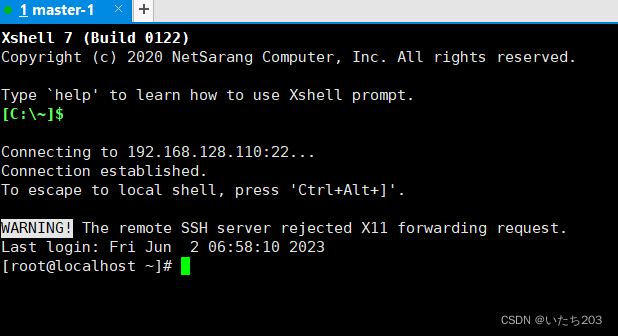
3)修改主机名称
用图中命令修改主机名称后,命令“reboot”重启虚拟机。
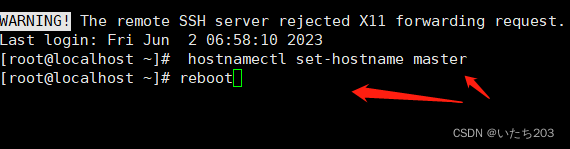
最后结果如图所示

4)使用YUM安装软件
使用命令
yum install -y vim zip openssh-server openssh-clients
以安装vim、zip、openssh-server、openssh-clients
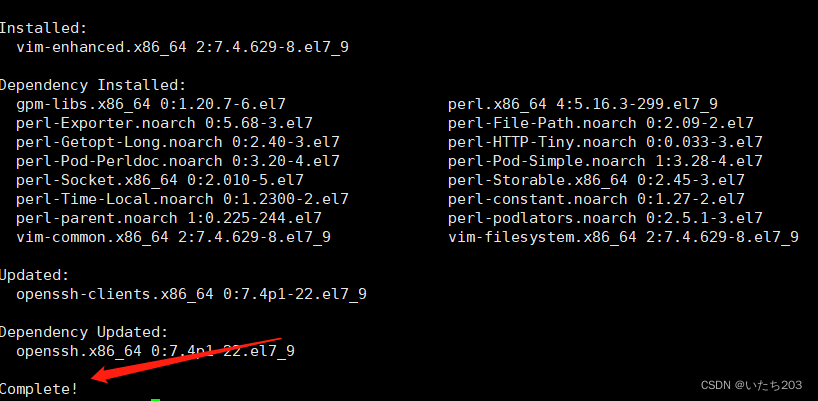
出现**Complete!**表示成功
2、搭建Hadoop集群
1)上传所需安装包
上传JDK安装包至虚拟机master,按“Ctrl+Alt+F ”组合键,进入文件传输的弹窗
在左侧查找到jdk-8u351-linux-x64.rpm和hadoop-3.2.4.tar.gz安装包,右键单击该安装包,选择“传输”命令上传至Linux的/opt目录下。
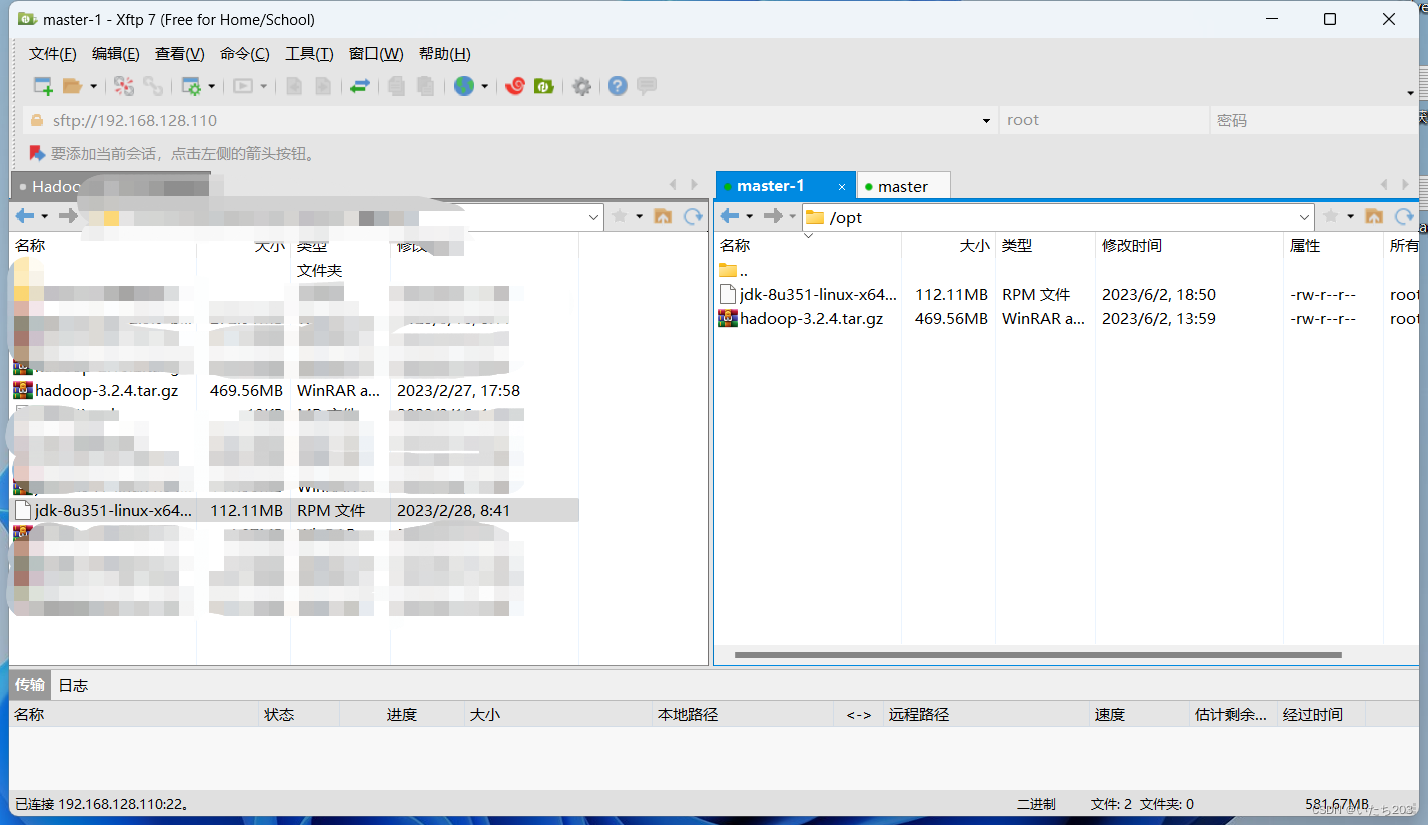
然后进入控制台
进入/opt目录
cd /opt
输入这两个命令分别解压这两个安装包
rpm -ivh jdk-8u281-linux-x64.rpm
tar -zxf hadoop-3.2.4.tar.gz -C /usr/local
安装后的
Java路径在/usr/java/jdk1.8.0_351-amd64
Hadoop路径在/usr/local下
2)下载ntp和chrony
[root@master ~] yum install ntp ntpdate -y #安装时间同步
[root@master ~] ntpdate ntp.aliyun.com
2 Jun 02:16:20 ntpdate[1756]: adjust time server 203.107.6.88 offset 0.001007 sec
ntp就上述步骤和简单,到了chrony就需要下载完修改文件了
[root@master ~] yum install chrony -y
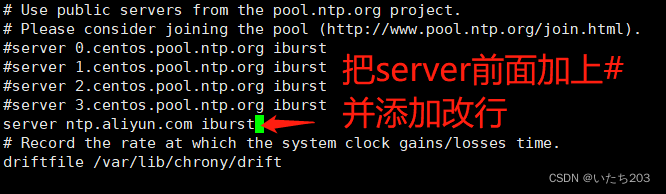
[root@master ~] vi /etc/chrony.conf
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server ntp.aliyun.com iburst #这一行不要添加星号
[root@master ~] systemctl start chronyd
[root@master ~] timedatectl set-ntp true #默认打开ntp
[root@master ~] date
Tue Feb 28 09:00:12 CST 2023
[root@master ~]
3)修改Hadoop文件
进入目录:
cd /usr/local/hadoop-3.2.4/etc/Hadoop/
依次修改下面的文件:
(1)core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
需要添加进去,注意添加的格式,如图:
我们刚打开的文件里面内容是这样的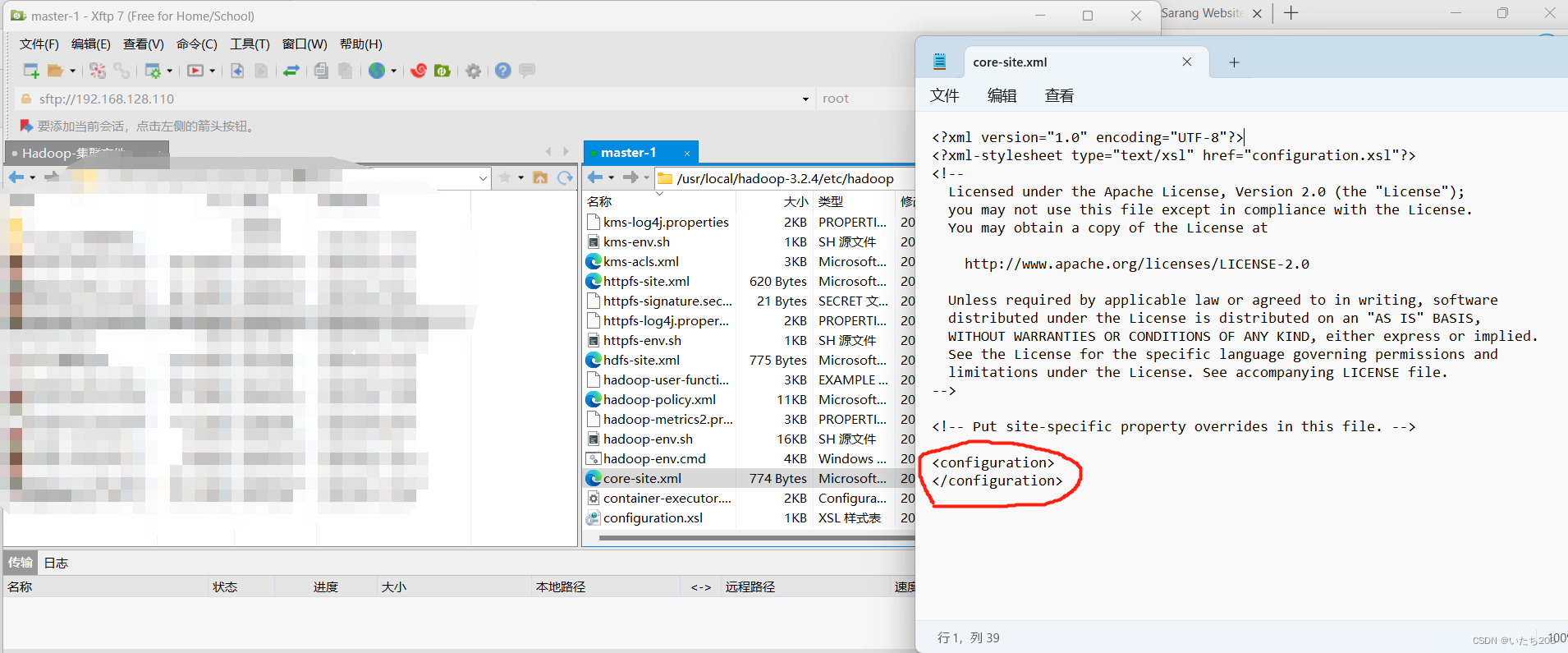
我们要复制好把他插入在此中间,然后保存。
P.S. 用文件操作系统更改文件更为方便,不然还可以在Xshll开启撰写窗口也可以达到目的
<configuration>
</configuration>
最后插入如图所示
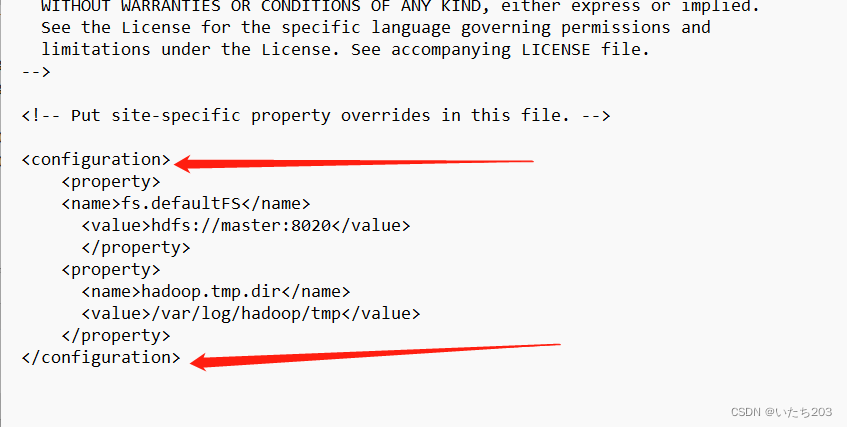
记住!!!一定要保存!!!!
(2)hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
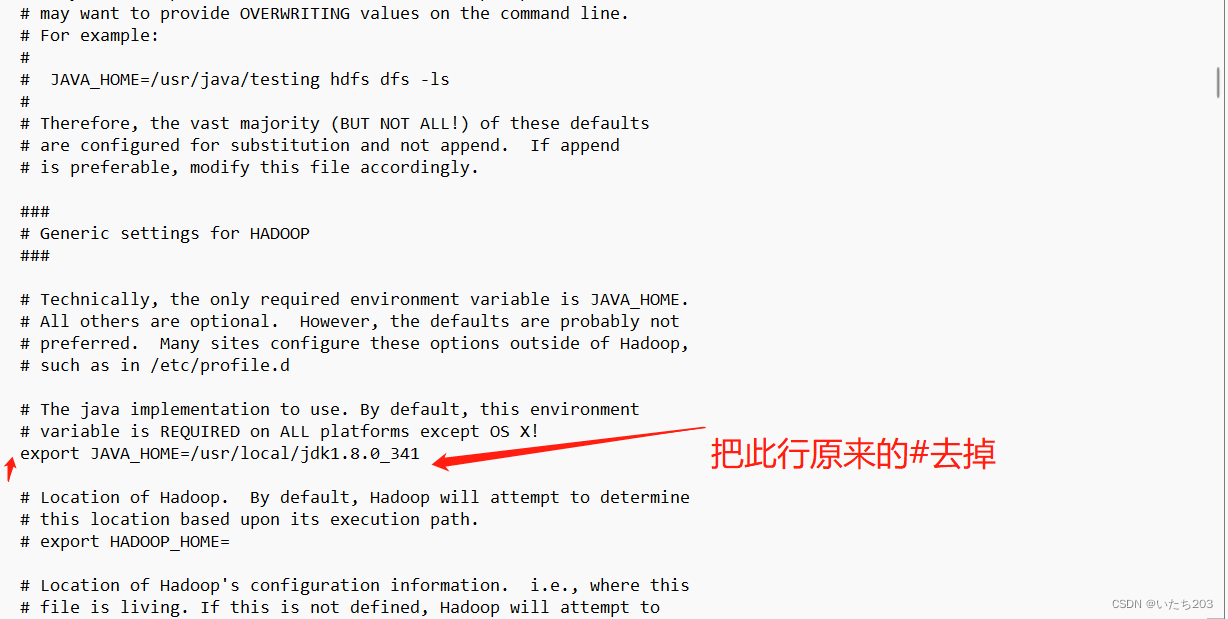
这里需要注意你的jdk的版本是否跟我一样
(3)hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
(4) mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
(5) yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
(6)yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
添加在最末尾
(7)workers
slave1
删除里面原来在添加此数据
(8)hosts
注意这个文件在/etc/hosts,在其某位添加如下代码:
首先`
vi /etc/hosts
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
(9)profile环境变量
这个也是/etc下面的文件,也是在其末尾添加。
export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH
然后使用
source /etc/profile
使环境变量生效
4)克隆虚拟机
在虚拟机master上配置完成Hadoop集群相关配置后,将虚拟机master克隆,生成1个新的虚拟机slave1。
在window系统中虚拟机master的安装目录下建立1个文件slave1。用来存放slave1的内容
然后打开VM
右键单击虚拟机master,依次选择“管理”→“克隆”命令,进入“欢迎使用克隆虚拟机向导”的界面,直接单击“下一步”按钮
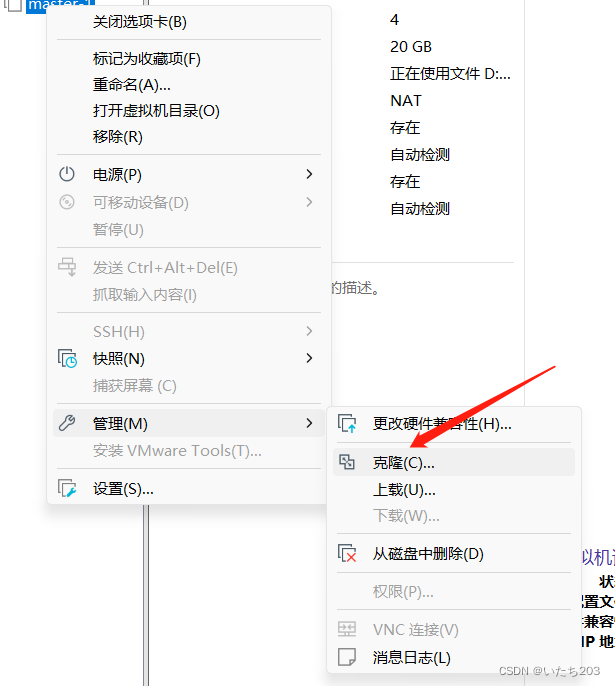
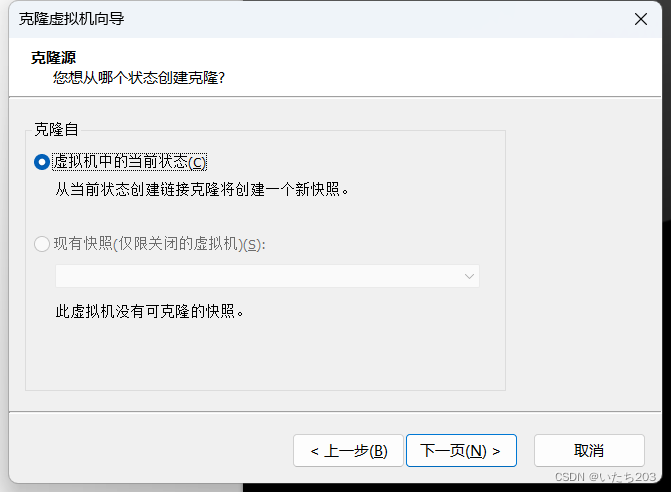
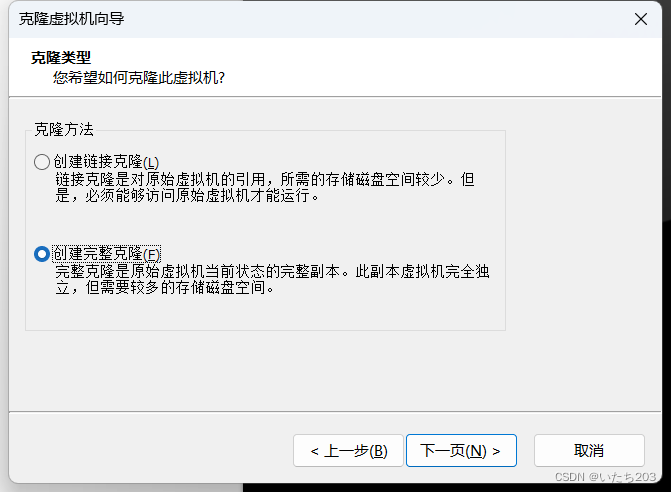
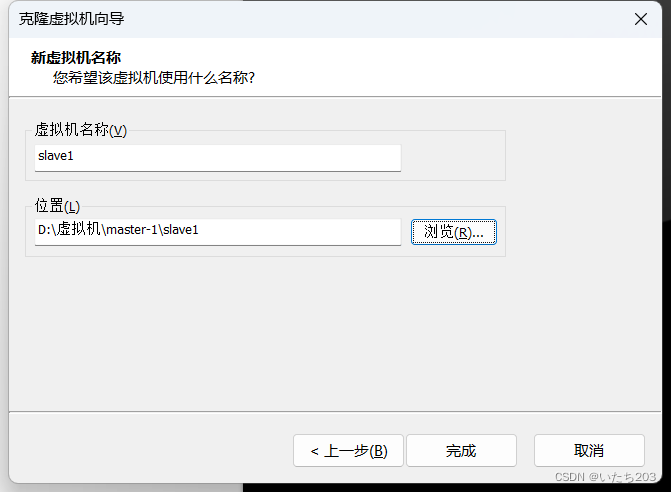
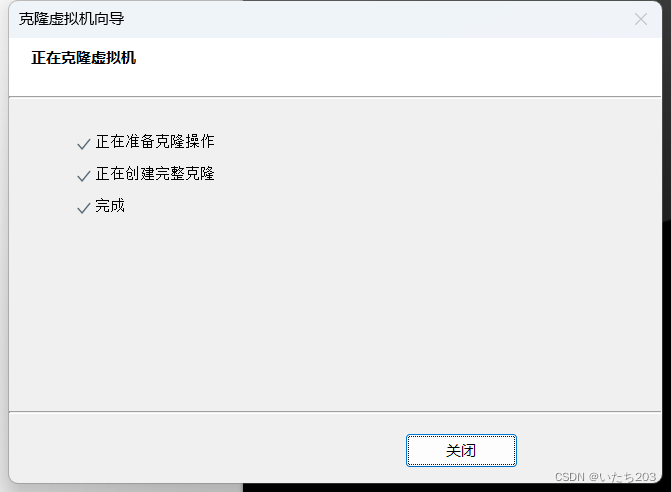
5)配置节点slave1相关属性
开启slave1虚拟机,修改相关配置。因为slave1虚拟机是由master虚拟机克隆产生的,即虚拟机配置与虚拟机master一致,所以需要修改slave1的相关配置,修改过程如下。
修改vi /etc/sysconfig/network-scripts/ifcfg-ens33文件,将IPADDR的值修改为“192.168.128.131”。
重启网络服务,并查看IP是否修改成功。
修改主机名称为slave1。
重启虚拟机,使用“reboot” 命令重新启动虚拟机。
具体参考第1节步骤,改名字的也在上述步骤中(自行查询)
同样也是把该节点连接到远程控制界面
该步骤也在上述中(自行查找借鉴)
6)配置SSH无密码登录
(1)使用ssh-keygen产生公钥与私钥对。
输入命令“ssh-keygen -t rsa”,接着按三次Enter键
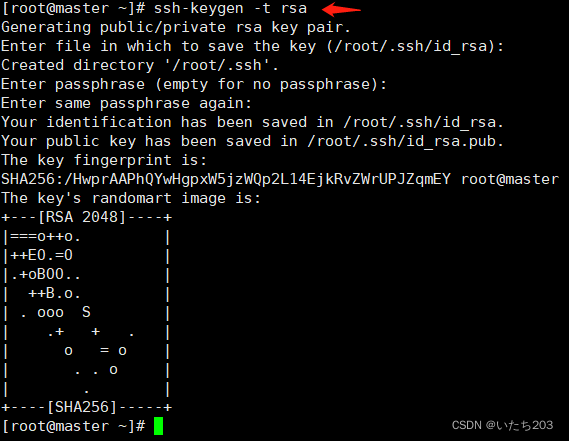
生成私有密钥id_rsa和公有密钥id_rsa.pub两个文件。ssh-keygen用来生成RSA类型的密钥以及管理该密钥,参数“-t”用于指定要创建的SSH密钥的类型为RSA。
(2)公钥复制到远程机器
依次输入yes, 000000(root用户的密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub master
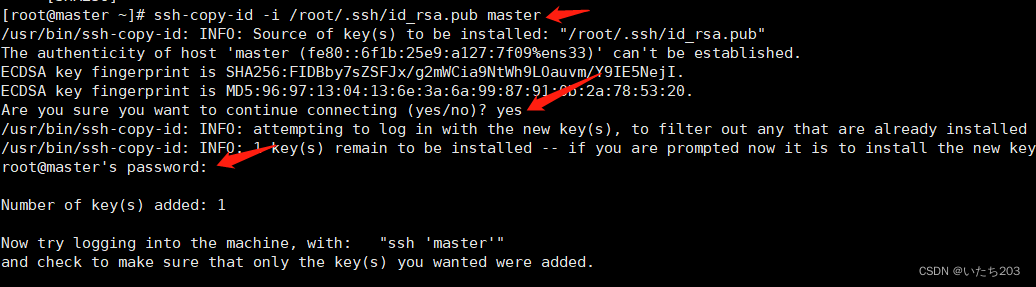
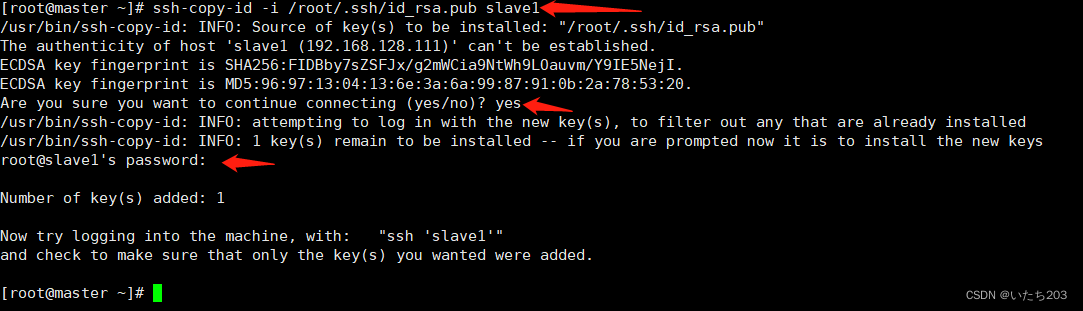
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
(3)验证ssh登录
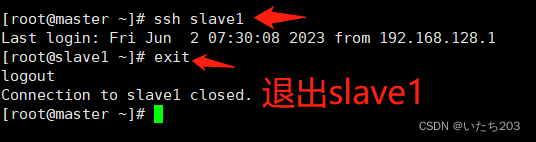
验证SSH是否能够无密钥登录。在master主节点下输入“ssh slave1”,结果如下图,说明配置SSH免密码登录成功。
7)Hadoop集群配置时间同步
(1)安装NTP
安装NTP服务。在各个节点用“yum install -y ntp ”命令。若出现了“Complete ”,则说明安装NTP服务成功。
(2)修改NTP文件
注意此操作是在master中
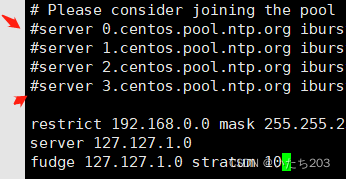
使用命令“vi /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加:
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
下面的操作是在节点slave1中操作
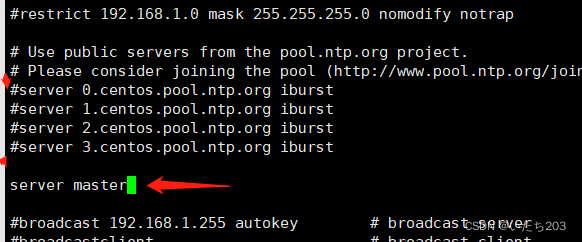
在slave中配置NTP,修改/etc/ntp.conf文件,注释掉server开头的行,并添加:
server master
(3)关闭防火墙
使用这两个命令关闭防火墙
注意!!! 所有节点都要关闭
systemctl stop firewalld
systemctl disable firewalld

节点slave1不再展示
(4)启动NTP服务
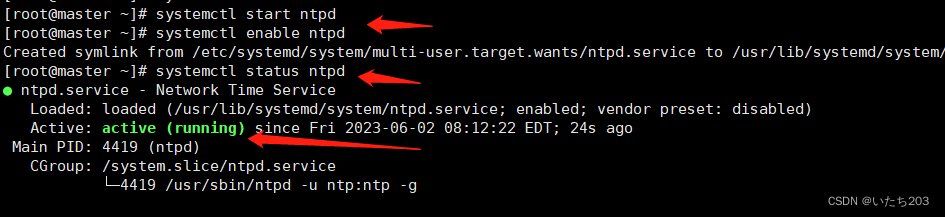
在master和slave1节点上使用这两代码开启NTP服务
systemctl start ntpd
systemctl enable ntpd
在使用systemctl status ntpd 命令查看ntpd的状态,出现 running 表示运行成功,slave1同样这样操作
然后在slave1 节点中,使用 ntpdate master 命令,同步时间

8)格式化NameNode
进入目录
cd /usr/local/hadoop-3.2.4/sbin
并使用代码
hdfs namenode -format
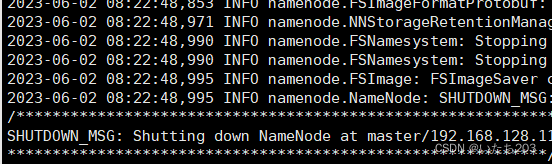
出现此情况表示格式化成功
注意!!!!slave1也是如此格式化
9)执行启动Hadoop集群
在master节点中也是在sbin 目录下然后输入
./start-all.sh
然后在输入
jps
出现如此现象表示Hadoop集群已经启动成功

三、测试启动
1、打开浏览器
查看Hadoop的服务监控端口
http://192.168.128.130:9870
http://192.168.128.131:8088
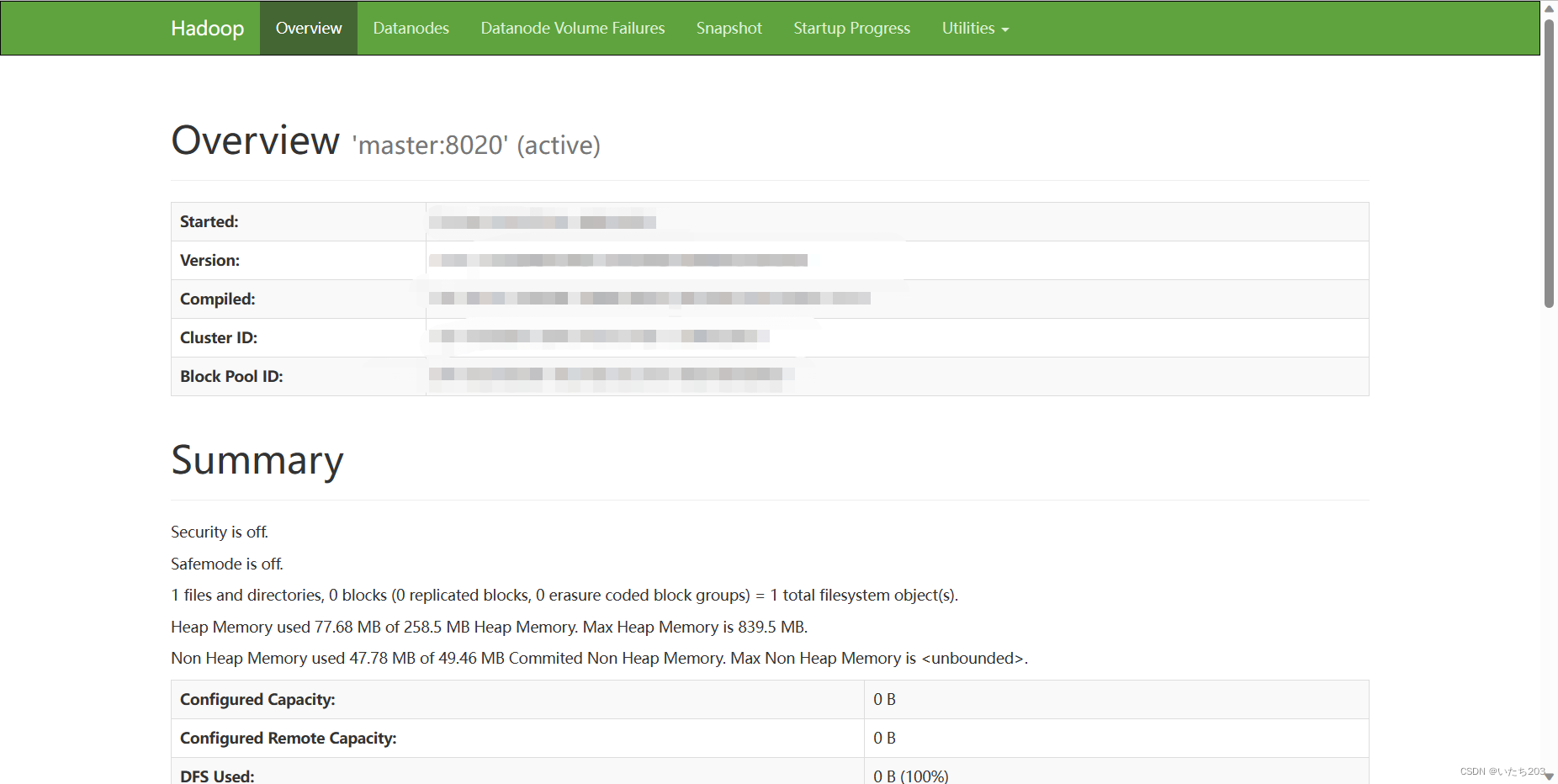
若出现这两个界面,那恭喜你,Hadoop集群搭建成功了!!!!















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











