






|
|
|
|
目录
- Spark双节点部署
1.1、安装Java
因为Spark需要在Java环境才能运行,所以需要在所有节点上安装Java。首先,准备一份JDK,然后使用软件Xftp进行上传到目录/opt下。然后进入控制台输入以下命令解压JDK到/usr/local目录下。
注意 :这里的所有步骤都是在虚拟机内进行的。镜像为 Centos 7。其中xshell和xftp都是对虚拟机的系统进行相关操作的工具。它们的详细介绍请参考我的前篇文章
| tar zxvf jdk-8u341-linux-x64.tar.gz -C /usr/local/ |
1.2、下载Spark安装包
首先,进入到spark官网,去下载该安装包,如图所示。

下载好后,同Java一样使用Xftp上传到Linux终端的/opt下。
使用命令解压到/usr/local下。注意搭建双节的Spark集群,两个包的解压路径必须一致。
| tar zxvf spark-3.3.2-bin-hadoop3-scala2.13_2.tgz -C /usr/local/ |
然后开始配置相关的Spark的文件。
1.3、Spark文件配置
在完成JDK和Spark包解压完成之后方可进行此步操作。以下操作在主节点master和从节点node中都要去配置
1.3.1、修正配置文件名称
首先进入spark的安装目录 usr/local 下,使用以下命令修改Spark的安装目录的名称。
| mv spark-3.3.2-bin-hadoop3-scala2.13/ spark-3.3.2 |
然后进入其文件下的 spark-3.3.2/conf目录,修改其内的三个文件名称,
命令分别为:
| mv spark-env.sh.template spark-env.sh mv workers.template workers mv spark-defaults.conf.template spark-defaults.conf |
![]()
1.3.2、配置workers文件
workers文件用于指定工作节点的主机名或IP地址。操作路径为/usr/local/spark-3.3.2/使用命令
| vi workers |
添加以下内容在末尾
| master node |
注意:这个步骤在master和node这两个节点中都要配置
1.3.2、配置spark-env.sh文件
这一步的操作步骤路径也是在 /usr/local/spark-3.3.2 /conf下进行。使用命令
| cd /usr/local/spark-3.3.2 /conf vi spark-env.sh |
并在其末尾添加以下内容
| export JAVA_HOME=/usr/local/jdk1.8.0_341 SPARK_MASTER_HOST=192.168.128.120 SPARK_MASTER_PROT=7777 |
在修改从节点的文件时,除了要添加上面的代码外,还仍需在加一行CPU核心数量例如
| export JAVA_HOME=/usr/local/jdk1.8.0_341 SPARK_MASTER_HOST=192.168.128.120 SPARK_MASTER_PROT=7777 export SPARK_WORKER_CORES=4 |
注意:节点的相关spark配置,也如同主节点的步骤一样操作!!!
1.3.4、启动Spark
首先重启虚拟机master和node。重启完成后,进入主节点的Spark安装目录。/usr/local/spark-3.3.2/sbin。输入命令启动Spark集群
| ./start-all.sh |

然后进入浏览器输入http://192.168.128.120:8080 就会看到如下界面,则表示Spark双节点部署完成

二、Spark代码
首先要想在Idea中实现spark代码的运行,就要spark的和Scala的相关包的jar目录放进在Idea的项目目录中。
第一步,进入网站去下载该软件包

下载完成后,在自己的本机里面进行解压然后打开其文件夹,找到jar目录并复制。然后,再打开其Idea 的项目目录,直接粘贴在其内。并改正名称lib.


2.1、完整代码
以下是在IEDA中所书写Spark完整代码,如下所示:
| package dykj import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object middle_salary { def main(args: Array[String]): Unit = { // 创建Spark配置对象 val conf: SparkConf = new SparkConf().setMaster("spark://master:7077").setAppName("salary_m") // 创建SparkContext对象 val sc: SparkContext = new SparkContext(conf) // 读取数据并进行处理 val drop_data: RDD[String] = sc.textFile("hdfs://master:8020/user/hive/warehouse/logs_new/Employee_salary_second_half.csv").mapPartitionsWithIndex( (index, data) => { if (index == 0) data.drop(1) data } ) // 对数据进行转换和映射 val map_data: RDD[(String, Int)] = drop_data.map( data => { val strings: Array[String] = data.split(",") // 提取工资值,并将其转换为整数类型 val net_pay = strings(6).toIntOption.getOrElse(0) ("salary", net_pay) // 将工资值和键"salary"组成键值对 } ) val sort = map_data.sortBy(x => x._2, true) //排序 val sort_list = sort.collect().toList //转换列表 val middle = sort_list.slice((sort_list.length * 0.2).toInt, (sort_list.length * 0.8).toInt + 1) val total = middle.map(x => x._2).sum //总和 val length = middle.length //求长度 println(total / length) } } |
2.2、代码解释
2.2.1、导入包和spark程序设置
| import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object middle_salary { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("spark://master:7077").setAppName("salary_m") val sc: SparkContext = new SparkContext(conf) |
导入了org.apache.spark.rdd.RDD和org.apache.spark.{SparkConf, SparkContext}类,这些类是用于在Spark中进行分布式计算和操作数据。
通过new SparkConf()创建一个SparkConf对象,并使用setMaster方法设置Spark应用程序的Master节点地址为"spark://master:7077",使用setAppName方法设置应用程序的名称为"salary_m"。
通过new SparkContext(conf)创建一个SparkContext对象。
2.2.2、读取数据
| val drop_data: RDD[String] = sc.textFile("hdfs://master:8020/user/hive/warehouse/logs_new/Employee_salary_second_half.csv").mapPartitionsWithIndex( (index, data) => { if (index == 0) data.drop(1) data } ) |
使用sc.textFile方法从HDFS中读取文件"Employee_salary_second_half.csv"的内容,并将其转换为一个RDD[String]类型的对象。然后使用mapPartitionsWithIndex方法对RDD的每个分区进行处理。
在函数中,对索引为0的,使用data.drop(1)删除第一行数据,然后返回处理后的数据。
2.2.3、数据转换
| val map_data: RDD[(String, Int)] = drop_data.map( data => { val strings: Array[String] = data.split(",") val net_pay = strings(6).toIntOption.getOrElse(0) ("salary", net_pay) } ) |
对drop_data里面的数据进行map,把每行数据按逗号分隔成一个字符串string,然后从数组中提取第7个元素,使用toIntOption方法将其转换为整数。最后,将字符串"salary"和提取到的工资值作为键值对存储在一个新的RDD中,RDD的类型为RDD[(String, Int)]。
2.2.4、获取中间值
要想获取中间值首先要进行对数据的排序,
| val sort = map_data.sortBy(x => x._2, true) val sort_list = sort.collect().toList |
对map_data进行升序排序。然后定义一个常量去接收排序后的数据,然后通过tolist转换成列表。然后使用slice函数获取这个数据的内容:去掉前百分之二十和后百分之二的中间部分。
| val middle = sort_list.slice((sort_list.length * 0.2).toInt, (sort_list.length * 0.8).toInt + 1) |
2.2.5、计算中间值
| val total = middle.map(x => x._2).sum val length = middle.length println(total / length) |
使用sum计算总和,将结果存储在total变量里。同时,使用length获取中间值子列表的长度。然后就是使用println把中间值算出来。
三、Spark集群运行代码
3.1、构建Jar包
在Idea中点击 “项目结构“,再依次点击 ”添加“,”Jar”, “项目依赖项”。然后选择求中位数的类。如图所示

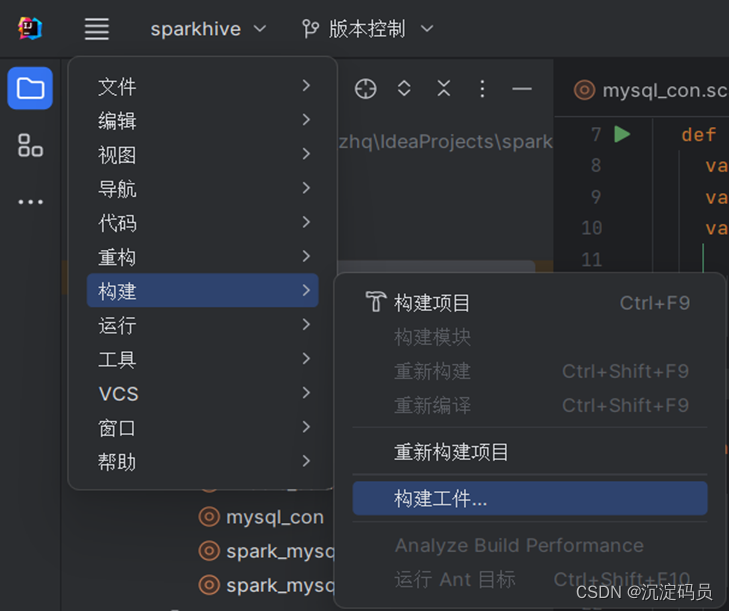
然后在“项目结构“里面再次点击 确定 。接下来开始进行构建,步骤如图所示。

点击后便是完成构建。会在其idea 文件夹出现一个构建的Jar包

3.2、上传数据和Jar包
使用Xfit传输这两个包到 /opt 下,

然后使用命令把数据Employee_salary_second_half.csv上传到HDFS上的/user/hive/warehouse/logs_new/下
| hdfs dfs -put /opt/Employee_salary_second_half.csv /user/hive/warehouse/logs_new/ |
然后在文件操作系统可以看到已上传
3.3、运行Jar包并指定结果文件
首先进入到Spark集群的目录的bin 下,然后使用下面的命令提交Jar包到Spark集群中运行,并将运行的结果保存在 /data/salary.txt 中
| ./spark-submit --class dykj.middle_salary --master local[*] /opt/sparkhive.jar --conf spark.log.level=WARN > /data/salary.txt |
这个命令将日志级别设置为 WARN,这意味着只会输出警告信息和错误信息,并将程序的输出重定向到 /data/salary.txt 文件中。这样,您的程序将只输出结果到文件中,并且不会产生其他日志信息。

3.4、查看结果
进入/data 目录使用命令查看文件 salary.txt
| cd /data cat salary.txt |

图中标注的数字便是工作的中位数。















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











