






任何数据库模式都可能有大量的文本字段。在本文中,我将文本字段分为三类:
1. 小文本:姓名、债券、用户名、电子邮件等。这些文本字段通常具有一些较低的大小限制,甚至可能使用 varchar(n) 而不是 text 。
2. 大文本:博客内容、论文、HTML 内容等。这些是存储在数据库中的大量的不受限制的文本。
3. 中等文本:描述、评论、产品说明、堆栈信息等。这些是介于大文本和小文本的任意文本字段。这些类型的文本通常不受限制,但自然要小于大文本。
在本文中,我会演示中等大小的文本对 PostgreSQL 查询性能的惊人影响。
理解 TOAST
在谈论大块的文本或任何其他可能包含大量数据的字段时,我们首先需要了解数据库如何处理这类数据。直觉上,你可能认为数据库像存储较小的数据一样行内存储大块数据,但实际上并不是:
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages. Therefore, it is not possible to store very large field values directly.
正如文档所述,PostgreSQL 不能在多个页面中存储行(元组)。那么数据库是如何存储大量数据的呢?
[...] large field values are compressed and/or broken up into multiple physical rows. [...] The technique is affectionately known as TOAST (or "the best thing since sliced bread").
那么这个 TOAST 是如何工作的呢?
If any of the columns of a table are TOAST-able, the table will have an associated TOAST table
所以 TOAST 是与我们的表相关联的一个单独的表。它用于存储 TOAST-able 列的大块数据(例如 text 数据类型,便是 TOAST-able)。
哪些共同组成了一个大值?
The TOAST management code is triggered only when a row value to be stored in a table is wider than TOAST_TUPLE_THRESHOLD bytes (normally 2 kB). The TOAST code will compress and/or move field values out-of-line until the row value is shorter than TOAST_TUPLE_TARGET bytes (also normally 2 kB, adjustable) or no more gains can be had
仅当要存储在表中的行值大于 TOAST_TUPLE_THRESHOLD 字节(通常为 2 kB)时,才会触发 TOAST 管理代码。TOAST 代码将压缩 和/或 移动字段值,直到行值短于 TOAST_TUPLE_TARGET 字节(通常也为 2 kB,可调整)或无法获得更多增益
PostgreSQL 将尝试压缩行中的大值,如果行不能满足限制,这些值将被行外存储在 TOAST 表中。
寻找 TOAST
现在我们对 TOAST 是什么有了一些了解,让我们看看它的实际应用。首先,创建一个带有 text 字段的表:
CREATE TABLE toast_test (id SERIAL, value TEXT);
该表包含一个 id 列和一个 TEXT 类型的 value 字段。注意,我们没有更改任何默认存储参数。
我们添加的 TEXT 支持 TOAST,或者说是 TOAST-able,所以 PostgreSQL 应该创建一个 TOAST 表。让我们尝试在 pg_class 中找到与表 toast_test 关联的 TOAST 表:
SELECT relname, reltoastrelid FROM pg_class WHERE relname = 'toast_test';
relname │ reltoastrelid
────────────┼───────────────
toast_test │ 340488
SELECT relname FROM pg_class WHERE oid = 340488;
relname
─────────────────
pg_toast_340484
如预期,PostgreSQL 创建了一个名为 pg_toast_340484 的 TOAST 表。
TOAST 的实际情况
让我们看看 TOAST 表是什么样子的:
db=# \d pg_toast.pg_toast_340484
TOAST table "pg_toast.pg_toast_340484"
Column │ Type
────────────┼─────────
chunk_id │ oid
chunk_seq │ integer
chunk_data │ bytea
TOAST 表包含三列:
chunk_id:对 toast 值的引用
chunk_seq:块内的序号
chunk_data:实际的块数据
与"普通"表类似,TOAST 表对行内存储的值有相同的限制。为了克服这个限制,大值被分成可以适应限制的块。
此刻,表是空的:
SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
这是有道理的,因为我们还没有插入任何数据。所以接下来,在表中插入一个小值:
INSERT INTO toast_test (value) VALUES ('small value');
INSERT 0 1
SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
将小值插入表后,TOAST 表仍然是空的。这意味着小值足够小,可以行内存储,并且无需将其移出行外存储到 TOAST 表中。
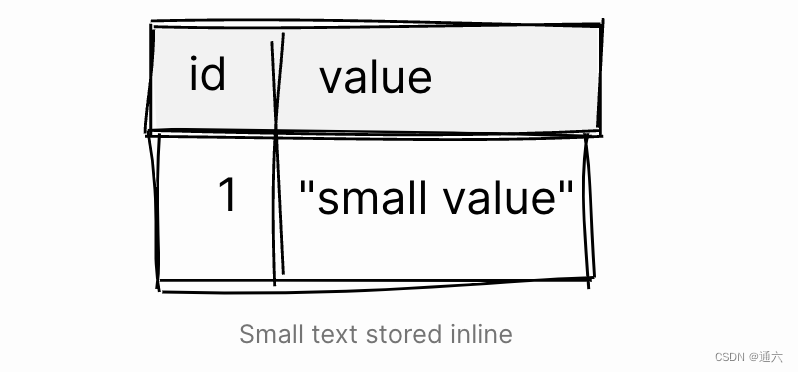
让我们插入一个大值,看看会发生什么:
INSERT INTO toast_test (value) VALUES ('n0cfPGZOCwzbHSMRaX8 ... WVIlRkylYishNyXf');
INSERT 0 1
为了简洁起见,我缩短了值,但这是一个包含 4096 个字符的随机字符串。让我们看看 TOAST 表现在存储了什么:
SELECT * FROM pg_toast.pg_toast_340484;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼──────────────────────
995899 │ 0 │ \x30636650475a4f43...
995899 │ 1 │ \x50714c3756303567...
995899 │ 2 │ \x6c78426358574534...
(3 rows)
大值行外存储在 TOAST 表中。因为该值太大而无法在一行中存储,所以 PostgreSQL 将它分成三个块。\x3063... 表示法是 psql 显示二进制数据的方式。
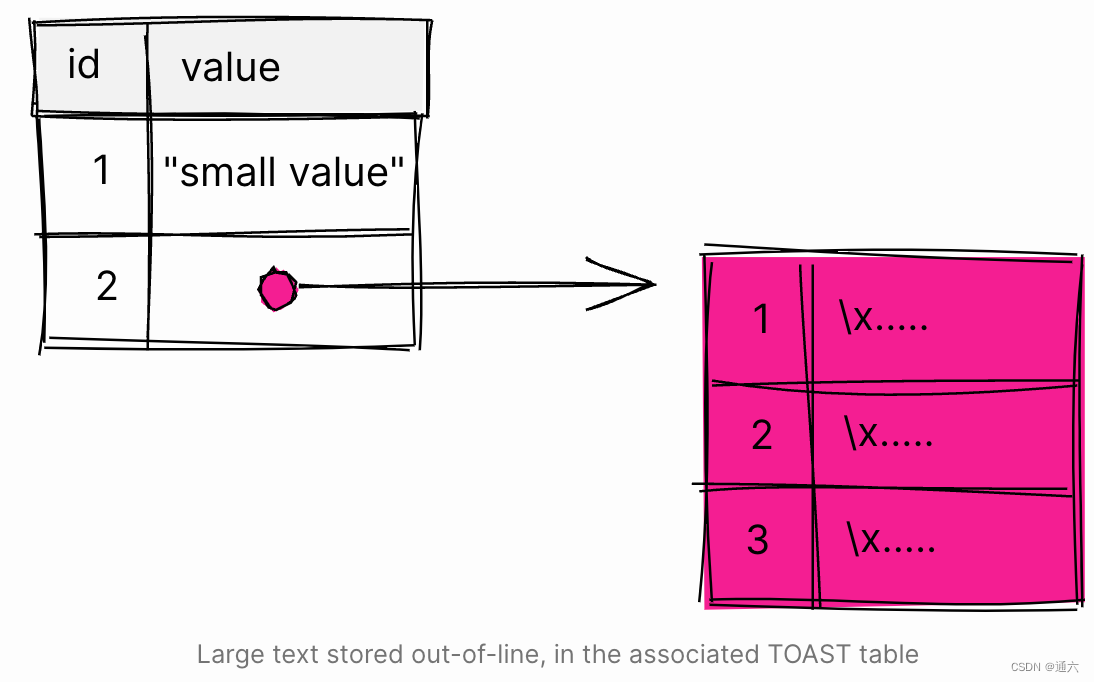
最后,执行以下查询来汇总 TOAST 表中的数据:
SELECT
chunk_id,
COUNT(*) AS chunks,
pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM
pg_toast.pg_toast_340484
GROUP BY
1
ORDER BY
1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
995899 │ 3 │ 4096 bytes
(1 row)
正如我们已经看到的,文本存储在三个块中。
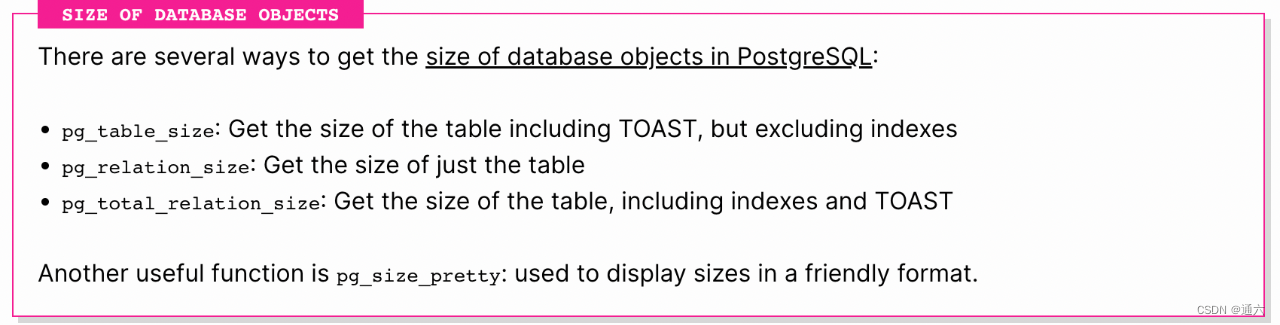
在 PostgreSQL 中有几种获取数据库对象大小的方法:
1. pg_table_size:获取表的大小,包括TOAST,但不包括索引
2. pg_relation_size:获取表的大小”
3. pg_total_relation_size:获取表的大小,包括索引和TOAST
另一个有用的函数是 pg_size_pretty:以友好的格式显示大小。
TOAST 压缩
到目前为止,我没有按大小对文本进行分类。原因是文本本身的大小并不重要,重要的是压缩后的大小。
为了创建用于测试的长字符串,我们实现一个函数来生成给定长度的随机字符串:
CREATE OR REPLACE FUNCTION generate_random_string(
length INTEGER,
characters TEXT default '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
) RETURNS TEXT AS
$$
DECLARE
result TEXT := '';
BEGIN
IF length < 1 then
RAISE EXCEPTION 'Invalid length';
END IF;
FOR __ IN 1..length LOOP
result := result || substr(characters, floor(random() * length(characters))::int + 1, 1);
end loop;
RETURN result;
END;
$$ LANGUAGE plpgsql;
生成一个由 10 个随机字符组成的字符串:
SELECT generate_random_string(10);
generate_random_string
────────────────────────
o0QsrMYRvp
我们还可以提供一组字符来生成随机字符串。例如,生成一个由 10 个随机数字组成的字符串:
SELECT generate_random_string(10, '1234567890');
generate_random_string
────────────────────────
4519991669
PostgreSQL TOAST 使用 LZ 系列的压缩技术。压缩算法通常通过识别和消除值中的重复项来工作。与由许多不同字符组成的字符串相比,包含较少字符的长字符串在编码为字节时应该可以更好地压缩。
为了说明 TOAST 如何使用压缩,我们将清理 toast_test 表,并插入一个由许多可能的字符组成的随机字符串:
TRUNCATE toast_test;
TRUNCATE TABLE
INSERT INTO toast_test (value) VALUES (generate_random_string(1024 * 10));
INSERT 0 1
我们插入了一个由随机字符组成的 10kb 的值。让我们检查 TOAST 表:
SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
该值行外存储在 TOAST 表中,我们可以看到它没有被压缩。
接下来,插入一个长度相似的值,但由更少的可能的字符组成:
INSERT INTO toast_test (value) VALUES (generate_random_string(1024 * 10, '123'));
INSERT 0 1
SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
1495961 │ 2 │ 3067 bytes
我们插入了一个 10K 的值,但这次它只包含 3 个可能的数字:1、2 和 3。这串文本更有可能包含重复的二进制项,并且应该比之前的值压缩得更好。查看 TOAST,我们可以看到 PostgreSQL 将值压缩到大约 3kB,这是未压缩值大小的三分之一。不错的压缩率!
最后,插入一个由单个数字组成的 10K 长字符串:
insert into toast_test (value) values (generate_random_string(1024 * 10, '0'));
INSERT 0 1
db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_340484 GROUP BY 1 ORDER BY 1;
chunk_id │ chunks │ pg_size_pretty
──────────┼────────┼────────────────
1495960 │ 6 │ 10 kB
1495961 │ 2 │ 3067 bytes
该字符串被压缩得非常好,以至于数据库能够将其行内存储。
配置 TOAST
如果你对为表配置 TOAST 感兴趣,可以通过 CREATE TABLE 或 ALTER TABLE ... SET STORAGE 语句设置存储参数来实现。相关参数为:
toast_tuple_target:PostgreSQL 尝试将长值移动到 TOAST 之后的最小元组长度
storage:TOAST 策略。PostgreSQL 支持 4 种不同的 TOAST 策略。默认值为 EXTENDED,这意味着 PostgreSQL 将尝试压缩该值并将其行外存储。
我个人从来不需要更改默认的 TOAST 存储参数。
TOAST 性能
为了了解不同的文本大小和行外存储对性能的影响,我们将创建三个表,每个表用于每种类型的文本:
CREATE TABLE toast_test_small (id SERIAL, value TEXT);
CREATE TABLE
CREATE TABLE toast_test_medium (id SERIAL, value TEXT);
CREATE TABLE
CREATE TABLE toast_test_large (id SERIAL, value TEXT);
CREATE TABLE
和前一节一样,PostgreSQL 为每个表创建了一个 TOAST 表:
SELECT
c1.relname,
c2.relname AS toast_relname
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test%'
AND c1.relkind = 'r';
relname │ toast_relname
───────────────────┼─────────────────
toast_test_small │ pg_toast_471571
toast_test_medium │ pg_toast_471580
toast_test_large │ pg_toast_471589
配置测试数据
首先,让我们用 500K 包含可以行内存储的小文本数据填充 toast_test_small:
INSERT INTO toast_test_small (value)
SELECT 'small value' FROM generate_series(1, 500000);
INSERT 0 500000
接下来,在 toast_test_medium 中填充 500K 行,这些行包含处于行外存储的边界的文本,但仍然足够小到可以行内存储:
WITH str AS (SELECT generate_random_string(1800) AS value)
INSERT INTO toast_test_medium (value)
SELECT value
FROM generate_series(1, 500000), str;
INSERT 0 500000
我尝试了不同的值,直到我得到一个足够大到可以行外存储的值。技巧是找到一个压缩得很差的大约 2K 的字符串。
接下来,在 toast_test_large 中插入 500K 行大文本:
WITH str AS (SELECT generate_random_string(4096) AS value)
INSERT INTO toast_test_large (value)
SELECT value
FROM generate_series(1, 500000), str;
INSERT 0 500000
现在准备好进行下一步。
比较性能
通常情况下,我们预期对大表的查询比对小表的查询慢。在这种情况下,期望小表上的查询比中型表上的查询运行得更快,中型表上的查询比大表上的相同查询更快并不是没有道理的。
为了比较性能,将执行一个简单的查询以从表中获取一行。由于我们没有索引,数据库将执行全表扫描。我们还将禁用并行查询执行以获得干净、简单的计时,并多次执行查询以解决缓存问题。
SET max_parallel_workers_per_gather = 0;
SET
从小表开始:
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────
Seq Scan on toast_test_small (cost=0.00..8953.00 rows=1 width=16
Filter: (id = 6000)
Rows Removed by Filter: 499999
Execution Time: 41.513 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
Execution Time: 25.865 ms
为了简洁起见,我多次运行查询并修剪了输出。正如预期的那样,数据库执行了全表扫描,时间最终确定在大约 25 毫秒。
接下来,对中型表执行相同的查询:
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
Execution Time: 321.965 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
Execution Time: 173.058 ms
在中型表上运行完全相同的查询花费了更多的时间,173 毫秒,这比在小表上慢了大约 6 倍。这是有道理的。
要完成测试,需要在大表上再次运行查询:
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
Execution Time: 49.867 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
Execution Time: 37.291 ms
嗯,这很令人惊讶!大表的查询时间和小表的时间差不多,比中表快6倍。

大表应该更慢,所以发生了什么?
理解结果
要理解结果的含义,需要查看每个表的大小,以及与其关联的 TOAST 表的大小:
SELECT
c1.relname,
pg_size_pretty(pg_relation_size(c1.relname::regclass)) AS size,
c2.relname AS toast_relname,
pg_size_pretty(pg_relation_size(('pg_toast.' || c2.relname)::regclass)) AS toast_size
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test_%'
AND c1.relkind = 'r';
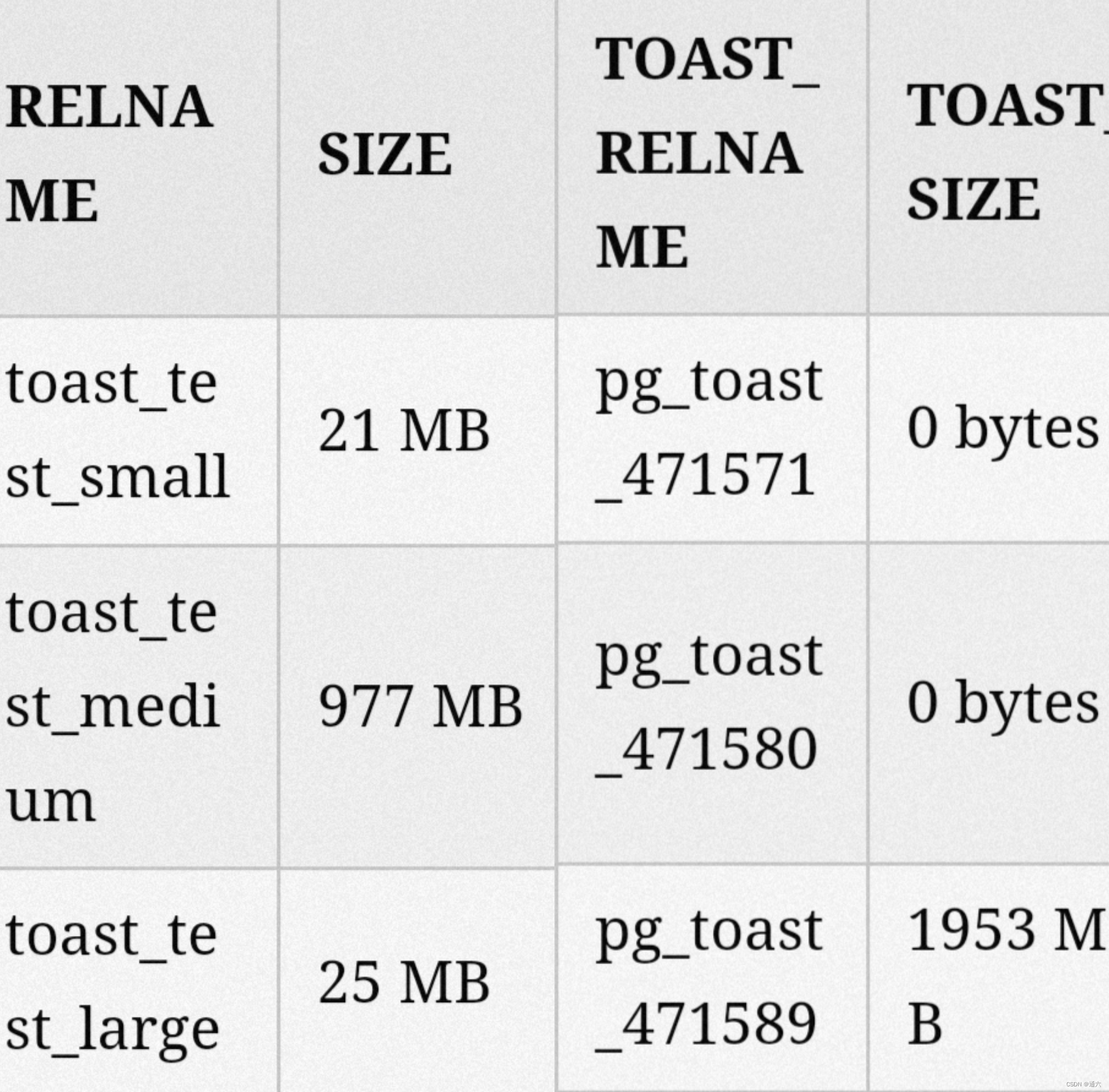
分解一下:
toast_test_small:表大小为21MB,没有TOAST。这是有道理的,因为我们插入该表的文本足够小,可以行内存储。
toast_test_medium:表明显更大,977MB。我们插入的文本值小到可以行内存储。结果,表变得很大,根本没有使用 TOAST。
toast_test_large:表的大小与小表的大小大致相似。这是因为我们将大文本插入到表中,而 PostgreSQL 将它们行外存储在 TOAST 表中。这就是为什么 TOAST 表对于大表来说如此之大,但表本身仍然很小。
当执行查询时,数据库进行了全表扫描。扫描大表和小表,数据库只需要读取 21MB 和 25MB,查询速度非常快。但是,当我们对中型表执行查询时,所有文本都行内存储,数据库必须从磁盘读取 977MB,查询花费的时间要长得多。
TOAST 是一种通过行外存储大值来保持表紧实的好方法!
使用文本值
在之前的比较中,我们执行了一个只使用 ID 而不是 text 值的查询。当我们实际需要访问文本值本身时会发生什么?
\timing
Timing is on.
SELECT * FROM toast_test_large WHERE value LIKE 'foo%';
Time: 7509.900 ms (00:07.510)
SELECT * FROM toast_test_large WHERE value LIKE 'foo%';
Time: 7290.925 ms (00:07.291)
SELECT * FROM toast_test_medium WHERE value LIKE 'foo%';
Time: 5869.631 ms (00:05.870)
SELECT * FROM toast_test_medium WHERE value LIKE 'foo%';
Time: 259.970 ms
SELECT * FROM toast_test_small WHERE value LIKE 'foo%';
Time: 78.897 ms
SELECT * FROM toast_test_small WHERE value LIKE 'foo%';
Time: 50.035 ms
我们对所有三个表执行查询以在文本值中搜索字符串。该查询预计不会返回任何结果,而是强制扫描整个表。这一次,结果更符合我们的预期:
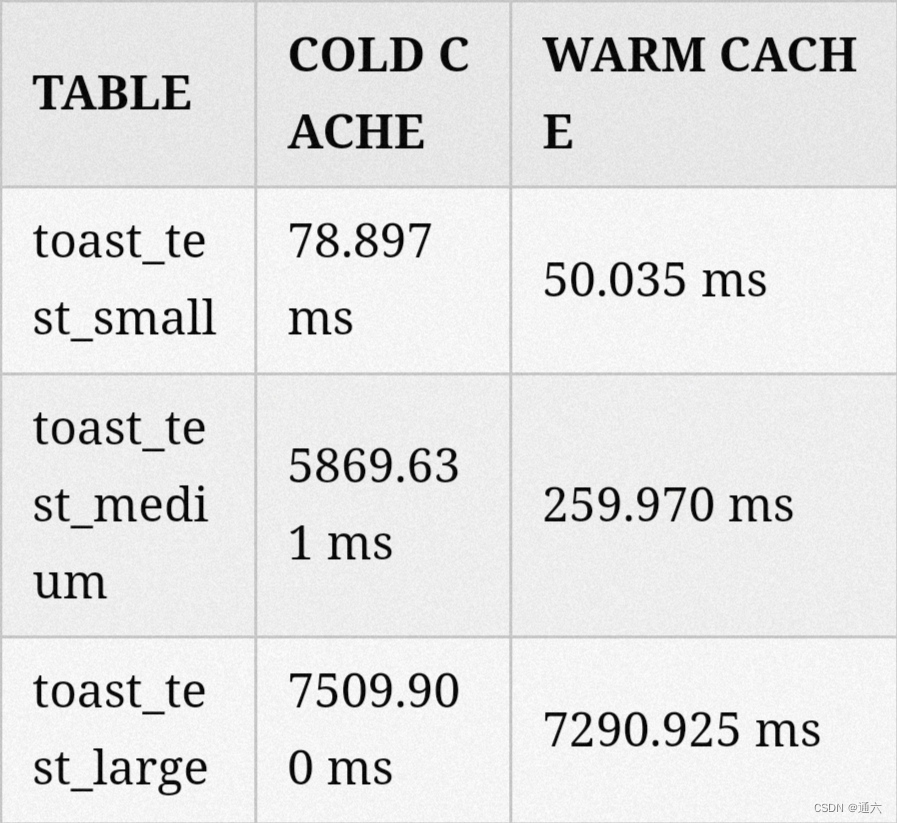
表越大,完成查询所需的时间就越长。这是有道理的,因为为了满足查询,数据库也被迫读取文本字段。在大表的情况下,这也意味着访问 TOAST 表。
索引如何
索引帮助数据库最大限度地减少满足查询所需要获取的页面数量。例如,我们以第一个示例为例,当我们通过 ID 搜索单行时,但这次我们将在字段上创建一个索引:
CREATE INDEX toast_test_medium_id_ix ON toast_test_small(id);
CREATE INDEX
CREATE INDEX toast_test_medium_id_ix ON toast_test_medium(id);
CREATE INDEX
CREATE INDEX toast_test_large_id_ix ON toast_test_large(id);
CREATE INDEX
使用表上的索引执行与以前完全相同的查询:
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_small_id_ix on toast_test_small(cost=0.42..8.44 rows=1 width=16)
Index Cond: (id = 6000)
Time: 0.772 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_medium_id_ix on toast_test_medium(cost=0.42..8.44 rows=1 width=1808
Index Cond: (id = 6000)
Time: 0.831 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id = 6000;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_large_id_ix on toast_test_large(cost=0.42..8.44 rows=1 width=22)
Index Cond: (id = 6000)
Time: 0.618 ms
在所有三种情况下都使用了索引,我们看到所有三种情况下的性能几乎相同。
到目前为止,我们知道当数据库必须执行大量 IO 时,麻烦就开始了。所以接下来,让我们制作一个数据库会选择使用索引的查询,但仍然需要读取大量数据:
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id BETWEEN 0 AND 250000;
QUERY PLAN
───────────────────────────────────────────────────────────────────────────────────────────────
Index Scan using toast_test_small_id_ix on toast_test_small(cost=0.4..9086 rows=249513 width=16
Index Cond: ((id >= 0) AND (id <= 250000))
Time: 60.766 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_small WHERE id BETWEEN 0 AND 250000;
Time: 59.705 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id BETWEEN 0 AND 250000;
Time: 3198.539 ms (00:03.199)
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_medium WHERE id BETWEEN 0 AND 250000;
Time: 284.339 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id BETWEEN 0 AND 250000;
Time: 85.747 ms
EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_large WHERE id BETWEEN 0 AND 250000;
Time: 70.364 ms
我们执行了一个获取表中一半数据的查询。这是表中一个足够低的数据量,使 PostgreSQL 决定使用索引,但仍然足够高,需要大量的 IO。

我们在每个表上运行每个查询两次。在所有情况下,数据库都使用索引来访问表。请记住,索引仅有助于减少数据库必须访问的页数,但在这种情况下,数据库仍然必须读取一半的表。
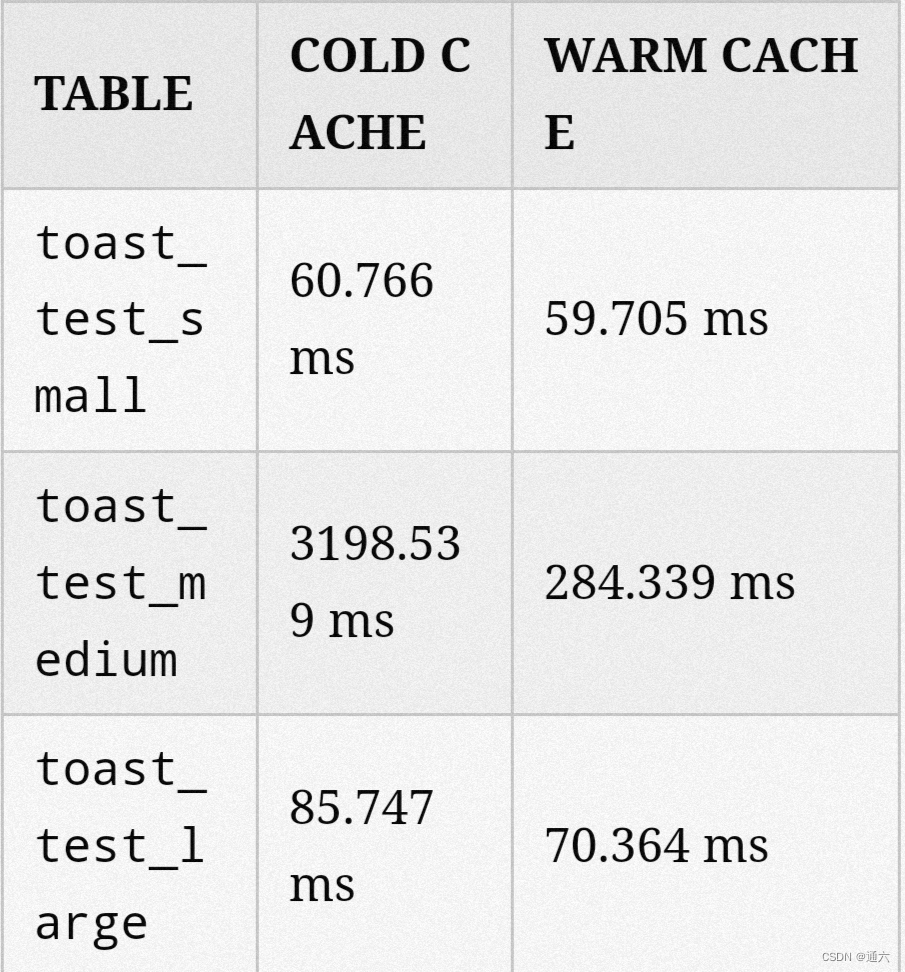
这里的结果与我们运行的第一个测试相似。当数据库必须读取表的大部分内容时,行内存储文本的中型表是最慢的。
可能的解决方式
如果在阅读到目前为止,你确信中等大小的文本是导致性能问题的原因,那么你可以做一些事情。
调整 toast_tuple_target
toast_tuple_target 是一个存储参数,它控制 PostgreSQL 尝试将长值移动到 TOAST 之后的最小元组长度。默认值为 2K,但可以减少到最小 128 字节。值越低,中等大小的字符串越有可能被移出行外存储到 TOAST 表。
为了演示,使用默认存储参数创建一个表,并使用 toast_tuple_target = 128 创建另一个表:
CREATE TABLE toast_test_default_threshold (id SERIAL, value TEXT);
CREATE TABLE
CREATE TABLE toast_test_128_threshold (id SERIAL, value TEXT) WITH (toast_tuple_target=128);
CREATE TABLE
SELECT c1.relname, c2.relname AS toast_relname
FROM pg_class c1 JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE c1.relname LIKE 'toast%threshold' AND c1.relkind = 'r';
relname │ toast_relname
──────────────────────────────┼──────────────────
toast_test_default_threshold │ pg_toast_3250167
toast_test_128_threshold │ pg_toast_3250176
接下来,生成一个大于 2KB 并压缩到小于 128 字节的值,插入到两个表中,并检查它是否被行外存储:
INSERT INTO toast_test_default_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
SELECT * FROM pg_toast.pg_toast_3250167;
chunk_id │ chunk_seq │ chunk_data
──────────┼───────────┼────────────
(0 rows)
INSERT INTO toast_test_128_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
SELECT * FROM pg_toast.pg_toast_3250176;
─[ RECORD 1 ]─────────────
chunk_id │ 3250185
chunk_seq │ 0
chunk_data │ \x3408.......
(大致)类似的中等大小文本在默认参数情况下行内存储,而较低的 toast_tuple_target 情况下则行外存储。
创建单独的表
如果你有一个存储中等大小文本字段的关键表,并且你注意到大多数文本都被行外存储并且可能会减慢查询速度,你可以将具有中等文本字段的列移动到它自己的表中:
CREATE TABLE toast_test_value (fk INT, value TEXT);
CREATE TABLE toast_test (id SERIAL, value_id INT)
之前遇到一个用例,错误消息是中等文本,其中许多是行内存储的,因此表很快就变大了!实际上如此之大,以至于我们注意到查询变得越来越慢。最终我们将错误移到了一个单独的表中,查询变得更快了!
结论
中等大小的文本的主要问题是它们使行非常宽。这是一个问题,因为 PostgreSQL 以及其他面向 OLTP 的数据库都将值存储在行中。我们要求数据库执行只有几列的查询时,这些列的值很可能分布在许多块中。如果行很宽,这将转化为大量 IO,从而影响查询性能和资源使用。
为了克服这一挑战,一些不面向 OLTP 的数据库正在使用不同类型的存储:列式存储。使用列式存储,数据按列而不是按行存储在磁盘上。这样,当数据库必须扫描特定列时,值将存储在连续的块中,通常会转换为更少的 IO。此外,特定列的值更有可能具有重复项和值,因此可以更好地压缩它们。
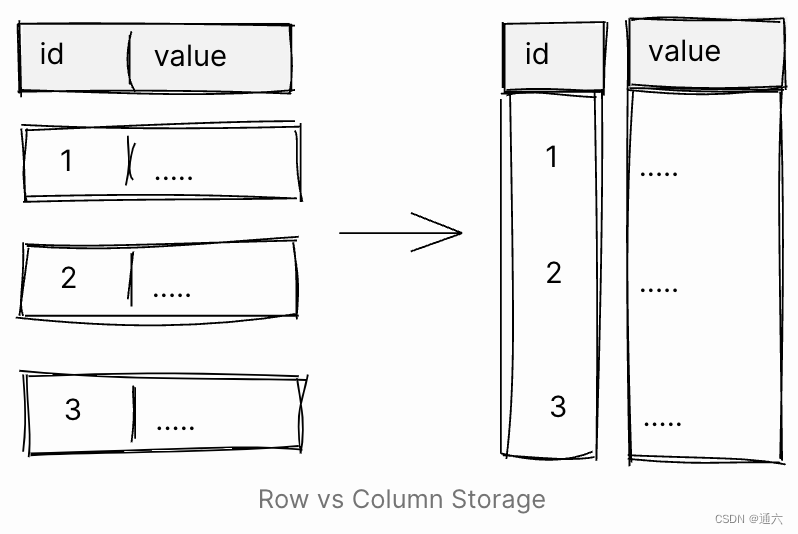
对于数据仓库系统等非 OLTP 的有效负载,这是有道理的。表通常很宽,查询通常使用一小部分列,并读取大量行。在 OLTP 有效负载中,系统通常会读取一行或很少的行,因此将数据存储在行中更有意义。
关于 PostgreSQL 中的可插拔存储的讨论一直在讨论,所以这是需要注意的事情!
TOAST 可观测性
原文译自 https://hakibenita.com/sql-medium-text-performance
提到 TOAST,变长的数据类型存储都是采用的varlena格式,struct varlena是一个通用的结构体,根据字节再转化为具体的对应格式,比如varattrib_1b_e,表示TOAST,它并不存储数据,只是指向了外部数据的地址。
/* TOAST pointers are a subset of varattrib_1b with an identifying tag byte */
typedef struct
{
uint8 va_header; /* Always 0x80 or 0x01 */
uint8 va_tag; /* Type of datum */
char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Type-specific data */
} varattrib_1b_e;
/*
* Type tag for the various sorts of "TOAST pointer" datums. The peculiar
* value for VARTAG_ONDISK comes from a requirement for on-disk compatibility
* with a previous notion that the tag field was the pointer datum's length.
*/
typedef enum vartag_external
{
VARTAG_INDIRECT = 1, ---一个varlena指针,可以指向varatt_external,varatt_expanded,或者是varattrib_1b,varattrib_4b 类型的原始数据。
VARTAG_EXPANDED_RO = 2, ---外部数据是存储在内存中,只读
VARTAG_EXPANDED_RW = 3, ---外部数据是存储在内存中,读写
VARTAG_ONDISK = 18 ---表示外部数据存储在磁盘中
} vartag_external;
掌握了原理,我们就可以 visualize TOAST了(具体的函数在https://dba.stackexchange.com/questions/301669/detecting-inline-inline-compressed-and-toast-storage)。举个例子:
create table toast_test(a varchar);
CREATE TABLE
insert into toast_test values('abc');
INSERT 0 1
insert into toast_test values('abcde');
INSERT 0 1
insert into toast_test values ('中');
INSERT 0 1
insert into toast_test values(repeat('+',126));
INSERT 0 1
insert into toast_test values(repeat('+',127));
INSERT 0 1
insert into toast_test values(repeat('-',2004));
INSERT 0 1
insert into toast_test values(repeat('-',2005));
INSERT 0 1
select pg_column_size(a) from toast_test ;
pg_column_size
----------------
4
6
4
127
131
2008
35
(7 rows)
select lp,t_data from heap_page_items(get_raw_page('toast_test', 0)) where lp in (1,2,3);
lp | t_data
----+----------------
1 | \x09616263 ---第一行数据,3字节
2 | \x0d6162636465 ---第二行数据,5字节
3 | \x09e4b8ad ---第三行数据,"中"的十六进制为09e4b8ad,3字节
(3 rows)
with bits as(
select t_ctid as ctid, (tuple_data_split('toast_test'::regclass, t_data, t_infomask, t_infomask2, t_bits))[1] as bits
from generate_series(0, (select max((ctid::text::point)[0]::int) from toast_test)) as page, lateral heap_page_items(get_raw_page('toast_test', page)) )
select case when is_toasted(bits) then toasted_original_len(bits)
else length(p.a)
end as uncompressed_bytes, --meta_bits(bits), is_compressed(bits) compressed, is_toasted(bits) out_of_line, bytes_on_disk(bits)
from bits
inner join toast_test p on p.ctid=bits.ctid;
uncompressed_bytes | compressed | out_of_line | bytes_on_disk
--------------------+------------+-------------+---------------
3 | f | f | 4
5 | f | f | 6
1 | f | f | 4
126 | f | f | 127
127 | f | f | 131
2004 | f | f | 2008
2005 | t | f | 35
(7 rows)
最核心的原理如下 👇🏻
xxxxxx00 4-byte length word, aligned, uncompressed data (up to 1G)
xxxxxx10 4-byte length word, aligned, compressed data (up to 1G)
00000001 1-byte length word, unaligned, TOAST pointer
xxxxxxx1 1-byte length word, unaligned, uncompressed data (up to 126b)
让我们一起分析一下:
1. 第一行数据,插入了 abc,总共3个字节,未使用压缩,也没有使用TOAST,加上header 1字节,总共4字节(没有使用对齐 alignment)👇🏻 可以看到 126字节的没有对齐,而127字节进行了对齐
2. 第二行数据,插入了 abcde,总共5个字节,未使用压缩,也没有使用TOAST,加上header 1字节,总共6字节(没有使用对齐 alignment)
3. 第三行数据,插入了中,在UTF8下面占用三个字节,所以也是 3 + 1 个字节
create table test(a bool,b varchar);
CREATE TABLE
insert into test values('t','');
INSERT 0 1
insert into test values('t',repeat('-',126));
INSERT 0 1
insert into test values('t',repeat('-',127));
INSERT 0 1
select lp,t_data from heap_page_items(get_raw_page('test', 0)) ;
lp |
t_data
----+----------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------
---------------------------------
1 | \x0103
2 | \x01ff2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2
d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d
2d2d2d2d2d2d2d2d2d
3 | \x010000000c0200002d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2
d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d
2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d
(3 rows)
4. 第四行数据,pg_column_size()会把header一起计算进去,超过126字节(因为varattrib_1b数据类型的 length 是7bit,2^7等于127字节)的会使用4字节的header,小于126字节的会使用1字节的header,所以可以看到pg_column_size()获取的到是127字节(126 + 1)
5. 第五行数据,因为超过了126字节,所以使用了4字节的header,因此pg_column_size()得到的是131字节(127 + 4)
6. 第六行数据,未使用压缩(可以通过 header 的bit flag判断是否使用压缩),插入了2004个字符,加上header,所以大小是2008字节
7. 第七行数据,使用了压缩,压缩后的大小是35字节,插入了2005个字符,所以未压缩前的数据(原始数据)是2005字节
小结
现在大家应该对TOAST有了比较清晰的了解了吧?结合这一篇文章,知晓了TOAST的原理之后,所以不要一股脑的认为大表查询就一定比小表查询慢了。总结一下:
1. UPDATE一个普通表时,当该表的TOAST表存储的数据没有修改时,TOAST表不需要更新。
2. 由于TOAST在物理存储上和普通表分开,所以当SELECT时没有查询被TOAST的列数据时,不需要把这些TOAST的PAGE加载到内存,从而加快了检索速度并且节约了使用空间。
3. 在排序时,由于TOAST和普通表存储分开,当针对非TOAST字段排序时大大提高了排序速度。
使用TOAST存储格式注意事项:
1. 当变长字段上需要使用索引时,权衡CPU和存储的开销,考虑是否需要压缩或非压缩存储。(压缩节约磁盘空间,但是带来CPU的开销)
2. 对于经常要查询或UPDATE的变长字段,如果字段长度不是太大,可以考虑使用MAIN存储。
3. 在超长字段,或者将来会插入超长值的字段上建索引的话需要注意,因为索引最大不能超过三分之一的PAGE,所以超长字段上可能建索引不成功,或者有索引的情况下,超长字段插入值将不成功。解决办法一般可以使用MD5值来建,当然看你的需求了。















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









