






随机创建不同二维数据集作为训练集 ,并结合k-means算法将其聚类 ,你可以尝试分别聚类不同数量的簇 ,并观察聚类 效果:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
x, _ = make_blobs(
n_samples=1000,
centers=[[-1, -1], [0, 0], [1, 1], [2, 2]], # 簇中心分别在[[-1,-1],[0,0],[1,1],[2,2]
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9
)
range_k = range(2, 5)
sc_list = []
centers_list = []
y_means_list = []
for i in range_k:
kmeans = KMeans(n_clusters=i,
random_state=42,
n_init=10)
# 训练
lab = kmeans.fit_predict(x)
y_means = kmeans.predict(x)
y_means_list.append(y_means)
# 计算轮廓
sc = silhouette_score(x,
lab)
sc_list.append(sc)
print(f'k={i}时轮廓系数:{sc:.3f}')
# 获取聚类的中心点
centers = kmeans.cluster_centers_
# 绘制中心点
centers_list.append(centers)
# 可视化第一个图
plt.subplot(2, 2, 1)
plt.scatter(x[:, 0], x[:, 1], marker="o")
plt.title('K-Means聚类结果')
for i in range(3):
# 可视化第i个图
plt.subplot(2, 2, i+2)
plt.scatter(x[:, 0], x[:, 1], marker="o", c=y_means_list[i])
plt.scatter(centers_list[i][:, 0],
centers_list[i][:, 1],
c='red',
s=100,
alpha=0.8)
plt.title('K-Means聚类结果')
plt.show()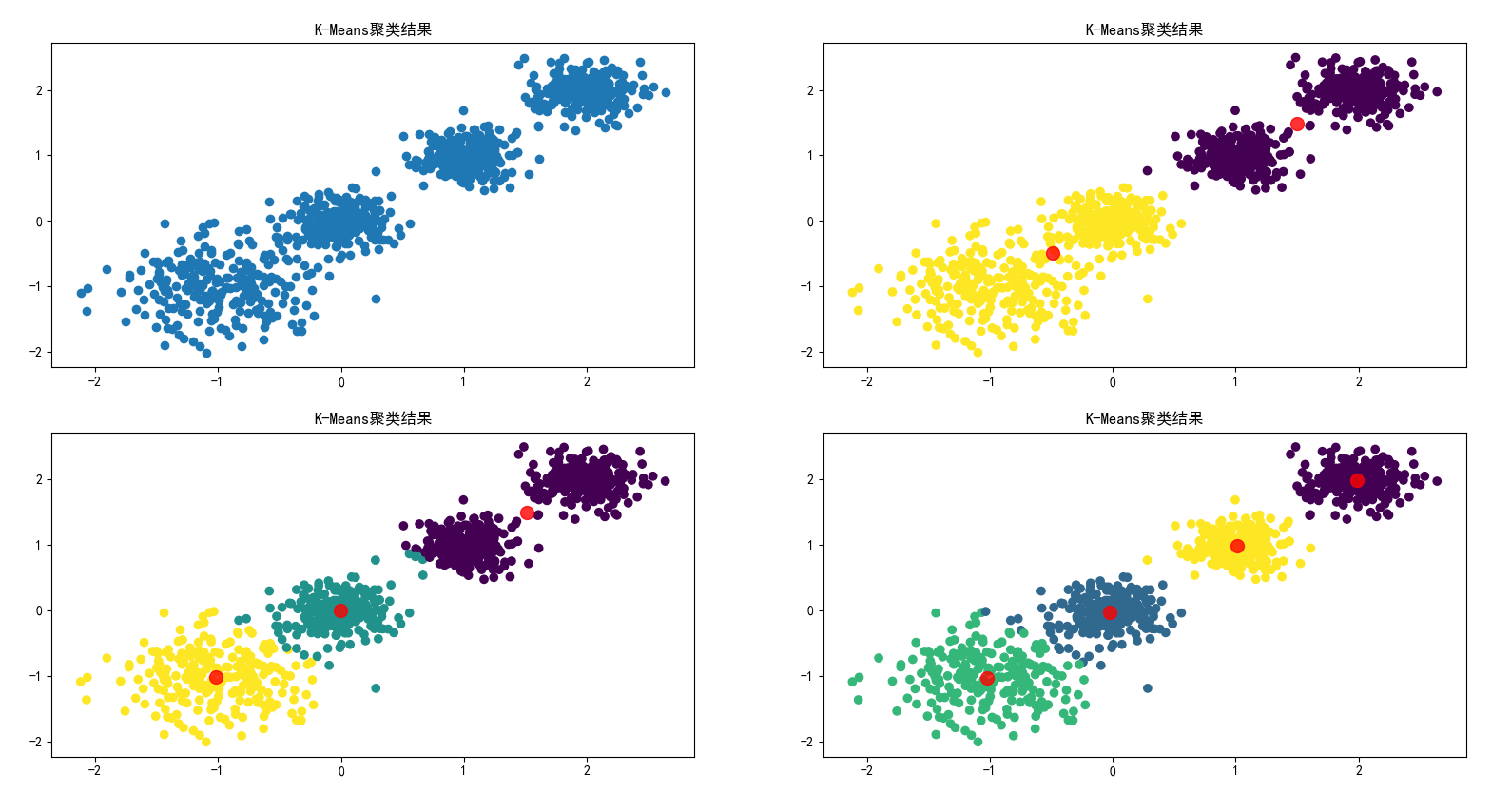
假设你是一家电子商务公司的数据分析师,公司希望根据客户的购买行为数据进行客户细分,以便制定更有针对性的营销策略。你需要使用K-means聚类算法对客户进行分组,并使用轮廓系数确定最佳K值。
数据集
我们将使用Kaggle上的"Customer Segmentation"数据集:
- 数据集链接: Mall Customer Segmentation Data | Kaggle
- 数据集包含客户ID、性别、年龄、年收入(千美元)和消费分数(1-100)
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import seaborn as sns
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('Mall_Customers.csv')
x = data[['Annual Income (k$)', 'Spending Score (1-100)']]
print(x.shape)
range_k = range(2, 11)
sc_list = []
center = []
k = 0
y_mean = 0
sc_max = 0
for i in range_k:
kmeans = KMeans(
n_clusters=i,
random_state=42,
n_init=10
)
# 训练
lab = kmeans.fit_predict(x)
y_means = kmeans.predict(x)
# 计算轮廓
sc = silhouette_score(x,
lab)
sc_list.append(sc)
# 获取聚类的中心点
centers = kmeans.cluster_centers_
# 绘制中心点
print(f'k={i}时轮廓系数:{sc:.3f}')
if sc > sc_max:
sc_max = sc
k = i
y_mean = y_means
center = centers
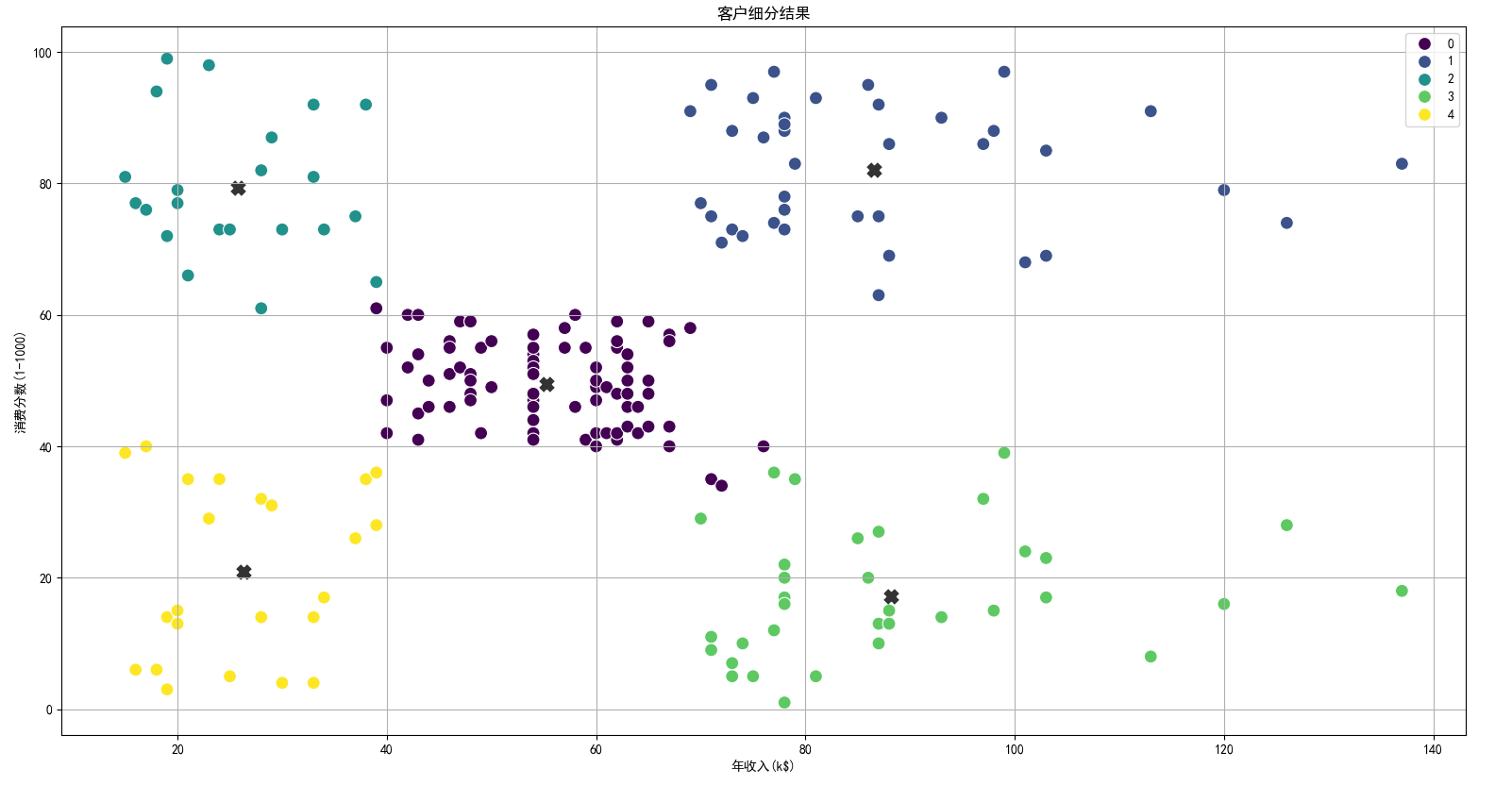
plt.figure(figsize=(10, 5))
sns.scatterplot(data=x,
x='Annual Income (k$)',
y='Spending Score (1-100)',
hue=y_mean,
palette='viridis',
s=100)
plt.scatter(center[:, 0],
center[:, 1],
c='black',
s=70,
alpha=0.8,
marker='x',
linewidths=5)
plt.grid(True)
plt.xlabel('年收入(k$)')
plt.ylabel('消费分数(1-1000)')
plt.title('客户细分结果')
plt.legend()
# 可视化
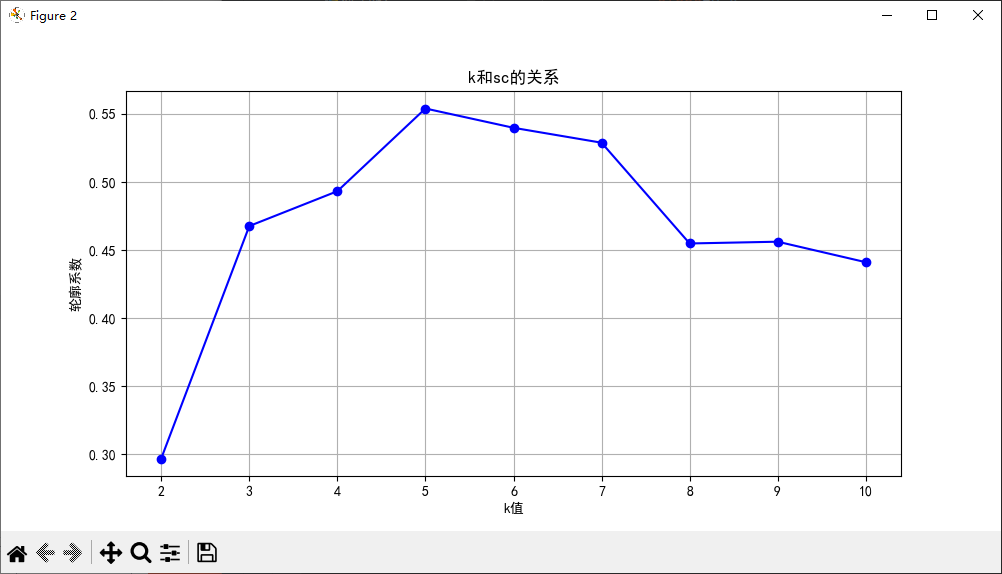
plt.figure(figsize=(10, 5))
plt.plot(range_k, sc_list, 'bo-')
plt.xlabel('k值')
plt.ylabel('轮廓系数')
plt.title('k和sc的关系')
plt.grid(True)
plt.show()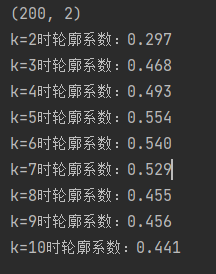


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









