






目录
1. 指令集分类
指令集为一套操作系统的指令集合,以及相关规范体系。是一种上层定义,汇编就是其具体的体现和实现。指令集分为以下两类:
- CISC 复杂指令集,以 x86 为代表(x86 在 PC 服务器领域具有统治地位)
- RISC 精简指令集,以 ARM MIPS 为代表(ARM 统治了手机和平板领域,MIPS 常用语手机、电脑之外的其他电子设备)
1.1. CISC
计算机编程很麻烦,例如用纸带打孔输入,因此计算机的设计者就考虑将 CPU 做的复杂一点,以简化这种本来就很麻烦的编程。因此有了 CISC 复杂指令集。x86 就是其中的典型代表,x86 的特点是:
- 指令向下兼容(这是其商业成功的重要因素之一!!!),缺点就是会让指令集越来越大、越来越复杂,功耗也更大(因此不适用于低功耗设备)
- 变长指令(MIPS 是等长的,只有 32 位),优点是节省空间、扩展性好,缺点是译码复杂
- 多种寻址方式
- 通用寄存器个数有限,x86-32 只有 8 个通用寄存器,x86-64 也只有 16 个寄存器
- 指令中,最多能有一个操作数在内存中,其他的操作数必须是立即数或者寄存器
1.2. RISC
历史原因,RISC 是 80 年代初发明的,那时整个计算机生态系统已经形成,编译器能力增强,就不需要 CPU 对外暴露过度复杂的指令集,因此有了 RISC 精简指令集。MIPS ARM 是 RISC 的代表,RISC 指令集特点是:
- 只关注一些简单常用的指令,因此简单轻量、高性能、功耗低
- 那些不常用的复杂指令,就依赖于编译器(即用软件来实现,而不是依赖于硬件的复杂指令),那时编译器已经比较强大
MIPS 特点:
- 以寄存器为中心。一出手就是 32 位(即寄存器是 32 位的),而且有 32 个通用寄存器
- 只有
load和store指令可以访问内存,其他指令只能操作寄存器和立即数(以寄存器为中心嘛) - 指令格式规范,长度一致(32 位),导致空间利用率不高,但是译码效率高
- 寻址方式非常简单
ARM 指令集特点:
- 大多数指令支持“条件执行”模式,能使得代码比较精简
- 具有 16 位压缩指令集,低功耗、低存储场景下很适用(ARM 在移动领域取得很大的成功,如 iphone 上的 A 系列处理器)
1.3. 两者区别
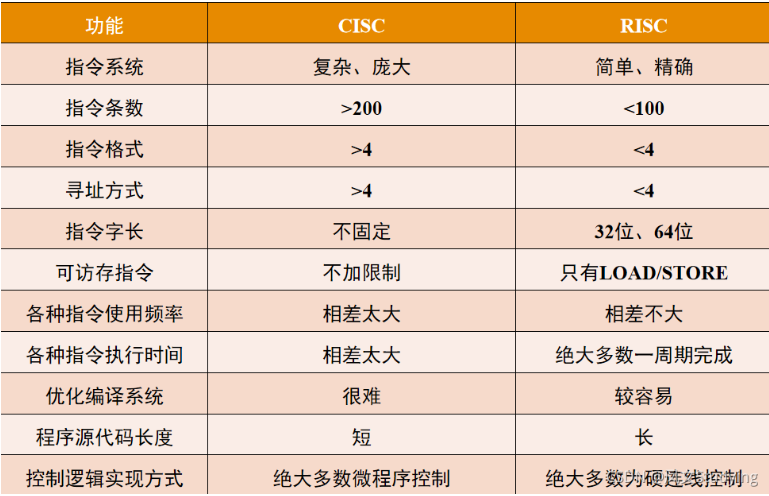
(1)指令系统。RISC主要设计经常使用的指令,让它们有简单高效的特色,对不常用的功能,常通过组合指令来完成,实现特殊功能的效率较低;CISC指令比较丰富,有专用指令来完成特殊功能,处理特殊任务的效率较高;
(2)对主存操作的限制。RISC对存储器操作有限制,使控制简单化;CISC机器存储器操作指令多,操作直接;
(3)编程的方便性。CISC对于汇编语言来说相对容易,可选指令多;RISC的汇编语言更困难
(4)寻址方式:RISC尽可能使用较少的寻址方式;CISC提倡通过丰富的寻址方式为用户编程提供更大的灵活性
(5)指令格式。RISC追求指令格式的规整性,一般使用等长的指令字来设计所有的指令格式;CISC指令格式因为要考虑更多的寻址方式可能引起的指令长度的变化等,设计起来相对要复杂;
(6)控制器设计。由于RISC指令格式规整、指令执行时间上的差异性很小,导致对应的CPU的控制器设计要简单,而且很多RISC可以使用硬布线方式(组合逻辑)高效实现;CISC的指令系统对应的控制信号复杂,大多采用微程序控制器方式。不管RISC和CISC都采用流水线技术提高效率。
2. 栈和堆的区别
2.1. 栈介绍
2.1.1. 生成机制
- 栈内存由编译器自动管理,通过函数调用分配和释放。
- 函数调用时,栈帧被压入栈,包含局部变量、参数和返回地址。
- 函数返回时,栈帧弹出,内存自动释放。
2.1.2. 触发场景
- 函数调用:每个函数调用生成新栈帧。
- 局部变量:非静态、非动态的变量在栈上分配。
栈由操作系统自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。参考如下代码。
void example() {
int a; // 栈上分配
char buffer[64];// 栈上分配
}其中函数中定义的局部变量按照先后定义的顺序依次压入栈中,也就是说相邻变量的地址之间不会存在其它变量。栈的内存地址生长方向与堆相反,由高到底,所以后定义的变量地址低于先定义的变量,比如上面代码中变量 s 的地址小于变量 b 的地址,p2 地址小于 s 的地址。栈中存储的数据的生命周期随着函数的执行完成而结束。
2.1.3. 特点
- 分配/释放速度快,但容量有限(易栈溢出)。
- 无需手动管理,由编译器控制生命周期。
2.2. 堆介绍
2.2.1. 生成机制
- 堆内存需显式申请和释放,生命周期由程序员控制。
- 通过动态内存管理函数手动操作。
2.2.2. 触发场景
2.2.2.1. C语言
malloc:分配未初始化的内存。calloc:分配并初始化为零的内存。realloc:调整已分配内存的大小。free:释放内存。
int* p = (int*)malloc(sizeof(int)); // 堆分配
free(p); // 释放2.2.2.2. C++
new:分配内存并调用构造函数。delete:调用析构函数并释放内存。new[]和delete[]:处理数组。
int* arr = new int[10]; // 堆分配数组
delete[] arr; // 释放堆的内存地址生长方向与栈相反,由低到高,但需要注意的是,后申请的内存空间并不一定在先申请的内存空间的后面,即 p2 指向的地址并不一定大于 p1 所指向的内存地址,原因是先申请的内存空间一旦被释放,后申请的内存空间则会利用先前被释放的内存,从而导致先后分配的内存空间在地址上不存在先后关系。堆中存储的数据若未释放,则其生命周期等同于程序的生命周期。
int main() {
// C 中用 malloc() 函数申请
char* p1 = (char *)malloc(10);
cout<<(int*)p1<<endl; //输出:00000000003BA0C0
// 用 free() 函数释放
free(p1);
// C++ 中用 new 运算符申请
char* p2 = new char[10];
cout << (int*)p2 << endl; //输出:00000000003BA0C0
// 用 delete 运算符释放
delete[] p2;
}
操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确地释放本内存空间。由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入空闲链表。
2.2.2.3. 栈溢出/堆内存泄
栈溢出:
- 避免过深递归或过大局部变量(如大数组)。
void risky() {
int huge[1000000]; // 可能栈溢出
}栈溢出危害为,通过相关栈溢出漏洞,修改相关返回值,进而修改并植入相关恶意代码。简单的参考文章如下:
使用vc6.0探讨栈溢出对代码进行攻击_c栈溢出攻击代码-CSDN博客
堆内存泄漏:
- 确保每次
malloc/new后都有对应的free/delete。 - 使用C++智能指针(如
std::unique_ptr、std::shared_ptr)自动管理堆内存。
野指针:
- 释放内存后,将指针置空
delete ptr;
ptr = nullptr; // 避免悬空指针2.2.3. 两者对比
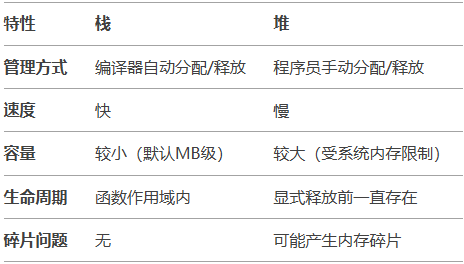
- 栈:函数调用和局部变量自动生成,高效但容量有限。
- 堆:通过
malloc/new显式生成,灵活但需手动管理。 - 核心函数:栈由编译器隐式处理;堆依赖
malloc/free(C)或new/delete(C++)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











