






学习目标:
前两天都讲的是django,今天和大家讲点好玩的,爬虫和数据可视化(内容和菜鸟教程基本完全一样,小编就跟着菜鸟学的·,所以这里小编也建议大家去看看菜鸟教程,就是最后可能会写一些案例教程)
学习内容:
首先讲解爬虫
根据去年比赛的要求,主要需要掌握的内容是urllid和requests,我们前面第二天讲解django的时候提到过requests,并且用它爬取过一些内容,而我们现在先开始学习urllid
Urllib :
包含以下几个模块:
1.Urllib.request 打开和读取url
2.Urllib.error 包含urllib.request抛出的异常
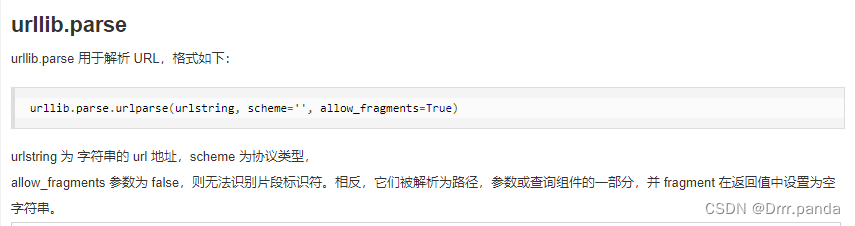
3.Urllib.parse 解析url
4.Urllib.rebotparser 解析robots.txt文件
Urllib.request 定义了一些打开uel的函数和类,保含授权验证,重定向,浏览器 cookies等
然后我们可以用urllib.request模拟浏览器的一个请求发起过程
所以我们可以用urrlliv=b.request 的urlopen方法去打开一个url,语法格式如下:
Urllib.request.urlopen(url,data=none,[timeout,]*,cafil=none,capath=none,cadefault=false,context=none)
注释:
1.url :url地址
2.Data:发送到服务器的其它数据对象,默认为none。
3.Timeout :设置访问超时时间
4.Cafile 和capath :cafile 为ca 证书,capath为 ca 证书的路径,使用https需要用到
5.Cadefault :已经被弃用
6.Context: ssl.SSLContext类型,用来指定SSL设置
实例:
From urllib.request import urlopen
MyURL=urlpoen(“https://www.runoob.com/”)
Print(myURL.read())
注释:以上代码是使用了urlopen 打开一个URL,然后使用read()函数获取html的实体代码
Read()是读取网页内容,我们可以指定读取的长度
实例:
From urllib.request import urlopen
myURL= urlopen (“https://www.runoob.com/”)
Print(myURL.read(300))
除了read之外,还可以用以下两个读取网页内容的函数:
Readline 读取文件的一行内容
实例:
From urllib.request import urlopen
MyURL =urlopen(“https://www.runoob.com/”)
Print(myURL.readine())
而readines 可以读取文件的全部内容,可以把读取的内容赋值给一个列表变量
From urllib.request import urlopen
myURL =urlopen(“https://www.runoob.com/”)
Lines =myURL.readines()
For line in lines:
Print(line)
如果想要将抓取的网页保存到本地,可以使用file weite()方法函数:
实例:
From urllib.request import urlopen
myURL= urlopen(“https://www.runoob.com/”)
F =open (“runoob_urllib-test.html”,wb)
Content =myURL.read()
F.weite(content)
f.close()
注释:执行以上代码就会在本地生成一个runnb_urllib_test.html文件,里面包含了https://www.runoob.com网页的内容
URL的编码与解码可以使用urllib.request.quote()与urllib.request.unquote()方法:
Import urllib.request
Encode_url=urllib.request.quote(“https://www.runoob.com/”) #编码
Print (encode_url)
Unencode_url =urllib,request.unquote(encode_url) #解码
Print(unencode_url)
输出结果:
https%3A//www.runoob.com/
https://www.runoob.com/
模拟头部信息
我们抓取头部信息一般需要对headers(网页头部信息)进行模拟,这时候要用到urllib.request.Request类:
Class urllib.request.Request.Request(url,data=None,origin_req_host=None,unverifiable=false,method=None)
1.Url :url 地址
2.Data:发送到服务器的其它数据对象,默认是None
3.Headers:HTTP请求的头部信息,字典格式
4.Origin_req_host:请求主机的地址,ip或者域名
5.Unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是false
6.Method:请求方法,如get.post
实例:
Import urllib.request
Import urllib.parse
Url =’https://www,reanoob,com/?s=’ #菜鸟教程搜索页面
Keyword =’python 教程’
Key_code =urllib.request.quote(keyword) #对请求进行编码
Url_all =url+key_code
Header ={
‘User-Agent’:’Mozilla/5.0 (x11;Fedora; Linux x86_64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/58.0.3029.110 Safari/537.36’
}
Request =urllib.request.Request(url_all,headers=header)
Request =urllib.request.Request(request).read()
Fh =open (“./urllib_test_runoob_search.html”,”wb”) #将文字写入到当前目录中
Fh.write(reponse)
Fh.close()
注释:当执行python的·时候,会在当前的目录生成urllib_test_runoob_search.html文件,打开urllib_test_runoob_search.html文件(可以使用浏览器打开)
表单post 传递数据,我们向创建一个表单,代码如下,我们使用phpdiamagnetic来获取表单的数据:
实例:
<html>
<head>
<meat charset=”utf-8”>
<title>菜鸟教程(runoob.com)urllib POST 测试</title>
</head>
<body>
<form action =”” method=”post” name =”myForm>
Name: <input type =”text” name=”name”><br>
Tab: <input type =”text”name=”tag”><br>
<input type =”submit” value=”提交 ”>
</from>
<hr>
<?php
//使用PHP来获取表单提交的数据,你可以换成其它的
If(isset ($_POST[‘name’]) &&$_POST[‘tag’]){
Echo $_POST[“name”].’,’ .$_POST[‘tag’];
}
?>
</body>
</html>


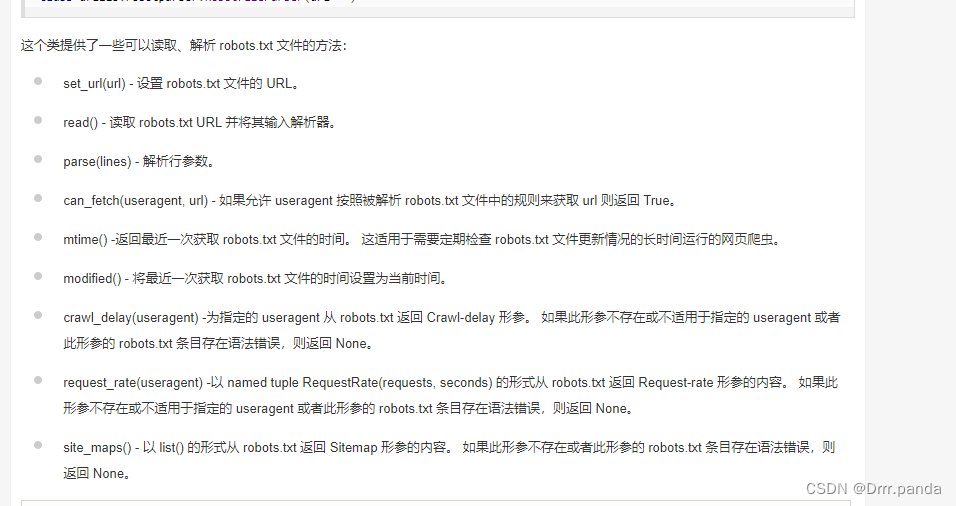
我们如果直接读取协议内容:

requests:
首先啊,python是自带requests模块的,这个模块主要是发送http请求用的,requests模块比urrlid模块更简洁一些
第二天的时候讲过怎么导入了吧,这里再讲一下
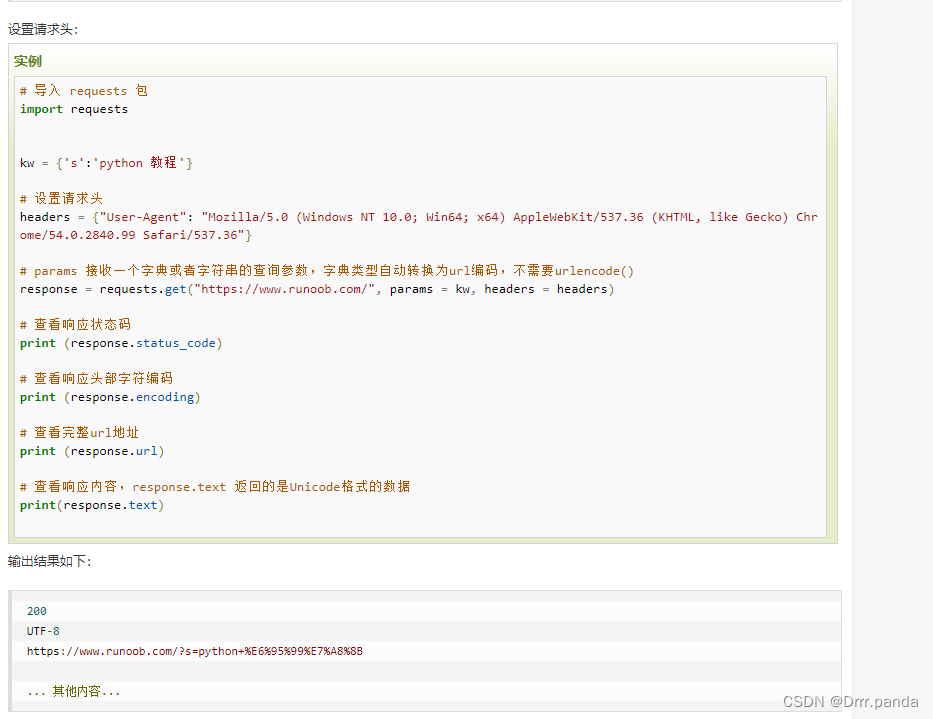
import requests # 导入requests包
x = requests.get('https://www.runoob.com/') # 发送请求
print(x.text) # 返回网页内容然后我们每次调用requests请求之后,会返回一个response对象,该对象包含了具体的响应信息
下面给大家表格
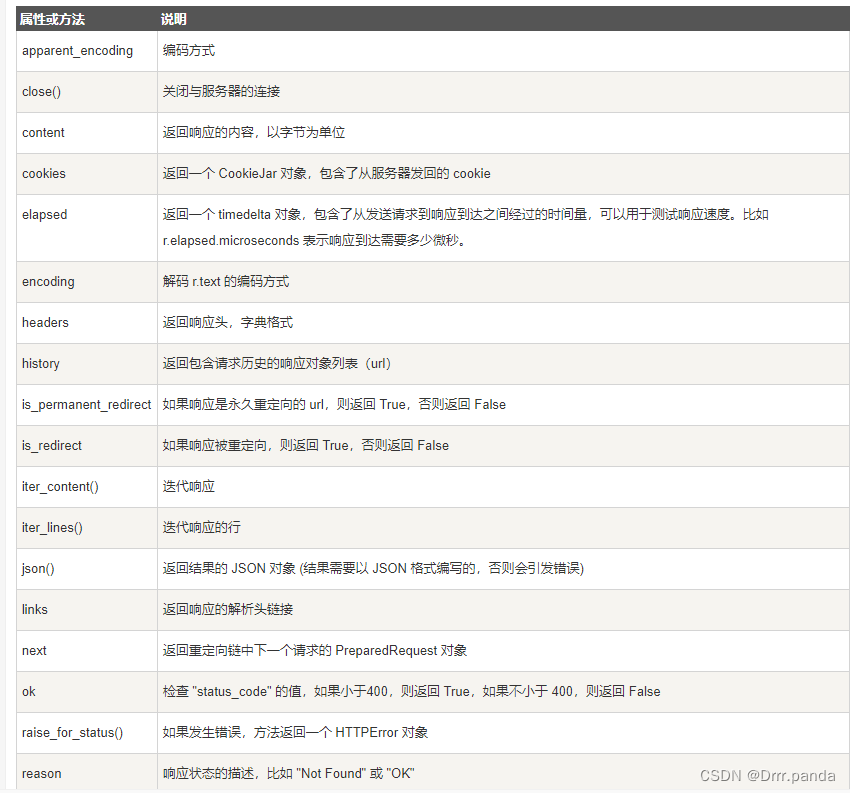
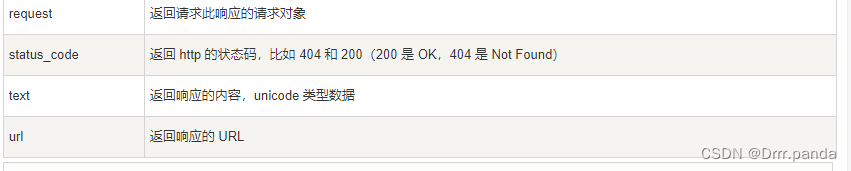
实例:
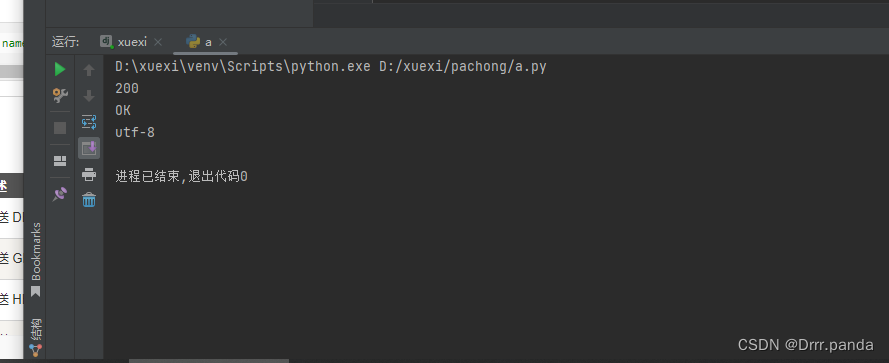
import requests # 导入requests包
x = requests.get('https://www.runoob.com/') # 发送请求
# 返回http 的状态码
print(x.status_code)
print(x.reason) # 响应状态描述
# 返回编码
print(x.apparent_encoding)
请求json的数据文件
import requests
x = requests.get('https://www.runoob.com/try/ajax/json_demo.json')
print(x.json())


import requests # 发送请求
x = requests.request('get', 'https://www.runoob.com/') # 发送请求
print(x.status_code) # 返回数据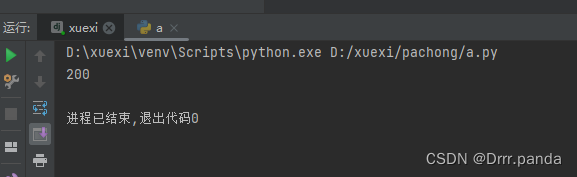
import requests
x=requests.post('')
print(x.text)结果:

import requests
myobj = {'fname': 'RUNOOB', 'lname': 'Boy'}
x = requests.post('https://www.runoob.com/try/ajax/demo_post2.php')
print(x.text)结果:
今天的爬虫就讲到这,明天突然想讲一下自动化和人工智能了,哎~
学习时间:
早八晚九
学习产出:
尽人事,听天命















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









