







这个题集涵盖了第十三届省赛所有组别的编程题,但 Python B 组的题解我写在了另一篇文章中:蓝桥杯【第13届省赛】Python B组 98.95分
测试链接:https://www.dotcpp.com/oj/train/1023/
刷题统计 100🏆
【题目描述】
小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目。请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n 题?
【输入格式】
输入一行包含三个整数 a, b 和 n
【输出格式】
输出一个整数代表天数。
【样例】
| 输入 | 输出 |
| 10 20 99 | 8 |
【评测用例规模与约定】
| 50% | |
| 100% |
【解析及代码】
import math
a, b, n = map(int, input().split())
# 每周做题数
num_per_week = 5 * a + 2 * b
# 花费周数
cost_week = n // num_per_week
# 经过 m 周后还差多少
undone = n - cost_week * num_per_week
# 总共花费天数
cost_day = cost_week * 7
if undone <= 5 * a:
cost_day += math.ceil(undone / a)
else:
undone -= 5 * a
cost_day += 5 + math.ceil(undone / b)
print(cost_day)修剪灌木 100🏆
【题目描述】
爱丽丝要完成一项修剪灌木的工作。有 N 棵灌木整齐的从左到右排成一排。爱丽丝在每天傍晚会修剪一棵灌木,让灌木的高度变为 0 厘米。爱丽丝修剪灌木的顺序是从最左侧的灌木开始,每天向右修剪一棵灌木。当修剪了最右侧的灌木后,她会调转方向,下一天开始向左修剪灌木。直到修剪了最左的灌木后再次调转方向。然后如此循环往复。灌木每天从早上到傍晚会长高 1 厘米,而其余时间不会长高。在第一天的早晨,所有灌木的高度都是 0 厘米。爱丽丝想知道每棵灌木最高长到多高。
【输入格式】
一个正整数 N ,含义如题面所述。
【输出格式】
输出 N 行,每行一个整数,第行表示从左到右第 i 棵树最高能长到多高。
【样例】
| 输入 | 输出 |
| 3 | 4 2 4 |
【评测用例规模与约定】
| 30% | |
| 100% |
【解析及代码】
分析一下样例,当输入 3 时输出是 4, 2, 4
| 早晨 | 1 1 1 | 1 2 2 | 2 1 3 | 3 1 1 | 4 1 2 |
| 傍晚 | 0 1 1 | 1 0 2 | 2 1 0 | 3 0 1 | 0 1 2 |
从表中可以看到:灌木最高高度 = 最长裁剪时间间隔 + 1
n = int(input())
for i in range(n):
# 向左裁剪 -> 向右裁剪, 向右裁剪 -> 向左裁剪
print(2 * max(i, n - i - 1))
X进制减法 100🏆
【题目描述】
进制规定了数字在数位上逢几进一。
X 进制是一种很神奇的进制,因为其每一数位的进制并不固定!例如说某种 X 进制数,最低数位为二进制,第二数位为十进制,第三数位为八进制,则 X 进制数 321 转换为十进制数为 65。
现在有两个 X 进制表示的整数 A 和 B,但是其具体每一数位的进制还不确定,只知道 A 和 B 是同一进制规则,且每一数位最高为 N 进制,最低为二进制。请你算出 A − B 的结果最小可能是多少。
请注意,你需要保证 A 和 B 在 X 进制下都是合法的,即每一数位上的数字要小于其进制。
【输入格式】
第一行一个正整数 N,含义如题面所述。
第二行一个正整数 Ma,表示 X 进制数 A 的位数。
第三行 Ma 个用空格分开的整数,表示 X 进制数 A 按从高位到低位顺序各个数位上的数字在十进制下的表示。
第四行一个正整数 Mb,表示 X 进制数 B 的位数。
第五行 Mb 个用空格分开的整数,表示 X 进制数 B 按从高位到低位顺序各个数位上的数字在十进制下的表示。
请注意,输入中的所有数字都是十进制的。
【输出格式】
输出一行一个整数,表示 X 进制数 A − B 的结果的最小可能值转换为十进制后再模 1000000007 的结果。
【样例】
| 输入 | 输出 | 说明 |
| 11 3 10 4 0 3 1 2 0 | 94 | 当进制为:最低位 2 进制,第二数位 5 进制, 第三数位 11 进制时,减法得到的差最小。 此时 A 在十进制下是 108, B 在十进制下是 14,差值是 94。 |
【评测用例规模与约定】
| 30% | N ≤ 10;Ma, Mb ≤ 8 |
| 100% | 2 ≤ N ≤ 1000;1 ≤ Ma, Mb ≤ 100000;A ≥ B |
【解析及代码】
以 a 为 [10, 2, 1],b 为 [1, 4, 0] 为例
- 最小进制:与 a, b 对应位置的数字有关,依次为 [11, 5, 2]
- δ = a - b:设各数位进制依次为 [x, y, z],则 [9, -2, 1] = ((9y - 2)z + 1),而这时 z 取最大进制还是最小进制,就由 9y - 2(高位换算到低位)的正负决定了;最高位的进制不用管
- a ≥ b:因为这个条件的存在,所以 δ 的前 n 位换算后总是大于等于 0,所以一直取最小进制就行了
mod = 10 ** 9 + 7
_ = input()
_, a = input(), list(map(int, input().split()))
_, b = input(), list(map(int, input().split()))
# a >= b, 可能需要补齐
b = (len(a) - len(b)) * [0] + b
# 最小进制
minbase = [max(max(ij) + 1, 2) for ij in zip(a, b)]
# a - b
delta = [i - j for i, j in zip(a, b)]
# 记录每一时刻的 最小、最大
res = delta[0]
# 高位换算到低位
for i in range(1, len(minbase)):
res = (res * minbase[i] + delta[i]) % mod
print(res)统计子矩阵 63🏆
【问题描述】
给定一个 N × M 的矩阵 A,请你统计有多少个子矩阵 (最小 1 × 1,最大 N × M) 满足子矩阵中所有数的和不超过给定的整数 K?
【输入格式】
第一行包含三个整数 N, M 和 K.
之后 N 行每行包含 M 个整数,代表矩阵 A
【输出格式】
一个整数代表答案
【样例】
| 输入 | 输出 | 说明 |
| 3 4 10 1 2 3 4 5 6 7 8 9 10 11 12 | 19 | 满足条件的子矩阵一共有 19,包含: 大小为 1 × 1 的有 10 个 大小为 1 × 2 的有 3 个 大小为 1 × 3 的有 2 个 大小为 1 × 4 的有 1 个 大小为 2 × 1 的有 3 个 |
【评测用例规模与约定】
| 30% | N, M ≤ 20 |
| 70% | N, M ≤ 100 |
| 100% | 1 ≤ N, M ≤ 500; 0 ≤ A ij ≤ 1000; 1 ≤ K ≤ 250000000 |
【解析及代码】
如果矩阵只有 1 列,通过两层 for 循环枚举 top 和 bottom,可遍历所有子矩阵
将该列处理成前缀和的形式 array[i][0],那么上界 t 下界 b 的子矩阵之和为 array[b][0] - array[t-1][0]
再通过一层 for 枚举子矩阵的右边界 r,找到满足子矩阵之和不超过 K 的最小 l(使子矩阵最大)
那么在固定 t, b, r 的情况下,满足条件的子矩阵有 r - l + 1 个
n, m, k = map(int, input().split())
array = [list(map(int, input().split())) for _ in range(n)]
# 每一列 -> 前缀和
for r in range(1, n):
for c in range(m):
array[r][c] += array[r - 1][c]
# 解析前缀和的函数
get_col = lambda t, b, c: array[b][c] - (array[t - 1][c] if t > 0 else 0)
cnt = 0
# 枚举子矩阵的上下边界
for t in range(n):
for b in range(t, n):
# 初始化双指针
l = sum_ = 0
for r in range(m):
# 增添右边界所在列
sum_ += get_col(t, b, r)
while sum_ > k:
# 减少左边界所在列
sum_ -= get_col(t, b, l)
l += 1
# 右边界固定, 左边界再右移仍满足条件 (生成新的子矩阵)
cnt += r - l + 1
print(cnt)积木画 100🏆
【问题描述】
小明最近迷上了积木画,有这么两种类型的积木,分别为 I 型(大小为 2 个单位面积)和 L 型(大小为 3 个单位面积):
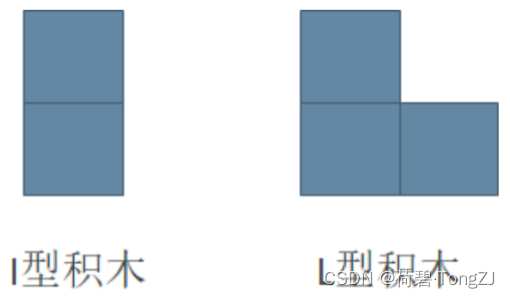
同时,小明有一块面积大小为 2 × N 的画布,画布由 2 × N 个 1 × 1 区域构成。小明需要用以上两种积木将画布拼满,他想知道总共有多少种不同的方式?积木可以任意旋转,且画布的方向固定。
【输入格式】
输入一个整数 N,表示画布大小
【输出格式】
输出一个整数表示答案。由于答案可能很大,所以输出其对 1000000007 取模后的值
【样例】
| 输入 | 输出 | 说明 |
| 3 | 5 |
|
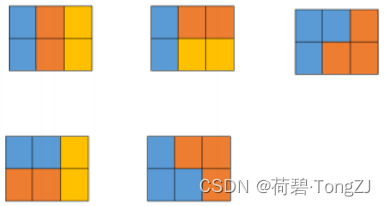
【评测用例规模与约定】
| 100% | 1 ≤ N ≤ 10000000 |
【解析及代码】
把画布看成 N 行 2 列,一行一行来进行拼接,一波动态规划
用 0 表示留空,用 1 表示占用,那么仅用 0 ~ 3 的二进制即可表示每一行:
- 用以下的拼接方式来确保:上一行总是铺满
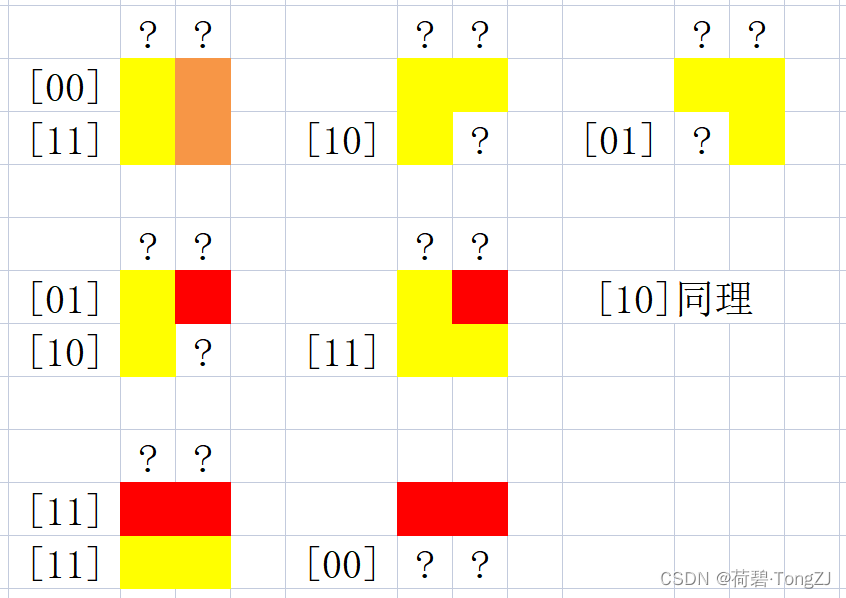
- 最后输出答案时,应当保证最后一行占满
n = int(input())
mod = 1000000007
s00, s01, s10, s11 = range(4)
# 首行留空 (00) / 铺设 I 型积木 (11)
cur = (1, 0, 0, 1)
for _ in range(n - 1):
cur = (
# 当前行不做动作
cur[s11],
# 铺设 L 型 (占满上一行) + 铺设 I 型 (补满上一行)
(cur[s00] + cur[s10]) % mod,
(cur[s00] + cur[s01]) % mod,
# 两个 I 型竖直铺设 + L 型铺满当前行、补全上一行 + 当前行 I 型横铺
sum(cur) % mod
)
# 输出最后一行占满的结果
print(cur[s11])
扫雷 42🏆
【问题描述】
小明最近迷上了一款名为《扫雷》的游戏。其中有一个关卡的任务如下, 在一个二维平面上放置着 n 个炸雷,第 i 个炸雷 表示在坐标
处存在一个炸雷,它的爆炸范围是以半径为
的一个圆。
为了顺利通过这片土地,需要玩家进行排雷。玩家可以发射 m 个排雷火箭,小明已经规划好了每个排雷火箭的发射方向,第 j 个排雷火箭 表示这个排雷火箭将会在
处爆炸,它的爆炸范围是以半径为
的一个圆,在其爆炸范围内的炸雷会被引爆。同时,当炸雷被引爆时,在其爆炸范围内的炸雷也会被引爆。现在小明想知道他这次共引爆了几颗炸雷?
你可以把炸雷和排雷火箭都视为平面上的一个点。一个点处可以存在多个炸雷和排雷火箭。当炸雷位于爆炸范围的边界上时也会被引爆。
【输入格式】
输入的第一行包含两个整数 n、m.
接下来的 n 行,每行三个整数 ,表示一个炸雷的信息。
再接下来的 m 行,每行三个整数 ,表示一个排雷火箭的信息。
【输出格式】
输出一个整数表示答案
【样例】
| 输入 | 输出 | 说明 |
| 2 1 2 2 4 4 4 2 0 0 5 | 2 | 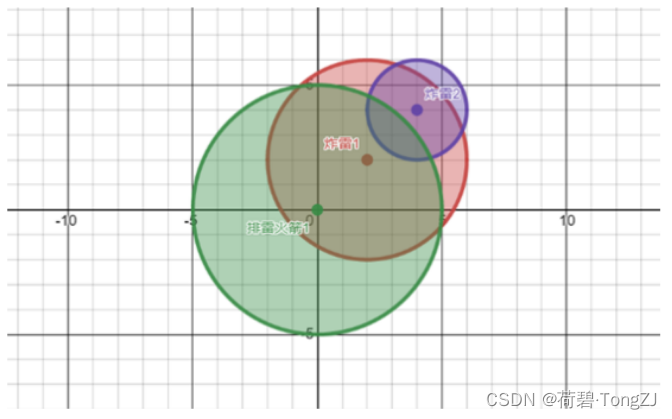 |
【评测用例规模与约定】
| 40% | |
| 100% |
【解析及代码】
定义 Mine 这个类,使用 __sub__ 方法定义两个 Mine 实例相减时的行为 —— 返回两者间的距离
编写函数 reach,用于寻找当前的火箭 / 炸雷所能引爆的炸雷
同时将找到的炸雷标记为不存在,并入队;再逐一地取出队列中的炸雷,重复以上操作
import bisect
class Mine:
def __init__(self):
x, y, r = map(int, input().split())
# 使用复数记录 x-y 坐标
self.z = x + y * 1j
self.r = r
def __sub__(self, other):
# 定义两个炸雷相减时的行为
# 距离: z1 - z2 的模
return abs(self.z - other.z)
n_mine, n_rocket = map(int, input().split())
mines = [Mine() for _ in range(n_mine)]
rockets = [Mine() for _ in range(n_rocket)]
# 记录未爆炸的炸雷
curmine = list(range(n_mine))
def reach(mine):
# mine: 排雷火箭 / 炸雷
queue = []
# 利用地雷的存在状态, 减少计算量
for i in curmine.copy():
if mine - mines[i] <= mine.r:
# 可被引爆的炸雷入队, 利用二分法查找炸雷的位置并删除
queue.append(i)
curmine.pop(bisect.bisect_left(curmine, i))
return queue
# 启动链式引爆
for q in map(reach, rockets):
while q: q += reach(mines[q.pop()])
print(n_mine - len(curmine))李白打酒 100🏆
【问题描述】
话说大诗人李白,一生好饮。幸好他从不开车。
一天,他提着酒壶,从家里出来,酒壶中有酒 2 斗。他边走边唱:
无事街上走,提壶去打酒。
逢店加一倍,遇花喝一斗。
这一路上,他一共遇到店 N 次,遇到花 M 次。已知最后一次遇到的是花, 他正好把酒喝光了。
请你计算李白这一路遇到店和花的顺序,有多少种不同的可能?
注意:壶里没酒 (0 斗) 时遇店是合法的,加倍后还是没酒;但是没酒时遇花是不合法的。
【输入格式】
第一行包含两个整数 N 和 M
【输出格式】
输出一个整数表示答案。由于答案可能很大,输出模 1000000007 的结果
【样例】
| 输入 | 输出 | 说明 |
| 5 10 | 14 | 如果我们用 0 代表遇到花, 1 代表遇到店,14 种顺序如下: 010101101000000 |
【评测用例规模与约定】
| 40% | 1 ≤ N, M ≤ 10 |
| 100% | 1 ≤ N, M ≤ 100 |
【解析及代码】
三维动态规划,每个元素代表的是指定条件下的情况种数:
- 第一维:遇店次数(0 ~ N)
- 第二维:遇花次数(0 ~ M-1),因为最后一次是遇花,所以只需规划 M-1 次遇花
- 第三维:酒的斗数(0 ~ M),因为最后酒刚好喝完,在任意时刻如果酒的斗数高于遇店的次数,那么最后酒都不可能喝完,不需要理
dp[n][m][x] 表示遇店 n 次、遇花 m 次、剩 x 斗酒的情况种数
遇店的状态传递是:dp[n-1][m] → dp[n][m]
遇花的状态传递是:dp[n][m-1] → dp[n][m]
为了应付 n-1, m-1 < 0 的情况(索引越界),分成三组代码进行状态转移
因为最后一次是遇花,而且酒刚好喝完,所以 dp[-1][-1][1] 即为答案
mod = 1000000007
# 遇店次数, 遇花次数
double, sub = map(int, input().split())
# 酒的上限: 遇店次数
max_wine = max(sub, 2)
# 刚开始有酒 2 斗, 最后一次是遇花
dp = [[[0] * (1 + max_wine) for _ in range(sub)] for _ in range(double + 1)]
# 刚开始有酒 2 斗, 从一开始就一直遇花
for t_s in range(min((2, sub)) + 1):
dp[0][t_s][2 - t_s] = 1
# 从一开始就一直遇店
for t_d in range(double):
wine = 2 << t_d
# 超过上限的不理
if wine > max_wine: break
dp[t_d][0][wine] = 1
# 状态转移
for t_s in range(1, sub):
for t_d in range(1, double + 1):
# 上一个状态 -> 遇花 -> 当前状态
dp[t_d][t_s][:-1] = dp[t_d][t_s - 1][1:]
# 保证遇店后酒不超过上限
for wine in range(max_wine // 2 + 1):
# 上一个状态 -> 遇店 -> 当前状态
dp[t_d][t_s][wine * 2] += dp[t_d - 1][t_s][wine]
# 因为最后一次遇花, 所以酒剩一斗
print(dp[-1][-1][1] % mod)
砍竹子
【问题描述】
这天,小明在砍竹子,他面前有 n 棵竹子排成一排,一开始第 i 棵竹子的高度为 .
他觉得一棵一棵砍太慢了,决定使用魔法来砍竹子。魔法可以对连续的一段相同高度的竹子使用,假设这一段竹子的高度为 H,那么使用一次魔法可以把这一段竹子的高度都变为 ,其中 ⌊x⌋ 表示对 x 向下取整。小明想知道他最少使用多少次魔法可以让所有的竹子的高度都变为 1。
【输入格式】
第一行为一个正整数 n,表示竹子的棵数。
第二行共 n 个空格分开的正整数 ,表示每棵竹子的高度。
【输出格式】
一个整数表示答案
【样例】
| 输入 | 输出 | 说明 |
| 6 2 1 4 2 6 7 | 5 | 其中一种方案: 2 1 4 2 6 7 → 2 1 4 2 6 2 |
【评测用例规模与约定】
| 20% | |
| 100% | |
【解析及代码】
求和 100🏆
【问题描述】
给定 n 个整数 ,求它们两两相乘再相加的和,即:
【输入格式】
输入的第一行包含一个整数 n 。
第二行包含 n 个整数 。
【输出格式】
输出一个整数 S,表示所求的和。请使用合适的数据类型进行运算
【样例】
| 输入 | 输出 |
| 4 1 3 6 9 | 117 |
【评测用例规模与约定】
| 30% | 1 ≤ n ≤ 1000,1 ≤ ai ≤ 100 |
| 100% | 1 ≤ n ≤ 200000,1 ≤ ai ≤ 1000 |
【解析及代码】
什么数据类型都不需要,优化第二个求和就行了
n = int(input())
array = list(map(int, input().split()))
result, summary = 0, 0
for i in range(n - 2, -1, -1):
summary += array[i + 1]
result += summary * array[i]
print(result)选数异或 45🏆
【问题描述】
给定一个长度为 n 的数列 和一个非负整数 x,给定 m 次查询, 每次询问能否从某个区间
中选择两个数使得他们的异或等于 x 。
【输入格式】
输入的第一行包含三个整数 n, m, x 。
第二行包含 n 个整数 。
接下来 m 行,每行包含两个整数 表示询问区间
。
【输出格式】
对于每个询问, 如果该区间内存在两个数的异或为 x 则输出 yes, 否则输出 no
【样例】
| 输入 | 输出 | 说明 |
| 4 4 1 1 2 3 4 1 4 1 2 2 3 3 3 | yes no yes no | 显然整个数列中 只有 2, 3 的异或为 1 |
【评测用例规模与约定】
| 20% | |
| 40% | |
| 100% |
【解析及代码】
异或的运算规则是相同为 0 相异为 1,那么当 x = 0 的时候,任何区间内都有 a ^ a = 0,不管怎样询问都是 yes
对于每一个数 来说,可以搜索离其最近的一个数
,使得两者异或为 x
创建一个前驱列表 pre,pre[i] 表示在 [0, i - 1] 区间内能与 异或得到 x 的数 的索引
则查询结果可表示为,pre[l-1, r] 内,是否有大于等于 l-1 的值
n, m, x = map(int, input().split())
array = list(map(int, input().split()))
if x == 0:
for _ in range(m):
l, r = map(int, input().split())
print('yes')
else:
# 对每个位置的数, 可与其异或 得到目标的 最近的数
pre = [-1] * n
# 搜索每个数的 前驱
for i in range(1, n):
for j in range(i - 1, -1, -1):
if array[i] ^ array[j] == x:
pre[i] = j
break
# 开始询问
for _ in range(m):
l, r = map(int, input().split())
l -= 1
print('yes' if max(pre[l: r]) >= l else 'no')
爬树的甲壳虫 53🏆
【问题描述】
有一只甲壳虫想要爬上一颗高度为 n 的树,它一开始位于树根,高度为 0,当它尝试从高度 i − 1 爬到高度为 i 的位置时有 的概率会掉回树根,求它从树根爬到树顶时,经过的时间的期望值是多少。
【输入格式】
输入第一行包含一个整数 n 表示树的高度。
接下来 n 行每行包含两个整数 ,用一个空格分隔,表示
【输出格式】
输出一行包含一个整数表示答案,答案是一个有理数,请输出答案对质数 998244353 取模的结果。其中有理数 对质数 P 取模的结果是整数 c 满足 0 ≤ c < P 且 c · b ≡ a (mod P)。
【样例】
| 输入 | 输出 |
| 1 1 2 | 2 |
【评测用例规模与约定】
| 20% | |
| 50% | |
| 100% |
【解析及代码】
用 E[i] 表示甲壳虫到达高度 i 的期望次数,显然有 E[0] = 0
能传递到 E[i] 的状态只有 E[i-1],但是有无穷多种可能,可得分布列:
| 次数 | ... | ... | ||||
| 概率 |
得状态传递方程:
因为除法操作的存在,与求余操作一起时会使结果出现错误
根据费马小定理有:
mod = 998244353
n = int(input())
# E[0] = 0
result = 0
for _ in range(n):
x, y = map(int, input().split())
result = (result + 1) * y % mod * pow(y - x, mod - 2, mod) % mod
print(result)青蛙过河 77🏆
【问题描述】
小青蛙住在一条河边,它想到河对岸的学校去学习。小青蛙打算经过河里的石头跳到对岸。
河里的石头排成了一条直线,小青蛙每次跳跃必须落在一块石头或者岸上。不过,每块石头有一个高度,每次小青蛙从一块石头起跳,这块石头的高度就会下降 1,当石头的高度下降到 0 时小青蛙不能再跳到这块石头上(某次跳跃后使石头高度下降到 0 是允许的)。
小青蛙一共需要去学校上 x 天课,所以它需要往返 2x 次。当小青蛙具有一个跳跃能力 y 时,它能跳不超过 y 的距离。
请问小青蛙的跳跃能力至少是多少才能用这些石头上完 x 次课。
【输入格式】
输入的第一行包含两个整数 n, x,分别表示河的宽度和小青蛙需要去学校的天数。请注意 2x 才是实际过河的次数。
第二行包含 n − 1 个非负整数 ,其中 Hi > 0 表示在河中与小青蛙的家相距 i 的地方有一块高度为
的石头,
表示这个位置没有石头。
【输出格式】
输出一行,包含一个整数,表示小青蛙需要的最低跳跃能力。
【样例】
| 输入 | 输出 | 说明 |
| 5 1 1 0 1 0 | 4 | 由于只有两块高度为 1 的石头,所以往返只能各用一块。 第 1 块石头和对岸的距离为 4,如果小青蛙的跳跃能力为 3 则无法满足要求。所以小青蛙最少需要 4 的跳跃能力。 |
【评测用例规模与约定】
| 30% | |
| 60% | |
| 100% |
【解析及代码】
往返 2x 次,等价于 2x 只青蛙同时从左到右过河
总的思路就是 贪心 + 二分答案,验证函数的思路是:
- 记录每个位置的青蛙数量,青蛙能跳多远就跳多远
- 有青蛙没法跳出某个位置时,该跳跃能力不可行
n, x = map(int, input().split())
x *= 2
# 石头高度: 补上起点 (0)、终点 (2x)
available = [0] + list(map(int, input().split())) + [x]
def check(pace):
# 记录对应位置剩余的青蛙
member = [x] + [0] * n
# 当前石头高度
avai = available.copy()
# 枚举青蛙所在位置
for i in range(n):
# 能跳多远跳多远
for j in range(min(i + pace, n), i, -1):
# 移动的青蛙数
move = min(member[i], avai[j])
# 更新青蛙位置, 石头高度
member[i] -= move
if j < n:
member[j] += move
avai[j] -= move
# 有青蛙没法跳出该位置
if member[i]: return False
return True
if check(1):
print(1)
else:
# 二分答案
l, r = 1, n
while l + 1 < r:
mid = (l + r) // 2
if check(mid): r = mid
else: l = mid
print(r)时间超限,点到为止
扫描游戏 72🏆
【问题描述】
有一根围绕原点 O 顺时针旋转的棒 OA,初始时指向正上方(Y 轴正向)。 在平面中有若干物件,第 i 个物件的坐标为 ,价值为 zi。当棒扫到某个物件时,棒的长度会瞬间增长
,且物件瞬间消失(棒的顶端恰好碰到物件也视为扫到),如果此时增长完的棒又额外碰到了其他物件,也按上述方式消去 (它和上述那个点视为同时消失)。
如果将物件按照消失的时间排序,则每个物件有一个排名,同时消失的物件排名相同,请输出每个物件的排名,如果物件永远不会消失则输出 −1。
【输入格式】
输入第一行包含两个整数 n、L,用一个空格分隔,分别表示物件数量和棒的初始长度
接下来 n 行每行包含第三个整数
【输出格式】
输出一行包含 n 整数,相邻两个整数间用一个空格分隔,依次表示每个物件的排名
【样例】
| 输入 | 输出 |
| 5 2 0 1 1 0 3 2 4 3 5 6 8 1 -51 -33 2 | 1 1 3 4 -1 |
【评测用例规模与约定】
| 30% | |
| 60% | |
| 100% |
【解析及代码】
在 x-y 坐标系上顺时针旋转,对应极坐标的 θ 的变化范围是
转换成 y-x 坐标系后,变成逆时针旋转,而且极坐标的起点也发生变化,θ 的变化范围是 ,从而写出 x-y 坐标转换为极坐标的函数
使用 list 记录物件,不改变次序;使用 dict 对物件进行排序
因为 dict 已经对极坐标进行排序了 (θ 优先级高于 r),所以一个 while 加两个 for 就完成了
import cmath
class Obj:
def __init__(self):
x, y, self.value = map(int, input().split())
# x-y 坐标系上顺时针 -> y-x 坐标系上逆时针
# y-x 坐标系 -> 极坐标
self.r, self.phi = cmath.polar(y + x * 1j)
# φ: [-pi, pi] -> [0, 2 pi]
self.phi += cmath.tau if self.phi < 0 else 0
# 该物件的排名
self.index = -1
def __bool__(self):
# 排名 -1 代表仍存在
return self.index == -1
def __repr__(self):
# 规定被 print 的行为
return str(self.index)
n, length = map(int, input().split())
obj_list = [Obj() for _ in range(n)]
obj_dict = {}
for obj in obj_list:
obj_dict.setdefault(obj.phi, []).append(obj)
# 字典的 value 按 r 升序排序
for phi in obj_dict:
obj_dict[phi].sort(key=lambda obj: obj.r)
# 字典的 key 按 φ 升序排序
keys = sorted(obj_dict)
cnt = 1
while True:
# 是否全部完成 (没有出现任何吞噬)
all_done = True
# 开始顺时针旋转
for phi in keys:
step_flag = 0
# 尝试就近吞噬, 判断 物品存在 (调用 __bool__)
for obj in filter(bool, obj_dict[phi]):
# 吞噬成功: 距离满足
if obj.r <= length:
# 记录排名, 更新长度
obj.index = cnt
length += obj.value
# 更新 cnt 步进标记
step_flag += 1
# cnt 步进, 继续旋转
if step_flag:
cnt += step_flag
all_done = False
if all_done: break
# 因为 Obj 类定义了 __repr__, 所以直接 print
print(*obj_list)数的拆分 31🏆
【问题描述】
给定 T 个正整数 ,分别问每个
能否表示为
的形式,其中
为正整数,
为大于等于 2 的正整数。
【输入格式】
输入第一行包含一个整数 T 表示询问次数
接下来 T 行,每行包含一个正整数
【输出格式】
对于每次询问, 如果 能够表示为题目描述的形式则输出 yes,否则输出 no
【样例】
| 输入 | 输出 | 说明 |
| 7 2 6 12 4 8 24 72 | no no no yes yes no yes | 第 4,5,7 个数分别可以表示为: |
【评测用例规模与约定】
| 10% | |
| 30% | |
| 60% | |
| 100% |
【解析及代码】
每一个整数 N 都可以被唯一地分解成 的形式,其中
是质数
当 是偶数的时候,
有整数解;当
是奇数的时候,仅当
的时
有整数解
所以满足当 时,有
,所以有
import math
def try_div(n):
i, bound = 2, math.sqrt(n)
while i <= bound:
if n % i == 0:
cnt = 1
n //= i
while n % i == 0:
cnt += 1
n //= i
if cnt == 1: return False
bound = math.sqrt(n)
i += 1
return n == 1
for _ in range(int(input())):
print('yes' if try_div(int(input())) else 'no')
假设最坏情况下, 和
均为质数,而且二者相近,此时为了可以求解其中之一,试除法的枚举范围是
而当出现了 时,其它质因数必满足
所以只需对试除法的剩余部分进行检查,是否可开方 / 开立方便可确认答案
import math
def is_power(n):
for p in 2, 3:
x = math.pow(n, 1 / p)
if math.ceil(x) == math.floor(x): return True
return False
def try_div(n):
# 开 5 次方 1e6 次消耗 0.24 s
# 1e18 ^ 0.2 约为 4000
i, bound = 2, min(math.sqrt(n), 4000)
while i <= bound:
if n % i == 0:
cnt = 1
n //= i
while n % i == 0:
cnt += 1
n //= i
if cnt == 1: return False
bound = min(math.sqrt(n), 4000)
i += 1
return n
for _ in range(int(input())):
n = try_div(int(input()))
print('yes' if n and is_power(n) else 'no')推导部分和 39🏆
【问题描述】
对于一个长度为 N 的整数数列 ,小蓝想知道下标 l 到 r 的部分和
是多少?
然而,小蓝并不知道数列中每个数的值是多少,他只知道它的 M 个部分和的值。其中第 i 个部分和是下标 到
的部分和是
。
【输入格式】
第一行包含 3 个整数 N、M 和 Q。分别代表数组长度、已知的部分和数量和询问的部分和数量。
接下来 M 行,每行包含 3 个整数
接下来 Q 行,每行包含 2 个整数 l 和 r ,代表一个小蓝想知道的部分和。
【输出格式】
对于每个询问,输出一行包含一个整数表示答案。如果答案无法确定,输出 UNKNOWN
【样例】
| 输入 | 输出 |
| 5 3 3 1 5 15 4 5 9 2 3 5 1 5 1 3 1 2 | 15 6 UNKNOWN |
【评测用例规模与约定】
| 10% | |
| 20% | |
| 30% | |
| 40% | |
| 60% | |
| 100% | |
【解析及代码】
假设已知部分和:[1, 4] (3),[5, 6] (2),[4, 6] (6),[2, 3] (1)
定义正区间 [4, 6] (6) 等价于负区间 [6, 4] (-6)
则 [1, 1] 的部分和等于:[1, 4] + [5, 6] + [6, 4] + [3, 2] = 3 + 2 - 6 - 1 = -2
如果把每个区间的部分和看成有向图的边权,区间的起始点则是有向图的顶点,平滑处理后,定义:
- 正区间:边 [l, r+1) 表示 [l, r] 的部分和
- 负区间:边 [r+1, l) 表示 [l, r] 的部分和(负值)
则 [1, 1] 的部分和等于:[1, 5) + [5, 7) + [7, 4) + [4, 2) = [1, 2)
该图共含有 N + 1 个顶点,使用邻接表进行存储
使用记忆化深度优先搜索,递归求解 [start, tar) 的部分和:
- 记录搜索过程的路径,用于判环
- 先查找该部分是否在邻接表中,如果有则 return
- 如果没有,则按照 [start, end) + [end, tar) 的形式求解,并记录最终的 [start, tar) 和 [tar, start)
import math
n, m, q = map(int, input().split())
adj = {i + 1: {} for i in range(n + 1)}
# 读取已知部分和, 写入邻接表
for _ in range(m):
l, r, sum_ = map(int, input().split())
# 写入正区间, 负区间
adj[l][r + 1] = sum_
adj[r + 1][l] = - sum_
def dfs(start, tar, path):
''' return: [start, tar) 的部分和'''
# 判断成环, 限制递归深度
if start in path or len(path) > 950: return math.nan
# 添加进路径
path.add(start)
# start -> tar
try:
return adj[start][tar]
except:
find = math.nan
# 遍历该顶点的出边
for end in adj[start]:
# start -> end
part_1 = adj[start][end]
if not math.isnan(part_1):
# end -> tar
part_2 = dfs(end, tar, path.copy())
find = part_1 + part_2
# 搜索成功
if not math.isnan(find): break
# 保存搜索结果
adj[start][tar] = find
if not math.isnan(find): adj[tar][start] = - find
return find
for _ in range(q):
l, r = map(int, input().split())
# 搜索: [l, r+1)
res = dfs(l, r + 1, set())
print('UNKNOWN' if math.isnan(res) else res)
字符统计 100🏆
【问题描述】
给定一个只包含大写字母的字符串 S,请你输出其中出现次数最多的字母。
如果有多个字母均出现了最多次,按字母表顺序依次输出所有这些字母
【输入格式】
一个只包含大写字母的字符串 S
【输出格式】
若干个大写字母,代表答案
【样例】
| 输入 | 输出 |
| BABBACAC | AB |
【评测用例规模与约定】
| 100% | |
【解析及代码】
用 collections 库的 Counter 快速解决
import itertools as it
from collections import Counter
cnt = Counter(input())
max_ = cnt.most_common(1)[0][1]
print(''.join(sorted(c for c, t in it.takewhile(
lambda item: item[1] == max_, cnt.most_common()))))
最少刷题数 100🏆
【问题描述】
小蓝老师教的编程课有 N 名学生,编号依次是 1 . . . N。第 i 号学生这学期刷题的数量是 。
对于每一名学生,请你计算他至少还要再刷多少道题,才能使得全班刷题比他多的学生数不超过刷题比他少的学生数
【输入格式】
第一行包含一个正整数 N。
第二行包含 N 个整数:
【输出格式】
输出 N 个整数,依次表示第 1 . . . N 号学生分别至少还要再刷多少道题
【样例】
| 输入 | 输出 |
| 5 12 10 15 20 6 | 0 3 0 0 7 |
【评测用例规模与约定】
| 30% | 1 ≤ N ≤ 1000, 0 ≤ Ai ≤ 1000 |
| 100% | 1 ≤ N ≤ 100000, 0 ≤ Ai ≤ 100000 |
【解析及代码】
先考虑所有学生都不一样卷的情况,对于总数 5 的序列(升序排序),索引 < 2 的学生需要比索引为 2 的学生卷就可以满足题意
对于总数为 n 的序列,这个分界的索引就为 m = n // 2
但是如果在这个序列中有个“中位数区间”,其中所有的学生都和索引 m 的学生一样卷
记区间边界为 [l, r],比该区间学生卷的人数就是 B = n - 1 - r,比该区间捞的人数就是 W = l:
- 在 B > W 的时候,“中位数区间”内的学生就需要卷 1 点
- 当一个学生从区间左侧进入“中位数区间”时,B 不变,W -= 1,如果这时 B > W,这名学生就需要比“中位数区间”的学生卷 1 点;否则,这名学生只需要和“中位数区间”的学生一样卷就行
class Student:
def __init__(self, cur):
# 当前刷题数, 额外刷题数
self.cur, self.add = cur, 0
def __eq__(self, other):
return self.cur == other.cur
def __repr__(self):
return str(self.add)
n = int(input())
stus = list(map(Student, map(int, input().split())))
# 对当前刷题数进行排序
sort_stus = sorted(stus, key=lambda stu: stu.cur)
# 找到与中位数的区间边界
l = r = n // 2
while l - 1 >= 0 and sort_stus[l] == sort_stus[l - 1]: l -= 1
while r + 1 < n and sort_stus[r] == sort_stus[r + 1]: r += 1
# 在中位数区间的左边
target = sort_stus[l].cur + (1 if n - r > l else 0)
for i in range(l):
sort_stus[i].add = target - sort_stus[i].cur
# 区间右侧人数 > 区间左侧人数: 中位数区间内卷
if n - 1 - r > l:
for i in range(l, r + 1): sort_stus[i].add = 1
print(*stus)
求阶乘 100🏆
【问题描述】
满足 N! 的末尾恰好有 K 个 0 的最小的 N 是多少?
如果这样的 N 不存在输出 −1
【输入格式】
一个整数 K
【输出格式】
一个整数代表答案
【样例】
| 输入 | 输出 |
| 2 | 10 |
【评测用例规模与约定】
| 30% | |
| 100% |
【解析及代码】
末尾有 K 个 0,等价于阶乘拆分后有 K 个 10 相乘
因为 10 的因数是 2 和 5,所以末尾有几个 0 由因数中有几个 5 决定,N 与 K 满足:
所以当 N ∈ [25, 30) 时 K 相同,依次类推可知符合题意的 N 为 5 的倍数,记 N = 5M,有:
因为下取整的操作,K(M) 没办法求出反函数 M(K),所以这个题只能用迭代来做
给定目标的 K 为 32,令初始的 M 也为 32:
- 当前 K 为 32 + 6 + 1 = 39,迭代量为 32 - 39 = -7,新的 M 为 25
- 当前 K 为 25 + 5 + 1 = 31,迭代量为 32 - 31 = 1,新的 M 为 26
- 当前 K 为 26 + 5 + 1 = 32,迭代量为 32 - 32 = 0,M = 26 即为结果,输出 N = 5M = 130
对于给定 K 不存在满足条件的 N 时,迭代中 M 会一直振荡。给定目标的 K 为 30,令初始的 M 也为 30:
- 当前 K 为 30 + 6 + 1 = 37,迭代量为 30 - 37 = -7,新的 M 为 23
- 当前 K 为 23 + 4 = 27,迭代量为 30 - 27 = 3,新的 M 为 26
- 当前 K 为 26 + 5 + 1 = 32,迭代量为 30 - 32 = -2,新的 M 为 24
- 当前 K 为 24 + 4 = 28,迭代量为 30 - 28 = 2,新的 M 为 26
自此迭代量的绝对值一直为 2,可将最后两次迭代量之和为 0 作为终止条件
# n = 5m
m = k = int(input())
def optimize(m):
cur_k, temp = 0, m
# 求出当前 K
while temp:
cur_k += temp
temp //= 5
return k - cur_k
last_grad = float('inf')
while True:
cur_grad = optimize(m)
# 迭代量为 0 时即完成
if cur_grad == 0:
print(5 * m)
break
# 检测是否不存在满足条件的 K
if cur_grad + last_grad == 0:
print(-1)
break
last_grad = cur_grad
# 更新 M
m += cur_grad
最大子矩阵 100🏆
【问题描述】
小明有一个大小为 N × M 的矩阵,可以理解为一个 N 行 M 列的二维数组。 我们定义一个矩阵 m 的稳定度 f(m) 为 f(m) = max(m) − min(m),其中 max(m) 表示矩阵 m 中的最大值,min(m) 表示矩阵 m 中的最小值。现在小明想要从这个矩阵中找到一个稳定度不大于 limit 的子矩阵,同时他还希望这个子矩阵的面积越大越好(面积可以理解为矩阵中元素个数)。
子矩阵定义如下:从原矩阵中选择一组连续的行和一组连续的列,这些行列交点上的元素组成的矩阵即为一个子矩阵。
【输入格式】
第一行输入两个整数 N,M,表示矩阵的大小。
接下来 N 行,每行输入 M 个整数,表示这个矩阵。
最后一行输入一个整数 limit,表示限制。
【输出格式】
输出一个整数,分别表示小明选择的子矩阵的最大面积
【样例】
| 输入 | 输出 |
| 3 4 2 0 7 9 0 6 9 7 8 4 6 4 8 | 6 |
【评测用例规模与约定】

| 100% |
【解析及代码】
枚举上下界,那么行数 r = bottom - top + 1,对于 r × C 的子矩阵,若对每一列求最大最小值,则该子矩阵可看作 1 × C 的行向量处理
锁定上界时,随着下界的逐渐下移,max 和 min 函数的参数是有规律增加的,故可作反复利用前一个 1 × C 的行向量的最大最小值
枚举左右边界时同理,而且可以当前子矩阵的面积、最优子矩阵的面积做剪枝
import math
rows, cols = map(int, input().split())
array = [list(map(int, input().split())) for _ in range(rows)]
limit = int(input())
square = 1
for t in range(rows):
maxs = [0] * cols
mins = [float('inf')] * cols
for b in range(t, rows):
# 对上下边界内的矩阵, 逐列求最值
maxs = [max(maxs[c], array[b][c]) for c in range(cols)]
mins = [min(mins[c], array[b][c]) for c in range(cols)]
# 只考虑比当前更优的 (固定高度, 对搜索的宽度进行裁剪)
height = b - t + 1
width = math.ceil(square / height + 1e-5)
if width <= cols:
# 枚举左右边界
for l in range(cols):
r_s = l + width - 1
if r_s < cols:
# 选定一个面积更大的子矩阵, 求最值
maxc = max(maxs[l: r_s + 1])
minc = min(mins[l: r_s + 1])
for r in range(r_s, cols):
# 扩大子矩阵的面积, 求最值
maxc = max(maxc, maxs[r])
minc = min(minc, mins[r])
if maxc - minc > limit: break
# 子矩阵的稳定性满足
square = width * height
width += 1
print(square)
数组切分 100🏆
【问题描述】
已知一个长度为 N 的数组: 恰好是 1 ∼ N 的一个排列。现在要求你将 A 数组切分成若干个 (最少一个,最多 N 个) 连续的子数组,并且每个子数组中包含的整数恰好可以组成一段连续的自然数。
例如对于 A = {1, 3, 2, 4}, 一共有 5 种切分方法:
{1}{3}{2}{4}:每个单独的数显然是 (长度为 1 的) 一段连续的自然数。
{1}{3, 2}{4}:{3, 2} 包含 2 到 3,是 一段连续的自然数,另外 {1} 和 {4} 显然也是。
{1}{3, 2, 4}:{3, 2, 4} 包含 2 到 4,是 一段连续的自然数,另外 {1} 显然也是。
{1, 3, 2}{4}:{1, 3, 2} 包含 1 到 3,是 一段连续的自然数,另外 {4} 显然也是。
{1, 3, 2, 4}:只有一个子数组,包含 1 到 4,是 一段连续的自然数。
【输入格式】
第一行包含一个整数 N。第二行包含 N 个整数,代表 A 数组
【输出格式】
输出一个整数表示答案。由于答案可能很大,所以输出其对 1000000007 取模后的值
【样例】
| 输入 | 输出 |
| 4 1 3 2 4 | 5 |
【评测用例规模与约定】
| 30% | 1 ≤ N ≤ 20 |
| 100% | 1 ≤ N ≤ 10000 |
【解析及代码】
这个题我是在 NewOJ 上测的:http://oj.ecustacm.cn/problem.php?id=2062
记某个子数组 seq 为 [l, r],那么当 r - l = max(seq) - min(seq) 时,该子数组中的整数恰好可以组成一段连续的自然数
构造入边表:如果 [2, 5) 区间满足题意,则顶点 5 可由顶点 2 到达
使用 dp[i] 存储达到顶点 i 的方案数(对应 array[:i] 的切分方法数),显然有 dp[0] = 1
如果顶点 4 可由 [0, 1, 3] 到达,那么 dp[4] = dp[0] + dp[1] + dp[3]
mod = 1000000007
n = int(input())
array = list(map(int, input().split()))
# 入边表: n + 1 个结点 (0 不可被到达)
adj = [[] for _ in range(n + 1)]
for l in range(n):
min_ = max_ = array[l]
# [l, l] 区间满足题意
adj[l + 1].append(l)
for r in range(l + 1, n):
min_, max_ = min(min_, array[r]), max(max_, array[r])
# [l, r] 区间满足题意
if max_ - min_ == r - l: adj[r + 1].append(l)
del array
dp = [1] + [0 for _ in range(n)]
for cur in range(1, n + 1):
dp[cur] = sum(dp[i] for i in adj[cur]) % mod
print(dp[-1])
回忆迷宫
【问题描述】
爱丽丝刚从一处地下迷宫中探险归来,你能根据她对于自己行动路径的回忆,帮她画出迷宫地图吗?
迷宫地图是基于二维网格的。爱丽丝会告诉你一系列她在迷宫中的移动步骤,每个移动步骤可能是上下左右四个方向中的一种,表示爱丽丝往这个方向走了一格。你需要根据这些移动步骤给出一个迷宫地图,并满足以下条件:
1、爱丽丝能在迷宫内的某个空地开始,顺利的走完她回忆的所有移动步骤。
2、迷宫内不存在爱丽丝没有走过的空地。
3、迷宫是封闭的,即可通过墙分隔迷宫内与迷宫外。任意方向的无穷远处视为迷宫外,所有不与迷宫外联通的空地都视为是迷宫内。(迷宫地图为四联通,即只有上下左右视为联通)
4、在满足前面三点的前提下,迷宫的墙的数量要尽可能少。
【输入格式】
第一行一个正整数 N,表示爱丽丝回忆的步骤数量。
接下来一行 N 个英文字符,仅包含 UDLR 四种字符,分别表示上(Up)、下(Down)、左(Left)、右(Right)
【输出格式】
请通过字符画的形式输出迷宫地图。迷宫地图可能包含许多行,用字符 ‘*’ 表示墙,用 ‘ ’(空格)表示非墙。
你的输出需要保证以下条件:
1、至少有一行第一个字符为 ‘*’。
2、第一行至少有一个字符为 ‘*’。
3、每一行的最后一个字符为 ‘*’。
4、最后一行至少有一个字符为 ‘*’。
【样例】
| 输入 | 输出 | 说明 |
| 17 UUUULLLLDDDDRRRRU | ***** * * * *** * * *** * * *** * * * ***** | 爱丽丝可以把第六行第六个 字符作为起点: 外墙墙墙墙墙外 墙内内内内内墙 墙内墙墙墙内墙 墙内墙墙墙内墙 墙内墙墙墙内墙 墙内内内内内墙 外墙墙墙墙墙外 |
【评测用例规模与约定】
| 100% | 1 ≤ N ≤ 100 |
【解析及代码】
我的思路是一开始把迷宫全部设为“外”,根据路径填“内”,同时把“内”周围的“外”设为“墙”
但是难处理的点在于,迷宫内可能存在一块很大的“外”(被“墙”包围),这一部分怎么去找?
我目前的想法是记忆化深搜,但是没实现,代码写一半挂这了
_ = input()
# 迷宫的边界信息: t, b, l, r
map_shape = [0] * 4
# 轨迹坐标
walk = [(0, 0)]
for oper in input():
last = walk[-1]
if oper == 'U':
cur = last[0], last[1] - 1
map_shape[0] = min(cur[1], map_shape[0])
elif oper == 'D':
cur = last[0], last[1] + 1
map_shape[1] = max(cur[1], map_shape[1])
elif oper == 'L':
cur = last[0] - 1, last[1]
map_shape[2] = min(cur[0], map_shape[2])
else:
cur = last[0] + 1, last[1]
map_shape[3] = max(cur[0], map_shape[3])
walk.append(cur)
# 计算迷宫参数: 留墙
width = map_shape[3] - map_shape[2] + 3
height = map_shape[1] - map_shape[0] + 3
x_bias, y_bias = - map_shape[2] + 1, - map_shape[0] + 1
around = (1, 0), (-1, 0), (0, 1), (0, -1)
# 一开始全部是外: $
map_ = [['$'] * width for _ in range(height)]
for x, y in walk:
x += x_bias
y += y_bias
map_[x][y] = ' '
# 检测空地, 设墙
for x_, y_ in around:
x_ += x
y_ += y
if map_[x_][y_] == '$':
map_[x_][y_] = '*'
# 查找内墙: 外 -> 墙
for x in range(1, width - 1):
for y in range(1, height - 1):
if map_[x][y] == '$':
# 深度优先搜索向下搜索外的连通块
pass拉箱子
【问题描述】
推箱子是一款经典电子游戏,爱丽丝很喜欢玩,但是她有点玩腻了,现在她想设计一款拉箱子游戏。
拉箱子游戏需要玩家在一个 N × M 的网格地图中,控制小人上下左右移动,将箱子拉到终点以获得胜利。
现在爱丽丝想知道,在给定地形(即所有墙的位置)的情况下,有多少种不同的可解的初始局面。
【初始局面】 的定义如下:
1、初始局面由排列成 N × M 矩形网格状的各种元素组成,每个网格中有且只有一种元素。可能的元素有:空地、墙、小人、箱子、终点。
2、初始局面中有且只有一个小人。
3、初始局面中有且只有一个箱子。
4、初始局面中有且只有一个终点。
【可解】 的定义如下:
通过有限次数的移动小人(可以在移动的同时拉箱子),箱子能够到达终点所在的网格。
【移动】 的定义如下:
在一次移动中,小人可以移动到相邻(上、下、左、右四种选项)的一个网格中,前提是满足以下条件:
1、小人永远不能移动到 N × M 的网格外部。
2、小人永远不能移动到墙上或是箱子上。
3、小人可以移动到空地或是终点上。
【拉箱子】 的定义如下:
在一次合法移动的同时,如果小人初始所在网格沿小人移动方向的反方向上的相邻网格上恰好是箱子,小人可以拉动箱子一起移动,让箱子移动到小人初始所在网格。
即使满足条件,小人也可以只移动而不拉箱子。
【输入格式】
第一行两个正整数 N 和 M,表示网格的大小。
接下来 N 行,每行 M 个由空格隔开的整数 0 或 1 描述给定的地形。其中 1 表示墙,0 表示未知的元素,未知元素可能是小人或箱子或空地或终点,但不能是墙。
【输出格式】
输出一个正整数,表示可解的初始局面数量
【样例】
| 输入 | 输出 |
| 2 4 0 0 0 0 1 1 1 0 | 13 |
【评测用例规模与约定】
| 30% | N, M ≤ 3 |
| 100% | 0 < N, M ≤ 10 |
【解析及代码】
矩形拼接 100🏆
【题目描述】
已知 3 个矩形的大小依次是 a1 × b1, a2 × b2 和 a3 × b3。用这 3 个矩形能拼出的所有多边形中,边数最少可以是多少?
例如用 3 × 2 的矩形(用 A 表示)、4 × 1 的矩形(用 B 表示)和 2 × 4 的矩形(用 C 表示)可以拼出如下 4 边形
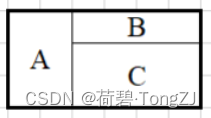
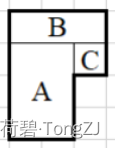
例如用 3 × 2 的矩形(用 A 表示)、3 × 1 的矩形(用 B 表示)和 1 × 1 的矩形(用 C 表示)可以拼出如下 6 边形。
【输入格式】
输入包含多组数据。
第一行包含一个整数 T,代表数据组数。
以下 T 行,每行包含 6 个整数 ,其中
是第一个矩形的边长,
是第二个矩形的边长,
是第三个矩形的边长。
【输出格式】
对于每组数据,输出一个整数代表答案。
【样例】
| 输入 | 输出 |
| 2 2 3 4 1 2 4 1 2 3 4 5 6 | 4 6 |
【评测用例规模与约定】
| 10% | |
| 30% | |
| 60% | |
| 100% |
【解析及代码】
小的不才,没有什么比较好的解法,解法接近暴力,基本的思路是:
- 将三个矩形分成 2 + 1 的形式,对前两个矩形进行拼接,以 int 表示凸边,以自定义类 Hollow 表示凹角
- 使用列表存储凸边、凹角,以表示多边形,该多边形的边数为:
当第三个矩形拼接在凹角处时,计算该凹角对边数的贡献
当第三个矩形未拼接在凹角处时,若不产生凹角则总边数不变,若产生新的凹角则增加 2 条边
import itertools as it
class Hollow:
def __init__(self, edge: tuple, third: tuple):
self.v = 2
# 有一条边与凹角吻合
if set(third) & set(edge): self.v = 0
# 刚好可以嵌入凹角
if edge in (third, third[::-1]): self.v = -2
def __repr__(self):
return f'<{self.v}>'
for _ in range(int(input())):
# 整理出矩形的边长
rects = list(map(int, input().split()))
rects = [tuple(rects[i * 2: (i + 1) * 2]) for i in range(3)]
# 对每个二元组进行拼接: 凸边, 凹角
result = []
for r1, r2, r3 in it.combinations(rects, 3):
for a in range(2):
for b in range(2):
# 两个矩形各保留一条边, 剩下的一条边进行拼接
tmp = [r1[a], r2[b], r1[1 - a] + r2[1 - b]]
have_corner = r1[a] != r2[b]
# 两拼接边长不相等: 产生转角
if have_corner:
res = abs(r1[a] - r2[b])
# 凹角 + 另一条边
if r1[a] > r2[b]:
tmp += [r1[1 - a], Hollow((res, r2[1 - b]), r3)]
else:
tmp += [r2[1 - b], Hollow((res, r1[1 - a]), r3)]
# 两拼接边长相等
else:
tmp.append(r1[1 - a] + r2[1 - b])
# 拼接第三个矩形 r3
x = 6 if have_corner else 4
for ele in set(tmp):
# 在转角处拼接: 访问 Hollow.v (与 r3 拼接后, 对边数的贡献)
if isinstance(ele, Hollow):
result.append(x + ele.v)
# 非转角处拼接: 不产生凹角 / 产生凹角
else:
result.append(x + (0 if ele in set(r3) else 2))
print(min(result))GCD 100🏆
【题目描述】
给定两个不同的正整数 a, b,求一个正整数 k 使得 gcd(a + k, b + k) 尽可能大,其中 gcd(a, b) 表示 a 和 b 的最大公约数,如果存在多个 k,请输出所有满足条件的 k 中最小的那个。
【输入格式】
输入一行包含两个正整数 a, b,用一个空格分隔。
【输出格式】
输出一行包含一个正整数 k。
【样例】
| 输入 | 输出 |
| 5 7 | 1 |
【评测用例规模与约定】
| 20% | |
| 40% | |
| 100% |
【解析及代码】
两个数的最大公约数只可能是两者之差的因数,即 gcd(a + k, b + k) 最大为 |a - b|,记为 g:
求 k 使 m, n 均为整数,有 ,为使 k 尽可能小,令
import math
a, b = map(int, input().split())
gcd = abs(a - b)
print(round(math.ceil(a / gcd) * gcd - a))
因数平方和 100🏆
【问题描述】
记 为 x 的所有因数的平方的和。例如:
。
定义 。给定 n, 求
除以
的余数。
【输入格式】
输入一行包含一个正整数 n
【输出格式】
输出一个整数表示答案 除以
的余数
【样例】
| 输入 | 输出 |
| 100000 | 680584257 |
【评测用例规模与约定】
| 20% | |
| 30% | |
| 100% |
【解析及代码】
给定 n,求 [1, n] 所有数的所有因数的平方和
比如对于 100000,则 [1, 100000] 中可被 32323 整除的数有 3 个,那么对 g(n) 的贡献是
同理可得:
设 ,那么:
mod = 10 ** 9 + 7
n = int(input())
# 前 i 项平方和
ssum = lambda i: i * (i + 1) * (2 * i + 1) // 6
res = y = n
while y != 1:
i = n // y + 1
res += (i - 1) * (ssum(y) - ssum(n // i))
res %= mod
y = n // i
print(res)
重新排序 95🏆
【问题描述】
给定一个数组 A 和一些查询 ,求数组中第
至第
个元素之和。
小蓝觉得这个问题很无聊,于是他想重新排列一下数组,使得最终每个查询结果的和尽可能地大。小蓝想知道相比原数组,所有查询结果的总和最多可以增加多少?
【输入格式】
输入第一行包含一个整数 n。
第二行包含 n 个整数 ,相邻两个整数之间用一个空格分隔。
第三行包含一个整数 m 表示查询的数目。
接下来 m 行,每行包含两个整数 ,相邻两个整数之间用一个空格分隔。
【输出格式】
输出一行包含一个整数表示答案。
【样例】
| 输入 | 输出 | 说明 |
| 5 1 2 3 4 5 2 1 3 2 5 | 4 | 原来的和为 6 + 14 = 20, 重新排列为 (1, 4, 5, 2, 3) 后和为 10 + 14 = 24,增加了 4。 |
【评测用例规模与约定】
| 30% | |
| 50% | |
| 70% | |
| 100% |
【解析及代码】
使用权重向量来记录数列对应位置的数被取的次数
为了降低时间复杂度,使用差分数列进行表示
对权重向量、原数列进行排序,按序相乘即为最优结果
import itertools as it
n = int(input())
array = list(map(int, input().split()))
# 权重向量的差分数列
weight = [0] * n
for _ in range(int(input())):
l, r = map(lambda i: int(i) - 1, input().split())
# 更新差分数列
weight[l] += 1
if r + 1 < n: weight[r + 1] -= 1
# 差分数列 -> 权重向量
weight = list(it.accumulate(weight))
print(sum(e * w for e, w in zip(*map(sorted, (array, weight)))) -
sum(e * w for e, w in zip(array, weight)))重复的数 77🏆
【题目描述】
给定一个数列 ,给出若干询问,每次询问某个区间
内恰好出现
次的数有多少个。
【输入格式】
输入第一行包含一个整数 n 表示数列长度
第二行包含 n 个整数 ,表示数列中的数
第三行包含一个整数 m 表示询问次数
接下来 m 行描述询问,其中第 i 行包含三个整数 表示询问
区间内有多少数出现了
次
【输出格式】
输出 m 行,分别对应每个询问的答案
【样例】
| 输入 | 输出 |
| 3 1 2 2 5 1 1 1 1 1 2 1 2 1 1 2 2 1 3 2 | 1 0 2 0 1 |
【评测用例规模与约定】
| 20% | n, m ≤ 500, 1 ≤ a1, a2, · · · , an ≤ 1000 |
| 40% | n, m ≤ 5000 |
| 100% | 1 ≤ n, m ≤ 100000, 1 ≤ a1, a2, · · · , an ≤ 100000 |
【解析及代码】
利用前缀和 + collections 库的 Counter 解决
from collections import Counter
import itertools as it
_ = int(input())
array = [Counter((i,)) for i in map(int, input().split())]
array = list(it.accumulate(array)) + [Counter()]
for _ in range(int(input())):
l, r, k = map(int, input().split())
# 对数字的频值进行统计
cnt = array[r - 1] - array[l - 2]
print(sum(i == k for i in cnt.values()))质因数个数 100🏆
【题目描述】
给定正整数 n,请问有多少个质数是 n 的约数。
【输入格式】
输入的第一行包含一个整数 n。
【输出格式】
输出一个整数,表示 n 的质数约数个数。
【样例】
| 输入 | 输出 |
| 396 | 3 |
【评测用例规模与约定】
| 30% | |
| 60% | |
| 100% |
【解析及代码】
从评测用例来看,只用试除法是不行的(只能拿 77 分),针对大数的质因数分解请看我的这篇文章:大数的质因数分解 Python
因为不需要求质因数的幂次,所以针对 prime_factor 这个类进行改造:
- 父类改为 set 类型,只存储质因数
- main、try_div 函数取消 gain 参数,不求解幂次
import math
import random
def miller_rabin(p):
""" 素性测试"""
# 特判 4
if p <= 4: return p in (2, 3)
# 对 p-1 进行分解
pow_2, tmp = 0, p - 1
while tmp % 2 == 0:
tmp //= 2
pow_2 += 1
# 进行多次素性测试
for a in (2, 3, 5, 7, 11):
basic = pow(a, tmp, p)
# a^m 是 p 的倍数或者满足条件
if basic in (0, 1, p - 1): continue
# 进行 r-1 次平方
for _ in range(1, pow_2):
basic = basic ** 2 % p
# 怎样平方都是 1
if basic == 1: return False
# 通过 a 的素性测试
if basic == p - 1: break
# 未通过 a 的素性测试
if basic != p - 1: return False
# 通过所有 a 的素性测试
return True
def pollard_rho(n):
""" 求因数: 7e5 以上"""
# 更新函数
bias = random.randint(3, n - 1)
update = lambda i: (i ** 2 + bias) % n
# 初始值
x = random.randint(0, n - 1)
y = update(x)
# 查找序列环
while x != y:
factor = math.gcd(abs(x - y), n)
# gcd(|x - y|, n) 不为 1 时, 即为答案
if factor != 1: return factor
x = update(x)
y = update(update(y))
return n
class prime_factor(set):
def __init__(self, n):
super().__init__()
self.main(n)
def count(self, n, fac):
# 试除并记录幂次
cnt = 1
n //= fac
while n % fac == 0:
cnt += 1
n //= fac
return n, cnt
def main(self, n):
# 试除法求解
if n < 7e5: return self.try_div(n)
# 米勒罗宾判素
if miller_rabin(n): return self.add(n)
# pollard rho 求解因数
fac = pollard_rho(n)
n, cnt = self.count(n, fac)
# 递归求解因数的因数
self.main(fac)
# 递归求解剩余部分
if n > 1: self.main(n)
def try_div(self, n):
""" 试除法分解"""
i, bound = 2, math.sqrt(n)
while i <= bound:
if n % i == 0:
# 计数 + 整除
n, cnt = self.count(n, i)
# 记录幂次, 更新边界
self.add(i)
bound = math.sqrt(n)
i += 1
if n > 1: self.add(n)
print(len(prime_factor(int(input()))))

















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











