






数据结构
在看过前言之后,你肯定会好奇它到底是如何降低查询数据的效率,这就需要讲到数据结构了。
1、什么是数据结构
数据结构简单的可以理解为是为了提高效率的一种结构,其中对应不同的代码可以使用不同的数据结构来去提高它的效率。
其中Mysql因为运用的innodb引擎,而innodb引擎所使用的索引是B+Tree索引所以Mysql使用的是B+Tree索引。
2、B+Tree数据结构
数据结构图形化网站
这里为了方便理解我会从二叉树结构、红黑树、B-Tree、B+Tree结构都大致的去讲一遍。
①、二叉树
原理:二叉树,是将所有的数据进行顺序存储,以第一个数据为根节点,其余数据位子节点,但是一个根节点,只能有两个子节点,所以一个节点即可以子节点也可以是根节点,但是第一个存储的数据只能是根节点,而二叉树的排序规则是:比根节点小的数据存储在左子节点,比根节点大的数据储存在右子节点。所以在二叉树中最左边的数据时最小的,最右边的数据是最大的。
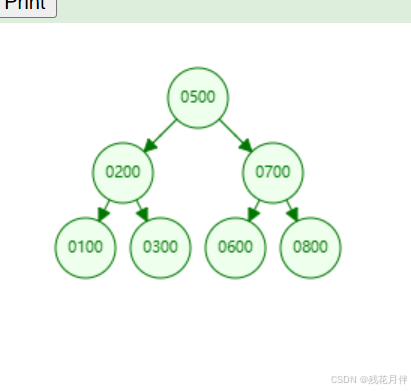
假设我存储:500、200、100、300、700、600、800这些数据此数据结构的图形化如下:
这个时候假设我想查询“600”这条数据的话,就只需要两步即可,有效的提高了查询的效率
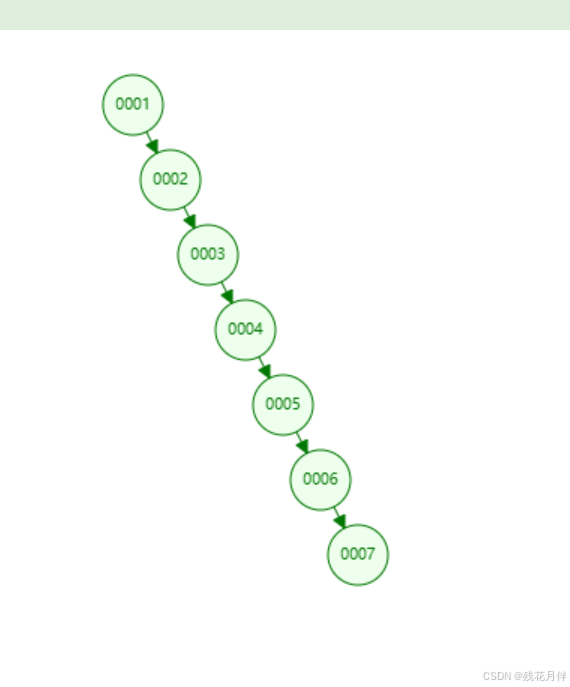
但是使用二叉树的有个很明显的缺点就是如果我是顺序插入数据的话就会使二叉树的深度提高,从而查询效率就提高的没有那么明显。
列如:
②、红黑树
优点:相对于二叉树避免了顺序插入会使得深度变高从而效率变为O(n),
缺点:实现复杂度高
原理:红黑树是在二叉树的基础上,去添加了三个规则,规则如下:
- 根节点和叶子节点(null)都是黑色
- 不存在连续的两个红色节点
- 任意节点到叶所有的路径黑节点的数量相同
插入数据的过程解析:想要在红黑树中插入数据,当已经有了根节点时,默认会将节点以红色的形式插入,在去判断是否违反规则,若是破坏了“规则2”将会在不破坏所有的规则的基础下进行旋转,若是破坏了“规则3”将会在不破坏所有的规则的基础下进行变色,(“规则1”更像是一个限制,因为有了此限制可以更好的去添加红黑节点)
实例:
违反“规则2”实例1:
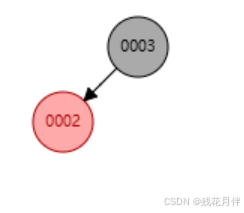
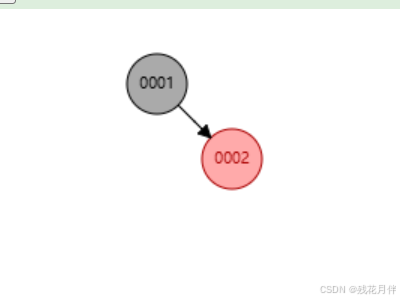
列如依次添加3、2、1数据如图:
在添加到“2”时可以看到此链接左下有了一个红色节点。
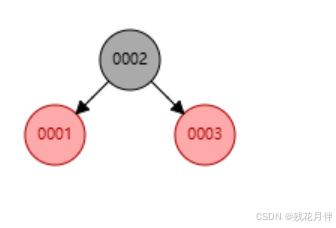
而在添加到“1”时就会发现红黑树进行了旋转,将“2”作为根节点“1”、“3”作为子节点,这是因为当添加“1”时默认是红节点但是放在图一中的最左边会发现已经违反了“规则2”所以根节点会进行右旋转,又因为“规则1”的规定所有的根节点为黑色所以在进行变色。
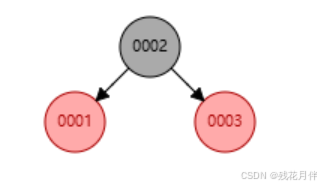
违反“规则2”实例2:
依次添加1、2、3,如图:
在添加到“2”时可以看到此链接右下有了一个红色节点。
因为数据与实例1相同所以结果一样但是他的过程与实例1,有一个地方是不同的,在进行旋转时他是将根节点进行左旋转后,在进行变色。
③、B-Tree
优点:对比二叉树、红黑树来说B-Tree的查询效率大大的提升了!
缺点:B-Tree的每个节点不经包含了key值还包含了value值,当value值过大时很容易超出其节点的最大值,从而使每个节点的key值减少,并导致B-Tree的层级过高,增加IO访问的次数。
原理:相对与二叉树、红黑树每个节点只可以存储一个值不同的是B-Tree可以在每个节点可以存储多个值,其存储方式是以key值与value值的一一对应的方式存储,且存储方式为向上分裂。
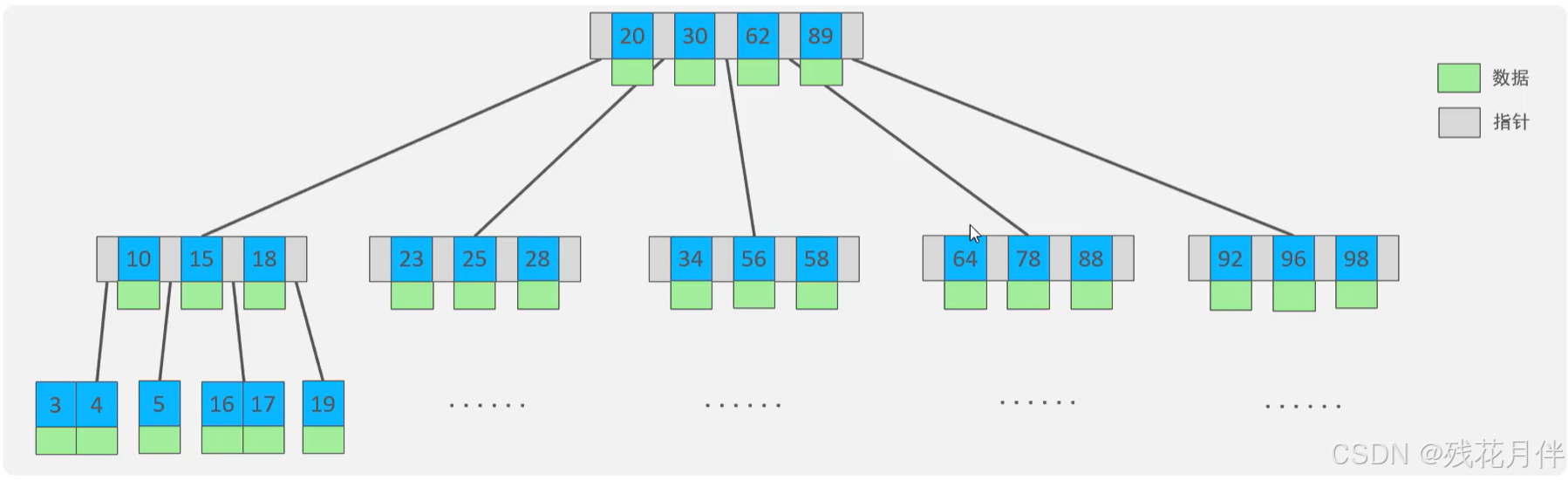
简述:以一颗最大度数(max-degree)为5(5阶)的B-Tree为例(每个节点最多存储4个key,5个指针)如图:
度数:每个节点的的子节点数。
存储示意图(这里以度数为5的B-Tree为例):
向上分裂:
随便存入4个值列如:
在去存入一个值时会发现图形进行了分裂,且时取中间值向上分裂


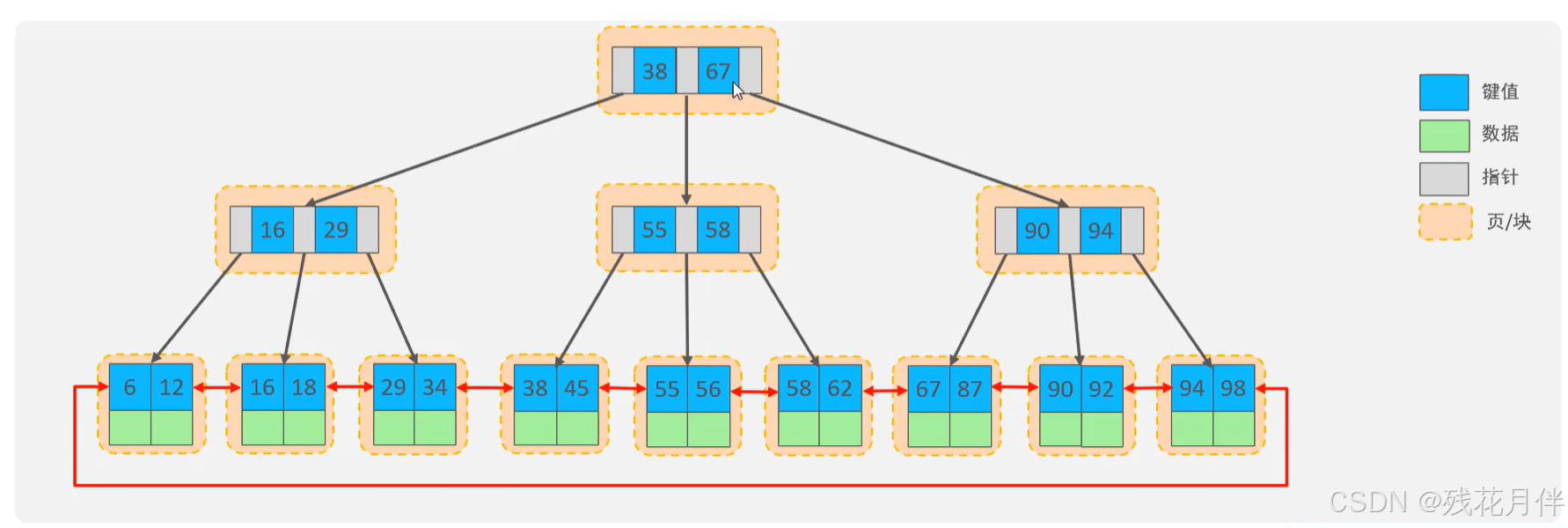
④B+Tree与B+Tree(Mysql)
优点:对比B-Tree来说B+Tree解决了节点上会超出其最大值(16KB)的问题,同时也优化了大量数据层级高的问题。(B+Tree(Mysql)是在次此基础上添加了双向链表)
缺点:节点分裂和合并的过程相对复杂。 当数据经常插入和删除时,维护成本较高。
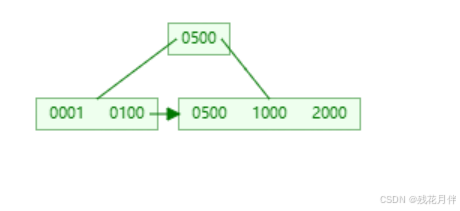
原理:在B-Tree的结构上的子节点上添加了单向列表,且改变B-Tree的存储方式,B+Tree的数据一般只会存储在其子节点上。如图:
B+Tree(Mysql)的示意图:


















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









