







Qwen2.5-Omni 是一种端到端多模态模型,旨在感知文本、图像、音频和视频等多种模态,同时以流式方式生成文本和自然语音响应。
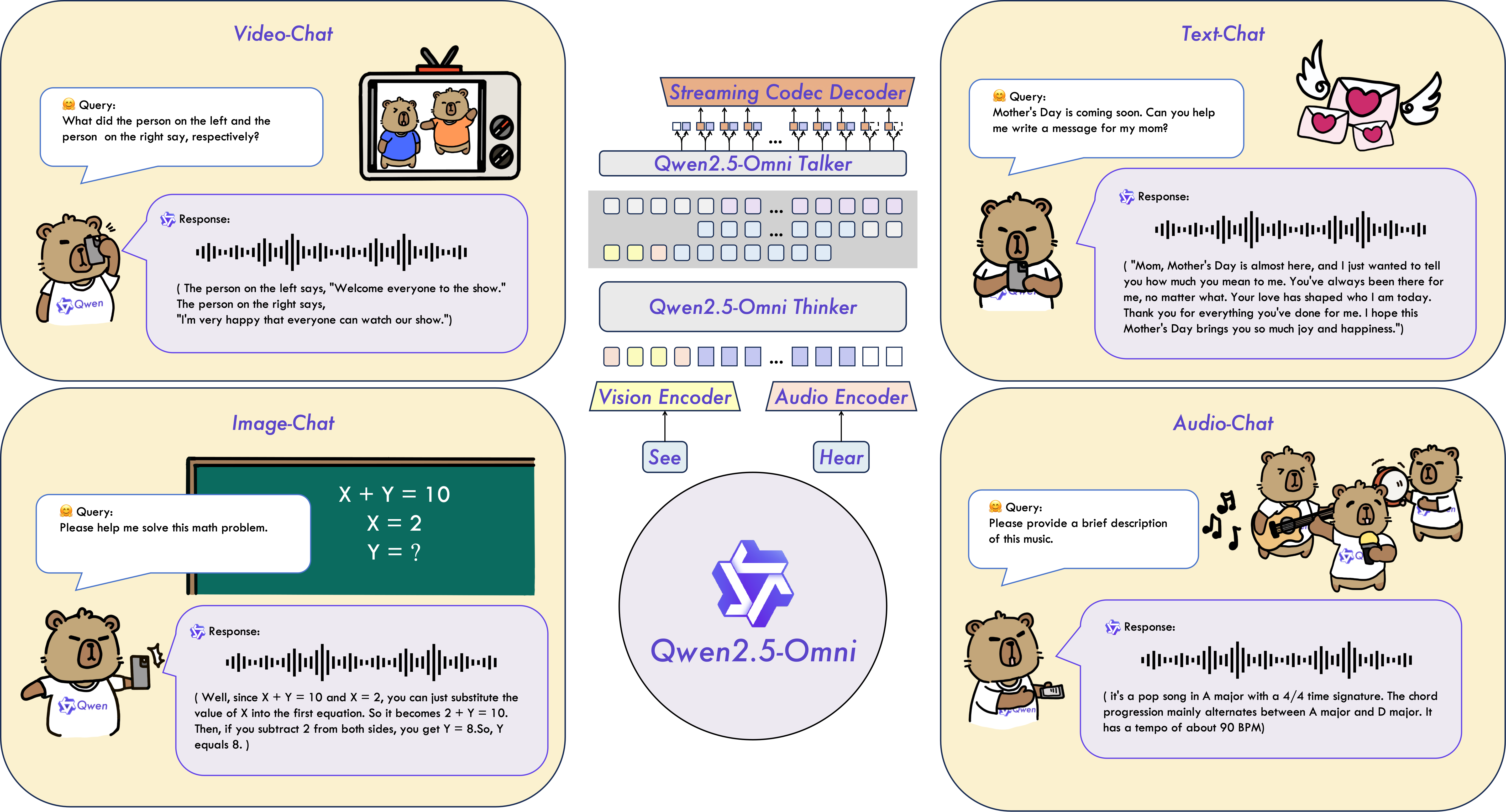
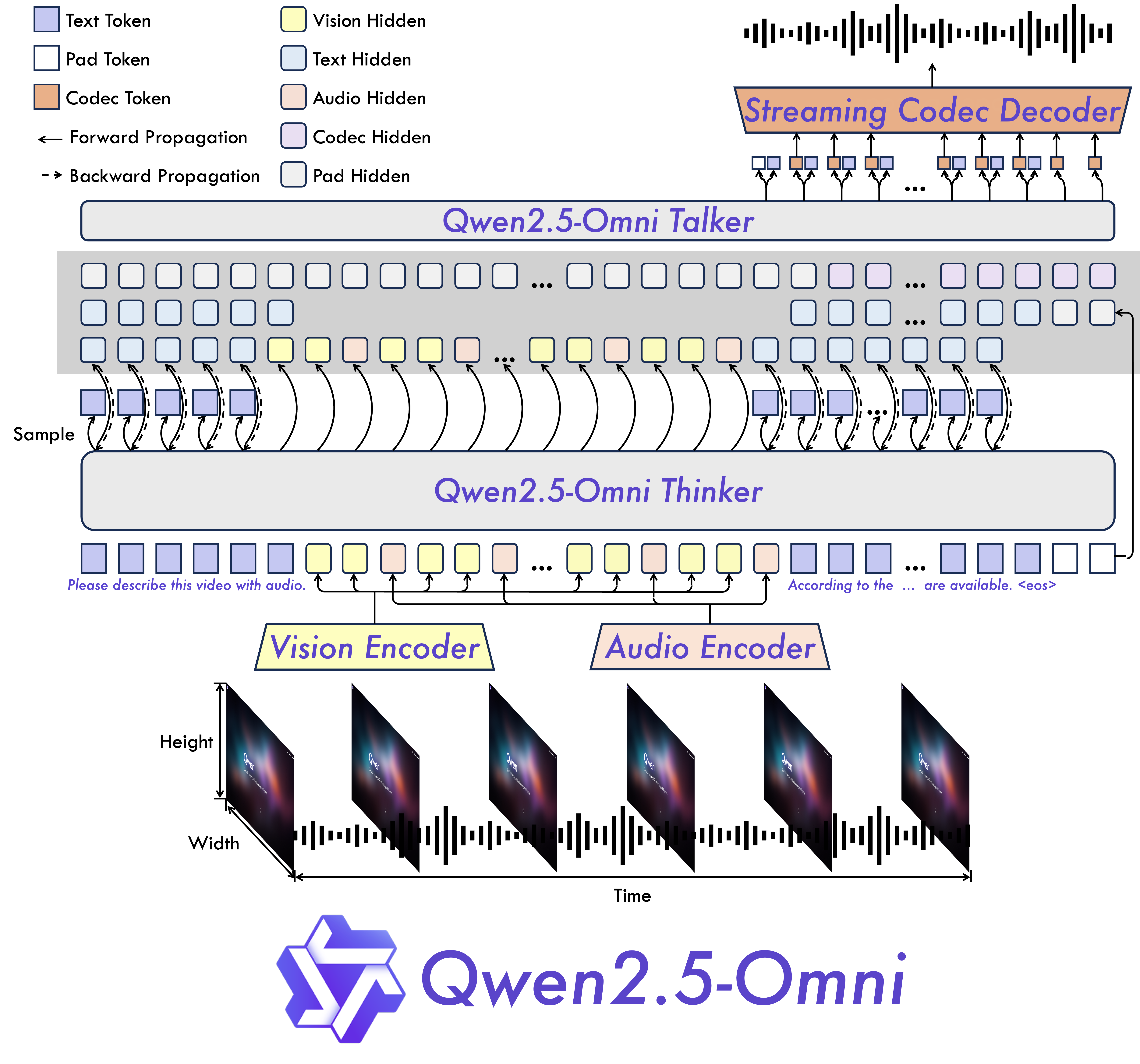
系统架构
性能
我们对 Qwen2.5-Omni 进行了全面评估,与类似规模的单模态模型和封闭源模型(如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro)相比,Qwen2.5-Omni 在所有模态中都表现出强劲的性能。在需要整合多种模式的任务中,如 OmniBench,Qwen2.5-Omni 实现了最先进的性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等领域表现出色。

多模态能力
| Datasets | Model | Performance |
|---|---|---|
| OmniBench Speech | Sound Event | Music | Avg | Gemini-1.5-Pro | 42.67%|42.26%|46.23%|42.91% |
| MIO-Instruct | 36.96%|33.58%|11.32%|33.80% | |
| AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% | |
| video-SALMONN | 34.11%|31.70%|56.60%|35.64% | |
| UnifiedIO2-xlarge | 39.56%|36.98%|29.25%|38.00% | |
| UnifiedIO2-xxlarge | 34.24%|36.98%|24.53%|33.98% | |
| MiniCPM-o | -|-|-|40.50% | |
| Baichuan-Omni-1.5 | -|-|-|42.90% | |
| Qwen2.5-Omni-3B | 52.14%|52.08%|52.83%|52.19% | |
| Qwen2.5-Omni-7B | 55.25%|60.00%|52.83%|56.13% |
快速上手
下面,我们提供了一些简单的示例,说明如何将 Qwen2.5-Omni 与🤗Transformers一起使用。Qwen2.5-Omni 的代码已包含在最新的拥抱脸变形程序中,我们建议您使用命令从源代码构建:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
我们提供了一个工具包,帮助您更方便地处理各种类型的音频和视频输入,就像使用 API 一样。其中包括 base64、URL 以及交错音频、图像和视频。你可以使用以下命令安装它,并确保你的系统安装了 ffmpeg:
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord] -U
如果您使用的不是 Linux,您可能无法从 PyPI 安装 decord。在这种情况下,您可以使用 pip install qwen-omni-utils -U,这样就可以使用 torchvision 进行视频处理。不过,您仍然可以从源代码中安装 decord,以便在加载视频时使用 decord。
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-3B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-3B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2", # 安装FA2,以降低对显存的占用,24GB可以足以运行
)
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-3B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
以上就不需要量化就能拥有自己的贾维斯了🤗🤗🤗


















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









