







第九章 集合
9.1 集合的结构
前言
- 因为数组在定义完成后长度确定,增删数据操作不方便,所以引出集合,集合非常适合做元素个数不确定,且要进行增删操作的业务场景。
- 集合类是类型可变,大小可变(数组只能存储同一类元素,大小固定)
- 集合中只能存储引用类型,不支持基本数据类型。基本类型会自动转成对应包装类。
- 集合都是支持泛型的
- 集合存储的是地址
- Collection不支持索引
9.1.1 集合概述
- 集合实际上就是一个容器,数组也是集合。
- 集合不能直接存储基本数据类型,也不能直接存储java对象,集合当中存储的都是java对象的内存地址。(或者说集合中存储的是引用。)
- 在java中每一个不同的集合,底层会对应不同的数据结构。往不同的集合中存储元素,等于将数据放到了不同的数据结构当中。
- 什么是数据结构?数据存储的结构就是数据结构。不同的数据结构,数据存储方式不同。例如:数组、二叉树、链表、哈希表…
集合分为两大类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DMLhMSdQ-1677422808587)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230223181456576.png)]
-
一类是单个方式存储元素:
单个方式存储元素,这一类集合中超级父接口:java.util.Collection -
一类是以键值对儿的方式存储元素:
以键值对的方式存储元素,这一类集合中超级父接口:java.util.Map
Collection 下的 List 和 Set 与 Map 共同组成 Java 中最常用的三种集合顶层接口
List 、 Set 、 Map 接口树状图:
-
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序 -
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
9.1.2 集合继承关系
Collection继承结构图:

Map继承结构图:

9.1.3 集合和数组的区别

9.2 Iterable和Collection
9.2.1 Iterable接口
Iterable接口是Collection接口的父接口,在集合中属爷爷辈的顶层 接口
主要有两种功能:
① 实现此接口允许对象成为 for-each 的循环目标
② 提供子接口——迭代接口 Iterator
Iterator迭代器作用:遍历集合中的数据
主要方法:
boolean hasNext();//如果仍有元素可以迭代,则返回true。
E next();//返回迭代的下一个元素。
迭代器迭代元素的过程中不能使用集合对象的remove方法删除元素,要使用迭代器Iterator的remove方法来删除元素,防止出现异常:ConcurrentModificationException
迭代原理图:

9.2.2 Collection接口
- Collection是单列集合的顶层父类接口,它主要用来定义集合的约定。
- Collection 分为 List 和 Set 两大分支。List 必须按照插入的顺序保存元素,而 Set 不能有重复的元素。
Collection 的主要方法:

9.3 List
前言
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fz1kQEa6-1677422808589)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230224154000661.png)]
特点:
-
List 集合的主要特点:有序、可重复、有索引
-
List 接口也是一个顶层接口,它集成了Collection接口,同时也是ArrayList、LinkedList等集合元素的父类。
-
List 接口的实现:
- ArrayList:查询数据比较快,添加和删除数据比较慢(基于可变数组)
- LinkedList:查询数据比较慢,添加和删除数据比较快(基于链表数据结构)
- Vector:Vector 已经不建议使用,Vector 中的方法都是同步的,效率慢,已经被ArrayList
取代 - Stack 是继承Vector 实现了一个栈,栈结构是后进先出,目前已经被LinkedList 取代
常用方法:
//向指定下标添加元素,后面的元素后移一位(效率低)
void add(int index, Object element);
//删除指定下标位置的元素
Object remove(int indext);
//修改指定位置的元素
Object set(int index, Object element);
//根据下标获取元素,可通过下标遍历,List集合特有
Object get(int index);
//获取指定对象第一次出现处的索引
int indexOf(Object o);
//获取指定对象最后一次出现处的索引
int lastIndextOf(Object o);
//列表迭代器
ListIterator listIterator();
//截取集合
List subList(int fromIndex, int toIntex);
9.3.1 ArrayList(数组)
特点:
- 有序、可重复、有索引
- 底层是数组结构,
- 查询数据快,增删数据慢。
- 可存单个或多个null
- 线程不安全,效率高
扩容细节:
-
底层是Object[]数组,
transient Object[] elementData(transient 修饰的属性不会被序列化)。 -
因为底层是数组,所以查找和遍历迅速,但是不适合插入和删除(数组的缺点是每个元素之间不能有间隔,所以在插入或者删除元素时,需要对数组进行复制、移动、代价比较高)
-
当使用无参构造器创建ArrayList对象时,elementData[]的容量是0,第一次添加为10.再次扩容为1.5倍
-
当使用制定大小的有参构造器创建ArrayList对象时,扩容为1.5倍
-
ArrayList 扩容相当于数组扩容,存在拷贝效率低的问题。
-
但是向尾部增删数据效率还是高的。
-
ArrayList 不是线程安全的容器,如果多个线程同时修改了ArrayList的结构会导致线程安全问题,可用线程安全的List作为替代,例如:Collections.synchronizedList
-
基本等于Vector除了线程不安全
List list = Collections.synchronizedList(new ArrayList(...));
9.3.2 LinkedList(双向链表)
链表结构简介:
1)单向链表

2)双向链表
- 存在两个属性first、last分别指向首节点和尾节点
- 每个节点(Node对象)存在prev(上个节点地址)、next(下个节点地址)、item(存放数据)三个属性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BBRfidK8-1677422808591)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230223203941116.png)]

LinkedList内存图:

3)LinkedList 底层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xHWzWx7y-1677422808594)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230223203138056.png)]
特点:
- 有序、有索引、元素可重复
- LinkedList 底层是用链表结构(实现双向链表双端队列)存储数据的,很适合数据的动态插入和删除
- 可以添加任意元素包括null,
- 查询数据慢,
- 增删数据快。
- 他还提供了List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆
栈、队列和双向队列使用。 - LinkedList 也不是线程安全的,如果要避免线程安全问题,链表必须外部加锁,或者使用:
List list = Collections.synchronizedList(new LinkedList(...));
- LinkedList 在内存中的地址是不连续的。
- LinkedList 查找元素只能从头结点或尾结点开始遍历查找。
- LinkedList 随机增删元素只改变前后两个节点的内容,而不像 ArrayList 那样导致大量元素位移。
特有方法:
//插入元素
void addFirst(E e);
void addLast(E e);
//获取元素
E getFirst();
E getLast();
//删除元素
E removeFirst();
E removeLast();
9.3.3 Vector
特点:
- 有序、可重复、有索引
- 底层是数组结构,
protected Object[] elementData; - 查询数据快,增删数据慢。
- 可存单个或多个null
- 线程安全的,方法带有synchronized关键字,效率低
扩容细节:
- 当使用无参构造器创建Vector对象时,elementData[]的容量是0,第一次添加为10.再次扩容为2倍
- 当使用制定大小的有参构造器创建Vector对象时,扩容为2倍
9.4 Set
前言
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0PtTKA00-1677422808595)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230224153924568.png)]
特点:
-
无序(不作要求)、不可重复(最多只能有一个null)、没有索引
-
对象的相等性本质是对象hashCode 值(java 是依据对象的内存地址计算出的此序号)判断
的,如果想要让两个不同的对象视为相等的,就必须覆盖Object 的hashCode 方法和equals 方
法。 -
Set 接口的实现:
-
HashSet:基于哈希表,元素无序且唯一
-
TreeSet:基于二叉树,元素有序且唯一
-
LinkHashSet:基于链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性
9.4.1 哈希表、二叉树
哈希表:
-
哈希表是一种数据结构,哈希表能够提供快速存取操作。
-
哈希表是一个数组和单向链表的结合体,也就是哈希表等同于,一个一维数组,数组中每个元素是一个单向链表,单向链表中的Node节点有四个属性(hash哈希值,key,value,next下一节点地址)
-
正常的数组,如果需要查询某个值,需要对数组进行遍历,只是一种线性查找,查找的速度比较慢。
-
如果数组中的元素值和下标能够存在明确的对应关系,那么通过数组元素的值就可以换算出数据元素的下标,通过下标就可以快数定位数组元素,这样的数组就是哈希表。
哈希表图解:

二叉树:
二叉树图解:

9.4.2 HashSet(Hash 表)
特点:
- 无序、不重复、无索引
- 非线程安全
- HashSet底层实际是使用HashMap存储数据,
- HashSet实际上是HashMap的key部分,
- 而判断是否同一条数据是hashcode和equals() 共同作用的结果。
存储原理
-
Hashset 集合底层采取的哈希表存储的数据。
-
1.默认一个长度为16,加载因子0.75(就是存满12个时自动扩容,每次扩容都是原来的两倍)的数组,数组名为table,
-
2.根据元素的哈希值与数组长度计算出存入位置,
-
3.判断当前位置是否为空,不空就存进去,如果不为空,调用equals方法比较(去重),如果一样,则不存,如果不一样jdk7前,新元素占老元素位置,指向老元素,jdk8 新元素挂在老元素下面。
-
Jdk8后,如果挂的长度等于8 但table小于64此时是扩表(原来的内容不变,此时再加元素可能导致,某一链表超过8)
-
如果挂在长度等于8(第9个元素开始加入)且table等于64就自动转换成红黑树
-
去重的原理:为了避免相同内容的不同对象,因为哈希值的不同掉入不同的存储位置而保留下来,所以要重写hashcode() 和equals()方法。
HashSet hashSet = new HashSet(); 1. 执行HashSet() public HashSet(){ map = new HashMap<>(); } hashSet.add("java"); 2. 执行add() public boolean add(E e) { //e = java,PRESENT用于占位,因为 map是k-v return map.put(e, PRESENT)==null; } 3.执行put() public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } 4.执行hash() static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } 5.执行hashCode() public int hashCode() { int h = hash; if (h == 0 && value.length > 0) {//hash =0;value =java char val[] = value; //val[] = [j,a,v,a] for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; } 6.执行putVal() final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {}哈希表是一种 对于增删改查数据性能都比较好的结构,原因是通过哈希值,能迅速找到在对应的位置
Jdk8前, 哈希表是数组+链表组成
Jdk8后, 哈希表是数组+链表+红黑树组成
哈希值 是jdk根据对象对的地址,按照某种规则算出来的int类型的数值。
9.4.3 TreeSet(红黑树)
- 按照大小默认升序排序、无重复、无索引。
- TreeSet()是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置,不允许null值。
- Integer 和String 对象都可以进行默认的TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现Comparable 接口,并且覆写相应的compareTo()函数,才可以正常使用。
- 在覆写compare()函数时,要返回相应的值才能使TreeSet 按照一定的规则来排序。
- 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
- 底层是基于红黑树的数据结构实现排序的,增删改查性能较好。
- 该类是一定要排序的,按照默认顺序
- 对于数值类型:按照大小升序
- 对于引用类型:默认按照首字符的编码升序
9.4.4 LinkHashSet
-
有序(每一个元素都有before、after属性 可以找到前一个元素后一个元素地址所以有序,插入顺序与查询顺序一样)、不重复、无索引
-
非线程安全
-
对于LinkedHashSet 而言,它继承与HashSet 、又基于LinkedHashMap(HashMap子类) 来实现的。
-
LinkedHashSet 底层使用LinkedHashMap (数组+双向链表)来保存所有元素,
-
1.默认一个长度为16,加载因子0.75(就是存满12个时自动扩容,每次扩容都是原来的两倍)的数组,数组名为table,每一个节点是LinkedHashMap$Entry(静态内部类)
-
2.根据元素的哈希值与数组长度计算出存入位置,
-
3.判断当前位置是否为空,不空就存进去,如果不为空,调用equals方法比较(去重),如果一样,则不存,如果不一样jdk7前,新元素占老元素位置,指向老元素,jdk8 新元素挂在老元素下面。
-
Jdk8后,如果挂的长度等于8 但table小于64此时是扩表(原来的内容不变,此时再加元素可能导致,某一链表超过8)
-
如果挂在长度等于8(第9个元素开始加入)且table等于64就自动转换成红黑树
9.5 Map
前言
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aeNVEmpI-1677422808597)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230224153611904.png)]
特点:
-
Map集合的键是无序、不重复、无索引、值不做要求(可重复)
-
Map集合是一种双列集合,每个元素包含两个数据,每个元素的格式:key = value(键值对元素)
-
Map集合的特点都是由键决定的。
-
Map集合后面重复的键对应的值会覆盖前面重复键的值
-
键值对都可以是null
-
Map实现类特点:
- HashMap:无序、不重复、无索引、值不做要求(可重复)–和map体系一致。
- LinkedHashMap: 有序、不重复、无索引、值不做要求(可重复)。
- TreeMap:元素按照键是排序,不重复,无索引,值不做要求的。
-
Map 中可以放置键值对,也就是每一个元素都包含键对象和值对象,Map 实现较常用的为HashMap,HashMap 对键对象的存取和HashSet 一样,仍然采用的是哈希算法,所以如果使用自定类作为Map 的键对象,必须复写equals 和hashCode 方法。
-
Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射,你可以通过“键”查找“值”。一个 Map 中不能包含相同的 key ,每个 key 只能映射一个 value 。
常用方法:
//清除所有映射
void clear();
//查询Map是否包含指定key
boolean containsKey(Object key);
//将Map转换为Set集合,集合的每个元素都是Map.Entry类型
Set<Map.Entry<K,V>> entrySet();
//返回指定key对应的value,如果没有该key则返回null
V get(Object key);
//查询Map是否为空,如果空则返回true
boolean isEmpty();
//返回该Map中所有key组成的Set集合
Set<K> keySet();
//添加一个键值对,如果已有一个相同的Key则覆盖旧的键值对
V put(K key, V value);
//将指定的Map的键值对复制到Map中
void putAll(Map<? extends K,? extends V> m);
//删除指定Key所对应的键值对,返回关联的value,如果key不存在则返回null
V remove(Object key);
//返回Map里键值对的个数
int size();
//返回Map中所有的value组成的集合
Collection<V> values();
Map转为Set集合
底层是数组+链表+红黑树,为了方便遍历,会创建一个EntrySet集合,该集合存放Map的每一个Node,EntrySet定义类型是Map.Entry实际存放的还Map$Node
entrySet()方法的图示:

9.5.1 HashMap
特点:
-
键是无序、不重复、无索引、值不做要求(可重复)
-
底层是数组+链表+红黑树
-
HashMap 最多只允许一条记录的键为null,允许多条记录的值为null。
-
HashMap 非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。
-
如果需要满足线程安全,可以用Collections 的synchronizedMap 方法使HashMap 具有线程安全的能力,或者使用ConcurrentHashMap。
-
1.默认一个长度为16,加载因子0.75(就是存满12个时自动扩容,每次扩容都是原来的两倍)的数组,数组名为table,
-
2.根据Key的哈希值与数组长度计算出存入位置,
-
3.判断当前位置是否为空,不空就存进去,如果不为空,调用equals方法比较(去重),如果一样,则不存,如果不一样jdk7前,新元素占老元素位置,指向老元素,jdk8 新元素挂在老元素下面。
-
Jdk8后,如果挂的长度等于8 但table小于64此时是扩表(原来的内容不变,此时再加元素可能导致,某一链表超过8)
-
如果挂在长度等于8(第9个元素开始加入)且table等于64就自动转换成红黑树

大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色
的实体是嵌套类Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的next。
- capacity:当前数组容量,始终保持2^n,可以扩容,扩容后数组大小为当前的2 倍。
- loadFactor:负载因子,默认为0.75。
- threshold:扩容的阈值,等于capacity * loadFactor
- Java8 对HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由数组+链表+红黑树组成。
根据Java7 HashMap 的介绍,我们知道,查找的时候,根据hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为O(n)。为了降低这部分的开销,在Java8 中,当链表中的元素超过了8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为O(logN)。

9.5.2 TreeMap

如果是自定义类型,需要实现 Comparable 接口,并重写 compareTo() 方法,才能实现排序。
9.5.3 HashTable
特点:
- 无序、不重复、无索引、值不做要求(可重复)
- 键和值都不能为null
- 线程安全
- 使用方法基本和HashMap一样
- 1.默认一个长度为11,加载因子0.75(就是存满8个时自动扩容,每次扩容都是原来的两倍+1)的数组,数组名为table,每一个节点是HashTable$Entry(静态内部类)
- 2.根据元素的哈希值与数组长度计算出存入位置,
- 3.判断当前位置是否为空,不空就存进去,如果不为空,调用equals方法比较(去重),如果一样,则不存,如果不一样jdk7前,新元素占老元素位置,指向老元素,jdk8 新元素挂在老元素下面。
- Jdk8后,如果挂的长度等于8 但table小于64此时是扩表(原来的内容不变,此时再加元素可能导致,某一链表超过8)
- 如果挂在长度等于8(第9个元素开始加入)且table等于64就自动转换成红黑树
9.6 集合的选取
判断存储的类型(一组对象还是一组键值对)
一组对象:Collection接口
- 允许重复:List
- 增删多:LinkedList(双向链表)
- 改查多:
- 线程不安全:ArrayList(数组)
- 线程安全:Vector(数组)
- 不允许重复:Set(底层Map)–以下实现线程不安全
- 无序:HashSet(底层实际是使用HashMap,维护一个Hash表(Jdk7:数组+链表 Jdk8:数组+链表+红黑树))
- 排序:TreeSet(红黑树)
- 插入和取出顺序一致:LinkHashSet(底层使用LinkedHashMap (数组+双向链表))
一组键值对:Map
- 键无序:
- 线程不安全 :HashMap(维护一个Hash表(Jdk7:数组+链表 Jdk8:数组+链表+红黑树))
- 线程安全:HashTable(维护一个Hash表(Jdk7:数组+链表 Jdk8:数组+链表+红黑树))
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap (数组+双向链表)
9.7 线程安全集合的解决方案
9.7.1 线程安全的集合
Collection体系集合下,除Vector以外的线程安全集合
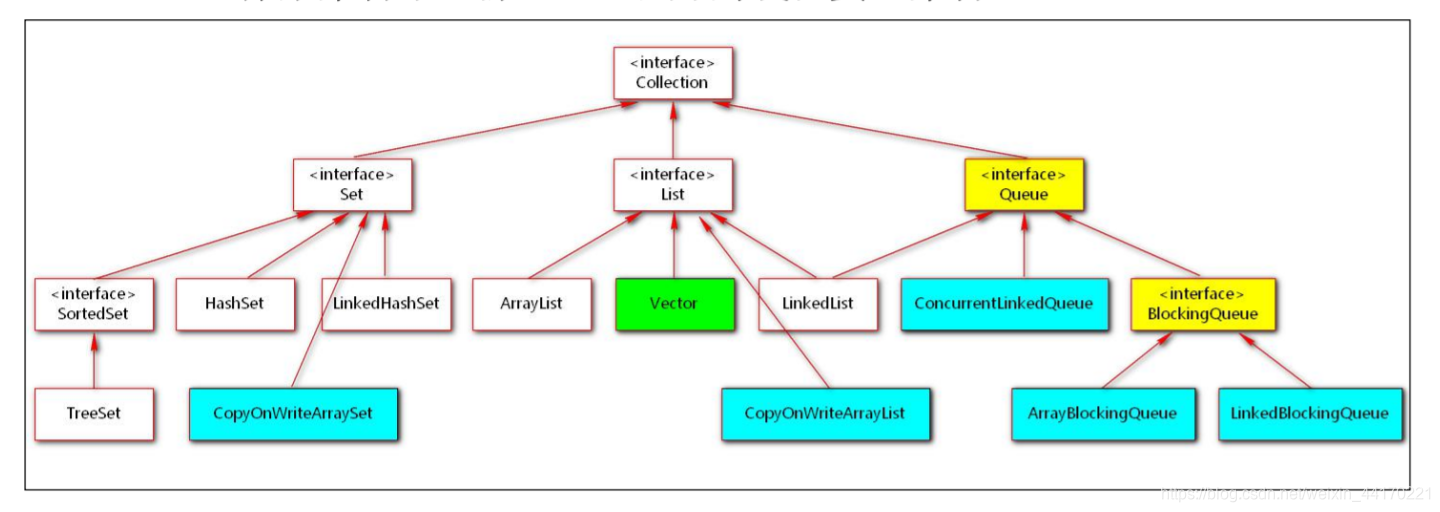
9.7.2 Collections工具类
Collections工具类位于 java.util 包下,这个类只包含操作或返回集合的静态方法。
常用方法:
//线程安全类
static <T> Collection<T> synchronizedCollection(Collection<T> c);
static <T> List<T> synchronizedList(List<T> list);
static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
static <T> Set<T> synchronizedSet(Set<T> s);
static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m);
static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s);
//算法类
static <T extends Comparable<? super T>> void sort(List<T> list);//排序
static <T> void sort(List<T> list, Comparator<? super T> c);//指定比较器排序
static void swap(List<?> list, int i, int j);//交换元素
public class ArrayListDemo {
public static void main(String[] args) {
List<String> list = Collections.synchronizedList(new ArrayList<>());
for (int i = 0; i < 100; i++) {
new Thread(() ->{
//向集合添加内容
list.add(UUID.randomUUID().toString().substring(0,8));
//从集合获取内容
System.out.println(list);
}, String.valueOf(i)).start();
}
}
}
9.7.2 JUC
CopyOnWriteArrayList
- 线程安全的ArrayList,加强版读写分离
- 写有锁,读无锁,读写之间不堵塞,优于读写锁
- 写入时,先copy一个容器副本、再添加新元素,最后替代引用
- 使用方式与ArrayList无异
public class TestCopyOnWriteArrayList {
public static void main(String[] args) {
List<String> list = new CopyOnWriteArrayList<String>();
}
}
CopyOnWriteArraySet
- 线程安全的Set,底层使用CopyOnWriteArrayList实现
- 唯一不同在于,使用addIfAbsent() 添加元素,会遍历数组
- 如存在元素,则不添加(扔掉副本)
public class TestCopyOnWriteArraySet {
public static void main(String[] args) {
Set<String> set = new CopyOnWriteArraySet<String>();
}
}
ConcurrentHashMap
- 初始容量默认为16段(Segment),使用分段锁设计
- 不对整个Map加锁,而是为每个Segment加锁
- 当多个对象存入同一个Segment时,才需要互斥
- 最理想状态为16个对象分别存入16个Segment,并行数量16
- 使用方式与HashMap无异
- 注意:JDK1.7版本源码解释
import java.util.HashMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.CopyOnWriteArraySet;
public class TestCopyOnWriteArrayList {
public static void main(String[] args) {
//写有锁,读无锁的集合
CopyOnWriteArrayList<String> onWriteArrayList = new CopyOnWriteArrayList<String>();
//写操作,有锁
onWriteArrayList.add("A");//将底层数组做了一次复制,写的是新数组,完成复制后再将新数组替换成旧数组
onWriteArrayList.add("B");//每次调用一次,底层方法扩容一次!
//读操作,无锁
onWriteArrayList.get(1);//读的是写操作完成之前的旧数组!写完之后才能读到新数组的新值
for (int i = 0; i < onWriteArrayList.size(); i++) {
System.out.println(onWriteArrayList.get(i));
}
//无序、无下标、不允许重复
CopyOnWriteArraySet<String> onWriteArraySet = new CopyOnWriteArraySet<String>();
//写操作,表面使用的是add方法,底层实际是使用的CopyOnWriteArrayList的addIfAbsent()来判断要插入的新值是否存在
onWriteArraySet.add("A");
onWriteArraySet.add("B");
onWriteArraySet.add("C");
for (String string : onWriteArraySet) {
System.out.println(string);
}
HashMap<String, String> hashMap = new HashMap<String, String>();
//分段锁设计 Segment JDK1.7做法
//CAS交换算法和同步锁 同步锁锁的是表头对象,拿到锁的对象要先做节点遍历
//查看有没有相同的key值,相同覆盖,不同则挂在最后一个节点的next上
ConcurrentHashMap<String, String> concurrentHashMap = new ConcurrentHashMap<String, String>();
concurrentHashMap.put("A", "哎");
System.out.println(concurrentHashMap.keySet());
System.out.println(concurrentHashMap.values());
}
}
Queue接口(队列)
- Collection的子接口,表示队列FIFO(First In First Out),意为先进先出
- 常用方法:
- boolean add(E e) //顺序添加一个元素(到达上限后,再添加则会抛出异常
- E remove() //获得第一个元素并移除(如果队列没有元素时,则会抛出异常)
- E element() //获得第一个元素但不移除(如果队列没有元素时,则会抛出异常)
- 返回特殊值: 推荐使用
- boolean offer(E e) //顺序添加一个元素(到达上限后则会返回false)
- E poll() //获得第一个元素并移除(如果队列没有元素时,则返回null)
- E keep() //获得第一个元素但不移除(如果队列没有元素时,则返回null)
ConcurrentLinkedQueue
- 线程安全、可高效读写的队列,高并发下性能最好的队列
- 无锁、CAS比较交换算法,修改的方法包含三个核心参数(V,E,N)
- V: 要更新的变量
- E: 预期值
- N: 新值
只有当V==E时,V=N;否则表示已被更新过,则取消当前操作
public class TestConcurrentLinkedQueue {
public static void main(String[] args) {
Queue<String> queue = new ConcurrentLinkedQueue<String>();
queue.offer("Hello");//插入
queue.offer("World");//插入
queue.poll();//删除Hello
queue.peek();//删除World
}
}
BlockingQueue接口(阻塞)
- Queue的子接口,阻塞的队列,增加了两个线程状态为无限期等待的方法
- 方法:
- void put(E e) //将指定元素插入此队列中,如果没有可用空间,则等待
- E take() //获取并移除此队列头部元素,如果没有可用元素,则等待
- 可用于解决生产者、消费者问题
阻塞队列
ArrayBlockingQueue
数组结构实现,有界队列(手工固定上限)
public class TestArrayBlockingQueue {
public static void main(String[] args) {
BlockingQueue<String> abq = new ArrayBlockingQueue<String>(10);
}
}
LinkedBlockingQueue
链表结构实现,无界队列(默认上限Integer.MAX_VALUE)
public class TestArrayBlockingQueue {
public static void main(String[] args) {
BlockingQueue<String> abq = new LinkedBlockingQueue<String>();
}
}
队列接口的使用
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class TestQueue {
public static void main(String[] args) {
// 列表,尾部添加(指定下标)
// 链表,头尾添加
// 队列,FIFO
// 如果要强制LinkedList只遵循队列的规则!
// Queue<String> link = new LinkedList<String>(); //遵循队列规则的链表
LinkedList<String> link = new LinkedList<String>();
link.offer("A");
link.offer("B");
link.offer("C");
// 用列表的方式打乱了FIFO队列的规则
// link.add(0,"D");
// 强制LinkedList后,不能调用带有下标的add方法
System.out.println(link.peek());// 队列中的第一个元素!
// 严格遵守了队列的规则,且是线程安全的,采用了CAS交换算法
Queue<String> q = new ConcurrentLinkedQueue<String>();
// 1.抛出异常的 2.返回结果的
q.offer("A");
q.offer("B");
q.offer("C");
q.poll();// 删除表头
System.out.println(q.peek());// 获得表头
// 手动固定队列上限
BlockingQueue<String> bq = new ArrayBlockingQueue<String>(3);
// 无界队列 最大有 Integer.MAX_VALUE
BlockingQueue<String> lbq = new LinkedBlockingQueue<String>();
}
}
9.7.3 集合接口总结
- ExecutorService线程接口、Executors工厂
- Callable线程任务、Future异步返回值
- Lock、ReenTrantLock重入锁、ReentrantReadWriteLock读写锁
- CopyOnWriteArrayList线程安全的ArrayList集合
- CopyOnWriteArraySet线程安全的Set集合
- ConcurrentHashMap线程安全的HashMap集合
- ConcurrentLinkedQueue线程安全的Queue队列
- ArrayBlockingQueue线程安全的Queue队列(生产者、消费者)















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









