






一、为什么要引入卷积神经网络
当输入的数据是图片200×200的彩色图片时,如果采用传统的神经网络那么一共有200×200×3个输入。而隐层的每一个神经元都会有(200×200×3+1)个权重值,这个数量非常的大。同时当训练的参数过多时,神经网络易出现过拟合的情况。
鉴于上面的情况,卷积神经网络应运而生。
卷积神经网络解决了传统较深的网络参数太多,很难训练的问题,使用了逗局部感受野地和逗权植共享地的概念,大大减少了网络参数的数量。关键是这种结构确实很符合视觉类任务在人脑上的工作原理。
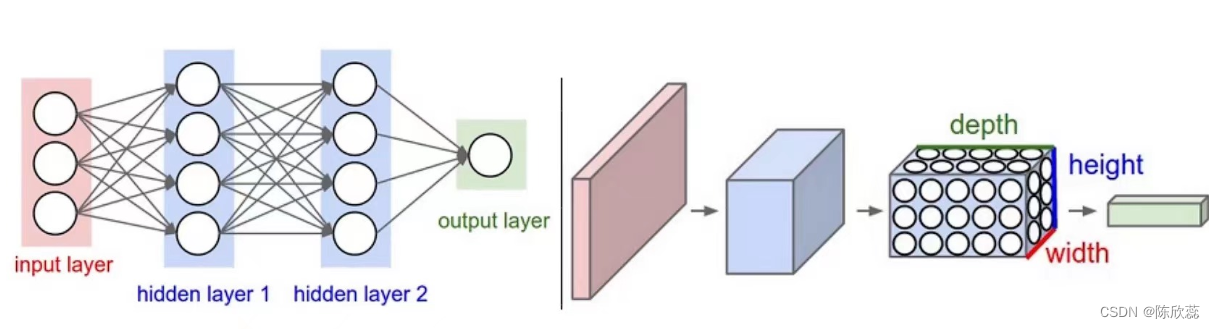 左边图片表示的传统的神经网络,右边的图片表示卷积神经网络
左边图片表示的传统的神经网络,右边的图片表示卷积神经网络
二、卷积神经网络的原理
1.什么是卷积核
在数学上,卷积核的标准定义是两个函数在反转和移位后的乘积的积分:
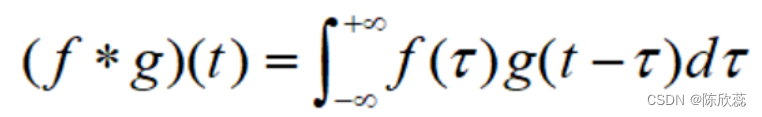
其中,函数g一般称为过滤器,函数f指的是信号或者图像。在卷积神经网络里,卷积核其实就是一个过滤器,但在深度学习里,执行逐元素的乘法和加法,这个称为互相关,在深度学习里称为卷积。
为什么要将卷积应用于神经网络呢?
因为上个世纪科学家就发现,视觉皮层的很多神经元都有一个小的局部感受野,神经元只对有限区域的感受野上的刺激物做出反应。不同的感受野可以重叠,他们共同铺满整个视野。并且发现,一些神经元仅仅对横线有反应,有一些神经元对其他方向的线条有反应,有些神经元的感受野比较大。因此,高级别的神经元的刺激是源于相邻低级别神经元的反应。
通过这个观点,通过卷积核提取图像的特征并生成一个个神经元,再经过深层的连接,就构建出了卷积神经网络。
2.卷积核包括核大小(kernel size)、填充(padding)和步长(stride)
卷积核大小:卷积核定义了卷积的大小范围,在网络中代表感受野的大小,二维卷积核最常见的就是 3×3 的卷积核和5×5的卷积核。一般情况下,卷积核越大,感受野越大,看到的图片信息越多,所获得的全局特征越好。但大的卷积核会导致计算量的暴增,计算性能也会降低。
步长:卷积核的步长代表提取的精度, 步长定义了当卷积核在图像上面进行卷积操作的时候,每次卷积跨越的长度。对于size为2的卷积核,如果step为1,那么相邻步感受野之间就会有重复区域;如果step为2,那么相邻感受野不会重复,也不会有覆盖不到的地方;如果step为3,那么相邻步感受野之间会有一道大小为1颗像素的缝隙,从某种程度来说,这样就遗漏了原图的信息。
填充:卷积核与图像尺寸不匹配,会造成了卷积后的图片和卷积前的图片尺寸不一致,为了避免这种情况,需要先对原始图片做边界填充处理。
3.对于输入灰度图片即单通道图片卷积的过程

这里的filter是一个3*3矩阵,步长是1,填充为0。filter在输入数据中滑动。在每个位置,它都在进行逐元素的乘法和加法。每个滑动位置以一个数字结尾,最终输出为3 x 3矩阵。
4.对于输入为三通道彩色图片的卷积过程
当输入是三通道的彩色图片时,卷积核的大小不在是输入为单通道图片的3×3大小。卷积核的大小要考虑三维的信息,即考虑到每个通道的信息,此时卷积核的大小为3×3×3。同理当卷积应用于神经网络中的其他层时,上一层的输出假设是5×5×16,那么此时卷积要考虑16个通道的数据,此时卷积核的大小一般为3×3×16。而此时做一次卷积的输出为3×3×1而输出的通道数取决于卷积核的个数,假设有10个卷积核做卷积,那么输出的大小为3×3×10。卷积的具体过程如下。


三、常见的神经网络
1.LeNet
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
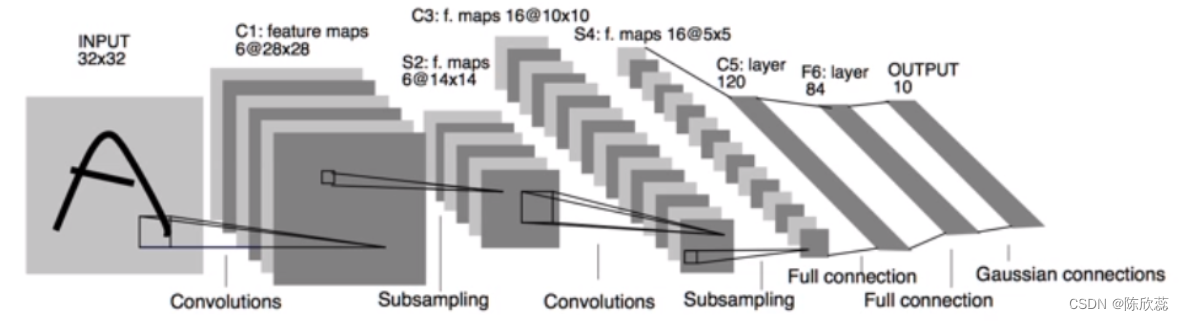
输入:32*32大小的原图;
1)6个5*5的核卷积,得到28*28*6的特征图,pooling:2*2的核,步长为2,结果为14*14*6的特征图;
2)16个5*5*6的核卷积,得到10*10*16的图,pooling:2*2的核,步长为2,结果为5*5*16的特征图;
3)120个5*5*16的核卷积,得到120*1的向量,进入全连接层;
4)由120*84*10的BP网络构成全连接层,输出层是10个节点,对应0~9十个类别的数字。
损失函数:
网络性能指标:
1)损失函数越小越好,但防止过拟合;
2)训练样本的正确率;
3)测试样本的正确率。
特点:
卷积->池化->卷积->池化->全连接->分类。
卷积层深度:从小到大,从大到小。(6->16->Dense->全连接)
下面是LeNet识别手写数字3的过程,以及每一层神经网络提取到的图片中的特征

2.AlexNet
AlexNet网络的结构如下:
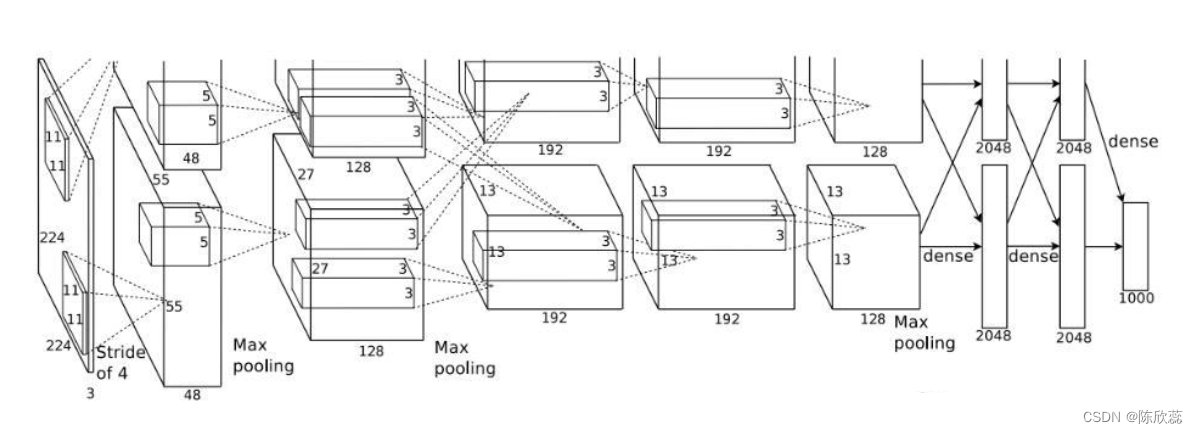
Conv1
输入图像大小: 224 * 224 * 3(RGB图像),但是会将输入图像预处理为227 * 227 * 3的图像
卷积核(filter)大小:11 * 11
卷积核个数:96
步长(stride):4
padding方式:VALID
输出featureMap大小:55 * 55 * 96 [(227-11+0)/4+1=55]
Pool1
输入图像大小:55 * 55 * 96
采样大小:3 * 3
步长:2
padding方式:VALID
输出featureMap大小:27 * 27 * 96 [(55-3)/2+1=27]
Conv2
输入图像大小: 27 * 27 * 96
卷积核(filter)大小:5 * 5
卷积核个数:256
步长(stride):1
padding方式:SAME
输出featureMap大小:27 * 27 * 256
Pool2
输入图像大小:27 * 27 * 256
采样大小:3 * 3
步长:2
padding方式:VALID
输出featureMap大小:13 * 13 * 256 [(27-3)/2+1=13]
Conv3
输入图像大小: 13 * 13 * 256
卷积核(filter)大小:3 * 3
卷积核个数:384
步长(stride):1
padding方式:SAME
输出featureMap大小:13 * 13 * 384
Conv4
输入图像大小: 13 * 13 * 384
卷积核(filter)大小:3 * 3
卷积核个数:384
步长(stride):1
padding方式:SAME
输出featureMap大小:13 * 13 * 384
Conv5
输入图像大小: 13 * 13 * 384
卷积核(filter)大小:3 * 3
卷积核个数:256
步长(stride):1
padding方式:SAME
输出featureMap大小:13 * 13 * 256
Pool3
输入图像大小:13 * 13 * 256
采样大小:3 * 3
步长:2
padding方式:VALID
输出featureMap大小:6 * 6 * 256 [(13-3)/2+1=6]
FC6
全连接层,这里使用4096个神经元,对256个大小为6X6特征图,进行一个全连接,也就是将6X6大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到,之后再进行一个dropout操作,也就是随机从4096个节点中丢掉一些节点信息(清0操作),然后就得到新的4096个神经元。
FC7
同上
F8
采用的是1000个神经元,然后对FC7中4096个神经元进行全连接,然后通过sofmax,得到1000个类别的概率值,也就是预测值。
AlexNet的特点:
1.使用ReLu作为激活函数
2.数据增广(Data Augmentation增强)抑制过拟合
3.使用Dropout抑制过拟合
4.重叠池化
5.局部归一化(Local Response Normalization,简称 LRN)
6.多GPU训练


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









