






本文章参考网络视频以及菜鸟教程等内容进行Pandas核心内容的梳理,包含大部分当前最常用的一些功能,帮助快速入门或复习Pandas。
文章内容
- 基础操作
- 对象创建和数据查看
- 实际工作常用命令
- 常用工作流
- 字符串、时间信息的处理
- 表格的排序和拼接
- 长表格转宽表格
- 注意事项
介绍
Pandas是什么
Pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib的第三方数据分析库,与后两者共同构成了python数据分析的基础工具包,广泛应用在学术、金融、统计学等各个数据分析领域。
数据结构
① Series:类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。由索引(index)和列组成

② DataFrame:表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由多个 Series 组成的字典(共同用一个索引)。

基础操作-1:对象创建和数据查看
创建Series对象
pandas.Series( data, index, dtype, name, copy):创建一个Series对象
data:一组数据(ndarray)index:数据索引标签,默认为0dtype:数据类型,默认自动判断name:设置名称copy:拷贝数据,默认为False
① 由列表创建Series
创建时不指定索引和名称
lst = [10, 20, 30]
lst_series = pd.Series(lst)
print(lst_series)
# 0 10
# 1 20
# 2 30
# dtype: int64
默认索引为RangeIndex,也就是 0,1,2,⋯0, 1, 2,\cdots0,1,2,⋯
创建时指定索引(行索引)和名称(每行的名称,在表格中作为列索引或行索引)
lst = [10, 20, 30]
lst_series = pd.Series(lst, index=['index-1', 'index-2', 'index-3'], name='test_lst')
print(lst_series)
# index-1 10
# index-2 20
# index-3 30
# Name: test_lst, dtype: int64
② 由字典创建Series
dic = {'10': 11, '20': 21, '30': 31}
dic_series = pd.Series(dic, index=['10', '30', 'test_index'], name='test_lst')
print(dic_series)
# 10 11.0
# 30 31.0
# test_index NaN
# Name: test_lst, dtype: float64
由列表创建需要指定行索引或名称,由字典创建若已在字典中指定过行索引了,在创建Series中再次指定为在其中的索引中进行选择,若在方法中指定在字典中不存在的索引,将会为空值
NaN (Not a Number).
③ Series序列三大属性:name,values,index
name:前面提到过,就是该序列的名称,组装成DataFrame后会成为表格的column或index(下面会介绍)values:Series序列中的所有值index:Series序列的索引值
ser = pd.Series([10, 20, 30], name='test_series', index=['day1', 'day2', 'day3'])
print(ser.name) # test_series
print(ser.values) # [10 20 30]
print(ser.index) # Index(['day1', 'day2', 'day3'], dtype='object')
创建DataFrame对象
pandas.DataFrame(data, index, columns, dtype, copy):DataFrame构造方法
data:一组数据(ndarray,series,map,lists,dict等类型)index:索引值 / 行标签columns:列标签dtype:数据类型copy:拷贝数据,默认为False
如果参数
index和columns未指定,默认为 RangeIndex(0, 1, 2,…, n),也就是 0,1,2,⋯0,1,2,\cdots0,1,2,⋯
① 利用Python列表创建DataFrame对象

workout_dict = [
[420, 300, 800, 100],
[40, 20, 30, 10],
['run', 'ride', 'jump', 'walk'],
]
workout = pd.DataFrame(workout_dict)
利用这种形式创建的
DataFrame表格,默认是按列的,每个子列表的第一个元素构成表格中的每列(Series)
② 利用Python字典创建DataFrame对象

import pandas as pd
# 利用python字典创建DataFrame表格
workout_dict = {
'calories': [420, 300, 800, 100],
'duration': [40, 20, 30, 10],
'type': ['run', 'ride', 'jump', 'walk'],
}
workout = pd.DataFrame(workout_dict)
pd.DataFrame()传入一个字典,根据字典创建表格(DataFrame)对象;字典中的key为表格中的column名称,也就是列索引,每行默认是列表中对应元素的索引,也就是行索引.
③ 利用Series对象创建DataFrame对象


# 指定多个Series创建,默认Series名称作为行索引,元素横向排列(左图)
test_series = pd.Series([1,2,3], name='test')
test_df1 = pd.DataFrame([test_series, test_series])
print(test_df1)
# 指定单个Series创建,默认Series名称作为列索引,元素纵向排列(右图)
test_df2 = pd.DataFrame(test_series)
print(test_df2)
④ 在字典中指定每行的行索引创建DataFrame对象

workout_dict = {
'calories': {'day1': 420, 'day2': 300, 'day3': 800, 'day4': 100},
'duration': {'day2': 40, 'day1': 20, 'day3': 30, 'day4': 10},
'type': {'day3': 'run', 'day2': 'ride', 'day1': 'jump', 'day4': 'walk'},
}
workout = pd.DataFrame(workout_dict)
也可以指定行索引,在指定行索引时,默认按字典中第一个元素的行索引顺序,例如上方案例中’duration’列和
type列元素中的顺序和第一列中元素顺序相同.
⑤ 在字典中不指定行索引,创建对象时指定行索引

workout_dict = {
'calories': [420, 300, 800, 100],
'duration': [40, 20, 30, 10],
'type': ['run', 'ride', 'jump', 'walk'],
}
workout = pd.DataFrame(workout_dict, index=['day1', 'day2', 'day3', 'day4'])
指定行索引中按顺序与原来索引对应,超出数量的索引也会创建,但元素用空值’NaN’替代
NaN:Not a Number,表示空值.
⑥ 在字典中指定行列索引后,创建对象时选择指定行列索引

workout_dict = {
'calories': {'day1': 420, 'day2': 300, 'day3': 800, 'day4': 100},
'duration': {'day2': 40, 'day1': 20, 'day3': 30, 'day4': 10},
'type': {'day3': 'run', 'day2': 'ride', 'day1': 'jump', 'day4': 'walk'},
}
workout = pd.DataFrame(workout_dict, columns=['calories', 'type', 'test_column'], index=['day1', 'day2', 'day4', 'test_row'])
若选中未指定的索引,则该列或该行的值为空值
⑦ 将DataFrame表格转换回Python字典
print(workout.to_dict())
# {
# 'calories': {0: 420, 1: 300, 2: 800, 3: 100},
# 'duration': {0: 40, 1: 20, 2: 30, 3: 10},
# 'type': {0: 'run', 1: 'ride', 2: 'jump', 3: 'walk'},
# }
DataFrame对象利用
to_dict()方法即可转换回python字典,但是对应字典是上述形式,即字典中的value也是字典,该字典的key为DataFrame中的行索引,value为值.
访问或更改DataFrane表格中索引
① 访问整个列索引(column index)或行索引(row index)
# workout是上面创建的DataFrame对象
print(workout.columns) # 列索引 Index(['calories', 'duration', 'type'], dtype='object')
print(workout.index) # 行索引 RangeIndex(start=0, stop=4, step=1)
# 有时会转换成列表处理
print(workout.columns.tolist()) # ['calories', 'duration', 'type']
print(workout.index.tolist()) # [0, 1, 2, 3]
访问DataFrame的索引相关属性,
tolist()方法可转换成python中的list对象.
② 更改DataFrame表格对象的索引

# workout是上面创建的DataFrame对象
workout.index = ['day-1', 'day-2', 'day-3', 'day-4'] # 更改整个行索引
workout.columns = ['colories', 'duration', 'type'] # 更改整个列索引
# 更改部分行索引或列索引
workout = workout.rename(columns={'colories': 'col', 'duration': 'dura'}, index={'day-4': 'day4'})
直接对DataFrame对象的属性
index和columns赋值可以更改整个行索引或列索引.更改部分索引时,也可以单独指定
columns参数或index参数,若不指定则不更改.
访问DataFrame表格中的列与行

# 创建DataFrame表格
workout_dict = {
'calories': [420, 300, 800, 100],
'duration': [40, 20, 30, 10],
'type': ['run', 'ride', 'jump', 'walk'],
}
workout = pd.DataFrame(workout_dict, index=['day1', 'day2', 'day3', 'day4'])
① 选择表格中的列与行 ([])
print(workout['calories']) # 选择一列, 返回Series序列对象
# day1 420
# day2 300
# day3 800
# day4 100
# Name: calories, dtype: int64
print(type(workout['calories'])) # <class 'pandas.core.series.Series'>
print(workout[['calories', 'type']]) # 双口号可以选择多个列, 返回DataFrame表格对象
# calories type
# day1 420 run
# day2 300 ride
# day3 800 jump
# day4 100 walk
# <class 'pandas.core.frame.DataFrame'>
# 选择列后若为Series对象则可进一步选择行(索引或行名称)
print(workout['calories']['day1']) # 420
# DataFrame对象可以用索引指定行(索引或名称)
print(workout['calories'][0]) # 420
# 直接用索引切片默认表示所有列的行
print(workout[0:2])
# calories duration type
# day1 420 40 run
# day2 300 20 ride
# 当然也可以选中某一列应用切片操作
print(workout['calories'][0:2])
# day1 420
# day2 300
# Name: calories, dtype: int64
- 若使用一个
[]且是切片操作,仅支持行索引名称切片或行索引数字切片.- 若使用一个
[]且内嵌一个[],则表示选择列索引,但不支持列索引切片和数字切片操作.- 若使用一个
[]且非切片操作,则第一个[]表示选择列索引.- 注:列索引不能切片或用数字表示,行索引可以切片或用数字表示,且切片操作若为标签切片的话包含最后一个数据,若为整数切片则不含最后一个数据。
② 选择表格中的列与行 (.loc[], .iloc[])
# .loc[]
print(workout.loc['day1',:])
# calories 420
# duration 40
# type run
# Name: day1, dtype: object
print(workout.loc[['day1', 'day2'], 'calories'], workout.loc[['day1', 'day2'], 'calories'])
# day1 420
# day2 300
# Name: calories, dtype: int64
print(workout.loc['day1':'day3', 'calories'], type(workout.loc['day1':'day2', 'calories']))
# day1 420
# day2 300
# day3 800
# Name: calories, dtype: int64 <class 'pandas.core.series.Series'>
print(workout.loc['day1':'day2', 'calories':'duration'], type(workout.loc['day1':'day2', 'calories':'duration']))
# calories duration
# day1 420 40
# day2 300 20 <class 'pandas.core.frame.DataFrame'>
# .iloc[]
print(workout.iloc[0, :], type(workout.iloc[0, :]))
# calories 420
# duration 40
# type run
# Name: day1, dtype: object <class 'pandas.core.series.Series'>
print(workout.iloc[[0 ,1, 2], [0, 1]], type(workout.iloc[[0 ,1, 2], [0, 1]]))
# calories duration
# day1 420 40
# day2 300 20
# day3 800 30 <class 'pandas.core.frame.DataFrame'>
③ .iloc[]、.loc[]、[]之间的区别:
三种方法都能用布尔值来表示索引,如下所示
print(workout[[True, True, True, False]])
# calories duration type
# day1 420 40 run
# day2 300 20 ride
# day3 800 30 jump
print(workout.iloc[[True, True, True, False], [True, True, False]])
# calories duration
# day1 420 40
# day2 300 20
# day3 800 30
print(workout.loc[[True, True, True, False], [True, True, False]])
# calories duration
# day1 420 40
# day2 300 20
# day3 800 30
.iloc[]、.loc[]之间的区别:
.loc[]函数:基于行标签和列标签进行索引的,切片时包含最后一个数据,不能对columns直接使用整数索引..iloc[]函数:基于行和列的位置进行索引的,索引值从0开始,并且切片时不包含最后一个数据, i表示integer,对于index和columns,.iloc[]只能用整数来索引.
与[]之间的一些区别:
[]在一个中括号中只能填一次,不能用逗号间隔一次同时做选择行和列操作[]中若非切片操作,则其中为列索引,而另外两种方法[]中的第一组值都为行索引.
Pandas中也有一些其它的数据选择操作,但不常用也不推荐使用,这三种方法已经基本可以满足需求了.
④ 过滤数据
过滤数据:
| 符号 | 含义 | 运算规则 |
|---|---|---|
| ~ | 按位取反(not) | (T,F) → (F,T) |
| & | 按位取和(and) | (T,T,F,F) & (T,F,T,F) → (T,F,F,F) |
| 按位取或(or) |

filt = ~workout['calories'].isnull() # workout表格中calories字段下的非空值所在的行
workout.loc[filt] # 赋值后效果等同于删除了calories字段下存在缺失值的数据
⑤ 如果访问单个值的话也可以用.at[]
print(workout.at['day1','calories'], type(workout.at['day1','calories'])) # 420 <class 'numpy.int64'>
该方法与上方的三种方法的不同时,得到的数据是该元素的数据类型,而上方的方法返回的都是DataFrame或Series类型.
基础操作-2:实际工作常用命令
外部数据的读取
① 读取excel文件(xlsx、xls)
pd.read_excel(path):读取excel文件
- path:要读取的文件路径
- sheetname:指定读取excel中哪一个工作表,默认sheetname = 0,即默认读取excel中的第一个工作表
- 若sheetname = ‘sheet1’,即读取excel中的sheet1工作表;
- 若sheetname = ‘汇总’,即读取excel中命名为"汇总"的工作表;
- header:用作列名的行号,默认为header = 0
- 若header = None,则表明数据中没有列名行;
- 若header = 0,则表明第一行为列名;
- names:列名命名或重命名,默认不变
data = pd.read_excel('E:\Project\data.xls', sheetname = 'sheet1',header =0)
② 读取csv文件
pd.read_csv(path):读取csv文件
- path:要读取的文件路径
- sep:指定列与列间的分隔符,默认sep = ‘,’
- 若sep = ‘\t’,即列与列间用制表符\t分隔;
- 若sep = ‘,’,即列与列间用逗号分隔;
- header:用作列名的行号,默认为0
- 若header = None,则表明数据中没有列名行;
- 若header = 0,则表明第一行为列名;
- names:列名命名或重命名,默认不变
- encoding:指定用于unicode文本编码格式
- 若encoding = ‘utf-8’,则表明用UTF-8编码的文本;
- 若encoding = ‘gbk’,则表明用gbk编码的文本;
data = pd.read_csv('E:\Project\data.csv', sep = ',',header=0,names=['主题分类','发文机构','实施日期'], encoding='utf-8')
③ 读取txt文件
pandas中的pd.read_csv()即可以读取csv文件,也可以读取txt文件方法同上,也可以用pd.read_table()读取txt文件,区别在于sep的默认参数不同.
pd.read_table()
- path:要读取的文件绝对路径
- sep:指定列与列间的分隔符,默认sep = ‘\t’
- 若sep = ‘\t’,即列与列间用制表符\t分隔;
- 若sep = ‘,’,即列与列间用逗号,分隔;
- header:用作列名的行号,默认为header = 0
- 若header = None,则表明数据中没有列名行;
- 若header = 0,则表明第一行为列名;
- names:列名命名或重命名,默认不变
data = pd.read_table('E:\Project\data.txt', sep = '\t', header = 1)
④ 读取JSON文件
pd.read_json(path)
path:文件路径orient:加载不同的数据封装格式,常用records,index,columns
data=pd.read_json('E:\Project\data.json', orient='records')
orient = 'records':多个字典组成的列表
-
json文件结构案例:
'[{"name":"ysh","age":"18"},{"name":"cjy"},{"age":"17"}]'
-
读取后:

orient = 'index':key作为行索引
-
json文件结构案例:
'{"city":{"guangzhou":"20","zhuhai":"20"},"home":{"price":"5W","data":"10"}}'
-
读取后:

orient = 'columns':key作为列索引
-
json文件结构案例:
'{"city":{"guangzhou":"20","zhuhai":"20"},"home":{"price":"5W","data":"10"}}'
-
读取后:
 .
.
这里介绍这四种文件的读取操作,基本满足大多情况
数据基本信息预览
创建DataFrame表格

workout_dict = {
'calories': [420, 300, 800, 100],
'duration': [40, 20, 30, 10],
'type': ['run', 'ride', 'jump', 'walk'],
}
workout = pd.DataFrame(workout_dict, index=['day1', 'day2', 'day3', 'day4'])
① 数据基本信息预览:.head(n) / .tail(n) / .sample(n)
.head(n):打印前n行数据,默认n为5.tail(n):打印后n行数据,默认n为5.sample(n):打印随机n行数据,默认n为5
workout.head(2)
# calories duration type
# day1 420 40 run
# day2 300 20 ride
workout.tail(2)
# calories duration type
# day3 800 30 jump
# day4 100 10 walk
workout.sample(2)
# calories duration type
# day3 800 30 jump
# day1 420 40 run
② 表格基本信息预览:.shape() / .len() / .dtypes() / .describe() /.info()
.shape:打印表格形状,(行数,列数).len():打印表格长度(行数).dtypes:打印表格中的行索引和该Series的元素数据类型,返回一个Series.describe():打印数值类型数据基本统计信息,包括:count:元素数量mean:平均数std:标准差min:最小值25% / 50% / 70%:四分位数max:最大值
.info():表格基本信息,包括:- 数据结构、行/列索引数,每个Series的数据类型,所占内存等
print(workout.shape) # (4, 3)
print(len(workout)) # 4
print(workout.dtypes, type(workout.dtypes))
# calories int64
# duration int64
# type object
# dtype: object <class 'pandas.core.series.Series'>
print(workout.describe())
# calories duration
# count 4.000000 4.000000
# mean 405.000000 25.000000
# std 294.561821 12.909944
# min 100.000000 10.000000
# 25% 250.000000 17.500000
# 50% 360.000000 25.000000
# 75% 515.000000 32.500000
# max 800.000000 40.000000
print(workout.info())
# <class 'pandas.core.frame.DataFrame'>
# Index: 4 entries, day1 to day4
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 calories 4 non-null int64
# 1 duration 4 non-null int64
# 2 type 4 non-null object
# dtypes: int64(2), object(1)
# memory usage: 128.0+ bytes
③ 统计性信息操作:.unique() / .nunique() / .groupby() / .agg() /.apply()
.unique():返回一个由Series中唯一的元素组成的列表 (ps:DataFrame对象没这个方法).nunique():返回唯一值元素的个数(Series和DataFrame对象都能用,后者返回的是其中所有Series和其对应的唯一值数量,可以进一步利用.sum()求和).groupby():根据某个(多个)字段划分为不同的组(group).apply():用于将某个函数应用于表格中的每个Series或Series中的每个值.agg():对数据计算统计信息,一般在.groupby()之后使用
.unique() / .nunique():唯一值 / 唯一值个数
# unique() / nunique()
print(workout['calories'].unique()) # [420 300 800 100]
print(workout['calories'].nunique()) # 4
print(workout.nunique(), type(workout.nunique()))
# calories 4
# duration 4
# type 4
# dtype: int64
# dtype: int64 <class 'pandas.core.series.Series'>
print(workout.nunique().sum(), type(workout.nunique().sum())) # 12 <class 'numpy.int64'>
.groupby():分组,返回一个DataFrameGroupBy对象,直接打印为其内存地址 (可以转为list进行查看)
一般会在执行分组后进行其它操作,下面会讲解
例:groupby(by='company')过程拆解:

# groupby()
workout_by_calories = workout.groupby('calories')
print(workout_by_calories) # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x785533b98100>
print(list(workout_by_calories))
# [
# (100, calories duration type
# day4 100 10 walk),
# (300, calories duration type
# day2 300 20 ride),
# (420, calories duration type
# day1 420 40 run),
# (800, calories duration type
# day3 800 30 jump),
# ]
可以看出,由于workout中的calories中四个元素都不同,按calories分组也就意味着按每个元素单独分为一组,用转为list之后数据来说明,每个分组为一个元组,每个元组中第一个元素为分类依据的元素,后面几个元素为数据的columns标签,然后开始为每一条分组数据的行索引和数据。
计算统计信息:.agg()
.agg()函数经常在.groupby()函数之后使用,也就是对数据分组后进行统计信息计算

def percentile_25(x):
return x.quantile(0.25)
def percentile_75(x):
return x.quantile(0.75)
# 按类别(pclass)和是否幸存(survived)分组后,统计这些分组中年龄的信息
age_agg = data[['Pclass', 'Survived', 'Age']].groupby(['Pclass', 'Survived']).agg(['min', 'max', 'median', 'mean', len, np.std, percentile_25, percentile_75])
age_agg
这里的数据集以泰坦尼克号中的训练集为例
percentile:百分数,quantile:量值;就是返回数据中的四分位数
.agg()函数处理后的数据为DataFrame对象,案例中的行和列都是多级的索引
print(type(age_agg)) # <class 'pandas.core.frame.DataFrame'>
print(age_agg.columns)
# MultiIndex([('Age', 'min'),
# ('Age', 'max'),
# ('Age', 'median'),
# ('Age', 'mean'),
# ('Age', 'len'),
# ('Age', 'std'),
# ('Age', 'percentile_25'),
# ('Age', 'percentile_75')],
# )
print(age_agg.index)
# MultiIndex([(1, 0),
# (1, 1),
# (2, 0),
# (2, 1),
# (3, 0),
# (3, 1)],
# names=['Pclass', 'Survived'])
.apply(func, axis=0, raw=False)
func:传入的函数或Lambda表达式axis:默认为0(列),0或index(列)1或columns(行)raw:默认为False,False ,表示把每一行或列作为 Series 传入函数中;True,表示接受的是 ndarray 数据类型
# 原始数据
print(workout)
# calories duration type
# day1 420 40 run
# day2 300 20 ride
# day3 800 30 jump
# day4 100 10 walk
# 计算数值类型的每个元素的平方根
print(workout.iloc[:, :2].apply(np.sqrt)) # 对选择的每个Series应用np.sqrt()函数
# calories duration
# day1 20.493902 6.324555
# day2 17.320508 4.472136
# day3 28.284271 5.477226
# day4 10.000000 3.162278
# 计算每一行数值类型的平均值
print(workout[['calories', 'duration']].apply(np.mean, axis=1))
# day1 230.0
# day2 160.0
# day3 415.0
# day4 55.0
# dtype: float64
# 将这两个column相加并作为一个新的column字段添加到表格中
workout['cal+dura'] = workout.iloc[:, :2].apply(lambda w: w.calories+w['duration'], axis=1) # 这里只是用了不同的写法
print(workout)
# calories duration type cal+dura
# day1 420 40 run 460
# day2 300 20 ride 320
# day3 800 30 jump 830
# day4 100 10 walk 110
处理的若为Series,则为每个元素应用函数func
索引设置

① .set_index():将某一列设置为index
keys:需要设置为index的列名drop:布尔值,在将原来的列设置为index,是否需要删除原来的列,默认为Trueappend:布尔值,新的index设置之后,是否要删除原来的index,默认为Trueinplace:布尔值,是否进行原地操作,即是否要用新的DataFrame取代原来的DataFrame,默认False


不保留(左),保留(右)
# 设置calories为新的行索引index,不保留原来的行索引和原来的Series
workout.set_index('calories')
# 设置calories为新的行索引行索引index,保留原来的行索引和Series
workout.set_index('calories', drop=False, append=False)
# 多个行索引的情况
workout_test = workout.set_index('type', drop=False, append=True)
workout_test.loc['day1']
# calories duration type
# type
# run 420 40 run
workout_test.loc['day1'].loc['run']
# calories 420
# duration 40
# type run
# Name: run, dtype: object
当表格中含有多个行索引时,对于该表格,只能使用最外层行索引确定,确定后可以进一步使用内层行索引确认
② reset_index():重新设置表格的行索引
drop:布尔值,表示是否舍弃当前行索引,默认为False


workout.reset_index(drop=False) # 图左
workout.reset_index(drop=True) # 图右
drop为False时,将当前行索引添加到正常列,然后将当前行索引变为 0,1,2,⋯0,1,2,\cdots0,1,2,⋯ 的形式
drop为True时,丢弃当前行索引,将当前行索引变为 0,1,2,⋯0,1,2,\cdots0,1,2,⋯ 的形式
常用工作流
字符串处理
① 使用str预定义的函数
一些基本函数:.lower() / .upper() / .len() / .strip()、.lstrip()、.rstrip() / .replace()
data['Name'].str.lower()[:3] # 字符串字母小写
data['Name'].str.upper()[:3] # 字符串字母大写
data['Name'].str.len()[:3] # 字符串长度
# strip(), lstrip(), rstrip():去除前后空格
data['Name'].str.strip()[:3]
data['Name'].str.replace(' ','_') # replace(被替换字符,替换字符)
# 链式编程
data['Name'].str.strip().str.lower().str.replace(' ','_')
分割字符串:.split()
data['LastName'] = data['Name'].str.split(',').str[0] # 取出第一个名字(名字由逗号分隔)
data['LastName'][:3]
# 0 Braund
# 1 Cumings
# 2 Heikkinen
# Name: LastName, dtype: object
② 字符串直接拼接:利用重载的 + 运算符

# 拼接LastName和Sex,组成一个新的column添加到表格中
data['LastName'] = data['LastName'].astype('string') # 转为string类型
data['NameSex'] = data['LastName'] + '\_' + data['Sex']
data[['LastName', 'Sex', 'NameSex']][:3]
③ 面对复杂情况,可以使用上面介绍过的.apply()应用自定义函数

# 给每行数据添加信息字段
def add_message(x):
prefix, survive_str = 'Mr.', 'died'
if x['Sex'] == 'femail':
prefix='Ms.'
if x['Survived'] == 1:
survive_str = 'survived'
msg = f'{prefix}{x.LastName}, {survive_str} at Titanic at the age of {x.Age}'
return msg
data['Message'] = data.apply(add_message, axis=1)
data[['LastName', 'Sex', 'Age', 'Survived', 'Message']][:3]
时间信息的处理
这里以一个这样的数据集为例(以下为数据前五行)

① 日期是一个Timestamp(时间戳)对象,日期的差为时间差(Timedelta)对象
# format参数是指定传入字符串的日期格式,默认为自动检测
time_start = pd.to_datetime('2022-01-01', format='%Y-%m-%d')
print(type(time_start)) # <class 'pandas._libs.tslibs.timestamps.Timestamp'>
print(pd.to_timedelta('3day')) # 3 days 00:00:00
print(pd.to_timedelta('3hour')) # 0 days 03:00:00
print(pd.to_timedelta('3min')) # 0 days 00:03:00
print(pd.to_timedelta('3s')) # 0 days 00:00:03
print(type(pd.to_timedelta('3s'))) # <class 'pandas._libs.tslibs.timedeltas.Timedelta'>
常用格式字符:
%Y:4 位数的年份%y:2 位数的年份%m:2 位数的月份(01 到 12)%d:2 位数的日期(01 到 31)%H:24 小时制的小时数(00 到 23)%I:12 小时制的小时数(01 到 12)%M:2 位数的分钟数(00 到 59)%S:2 位数的秒数(00 到 59)%f:6 位数的微秒数

② 常用操作:转为日期类型 / 日期相减得到时间差 / 时间差计算时间间隔 / 星期几
# 仅保留乘客上下车的时间
data = data[['pickup_dt', 'dropoff_dt']]
# 字符串类型转为日期类型
data['pickup_dt'] = pd.to_datetime(data['pickup_dt'])
data['dropoff_dt'] = pd.to_datetime(data['dropoff_dt'])
# 计算乘客在车上的时间
data['duration_time'] = data['pickup_dt'] - data['dropoff_dt']
# 将乘客在车上的时间转化为秒
data['duration_secs'] = data['duration_time'].dt.seconds
# 将乘客在车上的时间转化为小时
data['hour'] = data['duration_secs'] / 60 / 60
# 乘客乘车日期是星期几
data['week'] = data['pickup_dt'].dt.weekday
# 乘客乘车日期是否为休息日(周末),将日期转化为星期,然后判断是否大于5
# 0: Monday; 6: Sunday
data['isweekend'] = data['pickup_dt'].dt.weekday > 5
data.head()
两个时间戳(timestamp)相减得到一个时间差(timedelta)
③ 从日期数据进行数据过滤
time_start = pd.to_datetime('2020-04-01')
time_end = pd.to_datetime('2020-04-30 23:59:59')
filt_1 = (data['pickup_dt'] >= time_start) & (data['pickup_dt'] <= time_end)
filt_2 = (data['dropoff_dt'] >= time_start) & (data['dropoff_dt'] <= time_end)
filt_3 = (data['duration_time'] >= pd.to_timedelta('1min')) & (data['duration_time'] <= pd.to_timedelta('3hour'))
data_filt = data.loc[filt_1 & filt_2 & filt_3, :]
print(data_filt.shape) # (233319, 7)
- filt_1:上车时间在四月份
- filt_2:下车时间在四月份
- filt_3:在车上的时间在一分钟至三小时之间

# 出行时间可视化
data['hour'].plot.hist(bins=300) # bins=300表示将数据分成300个等宽的区间,并在每个区间上绘制一个条形
split-apply-combine
① 分类统计信息:groupby + apply

- 待处理表格```
根据上车地点编号计算每个地点上车游客的平均出行时间
def mean_traveltime_mins(x): # 传进来的x是当前分组的数据
return x[‘duration_secs’].mean()
data.groupby([‘PULocationID’]).apply(mean_traveltime_mins).head()
PULocationID
1 376.125000
3 1113.454545
4 782.835664
5 3274.000000
6 1216.333333
dtype: float64
② 分类统计信息:groupby + filter
筛选出出行次数大于500的上车地点编号分组
def gb_count_filt(df, min_trips):
if len(df) < min_trips:
return False
return True
data_bg = data.groupby([‘PULocationID’, ‘isweekend’])
data_bg = data_bg.filter(gb_count_filt, min_trips=500)
print(data_bg.shape) # (207312, 8)
> 这段代码中传到参数`df`中的是按`PULocationID`和`isweekend`划分的分组,在确定地点编号的前提下,又根据`isweekend`分为了两组,然后根据每一个这样进一步划分的组来判断长度是否大于500
③ apply返回Series序列,一次拓展多个列
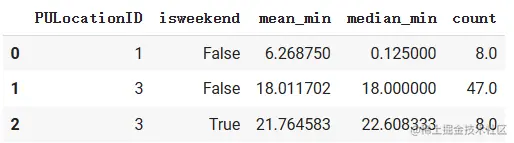
def mean_traveltime_df(df):
return pd.Series({‘mean_min’: df[‘duration_secs’].mean()/60, ‘median_min’: df[‘duration_secs’].median()/60, ‘count’: len(df)})
time_sum_min = data.groupby([‘PULocationID’, ‘isweekend’]).apply(mean_traveltime_df)
time_sum_min.reset_index().head(3)
> 这里用了apply函数之后,由于前面用了groupby分组,所以分组的两个column字段的值会作为行索引,这里使用reset\_index将这两个字段取消行索引变为普通列.
表格排序
----
根据列排序(默认为升序)
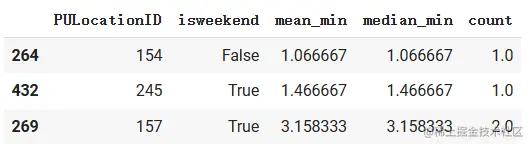
time_sum = time_sum.sort_values(‘mean_min’, ascending=True) # 根据均值进行排序,ascending默认为True(升序)
time_sum.head(3)
> 使用函数sort\_values按某一字段进行排序
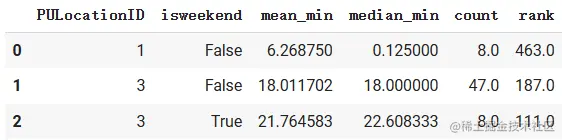
使用rank生成数据排名
time_sum[‘rank’] = time_sum[‘mean_min’].rank(ascending=False)
time_sum.head(3)
> 使用函数rank按某一字段生成排名,这里是按字段`mean_min`生成每条数据中按该字段得到的排名并作为一个新的column添加到表格中
若想使用原来的顺序,直接调用函数`.sort_index()`即可.
表格拼接
----
1. `.concat()`:按照行或列的方向简单拼接
2. `.join()`:按照行的索引index进行拼接
3. `.merge()`:按照列的值作为依据进行拼接
使用concat()函数:直接进行拼接
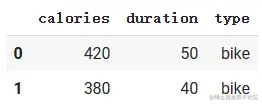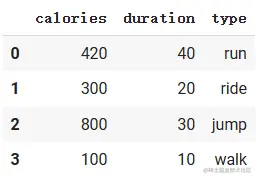
* 待处理表格 `workout1` 和 `workout2`

pd.concat([workout1, workout2], axis=0)
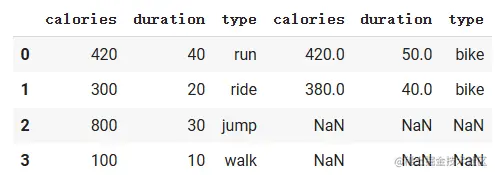
pd.concat([workout1, workout2], axis=1)
使用join()函数:以索引为依据进行拼接
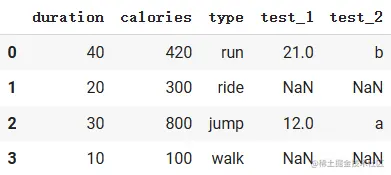
利用python字典创建DataFrame表格
workout_dict1 = {
‘calories’: [420, 300, 800, 100],
‘duration’: [40, 20, 30, 10],
‘type’: [‘run’, ‘ride’, ‘jump’, ‘walk’],
}
workout_dict2 = {
‘test_1’: [12, 21],
‘duration’: [30, 40],
‘test_2’: [‘a’, ‘b’],
}
workout1 = pd.DataFrame(workout_dict1)
workout2 = pd.DataFrame(workout_dict2)
workout1 = workout1.set_index(‘duration’)
workout2 = workout2.set_index(‘duration’)
workout = workout1.join(workout2, how=‘left’, rsuffix=‘_2’)
workout = workout.reset_index() # 拼接后的索引为workout1的索引, workout2的索引自动删除
> join函数是按两个表格中的索引作为依据,依据两个索引相同的拼接在一起,参数`how`为拼接方式,`left`表示表格self作为左侧,参数`rsuffix`表示若遇到相同的列名则在后面添加的后缀以确保列名不重复.
使用merge()函数:以指定列为依据进行拼接
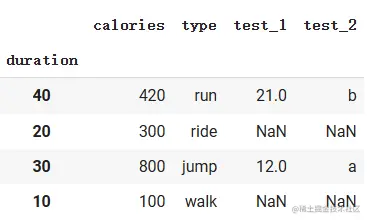
表格和join函数示例中set_index后的表格相同
workout = workout1.merge(workout2, left_on=‘duration’, right_on=‘duration’, how=‘left’)
这里展示的结果没有进行reset_index
长表格和宽表格之间的转化
------------
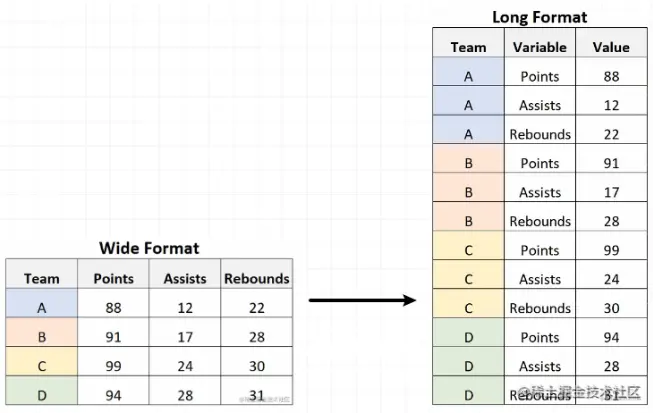
使用`.pivot()`函数:
df_2 = df_1.pivot(index=‘Team’, columns=‘Variable’, values=‘Value’)
> df\_1为图中的长表格
注意事项
====
① copy和view
要搞明白一些操作是对原表格数据的拷贝还是视图,如果是拷贝的话,那么在新的拷贝数据里进行的操作不会影响原数据,若为视图,则在新的数据进行修改,原数据也会收到影响 (两个对象指向同一内存地址)
Pandas中不能串联赋值单个元素:
workout.loc[‘day1’][‘calories’] = 420
print(workout[‘calories’][‘day1’]) # 430
ps:使用
loc、iloc在单个括号中定位或直接使用[]的串联赋值是允许的,但是对于单个元素的重构/赋值一般会用之前介绍过的.at[]来获取元素并进行赋值,在使用前可以使用df.copy()对原数据进行保存.上面那种链式索引方式会返回一个拷贝(copy),而不是原始的 DataFrame 对象,因此无法直接对其进行赋值操作,而
loc或iloc的多标签索引方式和直接使用[]的链式索引方式返回的都是原数据的视图(view),因而可以直接复制
② Pandas的不足
所有数据躲在电脑内存中,可以存储的数据大小有限,更大的数据需要建立数据库利用磁盘空间,也可以将大文件分割为小文件方便Pandas读取,真正的大数据分布式运算需要借助于Spark/PySpark这类分布式运算工具。
题外话
感谢你能看到最后,给大家准备了一些福利!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python兼职渠道推荐*
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









