







想象一下,您可以轻松地从互联网上获取所需的所有数据,而无需手动浏览网页或复制粘贴。这就是网络抓取的美妙之处。无论您是数据分析师、市场研究员还是开发人员,网络抓取都为自动化数据收集打开了全新的世界。
在这个数据驱动的时代,信息就是力量。然而,从数百甚至数千个网页手动提取信息不仅耗时,而且容易出错。幸运的是,网络抓取提供了一种高效准确的解决方案,可以自动从互联网上提取您需要的数据,从而极大地提高了效率和数据质量。
目录
- 什么是网页抓取?
- 网页抓取的过程通常包括以下步骤:
- 使用 Selenium 入门
- 准备工作
- 导入库
- 访问网页
- 启动参数
- 示例:无界面模式运行
- 定位页面元素
- 元素交互
- 数据提取
- 等待元素加载
- 绕过反抓取保护措施
- 结论
什么是网络抓取?
网络抓取是一种通过编写程序自动从网页中提取信息的技术。这项技术在许多领域有广泛的应用,包括数据分析、市场研究、竞争情报、内容聚合等。通过网络抓取,您可以在短时间内收集和整合大量网页的数据,而不是依赖手动操作。
网络抓取的过程通常包括以下步骤:
- 发送HTTP请求:通过编程向目标网站发送请求,获取网页的HTML源代码。常用工具如Python的requests库可以轻松完成这一步骤。
- 解析HTML内容:获取HTML源代码后,需要对其进行解析以提取所需数据。HTML解析库如BeautifulSoup或lxml可用于处理HTML结构。
- 提取数据:基于解析后的HTML结构,定位并提取特定内容,如文章标题、价格信息、图片链接等。常用方法包括使用XPath或CSS选择器。
- 存储数据:将提取的数据保存到适当的存储介质,如数据库、CSV文件或JSON文件,以便进行后续分析和处理。
使用Selenium等工具,可以模拟用户浏览器的操作,绕过一些反爬虫机制,从而更高效地完成网络抓取任务。
为了解决反复无法解决讨厌验证码的问题?
利用Capsolver AI的自动网络解锁技术,发现无缝自动验证码解决方案!
申请CapSolver的优惠代码:WEBS。在兑换后,每次充值后您将获得额外的5%奖金,无限。
使用Selenium开始
让我们以ScrapingClub为例,使用Selenium完成第一个练习。
准备工作
首先,确保在您的本地计算机上安装了Python。您可以通过在终端中输入以下命令来检查Python版本:
python --version
确保Python版本大于3。如果未安装或版本过低,请从Python官方网站下载最新版本。接下来,您需要使用以下命令安装selenium库:
pip install selenium
导入库
from selenium import webdriver
访问页面
使用Selenium驱动Google Chrome访问页面并不复杂。在初始化Chrome选项对象后,您可以使用get()方法访问目标页面:
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()
启动参数
Chrome选项可以添加许多启动参数,以帮助提高数据检索的效率。您可以在官方网站上查看完整的参数列表:Chromium命令行开关列表。以下是一些常用参数:
| 参数 | 用途 |
|---|---|
| –user-agent=“” | 在请求头中设置用户代理 |
| –window-size=xxx,xxx | 设置浏览器分辨率 |
| –start-maximized | 最大化运行 |
| –headless | 无头模式运行 |
| –incognito | 隐身模式运行 |
| –disable-gpu | 禁用GPU硬件加速 |
示例:在无头模式下运行
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()
定位页面元素
在数据抓取中必要的一步是在DOM中找到相应的HTML元素。Selenium提供了两种主要方法来定位页面上的元素:
find_element:找到符合条件的单个元素。find_elements:找到符合条件的所有元素。
这两种方法支持八种不同的定位HTML元素的方式:
| 方法 | 含义 | HTML示例 | Selenium示例 |
|---|---|---|---|
| By.ID | 通过元素ID定位 | <form id="loginForm">...</form> | driver.find_element(By.ID, 'loginForm') |
| By.NAME | 通过元素名称定位 | <input name="username" type="text" /> | driver.find_element(By.NAME, 'username') |
| By.XPATH | 通过XPath定位 | <p><code>My code</code></p> | driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | 通过链接文本定位 | <a href="continue.html">Continue</a> | driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | 通过部分链接文本定位 | <a href="continue.html">Continue</a> | driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | 通过标签名称定位 | <h1>Welcome</h1> | driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | 通过类名定位 | <p class="content">Welcome</p> | driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | 通过CSS选择器定位 | <p class="content">Welcome</p> | driver.find_element(By.CSS_SELECTOR, 'p.content') |
让我们返回ScrapingClub页面,并编写以下代码来找到练习一中的“Get Started”按钮元素:
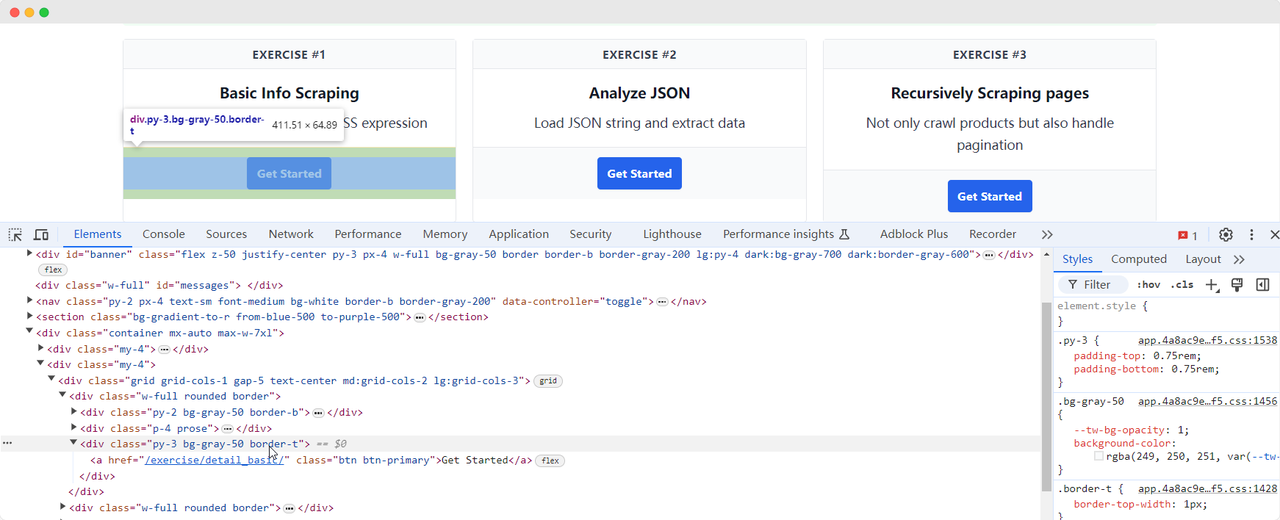
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()
元素交互
一旦找到了“Get
Started”按钮元素,我们需要点击按钮以进入下一页。这涉及到元素交互。Selenium提供了几种方法来模拟操作:
click():点击元素;clear():清除元素内容;send_keys(*value: str):模拟键盘输入;submit():提交表单;screenshot(filename):保存页面截图。
有关更多交互方法,请参阅官方文档:WebDriver API。让我们继续改进ScrapingClub练习代码,添加点击交互:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()
数据提取
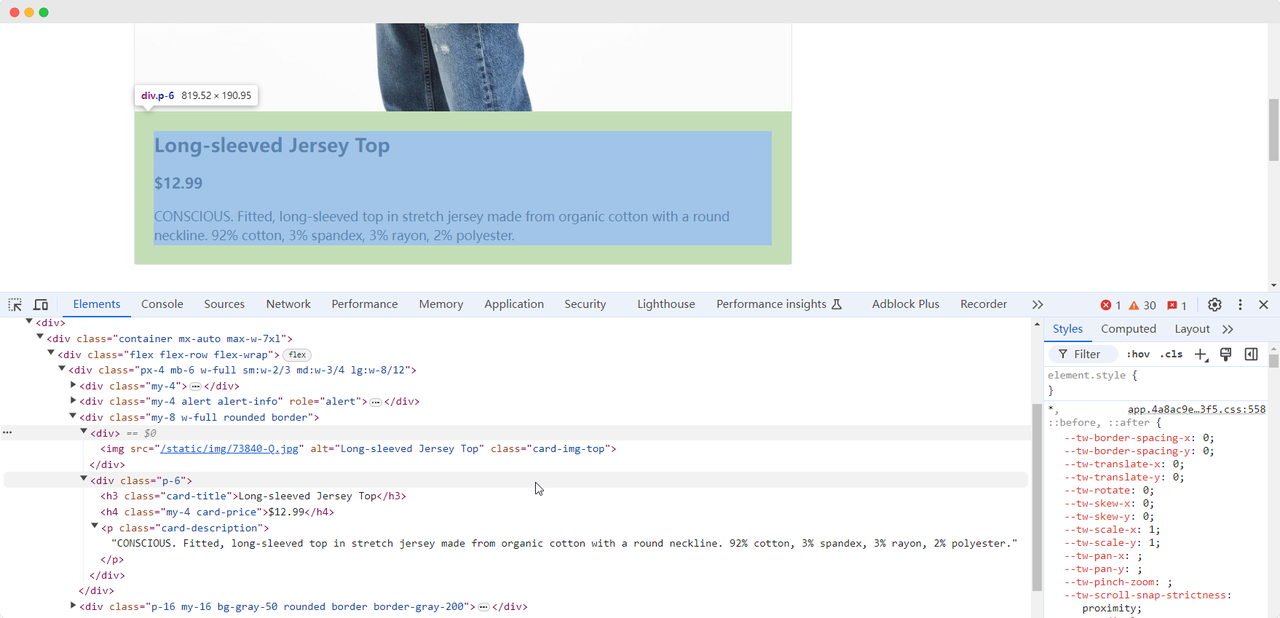
当我们到达第一个练习页面时,我们需要收集产品的图像、名称、价格和描述信息。我们可以使用不同的方法找到这些元素并提取它们:
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'产品名称:{product_name}')
print(f'产品图像:{product_image}')
print(f'产品价格:{product_price}')
print(f'产品描述:{product_description}')
driver.quit()
该代码将输出以下内容:
产品名称:长袖运动衫
产品图像:https://scrapingclub.com/static/img/73840-Q.jpg
产品价格:$12.99
产品描述:有意识。修身款长袖运动衫,采用有机棉制成,具有圆领。92%棉,3%氨纶,3%人造丝,2%涤纶。
等待元素加载
有时候,由于网络问题或其他原因,当Selenium完成运行时,元素可能尚未完全加载,这可能导致某些数据收集失败。为了解决这个问题,我们可以设置在继续数据提取之前等待直到某个元素完全加载。以下是一个示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# 等待产品图像元素完全加载
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'产品名称:{product_name}')
print(f'产品图像:{product_image}')
print(f'产品价格:{product_price}')
print(f'产品描述:{product_description}')
driver.quit()
绕过反爬虫保护
ScrapingClub练习很容易完成。然而,在实际的数据收集场景中,获取数据并不那么容易,因为一些网站采用了反爬虫技术,可能会检测到您的脚本作为机器人并阻止数据收集。最常见的情况是验证码挑战,如funcaptcha、datadome、recaptcha、hcaptcha、geetest等。
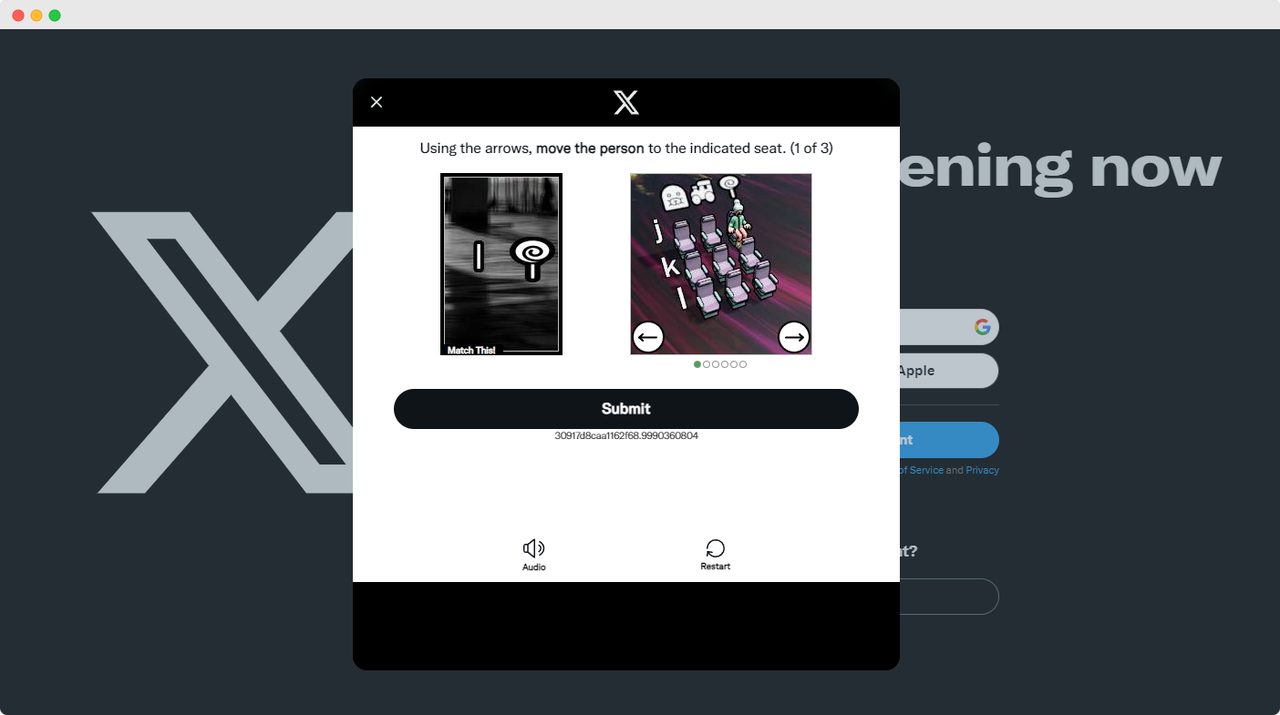
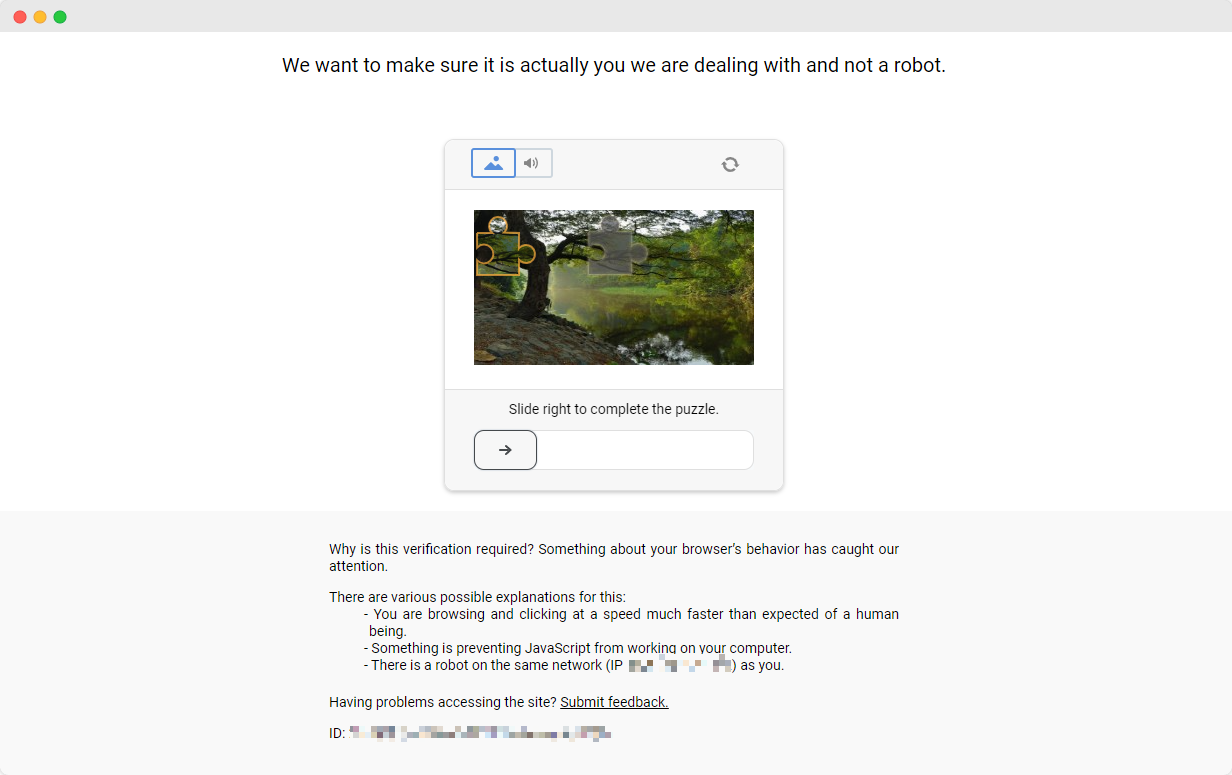
解决这些验证码挑战需要在机器学习、逆向工程和浏览器指纹对抗措施方面具有丰富的经验,这可能需要大量时间。幸运的是,现在您不必自己完成所有这些工作。CapSolver提供了完整的解决方案,帮助您轻松绕过所有挑战。CapSolver提供浏览器扩展,可以在使用Selenium进行数据收集时自动解决验证码挑战。此外,他们提供API方法来解决验证码并获取令牌,所有这些都可以在几秒钟内完成。请参阅CapSolver文档获取更多信息。
结论
从提取产品详细信息到应对复杂的反爬虫措施,使用Selenium进行网络抓取打开了自动化数据收集的广阔领域。在我们航行于网络不断变化的景观中,像CapSolver这样的工具为更顺畅地数据提取铺平了道路,使曾经令人生畏的挑战成为过去。因此,无论您是数据爱好者还是经验丰富的开发人员,利用这些技术不仅提高了效率,而且揭示了一个数据驱动洞见的世界,仅一次抓取即可得到。
CapsolverCN官 方代理交流扣 群:497493756















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









