






 本文详细解释了HashMap在JDK1.7前后底层结构的变化,涉及数组、链表和红黑树的使用,以及为何选择2的幂次数组长度。重点讨论了查找效率、解耦性和数组长度设置的原因。
本文详细解释了HashMap在JDK1.7前后底层结构的变化,涉及数组、链表和红黑树的使用,以及为何选择2的幂次数组长度。重点讨论了查找效率、解耦性和数组长度设置的原因。
HashMap
Map底层是哈希表
在JDK1.7之前,底层树数组加Entery链表来实现
在JDK1.7之后,是通过数组,Entery链表,红黑树实现
实现原理图
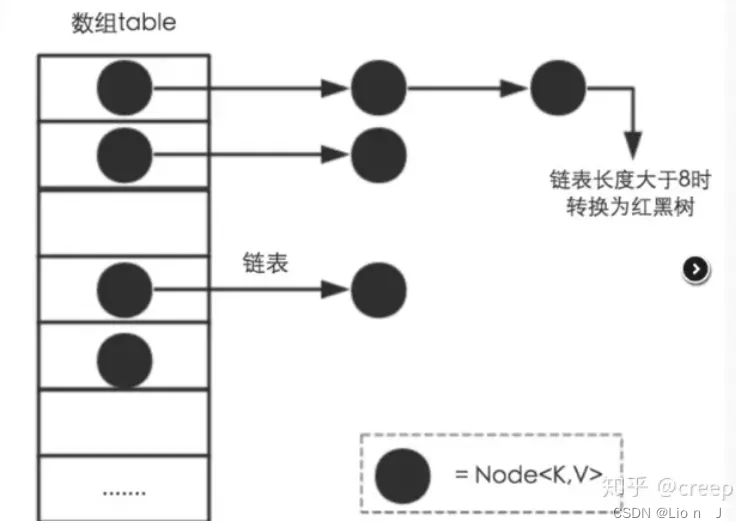
每一个Node<K,V>是一个单向链表结构,指向下一个链表
链表与红黑树转化问题:
对于底层table数组, 有本身的负载因子(0.75), 当元素个数table.legnth*0.75时候, 会自动扩容为原来的2倍(为什么是二倍?)
●链表转红黑树(链表树化阈值:默认8)
当table下的某个节点hash冲突的个数达到8的时候,而且此时数组的长度时大于等于64 就会自动转化成红黑树
●红黑树变链表(红黑树链化阈值:6)
当节点下的红黑树节点(hash冲突)小于6时候就会转化成链表
●最小树化阈值(默认64):避免在table很少的情况下频繁进行扩容和树化发生冲突
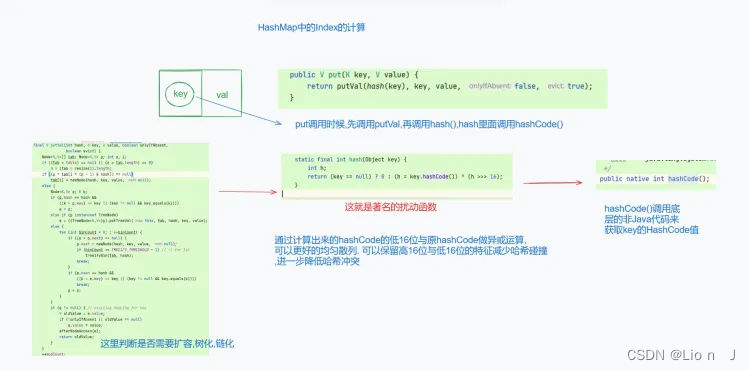
put方法的调用顺序
问题一: 为什么不用链表结构代替原哈希表里的数组?
Entry[] table=new Entry[capacity];
// entry就是一个链表的节点
//现在进行替换==>
List<Entry> table=new LinkedList<Entry>();
可以是可以, 但是会影响查找效率
查找效率 :
因为在数据存储时候,已经知道数据存储的节点位置, 所以数组的查找效率比LinkedList大(链表要从头到尾的遍历一遍)可以是可以, 但是会影响查找效率与解耦性
问题二: 为什么不用ArrayList代替原哈希表里的数组?
解耦性
因为毕竟数组是基本的数据结构, 宽容机制我们可以自己来定义,HashMap里的数组扩容是2的次幂, 做取模运算效率高. 而ArrayList扩容机制是1.5倍数, 就会降低效率
!!!因为当n时2的幂的时候: 由 hash%n = (n-1)&hash
Hash冲突:
我们在平时使用hashMap时候, 并没有存入什么hash的指定下标,
因为在我们的hashMap对我们存放进来的key值进行hashCode()运算, 生成一个值, 再对该值进行取余方法,用table.length-1与产生的hash值进行&运算

从这里就可以知道为什么我们的的table数组长度是2的n次幂, 只有这样, 在table.length进行减一与之相与的时候, 才能达到最大的n-1值
反例
假设我们长度是15,减一是14,对应的二进制表示为0000 1110,这样在与hash值做&操作时候, 最后一位永远是0, 不会用到table最后一个位置, 违背了对table数组无序使用的原则, 因为hashMap为高效存储, 就是减少碰撞, 尽量把数据分配均匀, 每个链表长度要基本相同
●问题三: 为什么map的底层总是2的次幂?
为了实现数据不均匀。 因为只要是2的幂, 那么length-1 的值二进制全是1,这种情况下index的值就等同于HashCode最后几位的值。只要hashCode是分布均匀的,那么Hash(key)的结果就是均匀的;在jdk8之前由于只与后几位有关,所以增加了扰动算法,保留了前16位的数据特征
jdk1.8: 使用扰动算法
●散列算法:
JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位(扰动函数)实现的:(h = key.hashCode()) ^ (h >>> 16)
●在数据转移(resize)时:
jdk1.8中,每次通过key获取到hashCode,然后异或hashCode的低16位获得hash,然后hash&(n-1)的到index, 如果每次将原数组元素转义到新数组都重新计算Hash,那么对整体性能肯定有影响
通过观察转移过程可以发现,每次扩容后数组的长度都是原来的2倍,也就是说,数组的长度是 2ⁿ ,所以,元素的新位置要么是在原位置,要么是在原来的位置上移动原数组长度的位置。
源码是通过 if ((e.hash & oldCap) == 0) 来将原链表分成两个,一个存位置不需要改变的元素,一个存位置需要改变的元素,然后遍历完一个index下的链表后,再将两个链表分别移到新数组当中去。即源码中的 newTab[j] = loHead; 和 newTab[j + oldCap] = hiHead;

●提问: (e.hash & oldCap) == 0 为什么是oldCap 而不是 oldCao - 1 ?
因为我们需要判断的是长度扩大之后的那个新增位(相比较于原来计算HashCode的新增位,如上图色位置),他的结果是0/1
oldCap的二进制位置刚好有一个1与新增位对应上了, 此时进行&运算就可以知道新增计算位是0/1

所以, 只要只要判断hashCode对应的newLength的最左边一位的差异为是0/1,就能保证新数组索引与老数组索引一致或者newIndex = oldIndex+oldCapacity,大大减少了之前已经散列好的老数组的数据位置重新的调换所浪费的性能
这也就是为什么数组长度是2的次幂的一个原因
另一原因就是保证数据的分布均匀性
















 43万+
43万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











