







一、jieba三种分词模式
(一)概述
jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组;除此之外,jieba 库还提供了增加自定义中文单词的功能。
支持三种分词模式
1、精确模式,试图将句子最精确地切开,适合文本分析;
result1 = jieba.cut(str2)
2、全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
result2 =jieba.cut(str1,cut_all = True)
3、搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
result3 = jieba.cut_for_search(str3)
(二)jupyter安装jieba库
输入pip install jieba wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple安装jieba和词云
安装完成!
(三)代码演示
代码与结果展示:

代码
import jieba
str = "本法所称突发事件,是指突然发生,造成或者可能造成严重社会危害,需要采取应急处置措施予以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件。"
# 精准模式:将句子最精确地切开,适合文本分析
result1 = jieba.cut(str)
print("/".join(result1))
# 全模式:所有的可以成词的词语都扫描出来(会有重叠的词)
result2 =jieba.cut(str,cut_all = True)
print("/".join(result2))
# 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
result3 = jieba.cut_for_search(str)
print("/".join(result3))(四)cut和lcut的区别
Jieba的cut和lcut分词:
(1)从效果看,二者没区别,区别在于结果的表示形式
(2)cut的结果是迭代器,需要进一步处理才能看到分词具体结果;lcut生成一个列表的形式,可以直接输出

二、SnowNLP
(一)概述
SnowNLP是一个常用的Python文本分析库。SnowNLP处理的是unicode编码,使用时需要自行decode成unicode。
Snownlp主要功能包括: (1)文本分类(2)转换成拼音(3) 繁体转简体(4)提取文本关键词(5)提取文本摘要
(二)安装snownlp
输入pip install snownlp -i https://pypi.tuna.tsinghua.edu.cn/simple 
(三)代码演示
代码与结果展示:
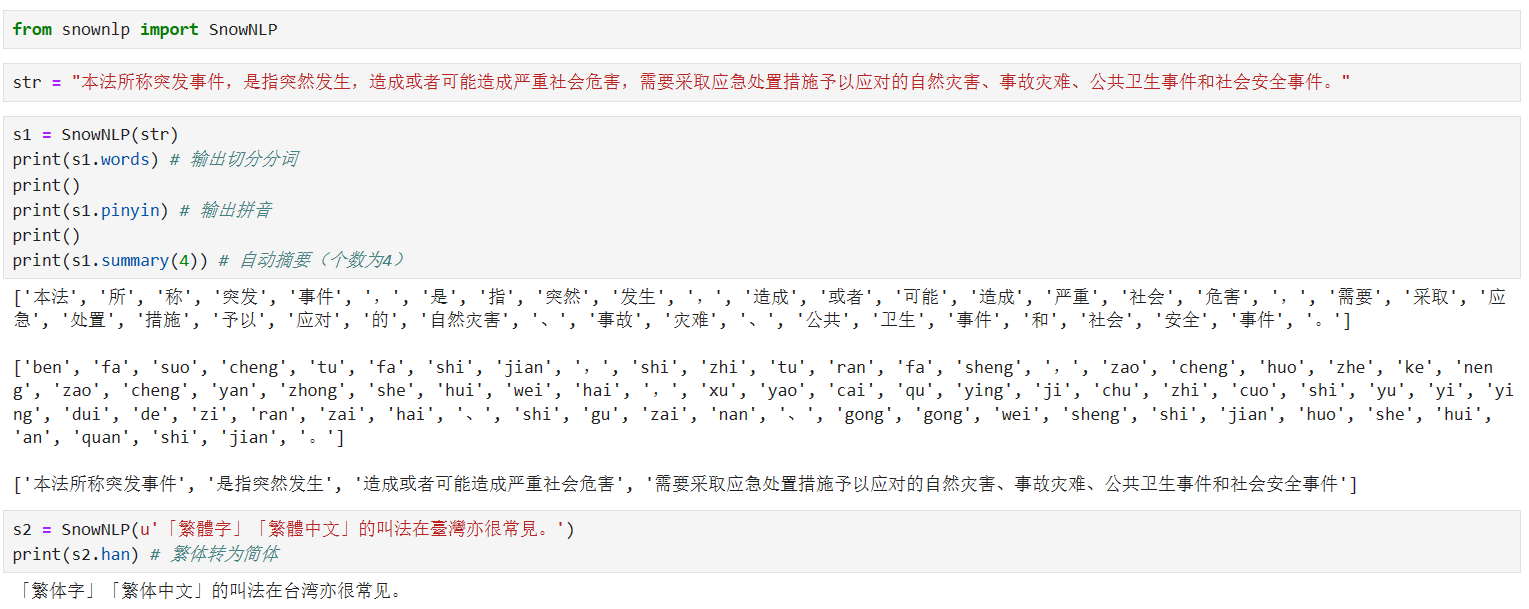
代码:
from snownlp import SnowNLP
str = "本法所称突发事件,是指突然发生,造成或者可能造成严重社会危害,需要采取应急处置措施予以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件。"
s1 = SnowNLP(str)
print(s1.words) # 输出切分分词
print()
print(s1.pinyin) # 输出拼音
print()
print(s1.summary(4)) # 自动摘要(个数为4)
s2 = SnowNLP(u'「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
print(s2.han) # 繁体转为简体三、去除停用词
(一)概述
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。 这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。
(二)代码演示
(1)停用词表在网上进行下载,保存在按当地的txt文档中
(2)准备需要进行分析的文本文档
两个文档部分展示如下:

“去除停用词”代码:
import jieba
# 读入需要处理的文本
with open ("Texts.txt", "r", encoding='UTF-8') as fp:
words = fp.read()
result_text = jieba.lcut(words)
#print(result_text)
# 读入停用词表,利用jieba分词以列表形式输出
with open ("stopwords_all.txt", "r", encoding='UTF-8') as fs:
stopwords = fs.read()
result_stop = jieba.lcut(stopwords)
#print(result_stop)
new_words = []
for i in result_text:
if i not in stopwords:
new_words.append(i)
print("去除停用词后的结果:", new_words)结果展示:

四、提取关键词
介绍两种方式:TF-IDF算法和textrank
这两种算法都只针对str类型
(一)TF-IDF算法
该算法是提取句子级的关键字
jieba.analyse.extract_tags(sentence, topK=5, withWeight=False, allowPOS=())
- topK,关键词个数
- withWeight,是否显示其权重,默认False
- allowPOS,指定词性(如:n名词,v动词,ns地点),默认为空
import jieba.analyse
# 提取20个关键词,词性筛选为名词和动词
# words = fp.read(),此处的words是str类型
keywords1 = jieba.analyse.extract_tags(words, topK=20, withWeight=False, allowPOS=('n','v'))
print(keywords1)
(二)Textrank算法
keywords2 = jieba.analyse.textrank(words, topK=20, withWeight=False, allowPOS=('n','v'))
print(keywords2)
五、特征向量构建
(一)CountVectorizer()函数
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
from sklearn.feature_extraction.text import CountVectorizer
# texts = [" ".join(keywords1)," ".join(keywords2)] # 可以像这样将两个列表化为一个
texts1 = [" ".join(new_words)] # 消除逗号,将其化为只有一个元素的列表
print(texts1)
cv = CountVectorizer()
cv_fit = cv.fit_transform(texts1)
# 词汇表,字典型
print(cv.vocabulary_)
# 文本矩阵。(0,192) 2 表示为:第0个列表元素;词典中索引为192的元素;词频为2
print(cv_fit)
# 将结果转化为稀疏矩阵。表示第0个列表元素,从第0个字符元素开始,其词频大小
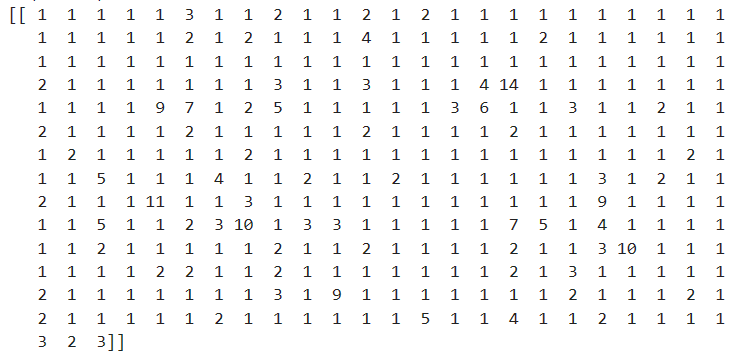
print(cv_fit.toarray())(1)字典型,结果展示

(2)文本矩阵,部分结果展示

(3)稀疏矩阵,结果展示
(二)TfidfVectorizer()函数
将文本进行向量化表示
from sklearn.feature_extraction.text import TfidfVectorizer
texts2 = [" ".join(keywords1)," ".join(keywords2)]
tv = TfidfVectorizer(norm=None)
tv_fit = tv.fit_transform(texts2)
print("特征向量:\n", tv.vocabulary_)
print("所有词汇如下:\n",tv.get_feature_names_out()) # 去除了重复的词汇
print("TF-IDF文档-词矩阵:\n", tv_fit.toarray())
print("文本矩阵:\n", tv_fit)结果展示:

















 5733
5733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









