







一. 实验目的
理解词法分析器的任务和工作原理;掌握计算机语言语法分析程序的设计方法,并能够针对给定语言的语法规则,使用某种高级编程语言实现其语法分析器。
二. 实验内容
对于只含有+、*运算的算术表达式,编写相应的语法分析程序,要求:
1. 用表驱动的预测分析法进行语法分析。
2. 采用某种高级程序设计语言,设计并实现语法分析程序。
3. 设计恰当的测试用例对语法分析程序进行测试。
三.实验设备
计算机、Windows 操作系统、编程语言集成开发环境。
四.实验原理(或程序框图)及步骤
设计思路:
首先明确该语言的语法规则,并用上下文无关文法将语法规则描述出来,并对文法进行消除左递归、提取左因子等操作;设计好文法后,学习表驱动的预测分析法的原理,明确分析过程,然后构造出对应的LL(1)分析表;最后设计测试用例。
在实现时,先将设计好的文法及其分析表输入,用struct type来保存上下无关文法,用数组保存分析表。然后逐行读取文件,调用分析函数。分析函数中每次读取分析栈栈顶元素,剩余栈读取当前待分析元素,然后逐步判读是否为剩余栈最后一个元素、是否元素没完但是分析栈已经为空、都不满足分析当前元素是否为终结符、为非终结符在分析表中查找对应非终结符以及对应元素,输出;一直循环上述,直到分析栈为空或者剩余栈为空。
文法:
| E->E+T|T T->T*F|F F->(E)|i |
消除左递归:
| E->TG G->+TG|ε T->FS S->*FS|ε F->(E)|i |
表4.1 对应文法的LL(1)分析表
| 非终结符 | 输入符号 | |||||
| + | * | ( | ) | i | $ | |
| E | E->TG | E->TG | ||||
| G | G->+TG | G->ε | G->ε | |||
| T | T->FS | T->FS | ||||
| S | S->ε | S->*FS | S->ε | S->ε | ||
| F | F->(E) | F->i | ||||
流程图:
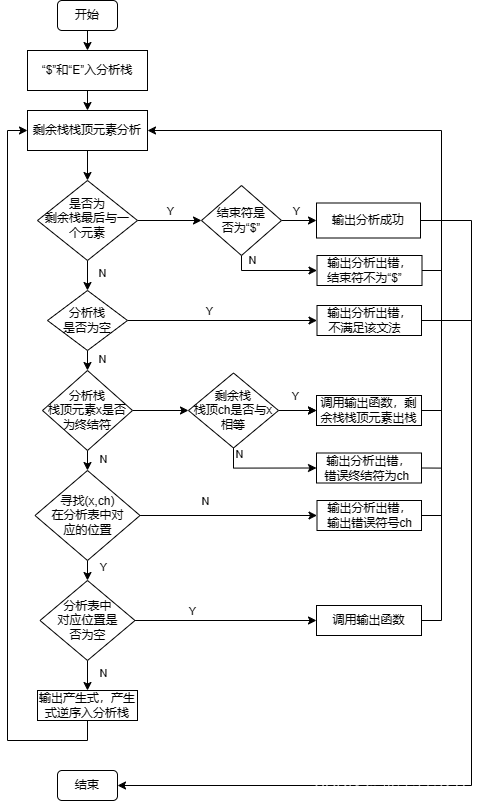
图4.1 流程图
数据结构:
| Struct char origin string array int length void init( ) |
还使用了用数组实现的栈结构。
五.程序源代码
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <cstring>
using namespace std;
const string ExpFileName = "C:/Users/29645/Desktop/语法分析.txt";
char analyeStack[20]; /*分析栈*/
char restStack[20]; /*剩余栈*/
//char TOKEN[20];
const string v1 = "i+*$"; /*终结符 */
const string v2 = "EGTSF"; /*非终结符 */
int top, ridx, len; /*len为输入串长度 */
bool endYN =true;
struct type { /*产生式类型定义 */
char origin; /*产生式左侧字符 大写字符 */
string array; /*产生式右边字符 */
int length; /*字符个数 */
type() :origin(NULL), array(""), length(0) {}
void init(char a, string b) {
origin = a;
array = b;
length = array.length();
}
};
type e, t, g, g1, s, s1, f, f1; /* 产生式结构体变量 */
type R[10][10]; /* 预测分析表 */
void print() {/*输出分析栈和剩余栈 */
for (int i = 0; i <= top + 1; ++i) /*输出分析栈 */
cout << analyeStack[i];
cout << "\t\t";
for (int i = 0; i < ridx; ++i) /*输出对齐符*/
cout << ' ';
for (int i = ridx; i < len; ++i) /*输出剩余串*/
cout << restStack[i];
cout << "\t\t\t";
}
// 读文件
vector<string> readFile(string fileName) {
vector<string> res;
try {
ifstream fin;
fin.open(fileName);
string temp;
while (getline(fin, temp))
res.push_back(temp);
return res;
}
catch (const exception& e) {
cerr << e.what() << '\n';
return res;
}
}
bool isTerminator(char c) { // 判断是否是终结符
return v1.find(c) != string::npos;
}
void init(string exp) {//初始化
top = ridx = 0;
len = exp.length(); /*分析串长度*/
for (int i = 0; i < len; ++i)
restStack[i] = exp[i];
}
void analyze(string exp) { // 分析一个文法
init(exp);
int k = 0;
analyeStack[top] = '$';
analyeStack[++top] = 'E'; /*'$','E'进栈*/
cout << "步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 " << endl;
while (true) {
char ch = restStack[ridx];//剩余栈,ridx指向待匹配的终结符
char x = analyeStack[top--]; /*x为当前栈顶字符*/
cout << ++k << "\t\t";
if (ridx >= len - 1) {//到最后一个字符
if (ch == '$') {//已全部匹配,结束符为$
if (endYN) {
cout << "分析成功!\n" << endl; /*接受 */
}
else
{
cout << "分析结束,中途出错!AC!\n" << endl; /*接受 */
}
return;
}
else {
cout << "分析出错,结束符不为“$”" << endl;
return;
}
}
else if (x == '$') {//没匹配完,栈已经空,出错,不满足该文法
print();
cout << "分析出错,不满足该文法" << endl;
return;
}
if (isTerminator(x)) {
if (x == ch) { // 匹配上了
print();
cout << ch << "匹配" << endl;
ch = restStack[++ridx]; /*下一个输入字符*/
}
else { /*出错处理*/
print();
cout << "分析出错,错误终结符为" << ch << endl; /*输出出错终结符*/
endYN = false;
}
}
else { /*非终结符处理*/
int m, n; // 非终结符下标, 终结符下标
//string::npos 静态常量,用于表示未找到匹配项的情况
( v2.find(x) != string::npos ) ? m = v2.find(x) : m = -1; // m为-1则说明找不到该非终结符,出错
( v1.find(ch) != string::npos ) ? n = v1.find(ch) : n = -1; // n为-1则说明找不到该终结符,出错
if (m == -1 || n == -1) { /*出错处理*/
print();
cout << "分析出错,错误符号为" << ch << endl; /*输出出错非终结符*/
endYN = false;
ridx++;
}
else {
type nowType = R[m][n];/*用来接受C[m][n]*/
if (nowType.origin != NULL) {/*判断是否为空*/
print();
cout << nowType.origin << "->" << nowType.array << endl; /*输出产生式*/
for (int j = (nowType.length - 1); j >= 0; --j) /*产生式逆序入栈*/
analyeStack[++top] = nowType.array[j];
}
else {//分析表中没有配对
print();
cout << endl;
continue;
}
}
//else { /*出错处理*/
// print();
// cout << "分析出错,错误非终结符为" << x << endl; /*输出出错非终结符*/
// return;
//}
}
}
}
int main() {
e.init('E', "TG"), t.init('T', "FS");
g.init('G', "+TG");
s.init('S', "*FS");
f.init('F', "(E)"), f1.init('F', "i"); /* 结构体变量 */
/*填充分析表*/
R[0][0] = R[0][3] = e;
R[1][1] = g;
R[1][4] = R[1][5] = g1;
R[2][0] = R[2][3] = t;
R[3][2] = s;
R[3][4] = R[3][5] = R[3][1] = s1;
R[4][0] = f1; R[4][3] = f;
cout << "读取的文件名为:" << ExpFileName << endl;
vector<string> exps = readFile(ExpFileName);
int len = exps.size();
for (int i = 0; i < len; i++) {
endYN = true;
string exp = exps[i];
cout << "------------------待分析字符串" << i + 1 << ":" << exp << "--------------------" << endl;
cout << "字符串" << i + 1 << ":" << exp << endl;
analyze(exp);
}
return 0;
}六.实验数据、结果分析
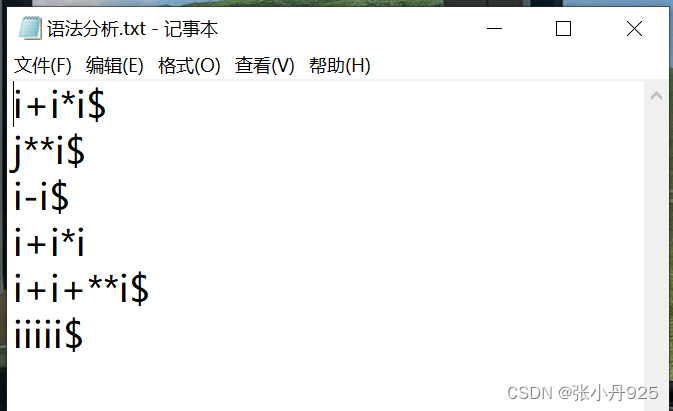
图6.1 测试用例
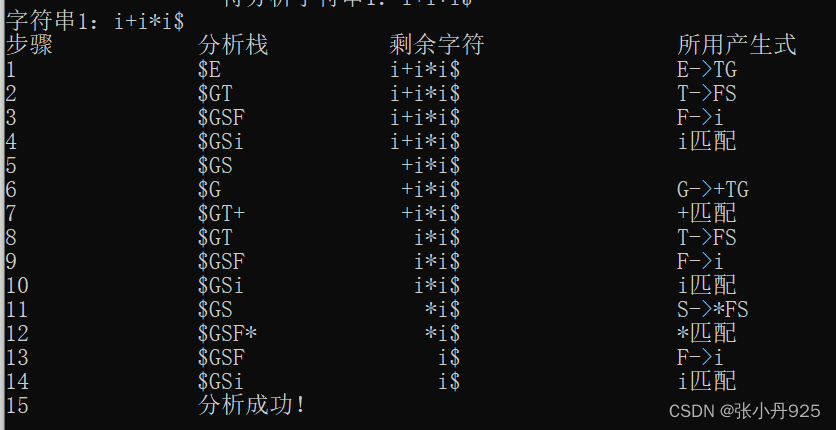
图6.2 字符串i+i*i$

图6.3 字符串j**i$
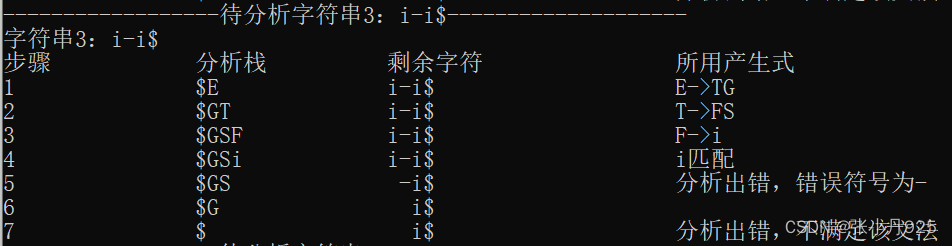
图6.4 字符串i-i$
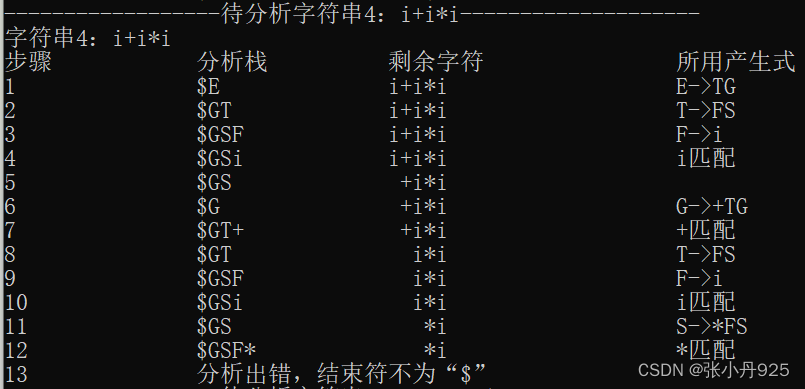
图6.5 字符串i+i*i
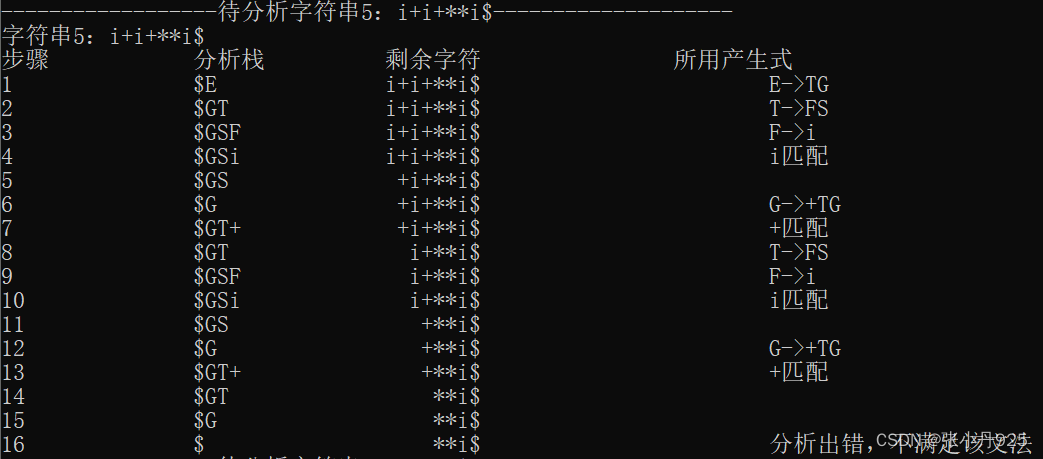
图6.6 字符串i+i+**i$

图6.7 字符串iiiii$
七. 实验小结
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









