







本文仅仅展现了python正则表达式中的一小部分内容,但是包含了实际应用中非常被频繁使用的例子,本文重在举例,即不需要相关语法知识就能够会用~
re.match()
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
参数
- pattern:匹配的正则表达式
- string:要匹配的字符串。
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
我们可以使用group(num) 或groups()匹配对象函数来获取匹配表达式。

用span来获取匹配到的位置
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 用span来获取匹配到的位置
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
out:
(0, 3)
None
再来看一下group的作用:
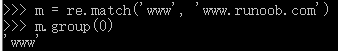
re.findall()
注意: match 和 search 是匹配一次 findall 匹配所有。
匹配两个字符串之间的字符串并返回
# 这种有两种方法
# 连同匹配条件(前后的字符串)一起返回
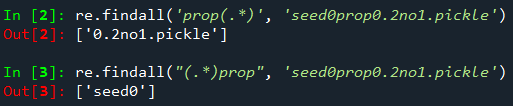
re.findall('prop.*?no', 'seed0prop0.2no1.pickle')
# 只返回中间字符串的内容
re.findall("prop(.*)no", 'seed0prop0.2no1.pickle')
out:

匹配某字符串之前/之后的所有字符串
# 这种有两种方法
# 返回prop之后的所有字符
re.findall('prop(.*)', 'seed0prop0.2no1.pickle')
# 返回prop之前的所有字符
re.findall("(.*)prop", 'seed0prop0.2no1.pickle')
out:
提取数字
提取所有数字(包括小数)
string = "Purchase100-0.76-0.63"
re.findall(r"\d+\.?\d*",string)
out:
['100', '0.76', '0.63']

提取形如“字符串+数字”中的数字
例如,要提取 Purchase100 后面的 100
string = "Purchase100-0.76-0.63"
re.findall(r'(?<=Purchase)\d+\.?\d*',string)
# 也可以这样操作
pattern = re.compile(r'(?<=Purchase)\d+\.?\d*')
pattern.findall(string)
out:
['100']

如果想要跟着 “purchase” 一块返回,可以这样:
string = "Purchase100-0.76-0.63"
re.findall(r'(?:Purchase)\d+\.?\d*',string)
out:
['Purchase100']

特殊字符有:
.
(点) 在默认模式,匹配除了换行的任意字符。如果指定了标签 DOTALL ,它将匹配包括换行符的任意字符。
^
(插入符号) 匹配字符串的开头, 并且在 MULTILINE 模式也匹配换行后的首个符号。
$
匹配字符串尾或者在字符串尾的换行符的前一个字符,在 MULTILINE 模式下也会匹配换行符之前的文本。 foo 匹配 ‘foo’ 和 ‘foobar’,但正则表达式 foo$ 只匹配 ‘foo’。 更有趣的是,在 ‘foo1\nfoo2\n’ 中搜索 foo.$,通常匹配 ‘foo2’,但在 MULTILINE 模式下可以匹配到 ‘foo1’;在 ‘foo\n’ 中搜索 $ 会找到两个(空的)匹配:一个在换行符之前,一个在字符串的末尾。
*
对它前面的正则式匹配0到任意次重复, 尽量多的匹配字符串。 ab* 会匹配 ‘a’,‘ab’,或者 ‘a’ 后面跟随任意个 ‘b’。
+
对它前面的正则式匹配1到任意次重复。 ab+ 会匹配 ‘a’ 后面跟随1个以上到任意个 ‘b’,它不会匹配 ‘a’。
?
对它前面的正则式匹配0到1次重复。 ab? 会匹配 ‘a’ 或者 ‘ab’。
*?, +?, ??
'*', '+',和 '?'修饰符都是 贪婪的;
它们在字符串进行尽可能多的匹配。
有时候并不需要这种行为。
如果正则式 <.*> 希望找到 '<a> b <c>',它将会匹配整个字符串,而不仅是 '<a>'。
在修饰符之后添加 ? 将使样式以 非贪婪`方式或者 :dfn:`最小 方式进行匹配;
尽量 少 的字符将会被匹配。
使用正则式 <.*?> 将会仅仅匹配 '<a>'。
参考:
https://www.runoob.com/python/python-reg-expressions.html
https://blog.csdn.net/u010412858/article/details/83062200















 6081
6081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











