







算法图解
一.算法简介
算法是一组完成任务的指令。
1.1二分查找
二分查找是一种算法,其输入是一个有序的元素列表。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回null。
一般而言,对于包含n个元素的列表,用二分查找最多需要log2n步,而简单查找最多需要n步。
# 在一个列表中用二分法查找元素
def binary_search(list, item):
low = 0
high = len(list)
while low <= high:
mid = low+(high-low)//2
guess = list[mid]
if guess == item:
return mid
elif guess > item:
high = mid - 1
else:
low = mid + 1
return None-
写中位数这样写不会越界。
mid = low+(high-low)//2简单查找最多需要猜测的次数与列表长度相同,这被称为线性时间(linear time)。二分查找的运行时间为对数时间(或log时间)。
1.2大O表示法
大O表示法指出了算法有多快。例如,假设列表包含n个元素,简单查找需要检查每个元素需要执行n次操作,使用大O表示法,这个运行时间为O(n)。为检查长度为n的列表,二分查找需要执行log n次操作。使用大O表示法表示为O(log n)。大O表示法说的是最糟的情形。
-
O(log n),也叫对数时间,这样的算法包括二分查找。O(n),也叫线性时间,这样的算法包括简单查找。
-
O(n * log n),这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。
-
O(n2),这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。
-
O(n!),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。

1.3小结
-
算法的速度指的并非时间,而是操作数的增速。
-
谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
-
算法的运行时间用大O表示法表示。
-
O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
二叉树???
二. 选择排序
两种最基本的数据结构——数组和链表
选择排序是下一章将介绍的快速排序的基石。
2.1数组和链表
使用数组意味着所有元素在内存中都是相连的(紧靠在一起的)。
链表中的元素可存储在内存的任何地方。链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
在需要读取链表的最后一个元素时,不能直接读取,必须先访问元素#1,从中获取元素#2的地址,再访问元素#2并从中获取元素#3的地址,以此类推。
需要同读取所有元素时,链表的效率很高,但如果需要跳跃,链表的效率很低。
元素的位置称为索引。
需要在中间插入元素时,使用链表时只需修改它前面的那个元素指向的地址,使用数组时,则必须将后面的元素都向后移,因此链表是更好的选择。
如果要删除元素链表也是更好的选择,因为只需修改前一个元素指向的地址即可,而使用数组时,删除元素后,必须将后面的元素都向前移。
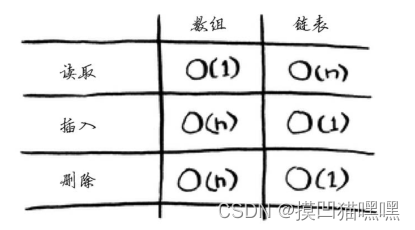
顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。
随机访问意味着可直接跳到第十个元素。本书经常说数组的读取速度更快,这是因为它们支持随机访问。
2.2选择排序
比如将一个列表内元素从大到小排列,一种办法是遍历这个列表,找出最大的元素,并将该元素添加到一个新列表中,以此类推。
需要的总时间为 O(n × n),即O(n2)。
# 选择排序,将列表从小到大
def find_smallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(0, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
def selection_sort(arr):
new_arr = []
for i in range(0, len(arr)):
smallest = find_smallest(arr)
new_arr.append(arr.pop(smallest))
return new_arr
print(selection_sort([15, 6, 8, 4]))2.3小结
-
数组的元素都在一起。
-
链表的元素是分开的,其中每个元素都存储了下一个元素的地址。
-
数组的读取速度很快。
-
链表的插入和删除速度很快。
-
在同一个数组中,所有元素的类型都必须相同。
Q:经常有用户在Facebook注册。假设你已决定使用数组来存储用户名,在插入方面数组有何缺点呢?
A:数组的插入速度很慢。另外,要使用二分查找算法来查找用户名,数组必须是有序的。因此每次插入用户名后,你都必须对数组进行排序!
三.递归
3.1基线条件和递归条件
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。
递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
def countdown(i):
print(i)
if i <= 0: #基线条件
return
else: #递归条件
countdown(i-1)3.2栈
栈是一种数据结构,它的主要操作方式是后进先出,包括压入(插入)和弹出(删除并读取)两个操作。
递归函数也使用调用栈!
缺点:存储详尽的信息可能占用大量的内存。尾递归???
3.3小结
-
递归指调用自身的函数。
-
每个递归函数都有两个条件:基线条件和递归条件。
-
栈有两种操作:压入和弹出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6512
6512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









