






文章:Sepp Hochreiter, Jürgen Schmidhuber; Long Short-Term Memory. Neural Comput 1997; 9 (8): 1735–1780. doi: https://doi.org/10.1162/neco.1997.9.8.1735


这段在讲 “全局误差信号流”是如何消失(vanish)的数学分析。核心思想是:在RNN中,如果网络结构和参数满足一定条件,误差信号在反向传播时会呈指数衰减,导致“梯度消失”问题。
总体结构
🔹 分析一个从u反向传播到某个中间单元 v 的误差信号有多大。
🔹 用矩阵和向量表达式将这个传播过程数学化。
🔹 推导出一个上界估计(upper bound),说明这个误差信号最多多大。
🔹 如果这个上界随着时间 q 增大而指数减小,就说明:误差信号越来越小,最终消失(梯度消失)。
Global error flow. The local error flow analysis above immediately shows that global error flow vanishes, too.
-
前面分析了局部误差传播(即从一层传到下一层时梯度是如何变化的),得出梯度会越来越小。么在此基础上的 global error flow,作为多个 local error flow 的传播与组合,自然也会 整体上趋于消失。
-
“局部(local)”与“全局(global)”的区别,本质上就体现在误差传播的范围和关注的对象上:
局部误差传播(Local Error Flow)
-
指的是相邻两层之间,例如从输出层传播到最后一层隐藏层,或者从隐藏层
传播到隐藏层
。
-
研究的是:“一小步”传播过程中,梯度是如何被某个激活函数的导数和权重矩阵影响的。
全局误差传播(Global Error Flow)
-
指的是从输出层一路传播回较早的隐藏层,甚至输入层的路径总和。
-
你可以把它看成很多 local error flow 串联起来之后的“乘积效应”。
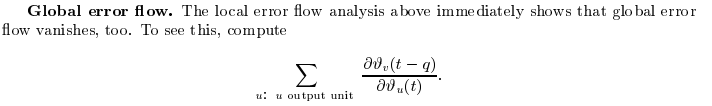
-
我们要计算的是——从 u 开始,误差往前(通过网络)传了 q 步,传到输出单元 v 的量级是多少?

将误差传播写成矩阵乘积形式
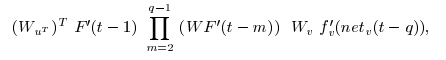
矩阵下标:
-
:表示从 第 m 层(前一层) 到 第 n 层(后一层) 的权重矩阵。
-
所以:
表示:从第
个单元(前一层)指向第
个单元(当前层) 的权重。
:
单元的 outgoing 权重向量
这是 矩阵 的 第
列:
-
因为每一列代表的是:从单元
出发,指向所有其他单元的权重
-
所以
:从
👉 可以理解为:v 的输出连接(outgoing)
 :u 单元的 incoming 权重向量
:u 单元的 incoming 权重向量
这是 的 第
行(不是列):
-
因为每一行表示的是:所有其他单元指向
的连接
-
所以
:从第
👉 可以理解为: 的输入连接(incoming)
📌 图示(可视化理解):
假设:
-
三个单元
,
,
,连接到下层单元
,
-
权重矩阵
大小是
,即从 3 个输入连接到 2 个输出
那么:
x1 x2 x3
↓ ↓ ↓
┌-----------------┐
y1 ← │ w11 w12 w13 │ ← 第1行:y1的incoming(W_{y1^T})
y2 ← │ w21 w22 w23 │ ← 第2行:y2的incoming(W_{y2^T})
└-----------------┘
↑ ↑ ↑
第1列 第2列 第3列
↓ ↓ ↓
x1's outgoing (W_{x1})
x2's outgoing (W_{x2})
x3's outgoing (W_{x3})
-
:是第2列,包含
,是 x2 的输出连接
-
:是第1行,包含
,是 y1 的输入连接
转置怎么理解?
-
如果你想把一个单元的 incoming 向量 变成一个列向量,就写作
-
所以
就是把 row vector(第 u 行)转成 column vecto
可以类比成:
-
第 v 列:v 发出多少条线(输出路径)
-
第 u 行:u 收到多少条线(输入路径)
incoming / outgoing 的方向是按照 前向传播(forward pass) 来定义的,不是反向传播!

分析上界,推导梯度消失条件
步骤一:定义 compatible 范数
Using a matrix norm  compatible with vector norm
compatible with vector norm 
👉 使用一个与向量范数兼容的矩阵范数。
✅ 什么叫 compatible?
就是满足不等式:
-
这是矩阵范数和向量范数之间的“兼容性定义”。
-
也就是说,这种范数组合是“良好配合”的,能保持不等式结构成立,特别方便后续推导中“估上界”。
步骤二:定义导数矩阵的最大范数
② we define 
-
:是某一时刻的导数矩阵,来自反向传播中激活函数的导数(例如 sigmoid 的导数)。
-
它是一个对角矩阵,形如:
-
然后我们对这些矩阵求范数(即
),再在所有
中取最大值:
步骤三:引入不等式估计
For 
👉 这是一个简单的性质:你向量里单个最大分量的绝对值,不会比整个向量范数更大。
举个例子:对
范数来说:
显然:
所以:
这个结论在后面帮助我们“用一个范数控制所有分量”。
步骤四:使用内积不等式
④ we get 
这是在用一个简单的不等式给出:
这个估计来自将内积写成分量和的形式:
然后使用 Cauchy-Schwarz 不等式(或极端估计法):
于是所有的 加起来总共不会超过:
这种估计虽然“粗糙”,但对分析足够用了。
✅ 解释:
-
当你不知道内积到底多大时,可以用这种“松弛”的估计方式;
-
这是在用“所有元素都可能最大”的极端情况来估上界;
步骤五:将每一层的导数估上界
Since 
这句话是说:
-
是某个输出神经元的激活函数在某个时间点的导数;
-
这个值不会超过
这个对角矩阵的范数;
-
由于对角矩阵范数(比如
)就是所有对角线元素的最大值,因此:
-
而我们前面定义了一个最大上界
,所以:
-
于是这一层的导数被包住了,也就是说:
我们在估计梯度传播时,要考虑每一层的“激活函数导数”
比如你用了 tanh,它的一阶导数最大也就 1。
这一层的激活函数导数矩阵(对角矩阵)记作:
我们对它求范数:
这个 是我们人为设置的「最大可能值」上界。
——就是这个范数不会再比这个上界大了,我们不需要关心具体数值,只关心它最多多少(“保守估计”)。
而那个范数又不会超过你上面定义的 
前文你定义过:
也就是说你在所有时间步上找到一个最大值 ,把它作为「最坏情况」的估计。
所以每一层的:
所以就是一层一层地把上限传递下去
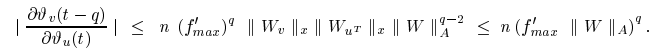
从当前时刻 t 的单元 u,反向传播 q 步回到单元 v 的时候,梯度的上界:
Note that this is a weak, extreme case upper bound...
上面这个上界 很宽松(loose upper bound),它只在以下极端情况下才可能成立:
-
所有激活函数的导数都刚好是最大值:
-
所有路径上的误差传播方向都一致(正号或负号相同),所以乘积不会抵消。
🔁 在实际中这很少发生——所以这个上界只是用来说明「最坏情况下,误差如何快速衰减」,而非真实情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









