







在使用影刀RPA获取小红书视频元素链接时,会发现获取到的链接是错误的,无法下载。
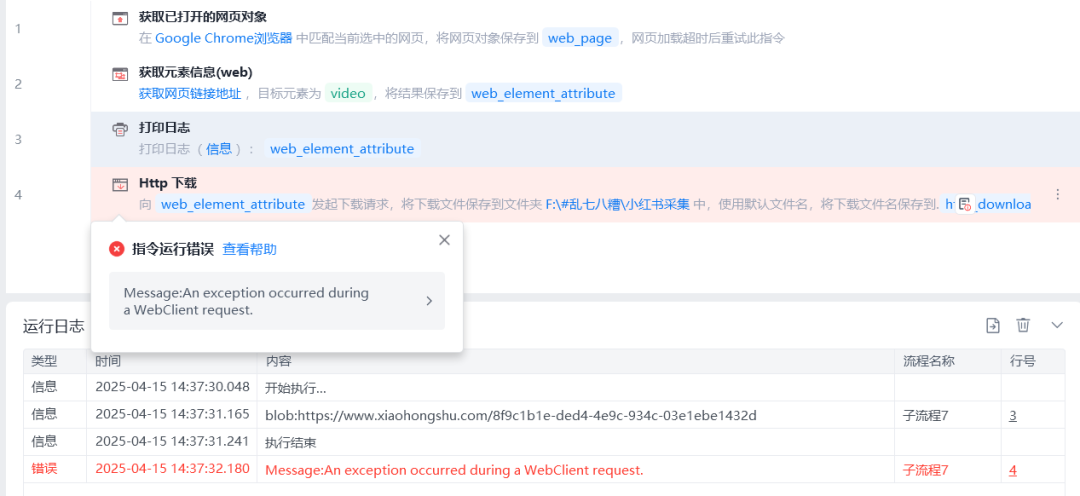
问题分析
什么原因呢,仔细找了下,原来视频链接藏在head标签里。
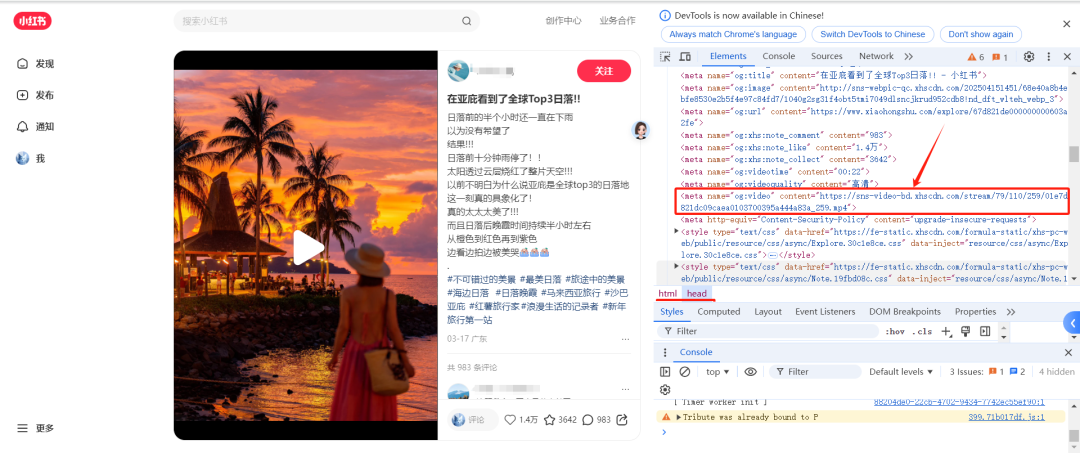
而且还不能是小窗口打开,必须全页面显示才能看到,这就有点麻烦了,按这个方式采集,效率将大打折扣。
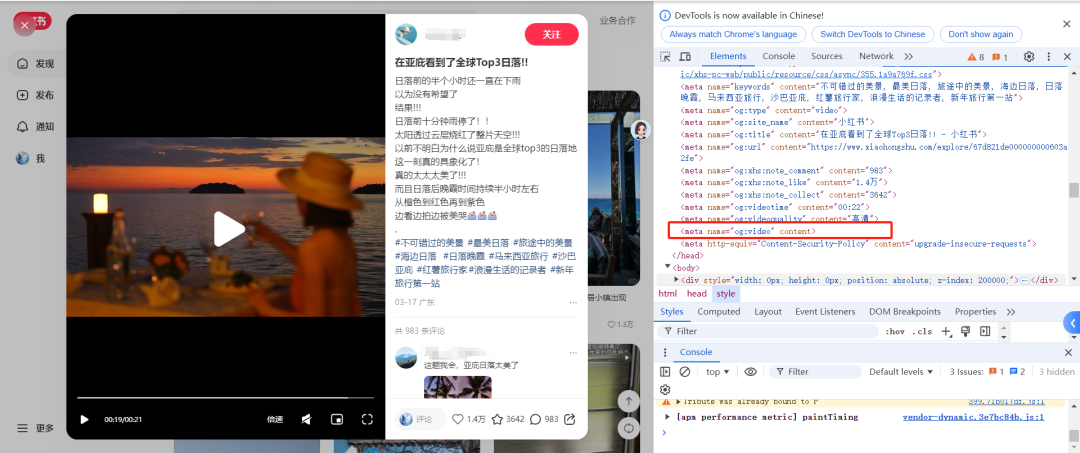
为了不影响采集效率,推荐使用requests函数库直接爬取网页内容。

爬取到的笔记内容是这样的,可以发现内容都,集中在这里,对数据进行下处理即可,处理结果如下。

可以发现,点赞收藏评论这三个数据是模糊的,这是因为我们直接使用requests函数,是以游客的身份访问的,像是这样:
解决方式如下,在请求头headers中写入个人登录的Cookie值。
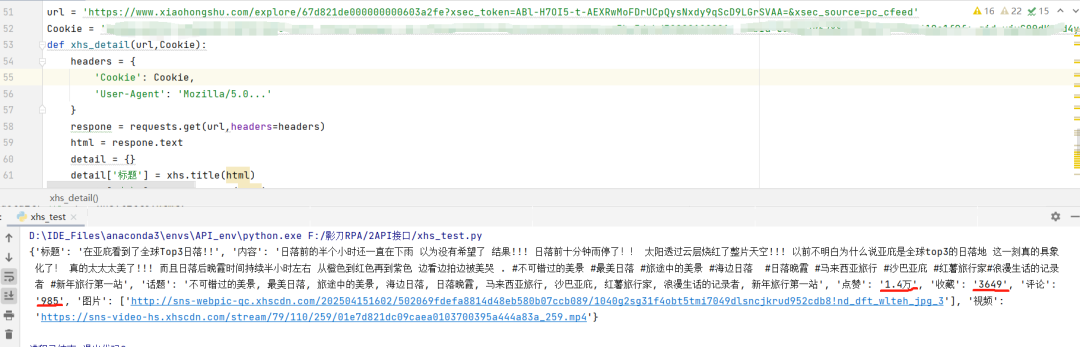
数据与登录账户后访问的页面数据相同了,完美解决。
Cookie怎么获取呢?
Cookie获取介绍
登录小红书官网并完成账号登录
打开开发者工具:
Windows电脑:按F12或Ctrl+Shift+I
Mac系统:按Fn+F12或Command+Option+I
通用方式:右键点击页面选择"检查"
切换到Network(网络)选项卡
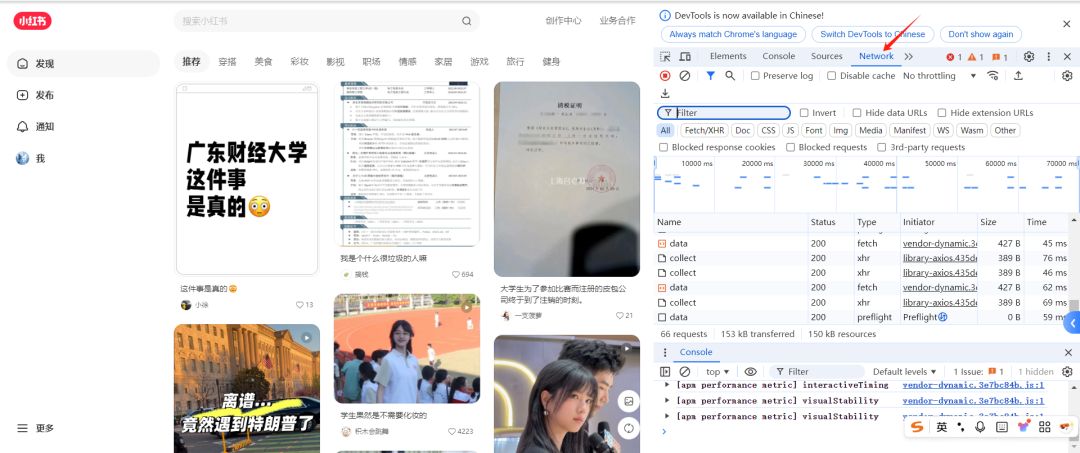
随便打开一个笔记,在过滤框输入"feed"或"search"进行过滤
选择任意一个以feed或search开头的请求
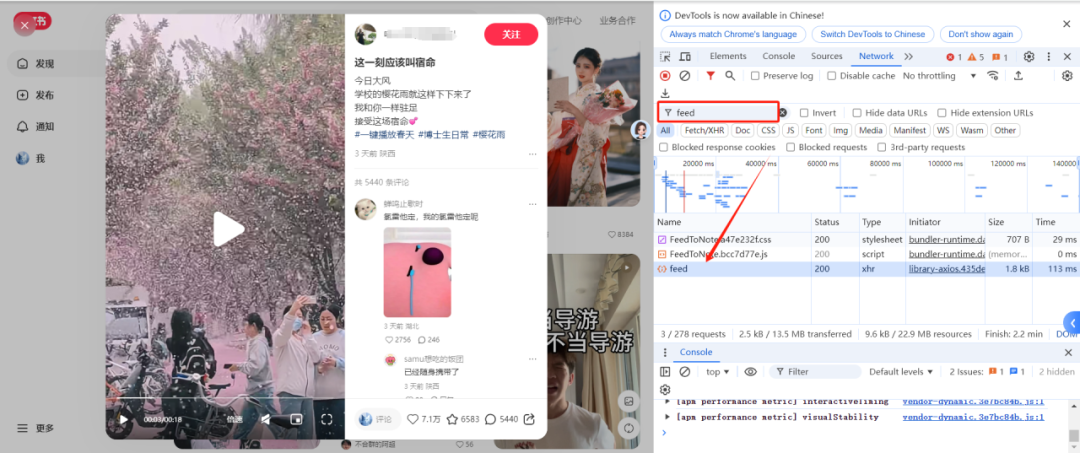
点击该请求 → 找到Request Headers(请求头) → 复制"Cookie"后的全部字符串 (左键连点三下)
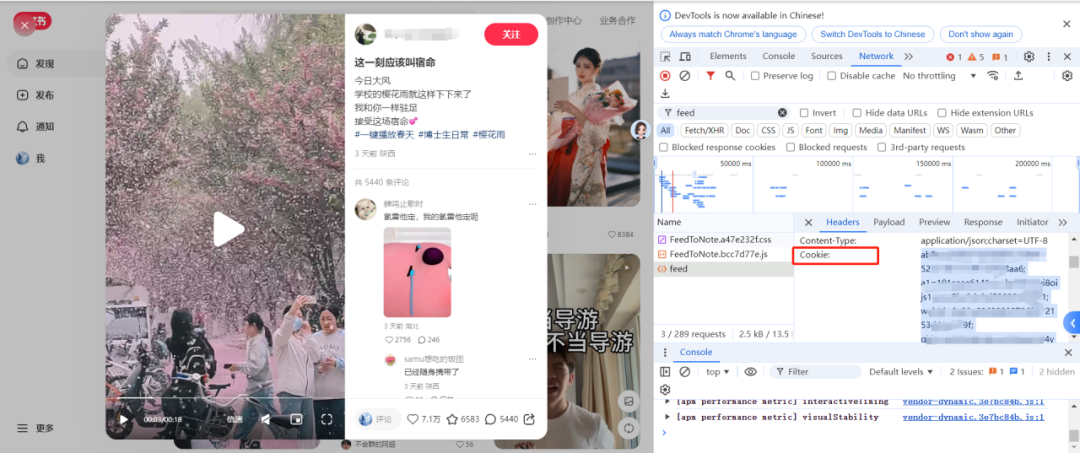
注意不要退出登录,退出后Cookie可能会失效
代码应用
右上角新建一个Python模块,我命名为xhs_detail
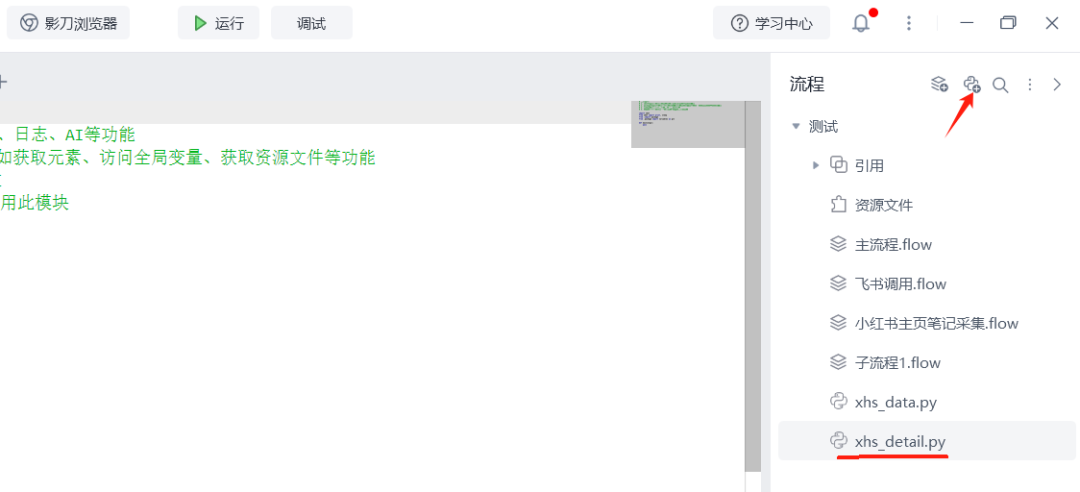
将这段代码复制上去
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import requests
import re
from bs4 import BeautifulSoup
class xhs:
def image(html): # 获取图片下载链接(包括视频封面)
pattern = r'<meta name="og:image" content="(http[^"]+)"'
image_urls = re.findall(pattern, html)
return image_urls
def video(html): # 获取视频下载链接
soup = BeautifulSoup(html, "html.parser")
video_meta = soup.find("meta", {"name": "og:video"})
if video_meta:
return video_meta.get("content")
else:
return None
def title(html):
soup = BeautifulSoup(html, "html.parser")
title_meta = soup.find("meta", {"name": "og:title"})
title = re.sub(r'\s-\s小红书$', '', title_meta.get("content"))
return title
def content(html):
soup = BeautifulSoup(html, "html.parser")
content_meta = soup.find("meta", {"name": "description"})
return content_meta.get("content")
def keywords(html):
soup = BeautifulSoup(html, "html.parser")
keywords_meta = soup.find("meta", {"name": "keywords"})
return keywords_meta.get("content")
def note_like(html):
soup = BeautifulSoup(html, "html.parser")
note_like_meta = soup.find("meta", {"name": "og:xhs:note_like"})
return note_like_meta.get("content")
def note_collect(html):
soup = BeautifulSoup(html, "html.parser")
note_collect_meta = soup.find("meta", {"name": "og:xhs:note_collect"})
return note_collect_meta.get("content")
def note_comment(html):
soup = BeautifulSoup(html, "html.parser")
note_comment_meta = soup.find("meta", {"name": "og:xhs:note_comment"})
return note_comment_meta.get("content")
def xhs_detail(url,Cookie):
if Cookie != None:
headers = {
'Cookie': Cookie,
'User-Agent': 'Mozilla/5.0...'
}
respone = requests.get(url,headers=headers)
else:
respone = requests.get(url)
html = respone.text
detail = {}
detail['标题'] = xhs.title(html)
detail['内容'] = xhs.content(html)
detail['话题'] = xhs.keywords(html)
detail['点赞'] = xhs.note_like(html)
detail['收藏'] = xhs.note_collect(html)
detail['评论'] = xhs.note_comment(html)
detail['图片'] = xhs.image(html)
detail['视频'] = xhs.video(html)
return detail
def main(args):
pass记得安装Python包,bs4与requests
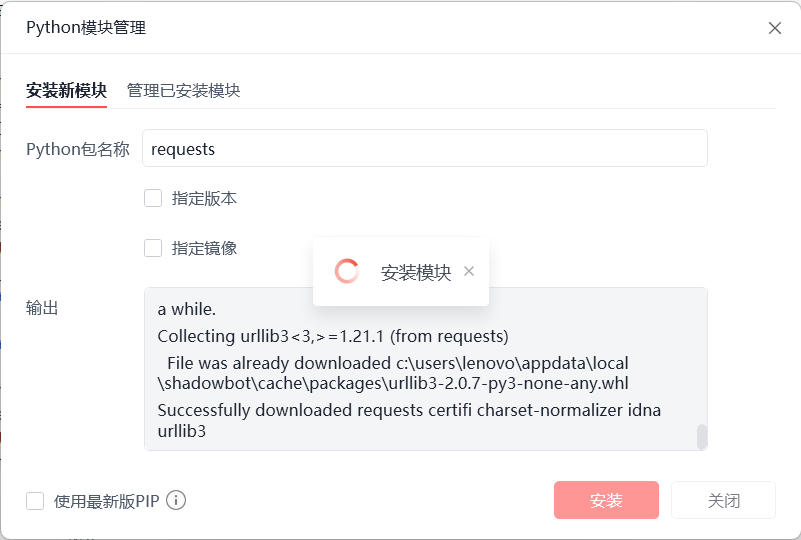
完成这些步骤就可以在流程中调用这个模块啦
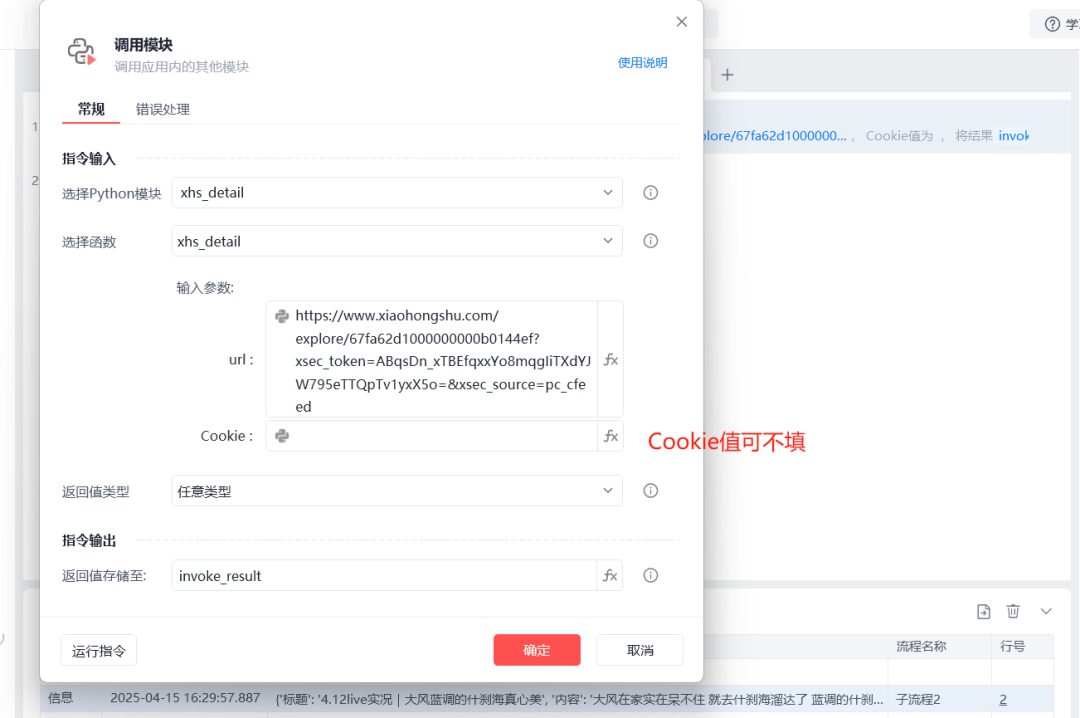
考虑到频繁使用Cookie爬取可能会影响到账号安全,所以使用时也可以不填入Cookie值。
返回值是以字典形式的,对于图文笔记,返回的视频值为None,下载素材时可对视频变量做个判断
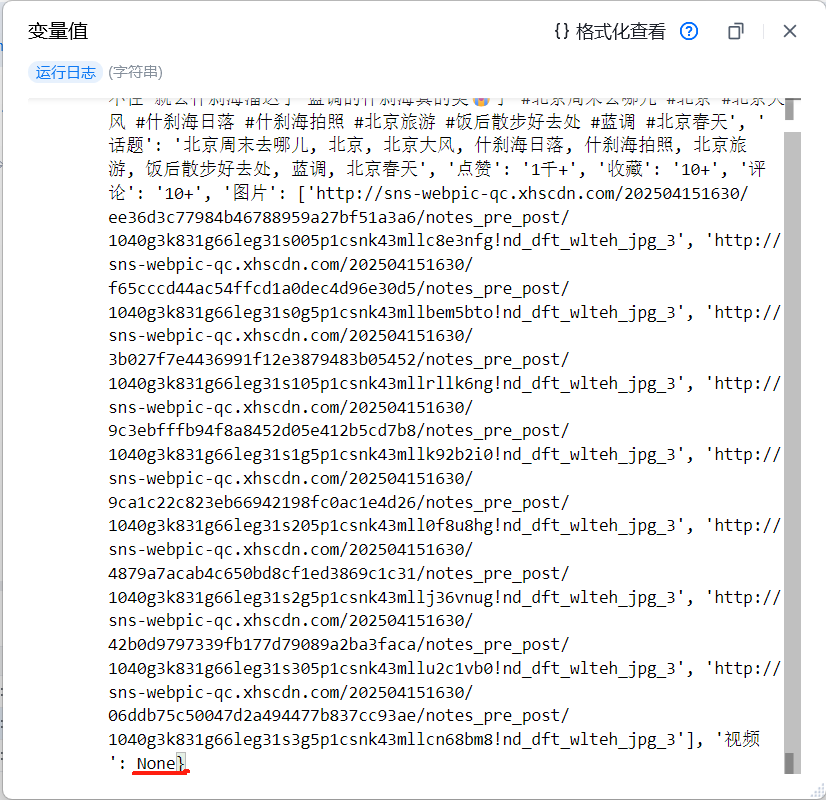

运行效果:
相关文章:
影刀RPA | 如何使用RPA采集小红书主页笔记,运行报错避坑指南


















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









