






一.主从复制
主从复制简介
在实际的生产中,为了解决Mysql的单点故障已经提高MySQL的整体服务性能,一般都会采用「主从复制」。
比如:在复杂的业务系统中,有一句sql执行后导致锁表,并且这条sql的的执行时间有比较长,那么此sql执行的期间导致服务不可用,这样就会严重影响用户的体验度。
主从复制中分为「主服务器(master)「和」从服务器(slave)」,「主服务器负责写,而从服务器负责读」,Mysql的主从复制的过程是一个「异步的过程」。
这样读写分离的过程能够是整体的服务性能提高,即使写操作时间比较长,也不影响读操作的进行。
主从复制的原理
首先放一张Mysql主从复制的原理图,总的来说Mysql的主从复制原理还是比较好理解的,原理非常的简单。

主从复制工作过程
MySQL 主服务器开始写入数据,就会记录在二进制日志文件中。从服务器有两个线程,分别是 I/o线程 与 SQL 线程。这时从服务器就会让 I / O 线程在 主服务器上打开一个口,这时会读取二进制日志文件写入中继日志中,SQL 线程就会读取中继日志,并重放日志中的事件,从服务器就会通过日志来同步主服务器。
主从搭建
下面我们就来实操搭建主从,使用的是两台centos7并且安装的是Mysql 8来搭建主从,有一台centos 7然后直接克隆就行了。
1.基础设备准备
操作系统 CentOs7 mysql5.7
两台虚拟机 192.168.211.155(主) 192.168.211.154(从)
2.安装mysql
3.在两台数据库分别创建数据库
4.在主数据库进行如下配置
#修改配置文件,执行一下命令打开mysql配置文件 修改完重启MySQL
vi /etc/my.cnf
#在MySQL模块中添加配置信息
log-bin=mysql-bin #二进制文件名称
binlog-format=ROW #二进制日志格式
binlog-format有row、statement、mixed三种格式,row指的是把改变的内容复制过binlog-format=ROW去,而不是把命今在从服务器上执行一遍,statement指的是在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。mixed指的是默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
server-id=1 #要求各个服务器的id必须不一样
binlog-do-db=ipay_db #ipay_db数据库名称
5.配置从服务器登录到主服务器的账号授权
#授权操作
set global validate_password_policy=0:
set global validate_password_length=1;
grant replication slave on *.* to 'root'@'%' identified by '123456';
--刷新权限
flush privileges;
6、从服务器的配置
#修改配置文件,执行以下命令打开mysql配置文件
vi /etc/my.cnf
#在mysqld模块中添加如下配置信息
#二进制文件的名称
log-bin=mysql-bin
binlog-format=ROW #二进制文件的格式
server-id=2 #服务器的id
8、重启从服务器并进行相关配置
#重启mysql服务
systemctl restart mysqld
#登录mysql
mysql -uroot -p
#连接主服务器
change master to master_host='192.168.211.155',master_user='root',master_password='123456',master_port=3306,master_log_file='mysql-bin.000006',master_log_pos=154;

master_log_file与master_log_pos与上图一致 如果找不到上图就是下图的log-bin为OFF (OFF为关闭,ON为打开)

在这里可以看到日志文件的开启状态log_bon on/off和其他日志配置信息,我这里是已开启日志。若日志未开启则把/etc/my.cnf文件中的log-bin=mysql-bin紧挨着【mysqld】写
#启动slave
start slave
#查看slave的状态
show slave status\G(注意没有分号) 必须全部为yes 为no 可能日志文件不对

二.amoeba读写分离
一、关于读写分离
1.读写分离(Read/Write Splitting),基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。
数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.读写分离原理:

3.读写分离过程:
amoeba作为访问数据库的前端程序,当其接收到来自客户端或者是应用段的sql语句对数据库做处理的时候,将sql语句进行分类,比如sql语句中有select关键词则作为数据库读操作,否则作为数据库写操作。Amoeba作为数据库和客户端的中间件,会同时链接master数据库和slave数据库。由于一般网站读操作远多于写操作,所以我们定义master数据库做为写操作的数据库,slave数据库作为读操作的数据库。这样amoeba就会将来自于客户端的写操作路由到master数据库,将读操作路由到slave数据库,来实现读写分离功能。
二.什么是amoeba?
Amoeba 的中文名是:变形虫。它是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy。它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特定的数据库上执行。基于此可以实现负载均衡、读写分离、高可用性等需求。
Amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。
Amoeba 由陈思儒开发,曾经就职阿里巴巴!该程序由 Java 程序开发。
主要解决:
·降低 数据切分带来的复杂多数据库结构
提供切分规则并降低 数据切分规则 给应用带来的影响
·降低db 与客户端的连接数
·读写分离
Amoeba的优缺点
优点:
Amoeba主要解决以下问题:
a). 数据切分后复杂数据源整合
b). 提供数据切分规则并降低数据切分规则给数据库带来的影响
c). 降低数据库与客户端连接
d). 读写分离路由
缺点:
a)、目前还不支持事务
b)、暂时不支持存储过程(近期会支持)
c)、不适合从amoeba导数据的场景或者对大数据量查询的query并不合适(比如一次请求返回10w以上甚至更多数据的场合)
d)、暂时不支持分库分表,amoeba目前只做到分数据库实例,每个被切分的节点需要保持库表结构一致
三、为什么要用Amoeba
目前要实现mysql的主从读写分离,主要有以下几种方案:
1、 通过程序实现,网上很多现成的代码,比较复杂,如果添加从服务器要更改多台服务器的代码。
2、 通过mysql-proxy来实现,由于mysql-proxy的主从读写分离是通过lua脚本来实现。mysql proxy根本没有配置文件,lua脚本就是它的全部,目前lua的脚本的开发跟不上节奏,而写没有完美的现成的脚本,这种东西需要编写大量的脚本才能完成一个复杂的配置。因此导致用于生产环境的话风险比较大,据网上很多人说mysql-proxy的性能不高。
3、 自己开发接口实现,这种方案门槛高,开发成本高,不是一般的小公司能承担得起。
4、 利用阿里巴巴的开源项目Amoeba来实现,具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库,并且安装配置非常简单。
。
下面是amoeba的结构,图中的ip不是实验中的IP

四、读写分离搭建
1、首先安装jdk,直接使用rpm包安装即可 并且安装mysql
本案例:jdk1.8.0-151
2、下载amoeba对应的版本https://sourceforge.net/projects/amoeba/,直接解压即可
本案例:amoeba-mysql-3.0.5-RC-distribution.zip
3、配置amoeba的配置文件
conf里面 amoeba.xml dbService.xml
Amoeba.xml配置

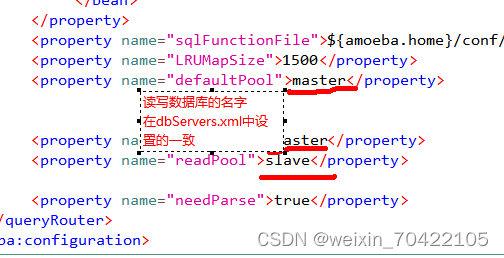
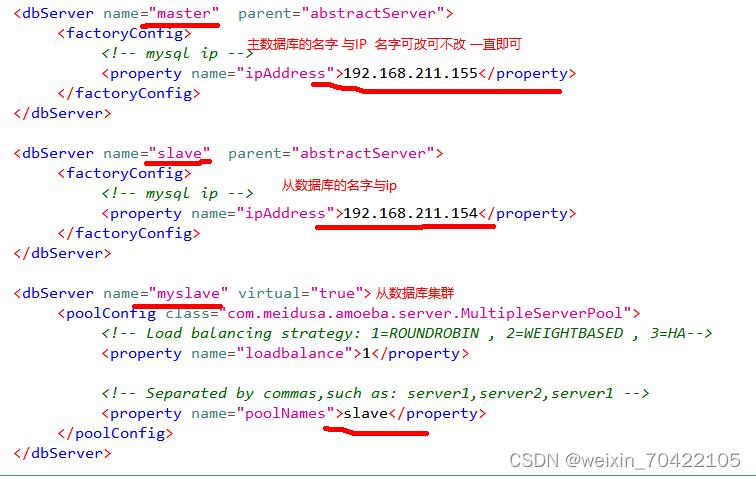
dbServers.xml 配置

启动amoeba
./bin/amoeba/bin/launcher
如报 The stack size specified is too small, Specify at least 228k
虚拟机内存太小
修改amoeba/jvm.properties文件 2.2.0版本的amoeba修改amoeba/bin/amoeba文件

如下图启动成功

测试
给数据库赋权
set global validate_password_policy=0;
set global validate_password_length=1;
黄色部分须按自己amoeba的配置修改
grant all privileges on *.* to 'amoeba'@'192.168.211.156' identified by '123456' with grant option;
从数据库链接amoeba
mysql -h192.168.211.156 -uamoeba -p123456 -P8066
如下图连接成功

分别在master和slave上查看插入的数据;
MariaDB [school]> select * from info;
+----+----------+-------+
| id | name | score |
+----+----------+-------+
| 1 | zhangsan | 89.00 |
+----+----------+-------+
停掉masterdb,然后在客户端分别执行插入和查询功能,发现master停掉后无法插入数据,但是可以查询
mysql> insert into info (id,name,score) values (2,'lisi',90);
ERROR 1044 (42000): Amoeba could not connect to MySQL server[172.16.40.2:3306],拒绝连接
mysql> select * from info;
+----+----------+-------+
| id | name | score |
+----+----------+-------+
| 1 | zhangsan | 89.00 |
| 2 | lisi | 90.00 |
+----+----------+-------+
开启master,然后停止slave,分别在客户端插入和查询,返现无法查询,但是可以插入
mysql> insert into info (id,name,score) values (3,'lily',92);
Query OK, 1 row affected (0.05 sec)
mysql> select * from info;
ERROR 1044 (42000): poolName=myslave, no valid pools
然后打开slave,查看同步情况,发现数据已经同步完成
MariaDB [school]> select * from info;
+----+----------+-------+
| id | name | score |
+----+----------+-------+
| 1 | zhangsan | 89.00 |
| 2 | lisi | 90.00 |
| 3 | lily | 92.00 |
+----+----------+-------+
至此发现主从同步和读写分离是正常的。
附加:
1:查看显示所有数据库
mysql> show databases;
2:查看当前使用的数据库
mysql> select database();
3:查看数据库使用端口
mysql> show variables like ‘port’;
4:查看当前数据库大小
例如,我要查看INVOICE数据库的大小,那么可以通过下面SQL查看
mysql> use information_schema
查看数据所占的空间大小
mysql> use information_schema;
查看索引所占的空间大小
mysql> select concat(round(sum(index_length)/(1024*1024),2),’MB’) as ‘DB Size’
5:查看数据库编码
mysql> show variables like ‘character%’;
character_set_client 为客户端编码方式;
character_set_connection 为建立连接使用的编码;
character_set_database 为数据库的编码;
character_set_results 为结果集的编码;
character_set_server 为数据库服务器的编码;
6:查看数据库的表信息
mysql> show tables;
7:查看数据库的所有用户信息
mysql> select distinct concat(‘user: ”’,user,”’@”’,host,”’;’) as query from mysql.user;
8: 查看某个具体用户的权限
mysql> show grants for ‘root’@’localhost’;
9: 查看数据库的连接数
mysql> show variables like ‘%max_connections%’;
10:查看数据库当前连接数,并发数。
mysql> show status like ‘Threads%’;
11:查看数据文件存放路径
mysql> show variables like ‘%datadir%’;














 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









