






什么是redis?
redis是nosql(not only sql)非关系型数据库,采用键值对存储数据在内存中,读写速度非常快,因此常用来做缓存。
为什么redis这么快?特点?
- 单线程,每个命令具有原子性
- Redis 基于内存,内存的访问速度是磁盘的上千倍;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用。
Redis 5种常用的数据类型
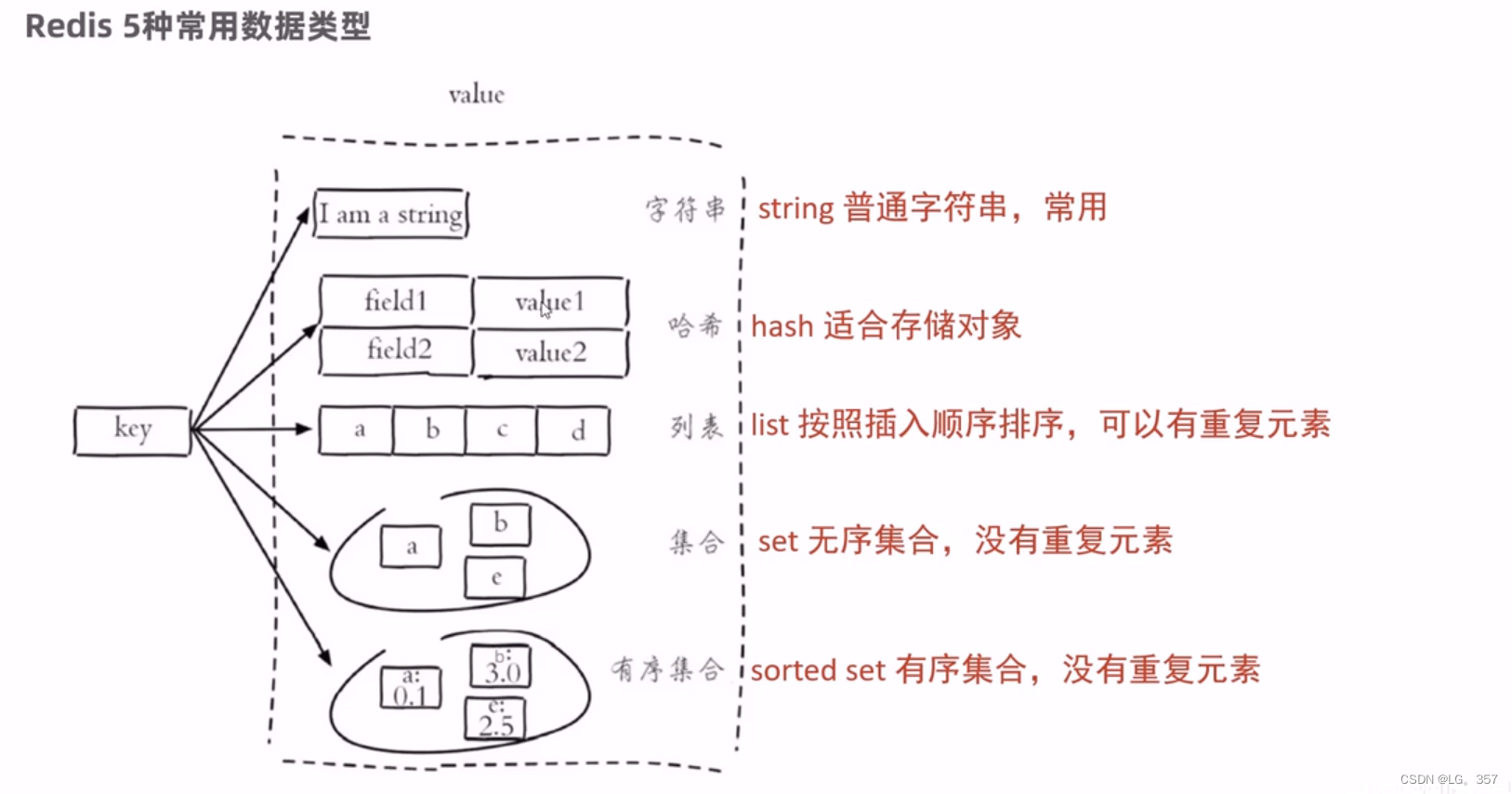
redis数据结构的应用场景:
-
String:一般的数据缓存、如token和验证码等
-
hash:缓存店铺信息,对象的信息等,还有就是可重入锁的计数器
-
list:点赞者记录,消息队列(缺点:单消费者模式,有信息丢失问题)
-
stream:可实现消息队列-消费者组模型,缺点是使用麻烦,不如mq和kafka方便


-
set:利用求交集可以实现共同关注,每个用户的关注列表都要缓存在redis中
-
zset:利用排序功能实现点赞的排行榜,
Redis的场景应用
1.基于redis实现短信验证码登录与权限校验。
1.需求分析
每个tomcat有独自的session,session在多个tomcat的集群模式下无法共享,因此需要用redis缓存验证码的数据,使得所有tomcat服务器都可见。
2.redis数据结构
redis中的string和Hash就可以实现
3.实现思路
使用redis共享缓存空间。将手机号码——验证码(String)、和token——用户的简化信息(hash)、存储到redis中。结合MVC请求路径拦截器实现登录和校验拦截。



2.登录拦截器
两个拦截器,一个对所有页面都刷新token,一个对限定页面拦截未登录用户。

3.设置缓存,不同的数据类型,设置不同缓存策略


双写一致性问题解决方案:
超时剔除和主动更新
但无法保证完全100%的一致性,除非加锁和不用redis。

redis三大缓存问题
1.缓存穿透:查询null值,直接穿透到数据库
- 缓存空对象:但可能造成数据短期不一致
- 布隆过滤器
- 增强id复杂度,做好基础格式校验
- 热点参数限流


2.缓存雪崩:同一时刻大量的缓存过期或者redis服务器宕机,导致所有的请求同时落到数据库中
- 设置随机过期时间
- redis集群
- 多级缓存
3.缓存击穿:热点key问题,某个热点key过期,并且缓存重建较慢,导致大量请求落到数据库中
-
互斥锁
- 优点:实现简单,给写数据库加锁
- 缺点:导致其他线程阻塞,性能差,还有死锁风险

全局唯一id生成
- UUID
- redis自增长
- 雪花算法
解决超卖问题和一人一单问题
-
超卖:卖出数量大于库存
- 使用悲观锁lock和s锁
- 使用乐观锁,cas原理,在数据库SQL里实现,当库存大于零才能修改成功。

-
一人一单问题(同一用户,高并发访问)
- 核验用户id和秒杀卷订单是否存在
- 对库存修改和创建订单加锁(双重检验)

- (userId.toString().intern()):获取值为用户id的字符串对象,intern()保证字符串对象唯一
- 集群模式下,使用分布式锁替代S锁。不同进程的内存独立,锁监视器不同,有线程安全问题。

分布式锁:满足分布式系统下或者集群模式下多进程可见的互斥锁
为什么选用redis的String结构实现分布锁?

redis分布式锁实现原理:redis实现了多进程可见,共用一个锁监视器
- 利用setnx的互斥特性创建锁

- 超时误删的问题:自己锁没了,删了别人的
- 优化,将key的value用UUID和线程ID拼接,解锁前进行校验value是否相同。进程用UUID区分,线程用线程id区分,妙!!!

- 再进一步优化,利用lua脚本将校验和解锁原子化,防止误删问题!
- 设置超时释放,保证redis宕机后不会死锁,解锁进行校验

redis分布式锁的缺点
- 不可重入
- 不可重试
- 超时释放可能导致误删
redisson分布式锁
- 可重入:利用了hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败重试机制
- 超时续约:解锁前永不过期,利用watchdog,每隔一段时间(leaseTime的1/3),重置超时时间

redisson配置流程
- 添加坐标依赖

- 配置RedissonClient第三方bean

redis和redisson分布式锁的区别
-
redis
- 原理:利用setnx的互斥性实现锁;利用ex设置了超时释放,避免死锁;释放锁判断标识避免误删;
- 缺点:不可重入,不可重试,锁超时可能失效
-
redisson:
- 原理:利用hash结构记录线程标识和重入次数,实现可重入;利用信号量和订阅机制实现锁可重试;利用看门狗机制实现了超时释放延时。
- 缺点:集群模式下主redis宕机会引起锁失效问题
-
redisson的multiLock:
- 原理:设置多个独立的主redis节点,必须全部获取锁成功才算
- 缺陷:运维成本高、实现复杂
redis实现异步秒杀的优化
-
基于阻塞队列实现异步秒杀
- 缺点:有可能会丢失数据,无法返回处理结果,单消费者模式性能差
-
基于Stream实现异步秒杀
- 优点:可持久化,消息回溯

- 优点:可持久化,消息回溯
秒杀业务总结(redisson分布式锁+lua原子性+Stream消息队列+redis缓存实现异步秒杀!)
-
缓存
- 使用redis实现秒杀券和下单用户的缓存
- 提高了秒杀资格的判断速度,减少了数据库高并发量下的负担
- 使用redis缓存实现库存的扣减
- 实现了异步下单,提高了并发性能
- 使用redis实现秒杀券和下单用户的缓存
-
超卖问题
- 基于乐观锁(cas)和悲观锁(s锁)解决
-
基于redis的分布式锁
- redis的string结构实现的分布式锁
- 解决了一人一单的问题
- 解决了集群模式下,锁的互斥性问题
- 添加UUID和线程ID为value标识,解决锁的误删问题
- redis的ex命令解决了锁超时释放问题
- redis的hash结构实现的分布式锁
- 用value记录锁重入次数,解决了锁不可重入的问题
- redisson锁
- 集大成者,封装好的锁
- 可重入,发布订阅信号量解决可重试问题,看门狗解决锁超时释放问题
- redis的string结构实现的分布式锁
-
lua脚本
- 解决下单资格判断和库存扣减的原子性问题
local voucherId = ARGV[1] local userId = ARGV[2] local id = ARGV[3] local stockKey = 'seckill:stock:' .. voucherId local orderKey = 'seckill:order:' .. voucherId -- 判断库存 if (tonumber(redis.call('get', stockKey)) <= 0) then return 1 end -- 判断订单 if (redis.call('sismember', orderKey, userId) == 1) then return 2 end --扣减库存 redis.call('incrby', stockKey, -1) --下单保存用户 redis.call('sadd', orderKey, userId) --创建消息队列,并且发送消息, XADD stream.orders * k1 v1 k2 v2 k3 v3 redis.call('xadd', 'stream.orders','*','voucherId',voucherId,'userId',userId,'id',id) return 0 - 使用redistemplate调用lua脚本
- 初始化lua脚本
//静态代码块初始化lua脚本 private static final DefaultRedisScript<Long> SECKILL_SCRIPT; static { SECKILL_SCRIPT = new DefaultRedisScript<>(); SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua")); SECKILL_SCRIPT.setResultType(Long.class); } -
api调用
Long result = redisTemplate.execute( SECKILL_SCRIPT, Collections.emptyList(), voucherId.toString(), userid.toString(), orderId );
- 初始化lua脚本
- 解决下单资格判断和库存扣减的原子性问题
-
redis消息队列
- 基于list
- 基于发布订阅
- 基于stream
- 创建消费者组和将下单数据放入队列


- 从队列中获取第一条未处理的任务

- 从pendinglist中获取第一个任务

- 创建消费者组和将下单数据放入队列
redis的feed流实现朋友圈推送
- 拉模式:内存暂用少,但是处理慢,不适用
- 推模式:内存占用多,但是快,单个粉丝量级在千万以下适用
- 推拉结合:在拉模式的基础上,对个别活跃用户群组进行推模式,适用于千万级粉丝的大v
1.需求分析
用户每次发布博客,粉丝都可以按照发布时间顺序获取到。使用推模式速度更快
2.数据结构
redis中的sortedSet可以对每个用户维护一个blog的推送列表,
3.实现思路
每次用户发布博客,根据用户关注表获取该用户所有粉丝的id,对每个粉丝用zset创建feed组,将新建blog的id放入value,当前时间戳作为score。
// 获取粉丝id,推送blog消息
List<Follow> list = followService.lambdaQuery().eq(Follow::getFollowUserId, user.getId()).list();
List<Long> ids = list.stream().map(Follow::getUserId).collect(Collectors.toList());
for (Long id : ids) {
redisTemplate.opsForZSet().add(RedisConstants.FEED_KEY + id,blog.getId().toString(),System.currentTimeMillis());
}redis实现Feed流滚动分页
1.需求分析
通过对数据添加时的时间戳降序排序进行滚动分页,滚动分页角标会发生变化
2.数据结构
List和SortedSet可以实现分页
List
只能通过角标查询,可以实现按时间戳降序排序,即从最大角标开始分页,但角标会变化,会引发一些问题。
举个例子:
当前List中有角标分别为1,2,3,4,5,6的6条数据,page为1,size为5时分页显示出角标为6,5,4,3,2的数据,此时插入一条数据,List中数据为1,2,3,4,5,6,7,page为2,size为5时分页显示出角标为2,1的数据。
可以看出角标为2的数据重复展示了,所以List不能实现滚动分页。
SortedSet
SortedSet可以通过 score进行排序,并且score代表的时间戳是不会变的,所以通过score可以进行滚动分页。
3.实现思路
redis命令为:

我们这里
max: 时间戳
min: 0
offset: 偏移量
count: 分页size
为了防止出现查询重复现象,每次返回上次查询时间戳的最大值max和重复出现的数量offset
long min = 0;
int offset = 1;
for (ZSetOperations.TypedTuple<String> record : records) {
Blog blog = blogService.getById(record.getValue());
queryBlogUser(blog);
isBlogLike(blog);
blogList.add(blog);
long time = record.getScore().longValue();
if(time == min){
offset++;
}else {
min = time;
offset = 1;
}但是极端情况下会进入死循环,如:连续两页数据的时间戳都相同!
解决思路:只记录第一次查询的当前时间戳max,offset初始为0,每查到一个新的数据offset+1;每次结束返回max和offset。
redis实现签到和统计功能
1.需求分析
将每个用户的签到信息持久化保存在数据库中,内存占用太大不现实,因此需要redis存储每个用户每日的签到记录
2.数据结构
redis中基于String数据类型实现的BitMap,bit最大为2^32位,可以用4个字节(32位的bit)来存储每月的签到记录
3.实现思路
- 每次签到,今日的在当前月的天数,通过命令setbit修改bit中对应位数的value为1

其中offset为修改的位数角标(从0开始):为天数-1
统计连续签到天数:
- 通过命令bitfield来获取本月至今的签到记录,返回值为10进制的数
![]()
![]()
其中get、set为副命令,选用get。
type:有无符号,以及查询位数,如u14:查无符号14位
offset:查询起点角标0
- 获取返回值后,通过循环位运算&和>>>来统计其二进制最右边1的连续个数,即位结果
long o = (long) record.get(0);
int count = 0;
while (true) {
if ((o & 1) == 1) {
count++;
o >>>= 1;
} else break;
}













 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









