







根据实际项目经验,从零开始介绍推荐的基础知识与整体框架。希望能帮助大家在了解部分碎片化知识后,形成对推荐系统全貌的认知。
01 推荐算法的理解
如果说互联网的目标就是连接一切,那么推荐系统的作用就是建立更加有效率的连接,节约大量用户与内容和服务连接的时间和成本。
如果把推荐系统简单拆开来看,推荐系统主要是由数据、算法、架构三个方面组成。
-
数据提供了信息。数据储存了信息,包括用户与内容的属性,用户的行为偏好例如对新闻的点击、玩过的英雄、购买的物品等等。这些数据特征非常关键,甚至可以说它们决定了一个算法的上限。
-
算法提供了逻辑。数据通过不断的积累,存储了巨量的信息。在巨大的数据量与数据维度下,人已经无法通过人工策略进行分析干预,因此需要基于一套复杂的信息处理逻辑,基于大量的数据学习返回推荐的内容或服务。
-
架构解放了双手。架构保证整个推荐自动化、实时性的运行。架构包含了接收用户请求,收集、处理,存储用户数据,推荐算法计算,返回推荐结果等。一个推荐系统的实时性要求越高、访问量越大,那么这个推荐系统的架构会越复杂。
02 推荐系统的整体框架

推荐的框架主要有以下几个模块
-
协议调度:请求的发送和结果的回传。在请求中,用户会发送自己的ID,地理位置等信息。结果回传中会返回推荐系统给用户推荐的结果。
-
推荐算法:算法按照一定的逻辑为用户产生最终的推荐结果,不同的推荐算法基于不同的逻辑与数据运算过程。
-
消息队列:数据的上报与处理。根据用户的ID,拉取例如用户的性别、之前的点击、收藏等用户信息。而用户在APP中产生的新行为,例如新的点击会储存在存储单元里面。
-
存储单元:不同的数据类型和用途会储存在不同的存储单元中,例如内容标签与内容的索引存储在mysql里,实时性数据存储在redis里,需要进行数据统计的大量离线数据存储在hivesql里。
03 用户画像
3.1 用户标签
标签是我们对多维事物的降维理解,抽象出事物更具有代表性的特点。我们永远无法完全的了解一个人,所以我们只能够通过一个一个标签的来刻画他,所有的标签最终会构建为一个立体的画像,一个详尽的用户画像可以帮助我们更好的理解用户。
3.2 用户画像的分类

3.2.1. 原始数据
原始数据一共包含四个方面(以游戏内容推荐为例)。
-
用户数据:例如用户的性别、年龄、渠道、注册时间、手机机型等。
-
内容数据:例如游戏的品类,对游戏描述、评论的爬虫之后得到的关键词、标签等。
-
用户与内容的交互:基于用户的行为,了解了什么样的用户喜欢什么样的游戏品类、关键词、标签等。
-
外部数据:单一的产品只能描述用户的某一类喜好,外部数据标签可以让用户更加的立体。
3.2.2. 事实标签
事实标签可以分为静态画像和动态画像。
-
静态画像:用户独立于产品场景之外的属性,例如用户的自然属性,这类信息比较稳定,具有统计性意义。
-
动态画像:用户在场景中所产生的显示行为或隐式行为:
-
显示行为:用户明确的表达了自己的喜好,例如点赞、分享、评分、评论(可以通过NLP来判断情感的正负向)等。
-
隐式行为:用户没有明确表达自己的喜好,但用户会用实际行动,例如点击、停留时长等隐性的行为表达自己的喜好。隐式行为的权重小于显性行为,但是在实际业务中,用户的显示行为都比较稀疏,所以需要依赖大量的隐式行为。
3.2.3. 模型标签
模型标签是由事实标签通过加权计算或是聚类分析所得。通过一层加工处理后,标签所包含的信息量得到提升,在推荐过程中效果更好。
-
聚类分析:例如按照用户的活跃度进行聚类,将用户分为高活跃-中活跃-低活跃三类。
-
加权计算:根据用户的行为将用户的标签加权计算,得到每一个标签的分数,用于之后推荐算法的计算。
04 内容画像
4.1 内容画像
推荐内容与场景通常可以分为以下几类,根据所推荐的内容不同,其内容画像的处理方式也不同。
-
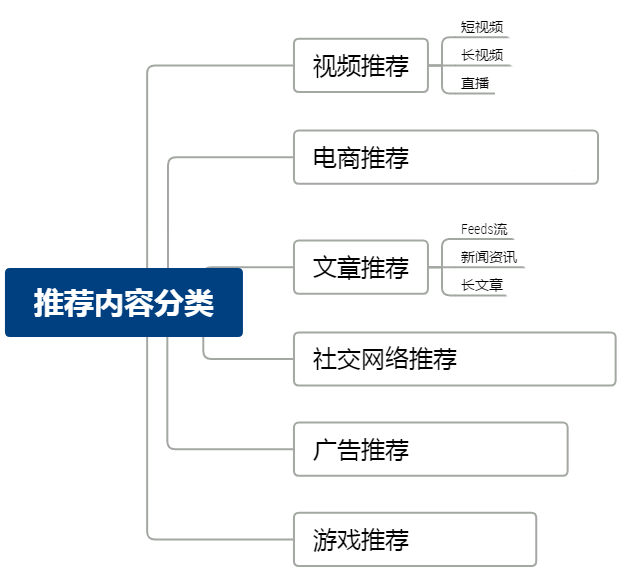
文章推荐:例如新闻内容推荐,需要利用NLP的技术对文章的标题,正文等提取关键词、标签、分类等。
-
视频推荐:除了对于分类、标题关键词的抓取外,还依赖于图片与视频处理技术,例如识别内容标签、内容相似性等。
4.2 环境变量
内容画像外,环境画像也非常重要。例如在短视频的推荐场景中,用户在看到一条视频所处的时间、地点以及当时所浏览的前后内容、当天已浏览时间等也是非常重要的信息,但由于环境变量数据量较大、类型较多,对推荐架构以及工程实现能力的要求也较高。
05 算法构建
5.1 推荐算法流程
推荐算法其实本质上是一种信息处理逻辑,当获取了用户与内容的信息之后,按照一定的逻辑处理信息后,产生推荐结果。热度排行榜就是最简单的一种推荐方法,它依赖的逻辑就是当一个内容被大多数用户喜欢,那大概率其他用户也会喜欢。但是基于粗放的推荐往往会不够精确,想要挖掘用户个性化的,小众化的兴趣,需要制定复杂的规则运算逻辑,由机器完成。
推荐算法主要分为以下几步:
-
召回:当用户以及内容量比较大的时候,往往先通过召回策略,将百万量级的内容先缩小到百量级。
-
过滤:对于内容不可重复消费的领域,例如实时性比较强的新闻等,在用户已经曝光和点击后不会再推送到用户面前。
-
精排:对于召回并过滤后的内容进行排序,将百量级的内容按照顺序推送。
-
混排:为避免内容越推越窄,将精排后的推荐结果进行一定修改,例如控制某一类型的频次,EE问题处理等。
-
强规则:根据业务规则进行修改,例如在活动时将某些文章置顶以及热点内容的强插等。

5.2 召回策略
-
召回层目的:当用户与内容的量级比较大,例如对百万量级的用户与内容计算概率,就会产生百
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









