







读前总览:
目录
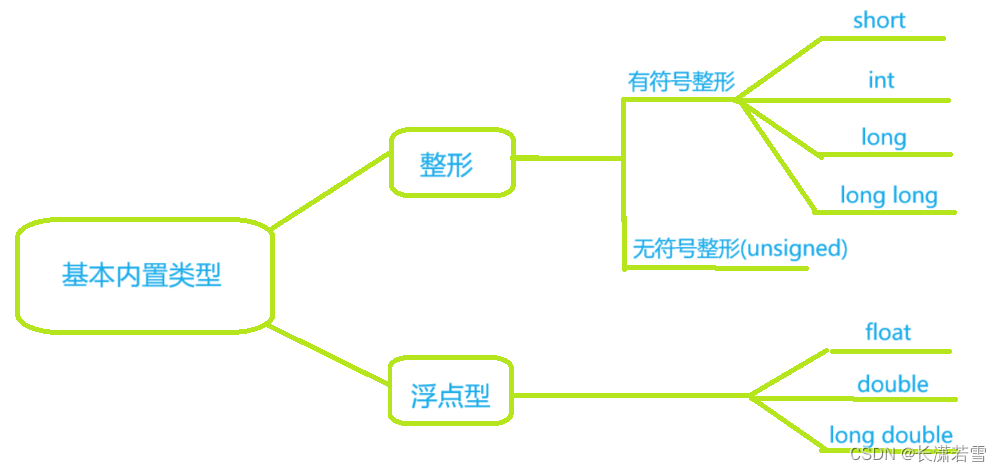
一、整型
1.整型简介
整型就是没有小数部分的数,如-1,0,和100。试想一下,能否把一个趋于无穷的整数存入计算机内?那肯定是不能的,因为计算机的内存是有限的,存储越大的数需要的内存也越多。就像我们人吃饭一样,饭量小的吃的少,饭量大的吃的多,所以人们会根据自己的饭量来选择,不然打多了浪费,打少了挨饿。计算机也是一样的,程序员要根据数据的范围选择合适的类型,不然空间太小了存储不了信息,空间太大了浪费内存,毕竟内存就那么大。
2.整型分类
内存知识介绍:
计算机内存的基本单元是位(bit),只能存储0和1。计算机内部由逻辑电路组成,这些电路只有两种状态:开关的接通与断开,这两种状态正好可以用二进制数中的“1”和“0”来表示。但是,用位来描述数据太过细致,一般都是使用字节来描述。字节(byte)通常指的是八位的内存单元,也就是1字节 = 8位,这八位的总组合数为2222222*2,也就是256。因此,可以表示0-255或者-128-127,每增加一位,组合数便翻倍。
如何分类:
通过上述知识的介绍,整形其实就是通过使用不同的位数来存储数据从而进行分类。
2.1 有符号整型
2.1.1如何查看各类型所占位数
有符号整形既可以存储正数也可以存储负数。按照在内存中所占位数从小到大为:short、int、long和long long。C++标准并没有明确规定这些类型的宽度,只是提供了一种灵活的标准:
1)short至少16位
2)int至少和short一样长
3)long至少32位
4)long long至少64位,且至少与long一样长
当然,具体的长度由所使用的环境和编译器决定。可以通过包含头文件climits,来查看你的编译器上它们的长度和最大值最小值。下面是visual studio 2022中的iostream文件中整形变量的最大、最小值:
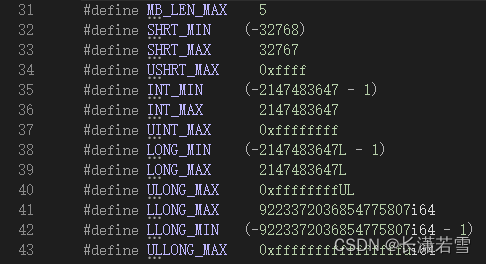
#define是一种预处理指令,在对代码进行编译之前,把紫色标识符,替换为后面的值,就是符号常量。由于包含了头文件climits我们就可以直接通过下面的代码把它们的值打印出来:
// 头文件的包含
#include <iostream>
#include <climits>
using namespace std; // 使用标准名称空间
int main()
{
cout << "short 的最小值:" << SHRT_MIN << endl;
cout << "short 的最大值" << SHRT_MAX << endl;
cout << "int 的最小值:" << INT_MIN << endl;
cout << "int 的最大值:" << INT_MAX << endl;
cout << "long 的最小值:" << LONG_MIN << endl;
cout << "long 的最大值:" << LONG_MAX << endl;
cout << "long long 的最小值:" << LLONG_MIN << endl;
cout << "long long 的最大值:" << LLONG_MAX << endl;
return 0;
}
代码运行结果如下:
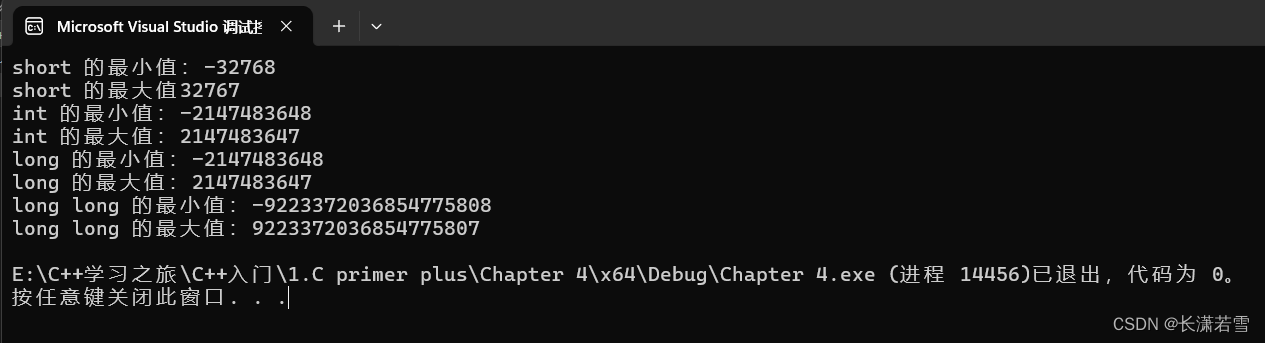
这样就可以计算出来编译器上各种整形类型所占的位数大小了。还有一种方式同样可以得出结果,使用sizeof运算符,使用格式为:sizeof(类型名),返回类型的所占字节数。代码如下:
cout << "short 的字节数为:" << sizeof(short) << endl;
cout << "int 的字节数为:" << sizeof(int) << endl;
cout << "long 的字节数为:" << sizeof(long) << endl;
cout << "long long 的字节数为:" << sizeof(long long) << endl;
这里只提供了代码的主体部分,其余的头文件包含这些就交给大家了。运行结果如下:

1字节 = 8位,大家乘以8就可以算出结果了,和上面通过最大最小值计算的结果是相同的。
2.1.2如何区分正负
有符号整形通过最高位来表示正负,最高位为0表示正数,最高位为1表示负数。我们用int类型举个例子吧,
int a = 1;
int b = -1;
分别定义了两个int类型的变量a、b,把它们初始化为1,-1。理论上他们存储在计算机中的二进制编码(原码)为:
a : 0000 0000 0000 0000 0000 0000 0000 0001
b : 1000 0000 0000 0000 0000 0000 0000 0001
但实际上却不是这样的,计算机中是按照如下方式存储的:
a : 0000 0000 0000 0000 0000 0000 0000 0001
b : 1111 1111 1111 1111 1111 1111 1111 1111
我们先介绍几个概念,原码、反码和补码。原码就是数据本来的二进制编码,就是我们理论上打印的a和b的编码。反码是除了符号位(也就是二进制最高位)以外,其他位取反,取反的意思就是1变成0,0变成1。a和b的反码如下:
a : 0000 0000 0000 0000 0000 0000 0000 0001
b : 1111 1111 1111 1111 1111 1111 1111 1110
补码就是在反码的基础上加1,a和b的补码如下:
a : 0000 0000 0000 0000 0000 0000 0000 0001
b : 1111 1111 1111 1111 1111 1111 1111 1111
计算机中以二进制的补码形式存储数据,且规定正数的原码、反码和补码相同。现在大家应该能理解为什么实际上a和b的二进制编码是这样了吧。至于为什么要以补码的形式存储,大家可以去百度上面科普一下或者观看相关视频讲解。这里只要知道如何区分正负数的就行。(不要问为什么作者不讲解,因为作者自己也不太懂)
有人问int类型有32位,理论上可以表示2^32(2的32次方)个数,为什么实际上只有2的31次方个数(int类型的最大值 - 最小值)?一看你小子就没认真看我上面的板书,这是有符号整形,最高为被当做符号位了,剩下不就只有31位了嘛。
2.2无符号整型
2.2.1与有符号整型的区别
其实无符号整形就是在有符号整形前面加了一个unsigned前缀修饰,声明变量的时候告诉编译器我要声明的是这个类型是无符号的。由于无符号类型没有负数,所以它的最高位就不用表示正负了,那么他所能表示的数的范围是同类型有符号的两倍,十进制多一位乘以10,二进制多一位乘以2嘛。无符号整型所占位数和同类型有符号整形相同,int占32位,unsigned int也占32位。
2.3整型使用时如何选择
首先,你要大概估计一下你需要存储的数值范围,然后选择能存储的类型。内存空间都不够放,还选啥呀老弟。然后如果需要负数的话那肯定选择有符号类型,如果没有负数的最好话选择相应的无符号类型,虽然有符号的类型空间也够,但是无符号能表示的范围更大,容错率更高嘛。
2.4整型溢出
虽然我们提前估算所需数值的范围,从而选择合适的整形类型。但是,在实际编写程序的时候,难免会不小心超出所选类型的最大范围。下面,我们分别从有符号和无符号类型来进行探究。
2.4.1有符号整型溢出
我们选择int类型作为小白鼠进行实验,首先定义两个int变量,分别给它们初始化为int类型的最大值和最小值,对最大值加1,对最小值减1,看看会怎么样。代码和输出结果如下:
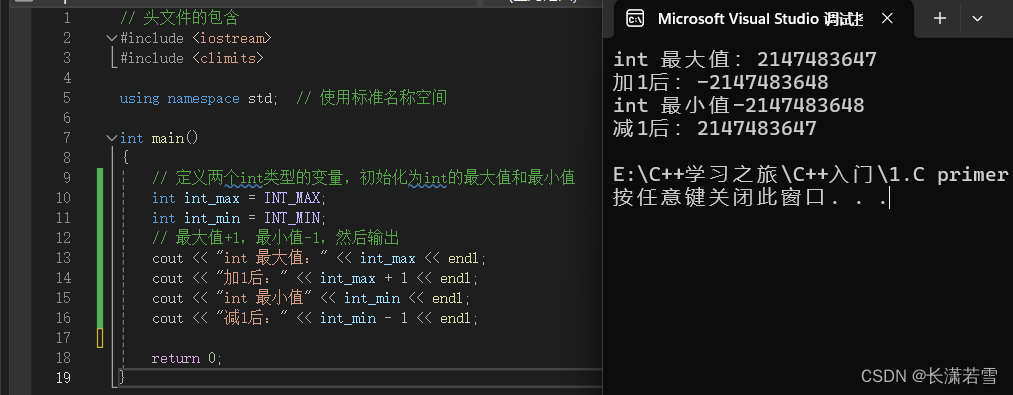
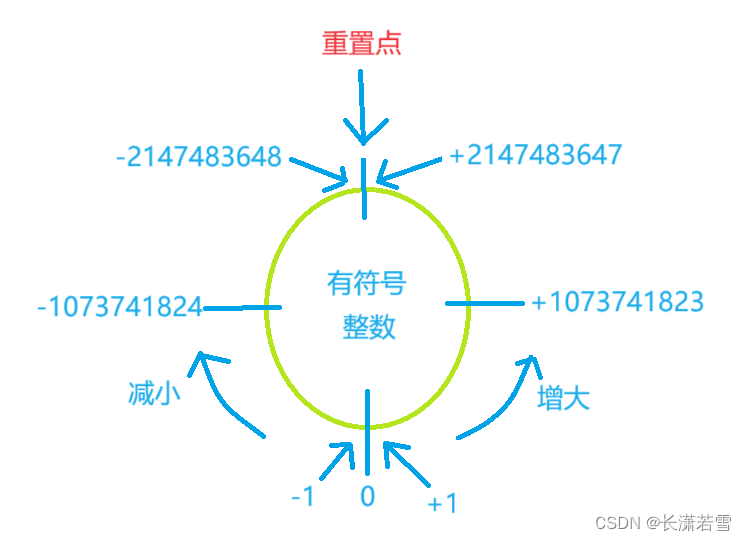
我们看到最大值+1,跑到最小值去了,最小值-1跑到最大值去了,就好像首尾相接了一样,画了张图描述了一下,大家不要嫌弃画的丑哈。
2.4.2无符号整型溢出
无符号整型选择unsigned int类型,操作和上面int类型一样。代码和输出结果如下:
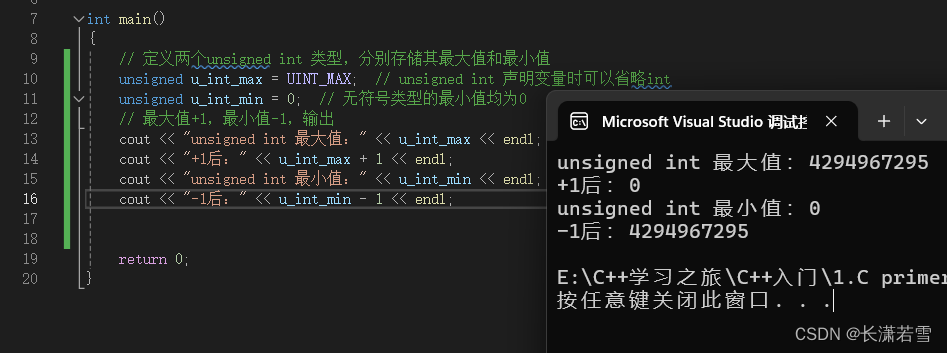
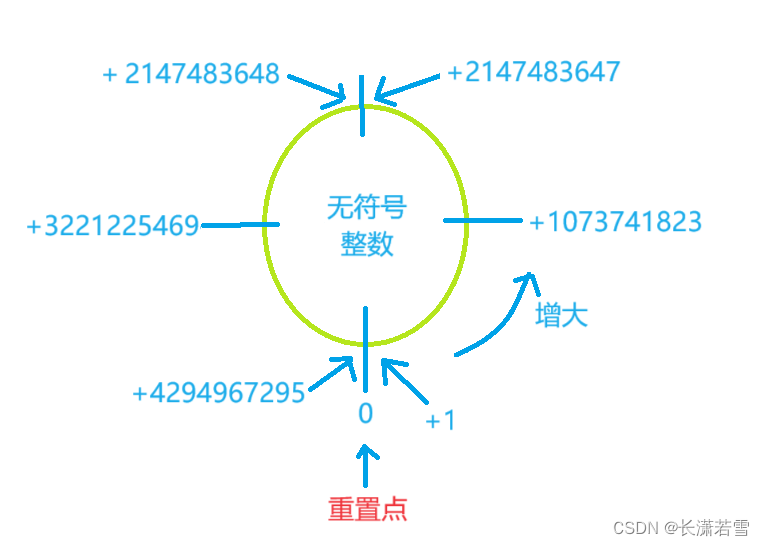
我们可以看到结果和有符号整型一致,均为超过最大值就从最小值开始,超过最小值就从最大值开始,首尾相接。
注意: 虽然有符号和无符号整型的溢出行为相同,但是C++只保证无符号类型溢出时像上面一样,不保证有符号类型。也就是说有符号类型溢出时不是百分之百按照上面的行为溢出。
2.5整形字面值
整形字面值(常量)就是直接显示的常量,如 int a = 10; 这个10就是直接显示的常量,也就是所谓的整形字面值。这条语句声明定义了一个int类型的变量a,并把整形字面值10的值赋给了变量a。其实,这个10也被存储在内存中,其实你想一下就能明白,编译器难道能凭空造个数出来?程序运行到这句话的时候,会先在内存中开辟一个空间,把10放进去,然后再开辟4个字节的空间存储变量a,最后用10初始化变量a。编译器要开辟空间首先要知道这个整形字面值的类型,不然怎么知道开辟多大的空间。由于int类型一般是计算机最自然的类型,也就是计算速度快,所以把整形字面值的类型一般都默认为int,除非存储不下。当存储的数值大于int最大值时,整形字面值按照如下顺序选择能存储的最小类型:
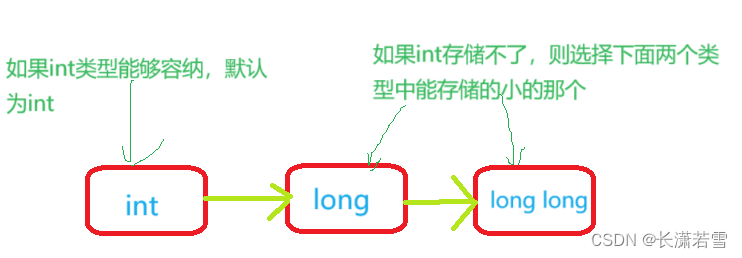
我们也能通过使用后缀来明确告诉编译器这个整型字面值的类型,整数后面加上l或者L表示这个整数是long类型(l和1很像,一般后缀L避免混淆),u或者U后缀表示unsigned int,组合起来uL就是unsigned long,如下图:

二、浮点类型
1.浮点类型介绍
浮点类型就是表示带小数部分的数。相较于整型,它们提供的值的范围更大。如果数字很大,如人体的细菌数(大约100万亿个),超出long类型的范围,则可以使用浮点类型来表示。使用浮点类型存储像2.5、3.1415和13.14这样带小数的数字,计算机将这样的值分成两部分存储。一部分存储值,另一部分存储缩放因子。如314.159和3.14159这两个数,除了小数点位置不同,其他完全相同。于是可以把第一位数表示为0.314159(基准值)和1000(缩放因子),第二个数表示为0.314159(基准值)和10(缩放因子)。缩放因子的作用是移动小数点的位置,浮点数因此得名。C++在内存中存储时也是使用类似的方法,只不过它基于的是二进制数。我们不必了解其内部的存储方式,只要知道浮点类型能表示小数、非常大的数和非常小的数即可。
2.浮点数的分类
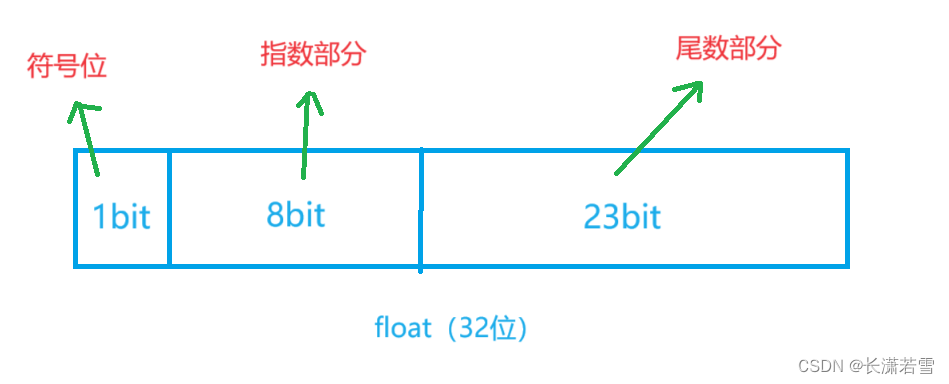
首先,浮点数和整型不一样,它没有无符号类型。在C++中有三种浮点类型:float、double和long double。这些类型根本上也是按照其所占位数大小来进行区分的,但是它的存储方式与整形不同。我们用32位的float(可以使用sizeof运算符计算)举例,把这32位内存单元分成三部分,最高位表示符号位,接下来8位表示指数部分,后面23位表示尾数部分,如下图:
三种类型的具体位数没有明确规定,double至少64位且至少和float一样长,long double至少和double一样长。可以通过sizeof运算符得到具体的位数。关于最大最小值这些信息,大家可以通过文件cfloat进行查看。
3.浮点数的精度问题
简单讲述一下浮点数在计算机中是如何存储的,如19.99这样的数字,首先是正数,符号位为0,然后把它看成0.1999*10^2,0.1999称为尾数部分,但存储的时候只存储1999这个整数,存入尾数部分,要使用的时候计算机会自动在前面加上0.前缀,这样节省空间,方便存储。指数部分就存储2,使用时自动乘以10的多少次方,和尾数部分一个道理。但是在计算机中底数为2,要转换为以2为底,这里不详细说明,知道就行。所以浮点数能表示的范围相当大,但是如果存储100.99999这个数字呢?就用float类型举例,这个数字肯定在它的范围之内,我们看代码和输出结果:

第一行代码让编译器以小数点后六位的形式输出,可以发现这个结果并不精确。float存储尾数部分只有23位,也就是最大存储2^23次方,8388608,七位数。而100.99999的尾数部分为10099999,八位数,超出了存储部分,但是原数100.99999在float的范围之内,所以编译器就会存储一个与它近似的数值进去。
4.浮点类型字面值常量
和整形一样,浮点型字面值是显式书写的带小数部分的常量,如1.88、1.34和0.03。浮点型字面常量有两种书写方式:
1)小数表示法:1.88、1.87这样常规直接书写。
2)E表示法:8.3E7相当于8.3*10^7,E前面是尾数,E后面是10的指数。注意,2.2E-2表示为0.022,E后面的负号只作用于10的指数部分,要表示负数要在最前面加负号。如-2.2E2表示为-220。
浮点型字面值默认类型为double,如果希望为float可添加后缀f或F,如果希望为long double可添加后缀l或L。
5.浮点类型的优缺点
与整数相比而言,浮点数有两大优点。首先,可以表示整数之间的数。其次由于指数部分的存在,浮点数可以表示的范围更大。但是,浮点数的计算速度相对于整数较慢,而且有精度范围,超出范围的值就不再精确。
三、操作和差异
1.数学运算的差异
在现实中,我们使用数字进行加减乘除等数学运算。在计算机中也是如此,但是与实际中又有所差异,并且计算机中还多了一个取模运算符%。
1.1加法、减法和乘法
这三种运算和实际中大差不差,我们分别选取整型中的int类型和浮点类型中的double类型,来进行这三种数学运算,代码和运行结果如下:
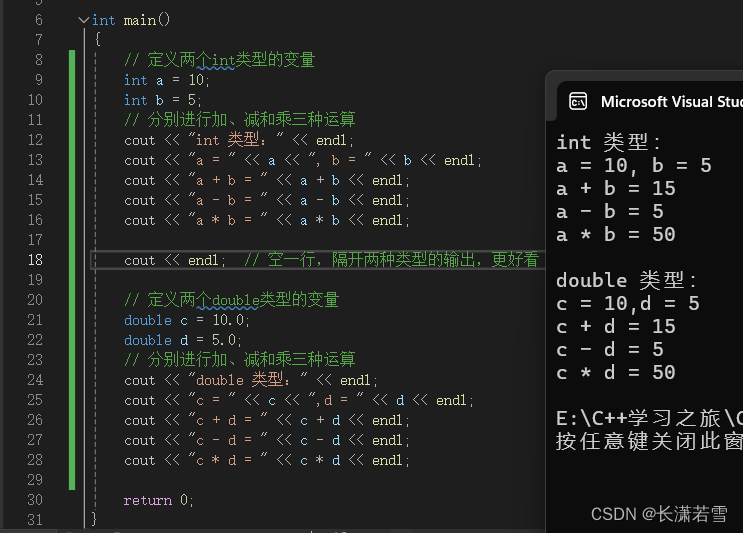
除了double类型带小数部分外,这两种类型在这三种运算上并无不同。(C++中使用符号*代表乘)
1.2除法
大家应该都能猜到这个除法肯定不一般,不然就不会给它开个专栏。除法大家肯定都不陌生,例如:2除以4 = 0.5,但是计算机里面又给你整活了,我们还是一样选择int和double类型,我们看代码:
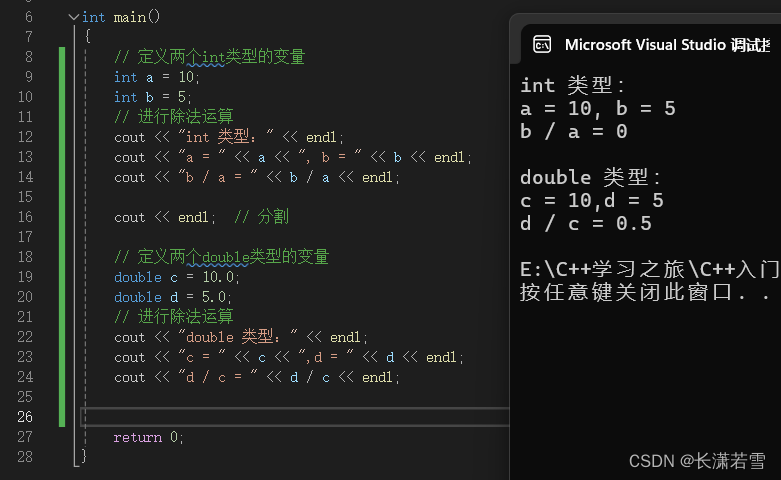
大家发现int类型不是预期的0.5而是0,这是为什么呢?这就牵扯到两种除法了(C++中符号/为除):
1)当符号 / 两边都是整型时,也就是两个整数相除,结果只保留整数部分。比如:10 / 3 的结果实际上是得3余1,但只保留整数部分,结果就是3,上面int类型的 b / a = 5 / 10 = 0,同样的道理,得0余5,保留0,丢弃5。
2)当符号 / 两边有一边为浮点类型,就进行浮点类型的运算,也就是实际生活中的除法。
1.3取模运算符 — %
取模运算符求左边的数除以右边的数的余数,该运算符只能用于整型,就是左右两侧必须都是整数。这也很好理解,整型的除法运算是丢弃余数,那我们取模运算的时候把余数捡回来就好了。我们来看看代码,如果两边都是整型int:
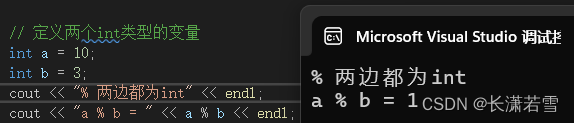
毫无疑问,正确运行。如果不小心用了浮点类型参与运算会如何?我们用double为例来尝试一下:
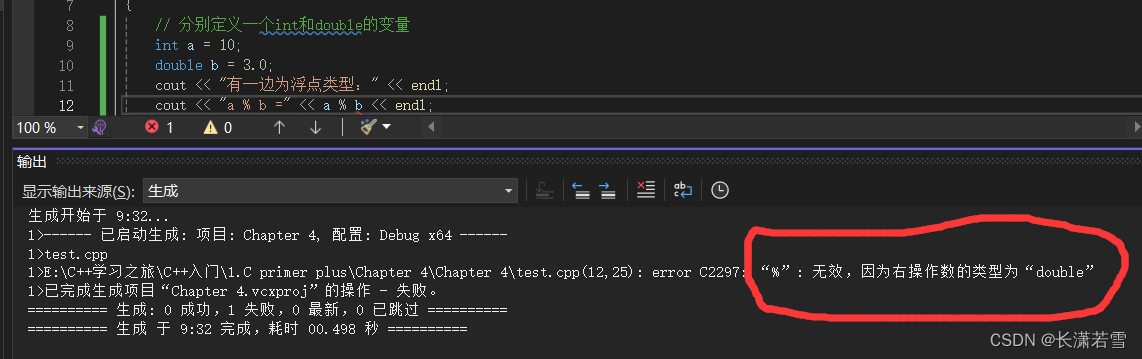
别说运行了,连编译都不通过。所以大家也不用特别担心,如果不小心用了浮点类型,编译器会给出错误提示。
2.不同类型之间操作的处理
我们编写程序,不可能总是在相同的类型之间进行操作,有时也会在多个类型之间来回操作。那编译器如何处理?结果又如何?
2.1类型转换
有时候我们创建变量的时候想偷懒,比如我们想把 double a = 3.0; 写成 double a = 3; ,但是字面值3是int类型的常量,这时编译器便会进行类型转换,使这个3变成double类型的。当然,既然编译器都能进行类型转换,程序员本身也可以。只不过前者是自动类型转换,而后者是强制类型转换。编译器也是没有办法,如果它不作为程序跑不动,会出问题,而我们就是想把一个类型强制转换为另一个类型。
2.1.1自动类型转换
C++会自动执行很多类型转换,但我们只谈下面这些:
1)将一种算数类型的值赋值给另一种算数类型的变量时,C++将对值进行转换
2)表达式中包含不同类型时,将对值进行转换
1)赋值时
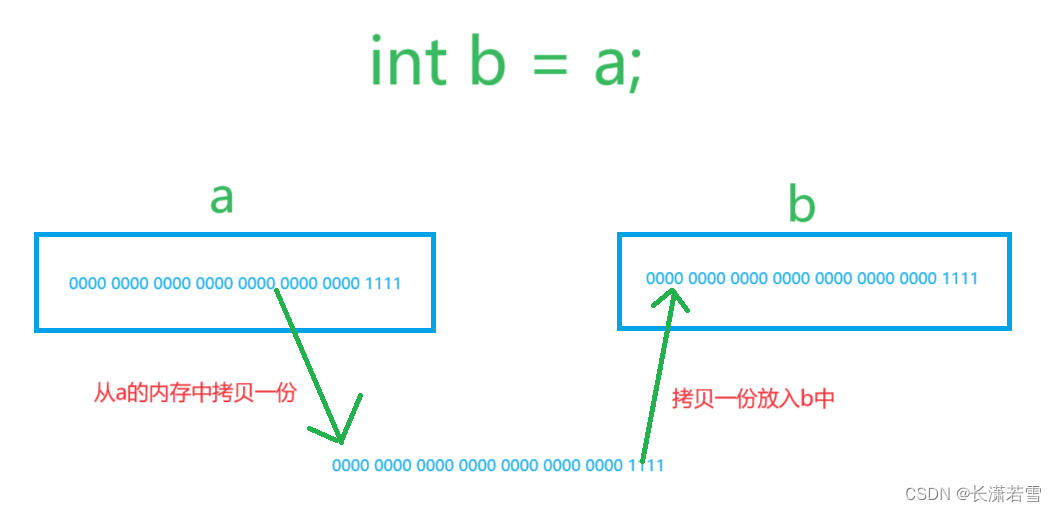
我们已经知道不同类型在内存中所占的位数不同,而赋值就是把赋值运算符=右侧的值赋值给左边,实际上就是把它的二进制编码拷贝一份放到左边的内存空间上。我们用int类型举例:
int a = 15;
int b = a;
第二句话就是把a内存中存的二进制编码拷贝到b上,如下图所示:
a.位数小的赋值给位数大的:
不同类型之间的赋值也是一样的,如果是位数小的类型赋值给位数大的类型,没有任何问题,只是把
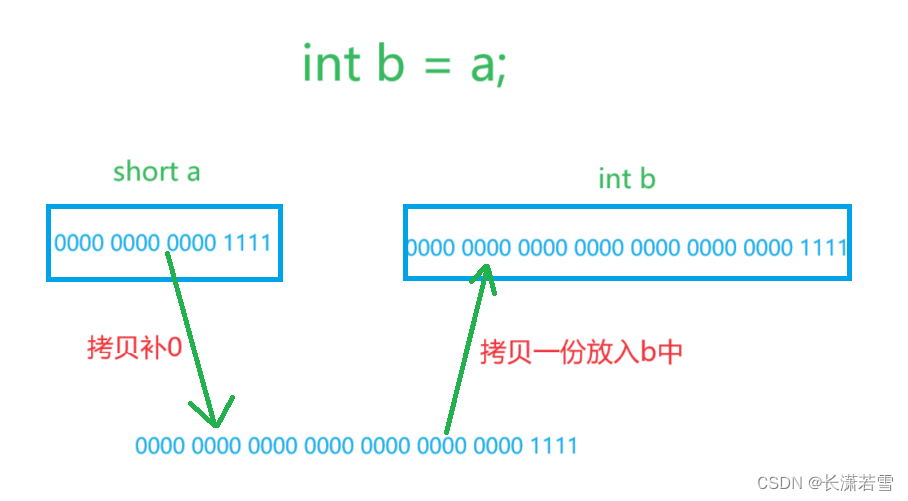
拷贝的位数前面补0(如果是负数的话,就在符号位1后面补0),使位数达到要求,然后放在自己的内存空间里,我们以short和int为例:
short a = 15;
int b = short;
由于short只有16位,拷贝过后会补充0达到int的32位,过程如下:
b.位数大的赋值给位数小的
如果是位数大的赋值给位数小的可能会造成数据损失,因为我们只能拷贝位数小的对象所能容纳的位数。我们依旧使用short和int为例,如下图:
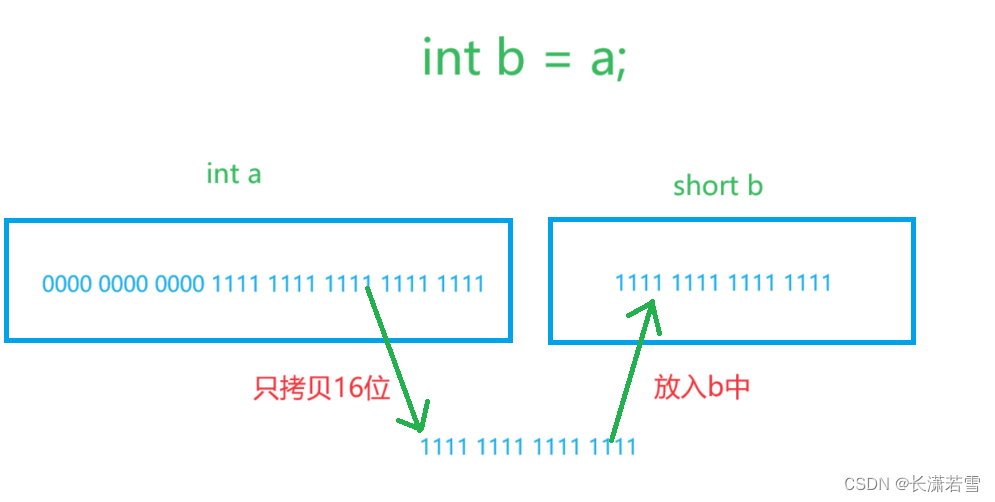
如上图所示,若int a的值超出了short b的最大值再赋给b会造成数据损失,毕竟b就16位这么大的空间。
所以,我们进行不同类型之间的赋值时,要先判断,是位数小的类型赋值给位数大的类型,还是位数大的类型赋值给位数小的类型。前者只是搬家换了一个更大的房子,房子空出来了不少。后者却是换了个更小的房子,那我必须丢掉一部分东西,不然房子放不下,这和数据损失是一个道理。浮点类型和整型之间的赋值类型转换和上面类似,但由于浮点类型的存储方式与整型不同,我们只要知道如下几点就行:
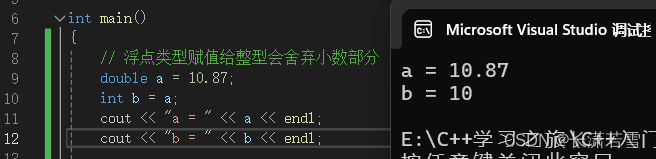
a.值小的赋值给值大的没有问题,记住这里是值,不是位数。但是浮点数赋值给整数会丢弃小数部分。
b.值大的赋给值小的产生的结果不确定,因为整型和浮点型的存储方式不同,且浮点数使用有效位数,不精确。
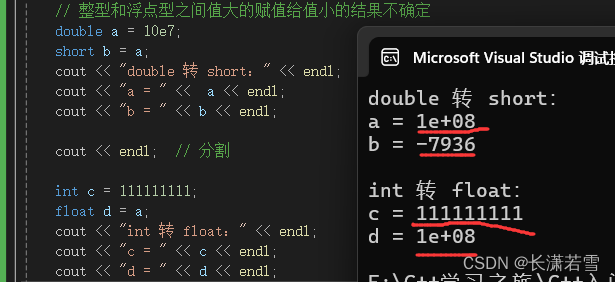
可以看到上面运行的结果没有一点规律可言,所以大家在进行浮点数和整数之间的转换是,切记提前计算一下大概范围,使用可以容纳的类型,防止产生不确定的结果。
2)表达式中
如果表达式中存在不同类型,则C++会依次查阅你所在编译器上的校验表,找到对应情况然后进行处理。下面是C++11版本的校验表:
a. 如果有一个操作数的类型是 long double ,则将另一个操作数准换为 long double 。
b. 否则,如果有一个操作数的类型是 double ,则将另一个操作数转换为 double。
c. 否则,如果有一个操作数的类型是 float,则将另一个操作数转换为 float。
d. 否则,说明操作数都是整型,执行整型提升。
e. 在这种情况下,如果两个操作数都是有符号或者无符号的,且其中一个级别比另一个级别高,则把级别低的转换为级别高的
f. 如果一个操作数为有符号的,一个操作数为无符号的,且无符号操作数的级别比有符号高,则将有符好数转换为无符号数类型。
g. 否则,如果有符号类型可以表示无符号类型的所有可能取值,则将无符号操作数转换为有符号操作数的类型。
h. 否则将两个操作数都转换为有符号类型的无符号版本
总之就一句话,如果两个操作数级别不同,就往级别高的那个类型转换(前提是能存储的下)。前面说的整数和浮点数进行除法,结果为浮点数,就是先把整型转换为浮点型,然后再进行的运算。还有如果是比int级别低的两个整型操作数进行运算,会先转换为int再进行运算。如下代码:
short a = 2;
short b = 3;
short c = a + b; // a和b先整形提升为int,然后相加得到结果5,然后转换为short存入c中
这是因为通常将int选择为计算机最自然的类型,计算机使用int进行计算时,速度可能会更快。
2.1.2强制类型转换
C++允许程序员通过强制类型转换来显式地进行类型转换,若要把变量a中的int值转换为long类型,可使用下面两个表达式中的一个:
(long)a
long(a)
两行都表示把变量a的值强制类型转换long类型,但强制类型转换不会改变变量a本身,而是创建一个新的、这种类型的变量,把a的值转换为对应类型后,放入新变量中,然后使用它,这种变量只是一个临时变量,使用完后就自动销毁。
强制类型转换的格式为:
(TypeName)val
TypeName(val)
第一种是C语言的转换风格,第二种是纯粹的C++。C++格式的想法是,使用强制类型转换就想使用函数调用一样。
这里只是简单地介绍了一下强制类型转换的使用方法,关于这方面的知识远远不止这些。除非真的需要使用强制类型转换,其他情况下,能不用尽量不用。因为作者也很少使用(可能是作者太菜了,还没到那个层次),如果要使用强制类型转换,请大家先去网上科普一下相关知识,熟悉了之后再使用。
四、总结
本文是我在阅读了《C++ Primer Plus》第三章之后,对其知识点进行总结最后结合我的个人理解书写而成。本文简单的介绍了一下C++基本内置类型——整型和浮点类型。浅谈了一下类型的由来,内存中的存储方式,使用过程中的注意事项,一些简单的运算操作和差异。本文的目的是想通过语言和图像的结合让初学者大致明白其中的原理,能正确使用这两种基本类型。
最后感谢每一位阅读过本文的读者,也感谢为我点赞、收藏、关注的朋友们。相信大家读完都有一个疑问,bool和char类型去哪了?其实,刚开始写的这篇博客的时候,我是先画上面那个读前总览图的时候忘记把这两个加上去了,然后想着后面再补。等后面我写到一半的时候,我想着一个布尔类型和一个字符类型,关我整型和浮点型什么事,于是我就不想写了。(主要还是作者太懒了,后面有空会补上的)这篇文章花了我很长时间进行创作,希望能对大家有所帮助,如果有写的不对的地方,请大家指出来,发表在评论或者私信我,作者会及时更正,谢谢!















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









