







大家网上冲浪多年,想必遇到过如下情况:
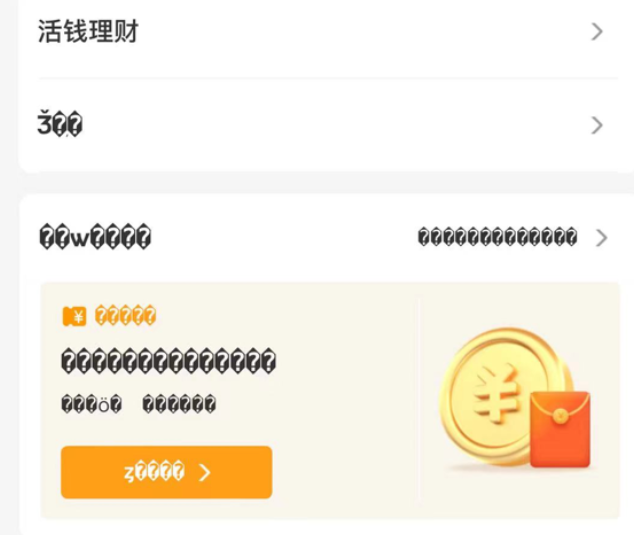
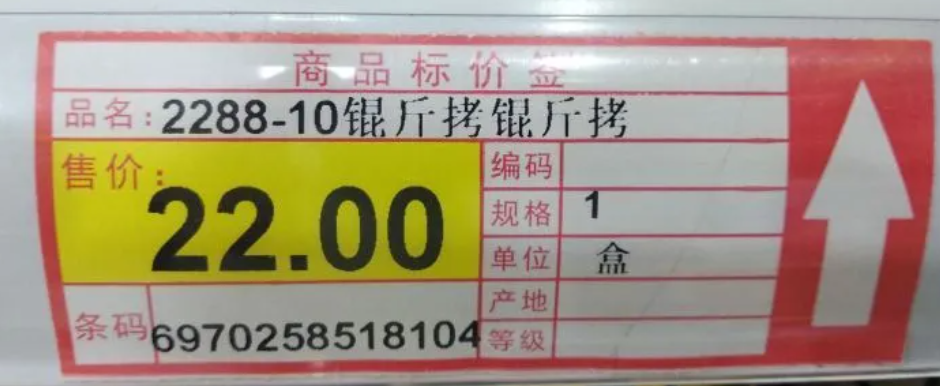

每当遇到这些情况,心里通常会暗骂一句:这是哪个小(da)可(sha)爱(bi)写的代码,怎么乱码了?
今天就来跟大家讨论一下,字符串的编码问题,希望能帮助大家以后告别"锟斤拷"。
中文乱码现象
中文乱码是指在文字处理、传输或显示过程中出现的乱码现象,使得原本应该显示的中文字符变成了不可理解的乱码或者乱码符号。
著名的"锟斤拷"就是中文乱码的绝佳代言人。
这里给出一张"乱码速查表",帮助大家快速定位问题。
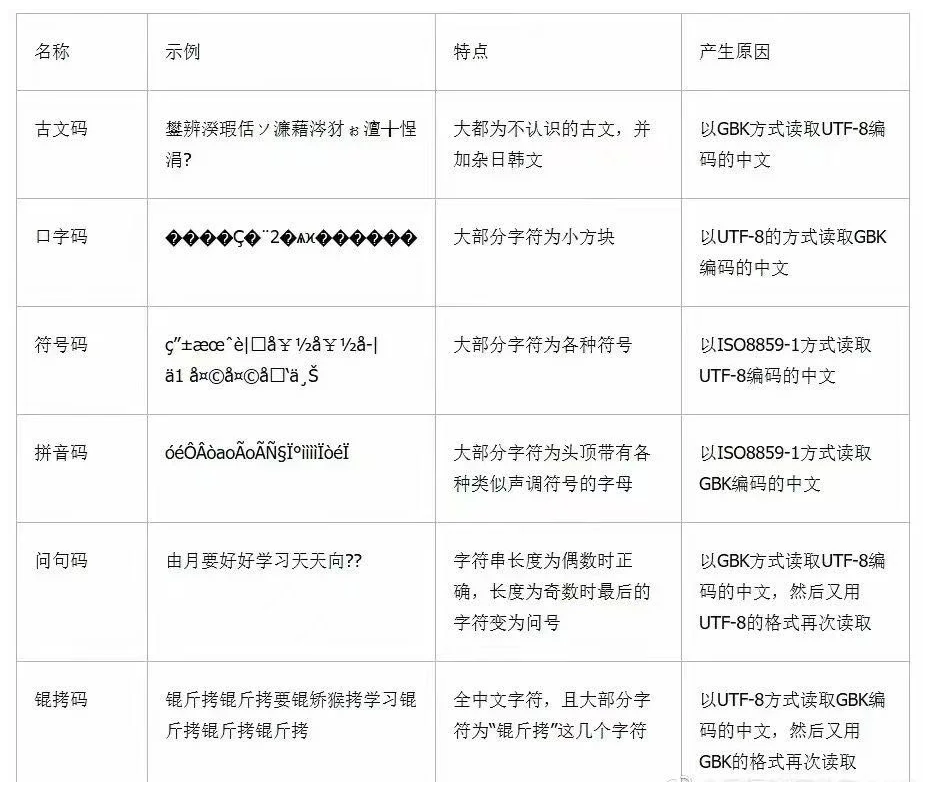
如果你对上面提到的GBK、UTF-8等概念不熟悉?没关系,接着往下看!
字符集和字符编码
我们都知道,对于计算机而言,它只认识0和1,所有的信息最终存储下来都是二进制数。而字符编码(Character Encoding)就是一种规则,它能够将字符(如字母、数字、标点符号等)映射到计算机中的二进制数据。
将字符映射到二进制数据的过程叫做编码,那么将二进制数据映射到字符就叫做解码。
为了能表示字符,我们就需要一个能描述某个字符范围的编码规则,这就是字符集的概念。
搞懂了字符编码和字符集的概念,我们来看个例子。
例:我自定义了一个叫做 IQ50 的字符集,它包含的字符范围和编码规则如下:
- 包含字符’a’、‘b’、‘C’、‘D’。
- 编码规则为:用一个字节(8bit)编码一个字符。映射关系如下:
- ‘a’ —> 0000 0001 十六进制:0x01
- ‘b’ —> 0000 0010 十六进制:0x02
- ‘C’ —> 0000 0011 十六进制:0x03
- ‘D’ —> 0000 0100 十六进制:0x04
有了这个 IQ50 字符集,我们就能够用二进制串来表示一些字符串了,比如说:
- ‘abb’ —> 00000001 00000010 00000010 十六进制:0x010202
- ‘DaC’ —> 00000100 00000001 00000011 十六进制:0x040103
- ‘bcde’:无法表示!因为IQ50字符集并不包含字符’c’、‘d’、‘e’。
例子举完了,当然在现实中,并没有这个叫做IQ50的字符集。那么接下来我们来看看一些常用的、比较重要的字符集:
ASCII字符集
ASCII(常读作:阿斯克)字符集共收录128个字符,包括空格、标点符号、数字、大小写字母和一些不可见字符。由于总共才128个字符,显然我们使用一个字节(8bit,28=256)就能进行编码了。
来看几个字符的编码方式:
| 字符 | 二进制编码 | 十进制 | 十六进制 |
|---|---|---|---|
| “A” | 0100 0001 | 65 | 0x41 |
| “a” | 0110 0001 | 97 | 0x61 |
| “0” | 0011 0000 | 48 | 0x30 |
总共才128个字符,对于英语使用国家来说可能够了,但是对于德语、西班牙语,特别是我们中文国家来说,那肯定是远远不能满足要求的。
ISO 8859-1字符集(别名Latin1)
ISO 8859-1字符集共256个字符,它在ASCII字符集的基础上又扩充了128个西欧常用字符(包括德、法两国的字母),所以ISO 8859-1是兼容ASCII字符集的。因为256个字符也能用一个字节表示,所以ISO 8859-1也是用一个字节编码的。
GB2312字符集
这个字符集是中国国家标准总局在1980年发布的编码,GB即"国标"的意思。
GB2312字符集收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母,收录汉字6763个(显然没有收录全),收录其它文字符号682个。这个字符集同时又兼容了ASCII字符集,所以在编码方式上有点奇怪,如果字符在ASCII字符集中,就用一字节编码,否则采用两字节编码。
这种使用不同字节数表示一个字符的编码方式称为变长编码方式。比如字符串"爱a",其中"爱"需要用2字节进行编码,编码的十六进制表示为0xB0AE,而"a"只要用1字节编码,十六进制表示为0x61,拼接起来"爱a"在GB2312字符集上的十六进制表示就是:0xB0AE61。
这里或许有同学会有疑问,计算机是怎么区分什么时候读一个字节,什么时候读两个字节呢?
很简单,因为ASCII只有128个字符,使用0-127就可以全部表示,那么如果某个字节是在0-127之间(字节的最高位为0),就意味着这是一个字节代表一个字符的,否则(字节最高位为1)就是两个字节代表一个字符的。
GBK字符集
GB2312字符集能基本满足汉字的计算机处理需求。但是对于人名、古汉语等出现的罕用字和繁体字,并没有收录到,于是就有了GBK字符集(这里的K可以看做"扩展"的意思)。
GBK字符集只是在收录的字符范围上对GB2312字符集进行了扩容。GBK字符集的编码方式兼容了GB2312字符集。
Unicode标准
我们不免会有这么一个想法:存在这么多的编码方式,同一串二进制能被解释为不同的符号,如果有一种编码,能将世界上所有的符号都纳入其中,给每一个符号一个独一无二的编码,乱码问题就能彻底消失。
于是就出现了Unicode,中文译做万国码、国际码。Unicode几乎收录了当今世界各个国家/地区使用的字符,而且还在不断增修。最新版是2020年3月的v13.0,收录了13万个字符。
具体的符号对应表可以查询官网:http://www.unicode.org
注意:我们这节的标题用的是Unicode标准。这也是我们需要强调的:Unicode只是一个用来映射字符和二进制数字的标准。它并没有指定需要用几个字节去编码一个字符,可以是一个两个或三个,甚至是无穷大(虽然肯定没人会这么做,太浪费空间了)。
UTF-8 / UTF-16 / UTF-32字符集
Unicode标准虽然统一了全世界字符的编码,但并没有规定如何存储。如果每个字符统一规定用几个字节存储的话,那么至少要用3个字节,因为两个字节(216 = 65536,上面我们说过Unicode收录了13万)肯定不够的。
那么由谁来规定呢?
UTF(Unicode Transformation Formats,Unicode的编码方式)来了。比较常见的UTF就是UTF-8、UTF-16和UTF-32。
其中UTF-8我们日常接触的比较多,会详细介绍一下。
UTF-8采用了变长编码,用1-4个字节去编码一个字符。对于0-127号字符,使用和ASCII相同的编码,只用一个字节表示。其它字符则可能用2、3或4个字节表示。
那么针对UTF-8的变长编码,计算机怎么知道什么时候读1个,什么时候读2、3或4个字节呢?
有这样的规则:如果只有一个字节,那么最高的比特位为0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为1,就用几个字节编码,剩下的字节均以10开头。
来看例子:
- 0xxxxxxxx:一个字节;
- 110xxxxx 10xxxxxx:两个字节(开始两个1);
- 1110xxxx 10xxxxxx 10xxxxxx:三个字节(开始三个1);
- 1111xxxx 10xxxxxx 10xxxxxx 10xxxxxx:四个字节(开始四个1);
对于常用的汉字,UTF-8使用三个字(224=16777216)节来编码,但实际上用不了这么多,所以不可避免会造成一些资源浪费。
对于UTF-16,它是使用2或4字节来编码一个字符。
对于UTF-32,它是固定使用4字节来编码一个字符。
模拟中文乱码(java)
首先我们再搬出这张图:
接下来我们来看demo:
@Test
public void test001(){
String originalStr = "你好世界";
String encodedStr = "";
// 将“你好世界”通过GBK编码转换为对应的字节数组
byte[] bytes = originalStr.getBytes(Charset.forName("GBK"));
// 用UTF-8编码方式解析字节数组,会导致乱码
encodedStr = new String(bytes,Charset.forName("UTF-8"));
System.out.println(originalStr);
System.out.println(encodedStr);
}
output:
你好世界
�������
出现乱码了,在Unicode中,�是一个特殊的符号,表示"无法显示",它的十六进制是0xEFBFBD。两个�就是0xEFBFBD EFBFBD。对两个�用GBK解码,就是大名鼎鼎的"锟斤拷"。验证一下:
@Test
public void test002(){
// UTF-8编码读取GBK编码的中文会得到"��"
// 这里将"��"转换为十六进制字符数组
char[] kunJinKao = HexUtil.encodeHex("��", StandardCharsets.UTF_8);
System.out.println(kunJinKao);
// 将十六进制字符数组解码为字节数组
byte[] bytes = HexUtil.decodeHex(kunJinKao);
// 将字节数组按照GBK编码方式解析为字符串
String result = new String(bytes, Charset.forName("GBK"));
System.out.println(result);
}
output:
efbfbdefbfbd
锟斤拷
所以以后出现了"锟斤拷",第一时间想到GBK和UTF-8的转换问题准没错。
如何避免乱码
下面是一些避免乱码的实践:
- 使用统一的字符编码,如 UTF-8。它包含了所有 Unicode 字符,并且广泛支持。确保在所有平台和系统上使用相同的编码。
- 在处理文本文件时,始终明确指定字符编码。例如,在 Java 中使用 InputStreamReader、OutputStreamWriter 时,指定编码参数。
- 在 HTML、XML 等文档中,指定字符编码。例如,在 HTML 页面中添加 。
- 对于数据库,确保使用正确的字符集。在创建数据库和表时,明确指定字符集,如 utf8mb4。
需要注意的是,在MySQL中,utf8是utf8mb3的别名,utf8mb3是MySQL为了提高性能,所"阉割"过的字符集,只使用1~3个字节表示一个字符。
所以推荐在MySQL中指定的字符集是utf8mb4,这也是最正宗完整的UTF-8字符集,使用1-4个字节表示一个字符。utf8mb4也是MySQL默认的字符集。连emoji都能存!
好了,本篇博客到此结束,希望对于大家了解字符串编码有所帮助,在面对"锟斤拷"时不再手足无措。















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









