




SCAFFOLD:2020 克服client-drift
论文:《SCAFFOLD: Stochastic Controlled Averaging for Federated Learning》
引用量:2284
源码地址:https://github.com/rruisong/pytorch_federated_learning
针对的问题:
对Federated Learning而言,一个重大的挑战就是数据的Non-IID,它也有个听上去高端的名字:异构性Heterogeneity。
本文作者就是想要解决由数据Non-IID而引发的client-drift(客户端漂移)。这是个作者提出的概念,下面给出对这个概念的解释:我们都知道模型的参数可以看成是参数空间的一个点,模型训练就是想要把这个点根据梯度慢慢移动到低的地方。但是在FL中,各模型的训练分散在各client中,每个client的参数都会根据模型在自己本地数据集上的训练情况往某个方向移动,显然在数据Non-IID时,这些client的参数的移动方向是不一致的(这就是client-drift),这就导致了在模型合并(合并的过程就是简单的平均)之后要么抵消,要么偏移,因此收敛到最低点的速度就慢了。
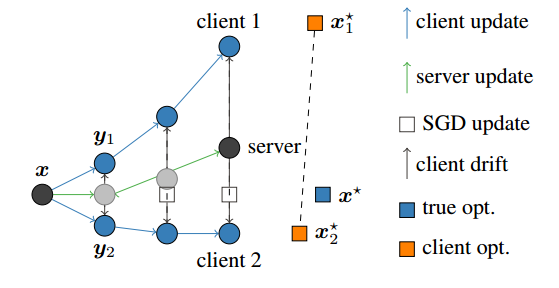
如下图所示,在FedAvg中,两个client由于数据Non-IID,往不同方向移动,即使server将它们聚合之后,也不在最优解的位置
x
∗
x^*
x∗处。
论文贡献:
为了缓解client-drift,作者提出了一种新的联邦优化算法SCAFFOLD,引入了一个额外的参数“控制变量c”(control variate),该控制变量中含有模型的更新方向信息,用于克服梯度差异,从而修正client-drift。
算法介绍:
SCAFFOLD在FedAvg的基础上,为全局的server和每个client设置了控制变量,分别是
c
c
c和
c
i
c_i
ci。这两者存在如下关系:
c
=
1
N
∑
c
i
c=\frac{1}{N}\sum c_i
c=N1∑ci
即server的控制变量是所有client控制变量的平均值,所有的控制变量都要初始化,最简单的情况就是初始化为0。

解读一下上面的算法流程:
- 在每一轮通信中,随机从 N N N个client中选出部分,记为集合 S S S,然后server将参数 ( x , c ) (x,c) (x,c)(全局模型参数+全局控制变量)发给集合中的各client。
- 各client初始化本地模型为 y i ← x y_i\leftarrow x yi←x,然后进行 K K K次本地更新(其中 g i ( y i ) g_i(y_i) gi(yi)为计算得到的梯度):
y
i
←
y
i
−
η
l
(
g
i
(
y
i
)
+
c
−
c
i
)
y_i\leftarrow y_i-\eta_l(g_i(y_i)+c-c_i)
yi←yi−ηl(gi(yi)+c−ci)
在
K
K
K次本地更新完毕后,局部控制变量
c
i
c_i
ci也要更新,作者提供了两种更新选择:
C
i
+
←
{
Option I.
g
i
(
x
)
,
or
Option II.
c
i
−
c
+
1
K
η
l
(
x
−
y
i
)
C_i^+\leftarrow\begin{cases}\text{Option I.}&g_i(x),\text{or}\\\text{Option II.}&c_i-c+\frac{1}{K\eta_l}(x-y_i)\end{cases}
Ci+←{Option I.Option II.gi(x),orci−c+Kηl1(x−yi)
其中选项一可能比选项二更加稳定,但选项二的计算成本更低,而且通常够用(论文中所有实验都用的选项二)。
然后将模型的增量
Δ
y
i
=
y
i
−
x
\Delta y_i=y_i-x
Δyi=yi−x以及控制变量的增量
Δ
c
i
=
c
i
+
−
c
i
\Delta c_i=c_i^+-c_i
Δci=ci+−ci发送给server。
并将局部控制变量更新:
c
i
←
c
i
+
c_i\leftarrow c_i^+
ci←ci+。
- server收到各client的结果后进行聚合(这里采用的是增量聚合):
x
←
x
+
η
g
∣
S
∣
∑
i
∈
S
Δ
y
i
x\leftarrow x+\frac{\eta_g}{|S|}\sum_{i\in S}\Delta y_i
x←x+∣S∣ηg∑i∈SΔyi
c
←
c
+
1
N
∑
i
∈
S
Δ
c
i
c\leftarrow c+\frac{1}{N}\sum_{i\in S}\Delta c_i
c←c+N1∑i∈SΔci
当然这里也可以不用增量聚合,直接去聚合更新后的模型也行(相比于增量聚合,通信成本显然会高点,但本篇论文关注点不在通信成本上,且我们跑实验是在本地,所以直接聚合更新后的模型写代码好写一点):
x
←
η
g
∣
S
∣
∑
i
∈
S
y
i
c
←
1
N
∑
i
∈
S
c
i
+
x\leftarrow \frac{\eta_g}{|S|}\sum_{i\in S}y_i\\c\leftarrow \frac{1}{N}\sum_{i\in S}c_i^+
x←∣S∣ηg∑i∈Syic←N1∑i∈Sci+
算法流程介绍完毕了。我们观察step 2中的本地模型更新公式,如果局部控制变量
c
i
c_i
ci总是为0,那么SCAFFOLD会退化为FedAvg。
算法有效性分析:
为什么SCAFFOLD只是在FedAvg的基础上加一个修正项
c
−
c
i
c-c_i
c−ci,就可以有效缓解各client的client-drift呢?
我们都知道,如果通信成本不成问题,最理想情况下对于第 i 个client的更新机制为:
y
i
←
y
i
+
1
N
∑
j
g
j
(
y
i
)
y_i\leftarrow y_i+\frac{1}{N}\sum_j g_j(y_i)
yi←yi+N1∑jgj(yi)
解释一下上面的公式,就是说让第 i 个client的模型
y
i
y_i
yi能够access到其他所有client的数据,这时候相当于把所有的数据都收集起来训练,是IID的,但这显然是不现实的。
在这个时候作者引入了控制变量来曲线救国,还记得上面伪代码中本地模型的更新公式为:
y
i
←
y
i
−
η
l
(
g
i
(
y
i
)
+
c
−
c
i
)
y_i\leftarrow y_i-\eta_l(g_i(y_i)+c-c_i)
yi←yi−ηl(gi(yi)+c−ci)
而又有:
c
i
=
g
i
(
x
)
→
c
i
≈
g
i
(
y
i
)
c
≈
1
N
∑
j
g
j
(
y
i
)
c_i=g_i(x)\rightarrow c_i\approx g_i(y_i)\\c\approx\frac{1}{N}\sum_j g_j(y_i)
ci=gi(x)→ci≈gi(yi)c≈N1∑jgj(yi)
带入本地模型更新公式之后就能发现,此时本地模型更新公式就约等于理想情况下的更新机制了。
简单来说就是,局部控制变量中含有client模型的更新方向的信息,而全局控制变量中含有其他所有client的模型更新方向信息。在本地模型更新时加上一个修正项
c
−
c
i
c-c_i
c−ci,可以理解为全局模型相对于本地模型的client-drift值,也就是说我们在本地模型更新时就考虑到了这个差异,这有助于消除client-drift。
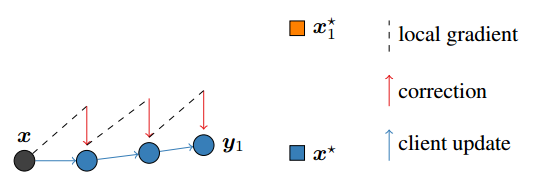
如下图所示,对于单个client,如果用传统的FedAvg,最优解会向
x
1
∗
x_1^*
x1∗移动,但是在加入修正项后,会对模型的更新方向产生一个修正,使其向真正的最优解
x
∗
x^*
x∗移动。
实验:
模拟数据集上的实验结果:
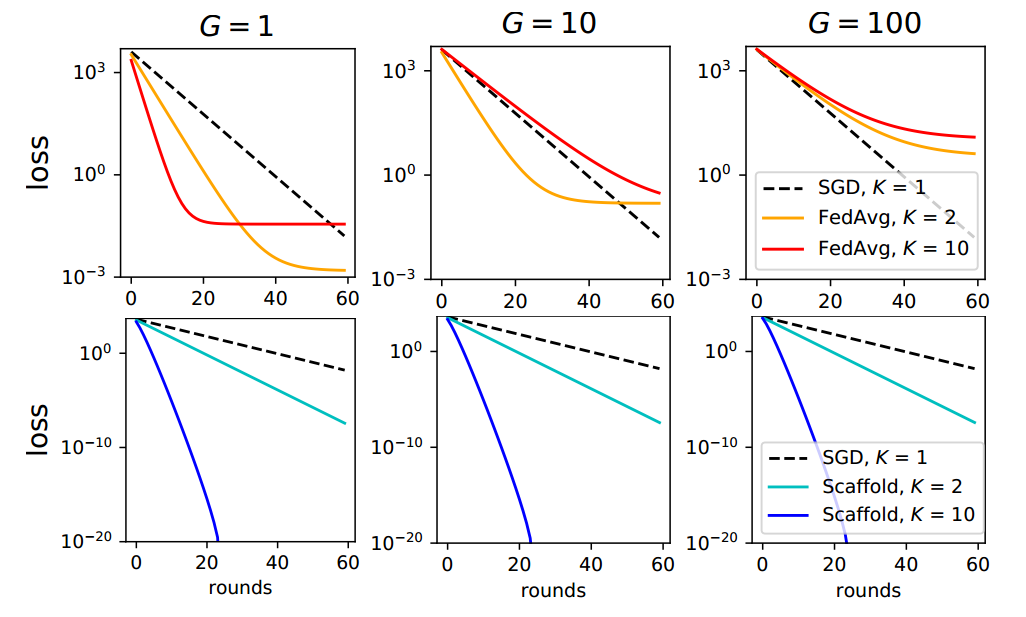
上图中G表示的是数据的异构程度,K表示的每个client局部更新次数epoch。注意上下两行loss的数量级不同。
竖着看我们得出结论:当数据Non-IID时,局部更新次数epoch增加,收敛会变慢,这是因为client-drift随着epoch增加而增加了。
横着看可知:数据Non-IID程度越大,FedAvg效果越差。
根据第二行可知,SCAFFOLD始终是收敛最快的,而且收敛性不受Non-IID程度影响。
EMNIST数据集上的结果:

上表展示了在不同本地更新次数epoch下,达到逻辑回归的0.5acc所需要的通信次数。
可知SCAFFOLD在其中表现最好。且当数据相似度为0%(即完全Non-IID)时,FedAvg随着epoch增加效果越差,其余情况下,SCAFFOLD和FedAvg都始终优于SGD。
不过这里FedProx的实验结果有点幽默了,始终最差。
总结:
优点:为了克服client-drift的影响,SCAFFOLD引入了控制变量,在本地模型更新时加入修正项,实验证明是有效的。
缺点:
- 要求每个client能保存自己的控制变量,在实际系统中是有难度的,比如对手机设备而言,即使没有参与训练也要为下一轮做准备。
- 通信中除了传递模型参数,还要额外传递控制变量(这个变量的维度和梯度一样),相当于通信代价double了。


















 5730
5730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









