






一、聚合函数
Mysql中内置了 5 种聚合函数,分别是:sum 、 max 、 min 、 avg 、 count 。
1.sum : 求和
select sum(列) from table_name [其他子句];
2.max : 求最大值
select max(列) from table_name [其他子句];
3.min : 求最小值
select min(列) from table_name [其他子句];
4.avg : 求平均值
select avg(列) from table_name [其他子句];
5.count : 求数量
select count(列) from table_name [其他子句];
二、高级查询
1.distinct
在 select 语句中,可以使用 distinct 关键字对查询的结果集进行去重。去重必须结果集
中每个列的值都相同。
2.order by
order by 用于对结果进行排序显示,可以使用 ASC / DESC 两种方式进行排序,可以有多
个排序条件
ASC :表示升序排序,如果不写即为此排序方式
DESC :表示降序排序
3.分页查询limit子句
第一个参数0是表示从第几条开始查询 (这里的 0 是可以省略不写的);
第二个参数 表示查询出几条数据
后面不够的,有多少写多少;
4.group by
select count(列) from table_name [其他子句];group by 是对数据进行分组,分组时,表中有相同值的分为一组。分组后可以进行聚合查询。
select 列1, 列2, (聚合函数) from table_name group by 列1, 列2;
group by 分组后的查询中, select 的列不能出现除了 group by 分组条件以及聚合函数
外的其他列。
5.having
having 是对 group by 分组后的结果集进行筛选。
select 列1, 列2, (聚合函数) from table_name group by 列1, 列2 having 分组后条件;
6.综合查询
SELECT DISTINCT emp.deptno FROM emp JOIN dept ON emp.deptno = dept.deptno WHERE bridate >= '2000-01-01' GROUP BY emp.deptno HAVING count(*) >= 2 ORDER BY count(*) DESC LIMIT 0, 5;
书写顺序是以上。
SQL 语句的执行顺序
from --> on --> join --> where --> group by --> having --> select --> distinct-- > order by--> limit
sql语句定义和执行顺序
三、多表连接
笛卡尔乘积现象
表查询中的笛卡尔乘积现象:多行表在查询时,如果定义了无效连接或者漏写了连接条
件,就会产生笛卡尔乘积现象,所谓的笛卡尔乘积即是每个表的每一行都和其他表的每一
行组合。
SELECT * FROM emp,dept;
1.等值连接查询
通常是在存在主键外键关联关系的表之间的连接进行,使用"="连接相关的表
n个表进行等值连接查询,最少需要n-1个等值条件来约束
--查询每个部门的所有员工
select dept.dname,emp.ename from emp,dept where dept.deptno = emp.deptno;
2.自连接查询
表表查询不仅可以在多个表之间进行查询,也可以在一个表之中进行多表查询
--查询当前公司员工和所属上级员工的信息
select e1.empno as 员工编号,e1.ename as 员工姓名,e2.empno as 领导编号,e2.ename as 领导姓名 from emp as e1,emp as e2 where e1.mgr = e2.empNo;
3.内连接查询(和等值查询差不多)
内连接查询使用 inner join 关键字实现, inner 可以省略。内连接查询时,条件用 on
连接,多个条件使用 () 将其括起来.
--查询每个部门的所有员工
select dept.name,emp.name from emp inner join dept on emp.deptno = dept.deptno;
4.外连接
外连接分为左外连接( left outer join ) 和右外连接( right outer join )其值 oute
r 可以省略。外连接查询时,条件用 on 连接,多个条件使用 () 将其括起来.
左外连接表示以左表为主表,右外连接表示以右表为主表。查询时将主表信息在从表中进
行匹配
--查询每个部门的所有员工 select dept.name,emp.name from emp right join dept on emp.deptno = dept.deptno; select dept.name,emp.name from dept left join emp on emp.deptno = dept.deptno;
四、子查询
存在于另外一个SQL语句中、被小括号包起来的查询语句就是子查询。相对于子查询来
说,在外部直接执行的查询语句被称作主查询
子查询分为:
-
单列子查询: 返回单行单列数据的子查询
-
单行子查询: 返回单行多列数据的子查询
-
多行子查询: 返回数据是多行单列的数据
-
关联子查询: 子查询中如果使用了外部主SQL中的表或列,就说这个子查询跟外部SQL是
相关的
1.单行子查询
--查询软件部门下的所有员工 select * from emp e where e.deptno = (select d.deptno from dept d where d.dname = '软件部' );
2.多行子查询
如果子查询返回了多行记录,则称这样的嵌套查询为多行子查询,多行子查询就需要用到
多行记录的操作符。如: in , all , any(some)
-
in 子查询中所有的记录
-
>any 表示大于子查询中的任意一个值,即大于最小值
-
>all 表示大于子查询中的所有值,即大于最大的值
--统计所有的员工分布在哪些部门的信息 select * from dept d where d.deptno in (select e.deptno from emp e);
--查询公司中比任意一个员工的工资高的所有员工 select * from emp e1 where e1.sal > any (select e1.sal from emp e2);
--查询公司中比所有的助理工资高但不是助理的员工 select * from emp e1 where e1.sal > all(select e2.sal from e2.emp where w2.joblike '%助理');
3.多列子查询
--查询公司中和员工***相同薪水和奖金的员工 select * from emp e1 where (e1.sal,e1.comm) = (select e2.sal,e2.comm from emp e2 where e2.ename = '张青');
五、单行函数
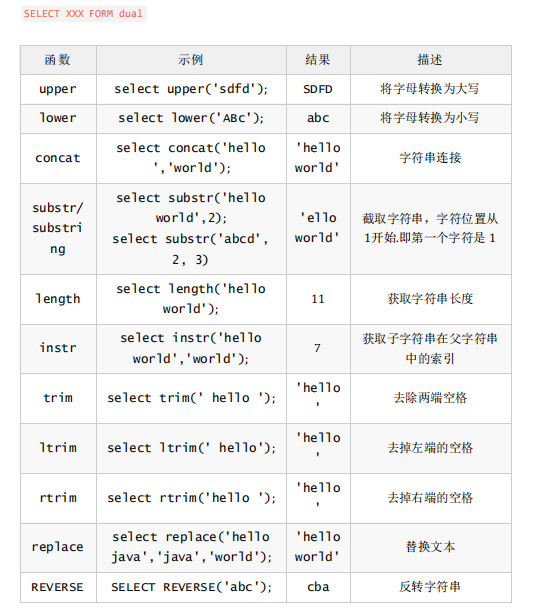
1.字符串函数
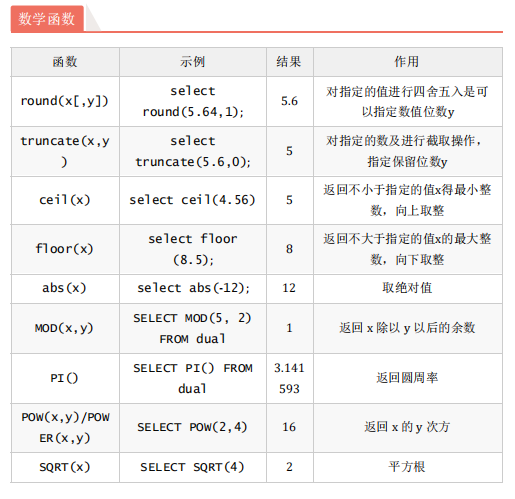
2.数学函数
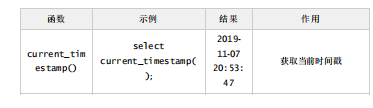
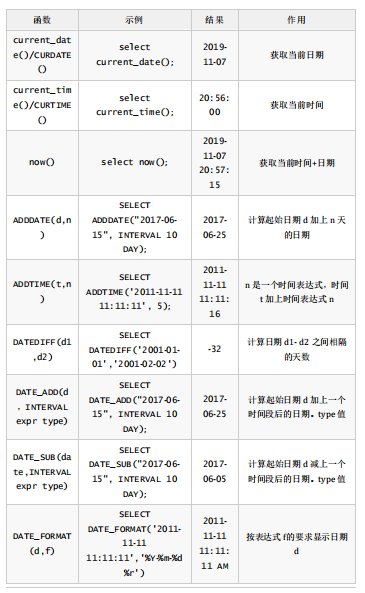
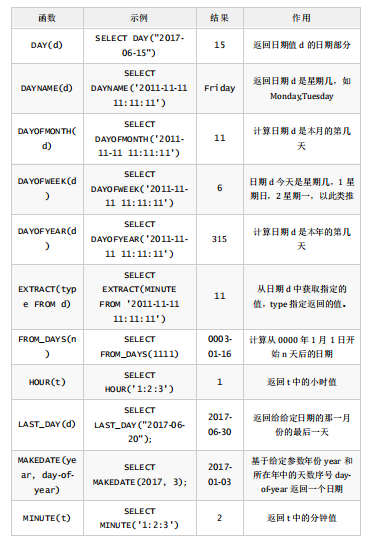
3.日期函数
六、设计数据库步骤
1.软件开发的步骤大致上可以分为:
需求分析,概要设计,详细设计,代码编写,运行测试,部署发行
数据库是在代码编写前完成的
2.数据库设计可分为这几个过程
需求分析,概念模型,逻辑模型,物理模型,运行验
七、数据库设计范式
数据库的设计有五大设计范式。常用的有三大设计范式,称之为第一范式( 1NF ),第二范
式( 2NF ),第三范式( 3NF ),他们是逐步为严格的,满足第二范式,就必须满足先满足第
一范式。满足第三范式时就必须首先满足第二范式第一范式(1NF)
1.第一范式
第一范式要求单个表中每个列必须是原子列(即每一个列都是不可再分的最小数据单
元),列不存在重复属性,每个实体的属性也不存在多个数据项。
1.原子列
2.不出现重复属性
3.不允许出现多个数据项
2.第二范式
第二范式是在满足第一范式的基础之上,要求数据表里的所有数据都要和该数据表的主键
有完全依赖关系。
3.第三范式
第三范式是在满足第二范式的基础之上,每一个非主键列都直接依赖主键列,不依赖其他
非主键列,即数据库中不能存在传递函数的依赖关系。
4.范式的优缺点
优点:
1). 范式化的数据库更新起来更加的快;
2). 范式化之后只有很少的重复数据,只需要修改更少的数据;
3). 范式化的表更小,可以在内存中直接执行;
4). 很少的冗余数据,在查询时候需要更少的distinct后者group by语句。
缺点:
1). 范式化的设计会产生更多的表;
2). 在查询的时候经常需要很多的表连接查询,到值查询性能降低;














 5645
5645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









