






摘要:土壤深度是生态水文模拟、碳储量计算和土地评价的重要依据。然而,人们对其空间变异了解甚少,也很少对其进行制图。在样本数有限的情况下,如何预测大面积复杂景观的土壤深度仍然是一个难题。本研究构建了一个集成机器学习模型,即分位数回归森林,以量化土壤深度与环境条件之间的关系。
关键词:数字土壤制图、空间变异、不确定性、机器学习、土壤-景观模型、土壤深度
研究区:黑河流域位于中国西北干旱区
算法:基于土壤调查样本构建了分位数回归森林模型来量化土壤深度与环境协变量之间的关系。发展了分位数回归森林算法:随机森林的不同之处在于,对于每棵树中的每个节点,它保留了该节点中所有样本的值,可以给出响应变量的全部条件分布,而随机森林只保留了该节点中样本的均值,忽略了其他所有信息。因此,它不仅可以进行预测,而且可以同时估计预测的不确定性。这种独特的优势是目前其他机器学习算法所不具备的。这种直接的不确定性估计方法被证明在样本数非常有限的( Vaysse和Lagacherie 2017)时比回归克里金方法更准确。
模型校准考虑了3个模型参数:
mtry:每次分裂时尝试的环境协变量的个数
nodeize:尝试分裂的最小节点大小
ntree:为用于形成森林的树的个数。 ntree被设置为其默认值500
像元位置的90 %预测区间为0.05和0.95分位数预测的差值。
不确定指标:通过计算预测区间与中位数的比值,推导出预测不确定度指标
变量重要性:均方误差的增加量( % IncMSE )来衡量相对重要性% IncMSE越大,协变量的重要性越大。
评价标准:10-fold cross validation method
4个测量值:决定系数( R2 )、一致相关系数( CCC )。林毅夫1989)、均方根误差( RMSE )和平均误差( ME )
模型预测性能:模型参数的调优过程显示了交叉验证R2和RMSE值随随机选择的协变量数量(即mtry )和最小节点大小(即nodesize )的变化
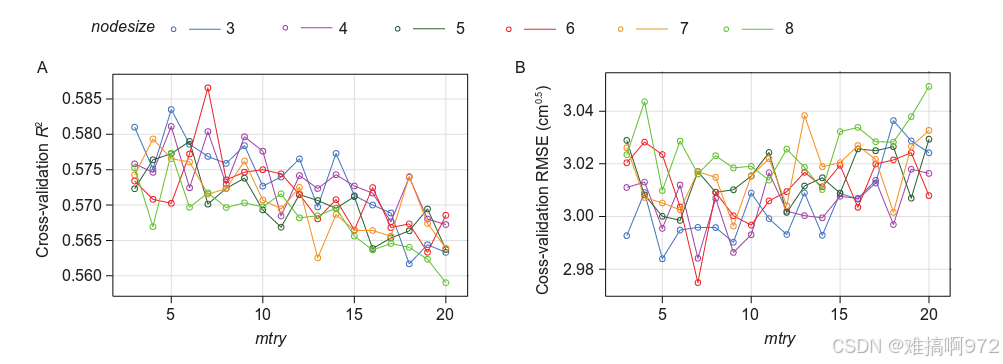
当mtry和nodeize分别为7和6时,获得最大的R2和最小的RMSE值。
在最优模型结构下,10折交叉验证显示R2为0.587,RMSE为2.98 cm ( sqrt scale ),表明模型解释百分之60的土壤深度变化。CCC为0.686,相对较高,表明预测的土壤深度值与观测值之间具有较好的一致性。
此外,得到的PICP值为88 %,非常接近90 %,表明所构建模型估计的预测下限和预测上限具有合适的数量级。也就是说,不确定性估计在很大程度上是可靠的。
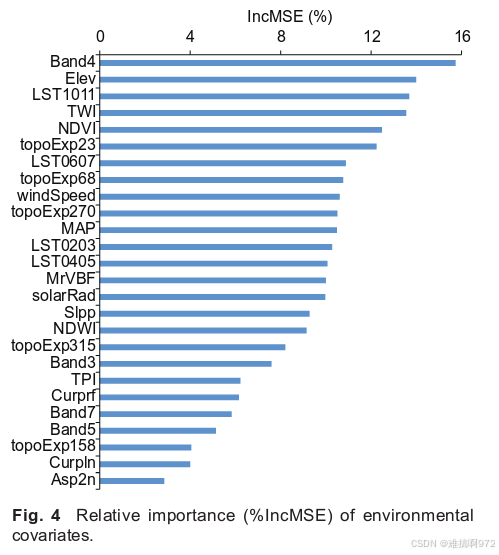
环境协变量的相对重要性:
对土壤深度预测最重要的协变量是Band4、Elev、LST1011、TWI、NDVI和topoExp23 。其中,Band4和NDVI代表植被状况,反映了植被覆盖度的空间差异
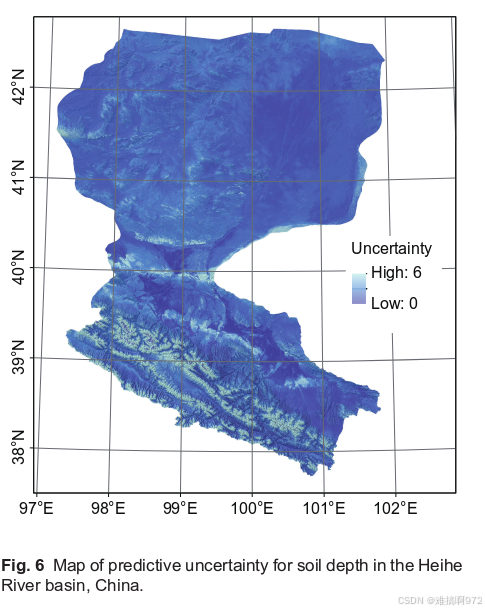
预测的土壤深度分布及其空间不确定性:
下图展示了土壤深度预测不确定性的空间分布。高不确定性(灰白色)主要出现在上游山区的山坡和山脊位置,中游绿洲外围的半荒漠,下游的低山丘陵和台地。这些地区可进入性差,土壤调查点稀疏或缺失。相比之下,低不确定性(深蓝色)出现在宽阔的河谷、绿洲和较低的冲积平原,那里有良好的可达性,有较高密度的土壤调查点。利用空间不确定性信息,可以将预测的土壤深度图以置信的方式传递给最终用户,供其决策使用。
局限性:
流域上游的高山和中下游的戈壁荒漠,加之可进入性差,导致很多局部区域样本缺失。这些地区如此稀疏的土壤深度采样,可能在一定程度上导致该流域超过40 %的土壤深度空间变异无法解释。为了进一步完善土壤深度图,需要在预测不确定性较高的区域进行补充土壤调查。
当前的机器学习是数据驱动的。对土壤深度的预测依赖于其学习到的样本,这可能导致不切实际的预测,特别是对于没有样本的地区。为了克服这个缺点,进一步的研究可以尝试将来自土壤调查人员的知识引入到机器学习过程中,以约束依赖于数据的预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









