







论文原文:
在公司融资和资产定价的实证工作中,研究人员经常使用面板数据。在这些数据集中,残差可能在不同公司或不同时间之间存在相关性,OLS (普通最小二乘) 标准误可能存在偏差。本文研究了文献中应对的不同方法,说明为什么不同的方法有时会给出 (相同) 不同的答案,并为研究者提供使用指导。
众所周知,当残差独立同分布时,OLS标准误是无偏的。当残差在各观测值之间存在相关性时, OLS标准误可能存在偏差。虽然面板数据集的使用在金融学中很常见,但研究者们解决标准误可能出现的偏差的方法差异很大,在很多情况下是不正确的。
有两种一般形式的非独立性在金融学中最为常见。某一公司的残差可能与某一公司的年份相关 (时间序列非独立性),本文将其称为未观察到的公司效应。另外,给定年份的残差可能会在不同的企业之间产生关联 (截面非独立性),本文将其称之为时间效应。
1估计存在企业固定效应的标准误
1.1 聚类标淮误估计
标准面板回归模型是:
$$
Y_{i t}=X_{i t} \dot{\beta}+\varepsilon_{i t},
$$
其中, $i$ 为企业, $t$ 为时间。 $X_{i t}$ 是解释变量,并与 $\varepsilon_{i t}$ 相互独立,二者均零均值,有限方差。 OLS估计系数和渐进方差为:
$$
\begin{aligned}
\hat{\beta}_{O L S} & =\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t} Y_{i t}}{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}=\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t}\left(X_{i t} \beta+\varepsilon_{i t}\right)}{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2} \\
& =\beta+\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t} \varepsilon_{i t}}{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}
\end{aligned}
$$
$$
\begin{aligned}
A \operatorname{Var}\left[\hat{\beta}_{O L S}-\beta\right] & =\operatorname{plim}_{\substack{N \rightarrow \infty \\
T \text { fixed }}}\left[\frac{1}{N^2}\left(\sum_{i=1}^N \sum_{t=1}^T X_{i t} \varepsilon_{i t}\right)^2\left(\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}{N}\right)^{-2}\right] \\
& =\operatorname{plim}_{\substack{N \rightarrow \infty \\
T \text { fixed }}}\left[\frac{1}{N^2}\left(\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2 \varepsilon_{i t}^2\right)\left(\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}{N}\right)^{-2}\right] \\
& =\frac{1}{N}\left(T \sigma_X^2 \sigma_{\varepsilon}^2\right)\left(T \sigma_X^2\right)^{-2} \\
& =\frac{\sigma_{\varepsilon}^2}{\sigma_X^2 N T} .
\end{aligned}
$$
这是标准的OLS估计,但面板数据经常难以满足独立性假设。本文最初假设具有一个固定的未观察到的企业效应,因此残差由一个企业特有的成分 $\left(\gamma_i\right)$ 和一个对每个观测值都是唯一的特异性成分 $\left(\eta_{i t}\right)$ 组成。残差可以指定为:
$$
\varepsilon_{i t}=\gamma_i+\eta_{i t}
$$
同样假设解释变量 $X$ 也有企业效应:
$$
X_{i t}=\mu_i+v_{i t}
$$
$X(\mu$ 和 $v)$ 和 $\varepsilon(\gamma$ 和 $\eta)$ 的成分均值为零,方差有限,且相互独立。这是系数估计量一致的必要条件。自变量和残差在同一公司的不同观测值之间都是相关的,但在不同公司之间是独立的。
$$
\begin{aligned}
\operatorname{corr}\left(X_{i t}, X_{j s}\right) & =1 \quad \text { for } i=j \text { and } t=s \\
& =\rho_X=\sigma_\mu^2 / \sigma_X^2 \text { for } i=j \text { and all } t \neq s \\
& =0 \quad \text { for all } i \neq j, \\
\operatorname{corr}\left(\varepsilon_{i t}, \varepsilon_{j s}\right) & =1 \text { for } i=j \text { and } t=s \\
& =\rho_{\varepsilon}=\sigma_\gamma^2 / \sigma_{\varepsilon}^2 \text { for } i=j \text { and all } t \neq s \\
& =0 \text { for all } i \neq j .
\end{aligned}
$$
鉴于这种数据结构 (公式 (1) 、(4) 和 (5)) ),可以确定OLS系数的真实标准误。由于残差在一个聚类内不再是独立的,所以残差和的平方不等于残差平方之和。OLS系数估计的渐进方差为:
$$
\begin{aligned}
& A \operatorname{Var}\left[\hat{\beta}_{O L S}-\beta\right]=\operatorname{plim}_{\substack{N \rightarrow \infty \\
T \text { fixed }}}\left[\frac{1}{N^2}\left(\sum_{i=1}^N \sum_{t=1}^T X_{i t} \varepsilon_{i t}\right)^2\left(\frac{\sum_{i-1}^N \sum_{t-1}^T X_{i t}^2}{N}\right)^{-2}\right] \\
&=\operatorname{plim}_{\substack{N \rightarrow \infty \\
T \text { fixed }}}\left[\frac{1}{N^2} \sum_{i=1}^N\left(\sum_{t=1}^T X_{i t} \varepsilon_{i t}\right)^2\left(\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}{N}\right)^{-2}\right] \\
&=\operatorname{plim}_{\substack{N \rightarrow \infty \\
T \text { fixed }}}\left[\frac{1}{N^2} \sum_{i=1}^N\left(\sum_{t=1}^T X_{i t}^2 \varepsilon_{i t}^2+2 \sum_{t=1}^{T-1} \sum_{s=t+1}^T X_{i t} X_{i s} \varepsilon_{i t} \varepsilon_{i s}\right)\right. \\
&\left.\times\left(\frac{\sum_{i=1}^N \sum_{t=1}^T X_{i t}^2}{N}\right)^{-2}\right] \\
&=\frac{1}{N}\left(T \sigma_X^2 \sigma_{\varepsilon}^2+T(T-1) \rho_X \sigma_X^2 \rho_e \sigma_e^2\right)\left(T \sigma_X^2\right)^{-2} \\
&=\frac{\sigma_{\varepsilon}^2}{\sigma_X^2 N T}\left(1+(T-1) \rho_X \rho_{\varepsilon}\right) .
\end{aligned}
$$
本文在推导第二个等式时使用了残差独立于企业的假设。在假设的数据结构下, $X$ 和 $\varepsilon$ 均组内正相关,并且等于方差中归属于企业效应的部分。当数据具有固定的企业效应时,且仅当 $\rho_X$ 和 $\rho_{\varepsilon}$均为非零时, OLS标准误将低估真实的标准误。误差的大小也是随着时间的增加而增加。直观理解,考虑自变量和残差在时间上完全相关的极端情况(即 $\rho_X=1, \rho_{\varepsilon}=1$ )。在这种情况下,每个额外的年份都不会提供额外的信息,也不会对真实的标准误产生影响。但是,OLS标准误将假设每增加一年提供 $N$ 个额外的观测值,估计的标准误将相应地缩小,而且不正确。
聚类内残差的相关性是聚类标准误所要纠正的问题。通过对每个聚类内的 $X_{i t} \varepsilon_{i t}$ 之和进行平方,就可以估计出聚类内残差之间的协方差 (图1)。这种相关性可以是任何形式的,不需假设参数结构。然而, $X_{i t} \varepsilon_{i t}$ 的平方和被假定为在各聚类中具有相同的分布。因此,随着聚类数量的增加,这些标准误是一致的。
1.2通过模拟检验标准误估计值
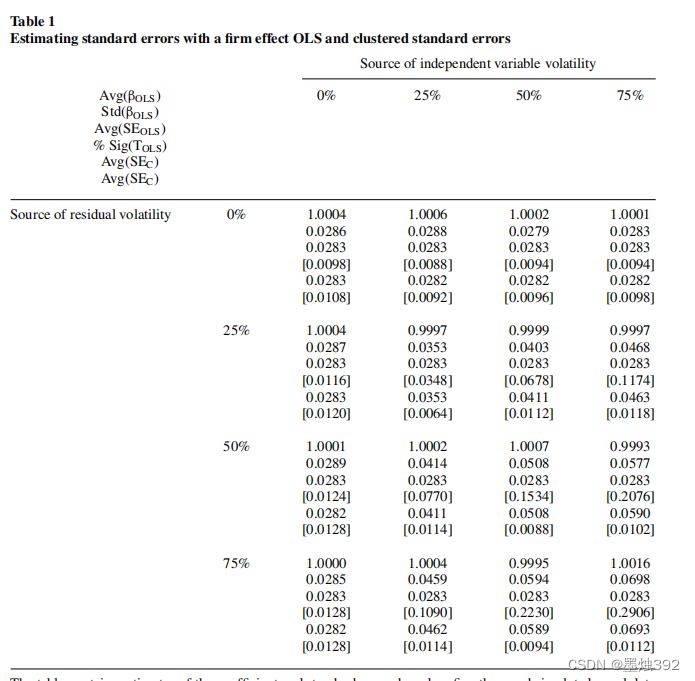
本文重复模拟一个面板数据。在第一个版本的模拟中,包含了一个固定的未观察到的公司效应,自变量或残差没有时间效应。因此,数据按照公式 (4) 和 (5) 进行模拟。在各次模拟中,自变量和残差的标准差都假设为恒定,分别为 1 和 2 。这将产生 $20 \%$ 的 $R^2$ 。在不同的模拟中,本文改变了自变量中由企业效应引起的方差的部分,范围从 $0 \%$ 到 $75 \%$ ,增量为 $25 \%$ (表 1 )。对残差也做了同样的事情。这说明了OLS标准误的偏差大小是如何随着自变量和残差中企业效应的强度而变化的。
最终目的是为了得到这张表
# 安装和加载所需的包
library(plm)
library(sandwich)
library(lmtest)
set.seed(123) # 设置随机数种子
# 设置参数
n <- 500 # 企业数量
T &l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











