







一、问题描述
[USACO3.4] 美国血统 American Heritage
题目描述
农夫约翰非常认真地对待他的奶牛们的血统。然而他不是一个真正优秀的记帐员。他把他的奶牛 们的家谱作成二叉树,并且把二叉树以更线性的“树的中序遍历”和“树的前序遍历”的符号加以记录而 不是用图形的方法。
你的任务是在被给予奶牛家谱的“树中序遍历”和“树前序遍历”的符号后,创建奶牛家谱的“树的 后序遍历”的符号。每一头奶牛的姓名被译为一个唯一的字母。(你可能已经知道你可以在知道树的两 种遍历以后可以经常地重建这棵树。)显然,这里的树不会有多于 26 个的顶点。 这是在样例输入和 样例输出中的树的图形表达方式:
C
/ \
/ \
B G
/ \ /
A D H
/ \
E F
树的中序遍历是按照左子树,根,右子树的顺序访问节点。
树的前序遍历是按照根,左子树,右子树的顺序访问节点。
树的后序遍历是按照左子树,右子树,根的顺序访问节点。
输入格式
第一行: 树的中序遍历
第二行: 同样的树的前序遍历
输出格式
单独的一行表示该树的后序遍历。
样例 #1
样例输入 #1
ABEDFCHG
CBADEFGH
样例输出 #1
AEFDBHGC
提示
题目翻译来自NOCOW。
USACO Training Section 3.4
二、思路分析
1、算法标签
这道题考察的是数据结构二叉树中常见的三种遍历方式:前序遍历、中序遍历、后序遍历。
2、思路分析
前序遍历:根节点——左子树——右子树
中序遍历:左子树——根节点——右子树
后续遍历:左子树——右子树——根节点
题目中给了我们前序遍历和中序遍历。给我们一个字符串,我们的首要任务就是要区分出:谁是左子树?谁是右子树?谁又是根节点?
我们发现,在前序遍历的字符串中,第一个元素就是根节点。 而当我们找到根节点后,再去看中序遍历,将刚才找到的根节点作为分隔符,再去找到左子树和右子树。
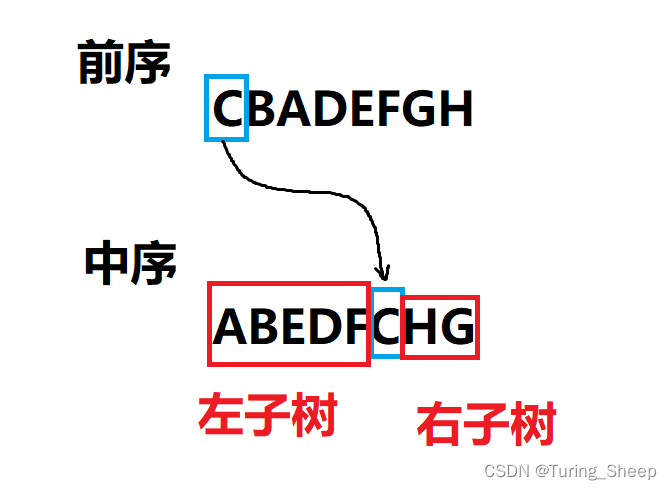
根据后续遍历的顺序,我们先对左子树重复上述操作,再对右子树重复上述操作,操作结束后,最后输出根节点。
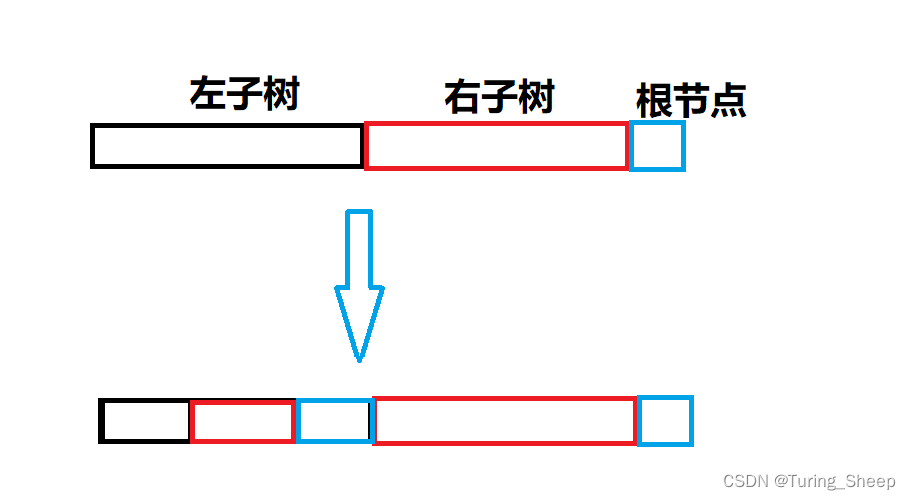
综上所述,我们将这些思路封装成一个递归函数即可。
三、代码实现
//3、美国血统(二叉树的前中后序遍历)
#include<iostream>
#include<string>
using namespace std;
void back(string s1,string s2)
{
int str1_l=s1.find(s2[0]);
if(str1_l>0)
{
string s1_l=s1.substr(0,str1_l);
string s2_l=s2.substr(1,str1_l);
back(s1_l,s2_l);
}
int str1_r=s1.size()-str1_l-1;
if(str1_r>0)
{
string s1_r=s1.substr(s1.find(s2[0])+1,str1_r);
string s2_r=s2.substr(s1.find(s2[0])+1,str1_r);
back(s1_r,s2_r);
}
cout<<s2[0];
}
int main()
{
string s1,s2;
cin>>s1>>s2;
back(s1,s2);
return 0;
}















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









