







前言
大多数时候使用爬虫爬取一页网页所得到的内容信息不够完善,这时候就需要我们进行分页爬取网页信息。
一、如何进行分页爬取?
1. 寻找分页地址的变动规律
2. 解析网页,获取内容,放入自定义函数中
3. 调用函数,输出分页内容
二、步骤
1.引入库
代码如下(示例):
import requests
import json
import pandas as pd2.读入数据
代码如下(示例):
rq=requests.get('https://www.ptpress.com.cn/bookinfo/wsBookSearch?rows=9&page=1&keyword=&jc=').content.decode('utf-8')
rq
该处使用的url网络请求的数据。
三、完整事例
1.这里我是对人民邮电出版社这个网页中有关计算机的书籍进行翻页爬取。
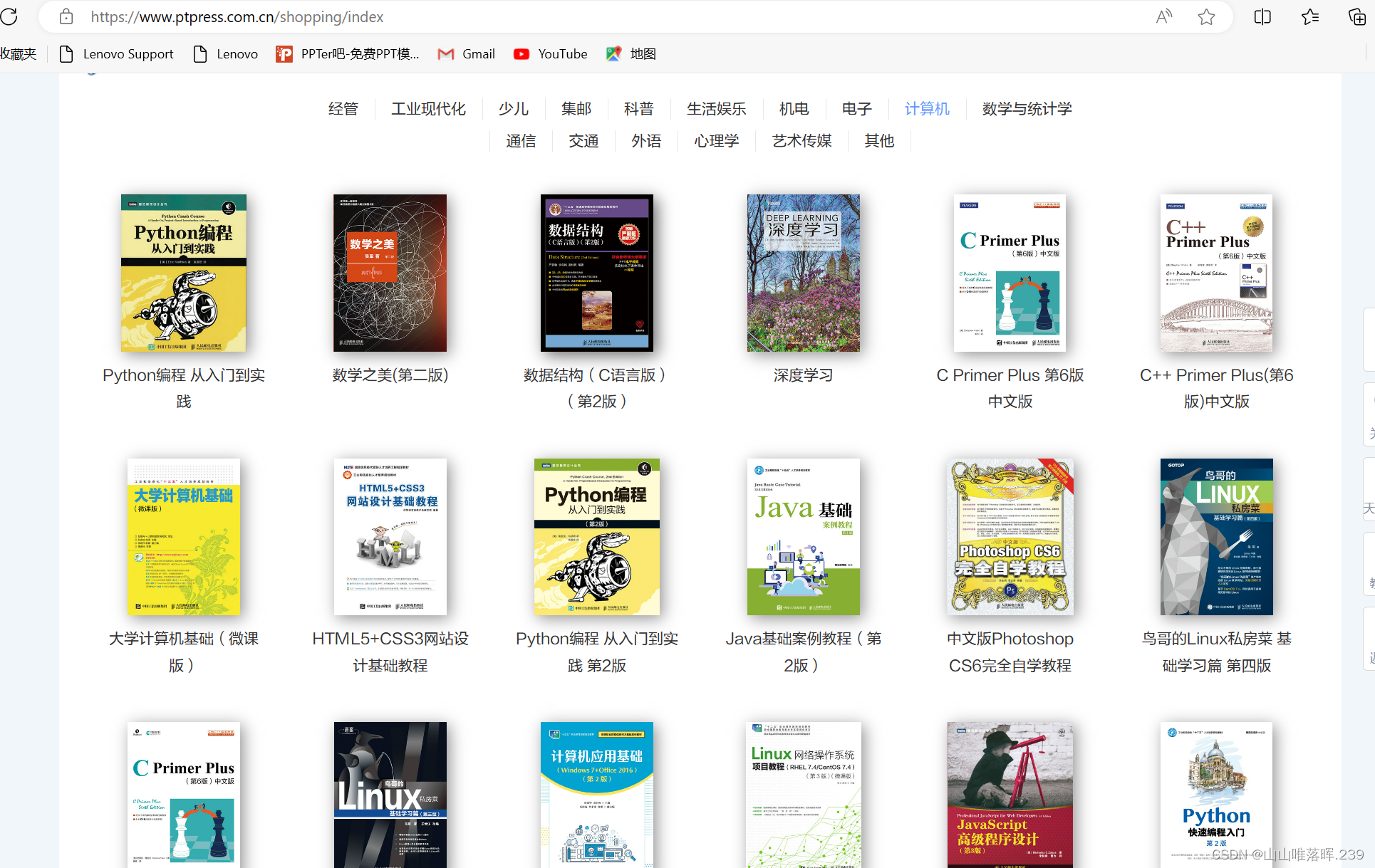
2.爬取的内容为图书名、作者、价格、封面图片路径。

3.得到的结果

四、完整代码
import requests
import json
import pandas as pd
rq=requests.get('https://www.ptpress.com.cn/bookinfo/wsBookSearch?rows=9&page=1&keyword=&jc=').content.decode('utf-8')
rq
type(rq)
data=json.loads(rq)
data
data['rows']
url_list=[]
for i in range(1,11):
url_str='https://www.ptpress.com.cn/bookinfo/wsBookSearch?rows=9&page='+str(i)+'&keyword=&jc='
url_list.append(url_str)
url_list
a=[]
b=[]
c=[]
d=[]
for i in url_list:
booknames=[]
authors=[]
prices=[]
picPaths=[]
rq=requests.get(i).content.decode('utf-8')
book=[i['bookName']for i in data['rows']]
authors=[i['author']for i in data['rows']]
prices=[i['price']for i in data['rows']]
picPaths=[i['picPath']for i in data['rows']]
a.extend(book)
b.extend(authors)
c.extend(prices)
d.extend(picPaths)
a
b
c
d
pd.DataFrame({'书名':a,'作者':b,'价格':c,'图片路径':d})


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









